Prefix-Tuning: Optimizing Continuous Prompts for Generation
ACL 2021
분야 및 배경지식
- 사전학습 언어모델(=pretrained language model) 최적화
- fine-tuning
- 각 태스크에 맞게 사전학습 언어모델을 재학습시키는 방법
- 일반적으로 언어모델의 모든 파라미터를 업데이트
- in-context learning, prompting
- 태스크에 특화된 별도의 튜닝이 필요하지 않음
- 사용자가 자연어로 된 태스크 설명(instruction)이나 몇 개의 예시를 input 앞에 붙여(prepend) 언어모델로부터 원하는 output을 얻는 방법
- 언어모델에 적절한 문맥(context)이 주어지면 모델의 파라미터를 바꾸지 않더라도 적절한 답을 얻을 수 없다는 intuition 제공
- fine-tuning
문제점
- fine-tuning은 언어모델의 모든 파라미터를 수정함으로써 각 태스크마다 하나의 모델을 필요로 함 (비효율적)
해결책
Prefix-tuning
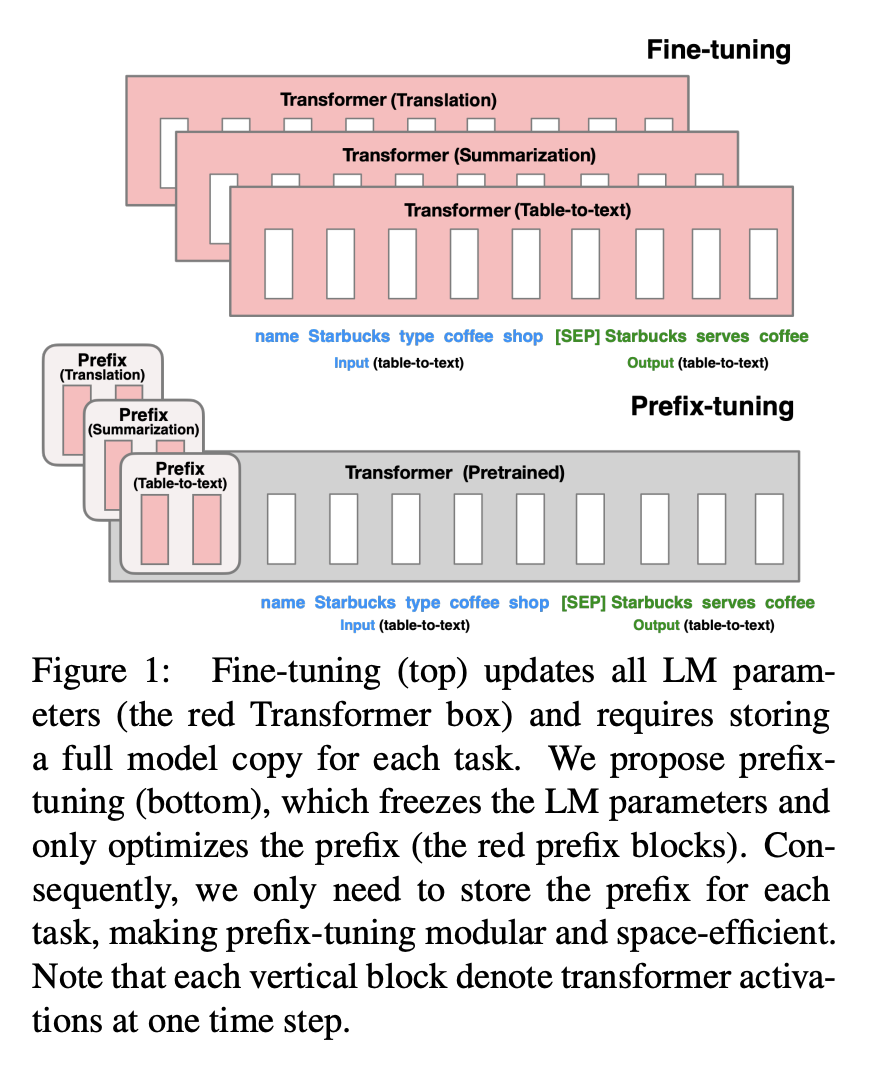
- 연속적인 태스크 특화 벡터(continuous task-specific vector = prefix)를 활용해 언어모델을 최적화하는 방법
- 언어모델의 파라미터는 고정한 상태(=frozen)
- continuous vector/virtual tokens을 사용한다는 점에서 자연어(discrete tokens)를 사용하는 접근방법과 구분됨
- 하나의 언어모델로 여러 개의 태스크를 처리할 수 있음 (prefix를 학습)
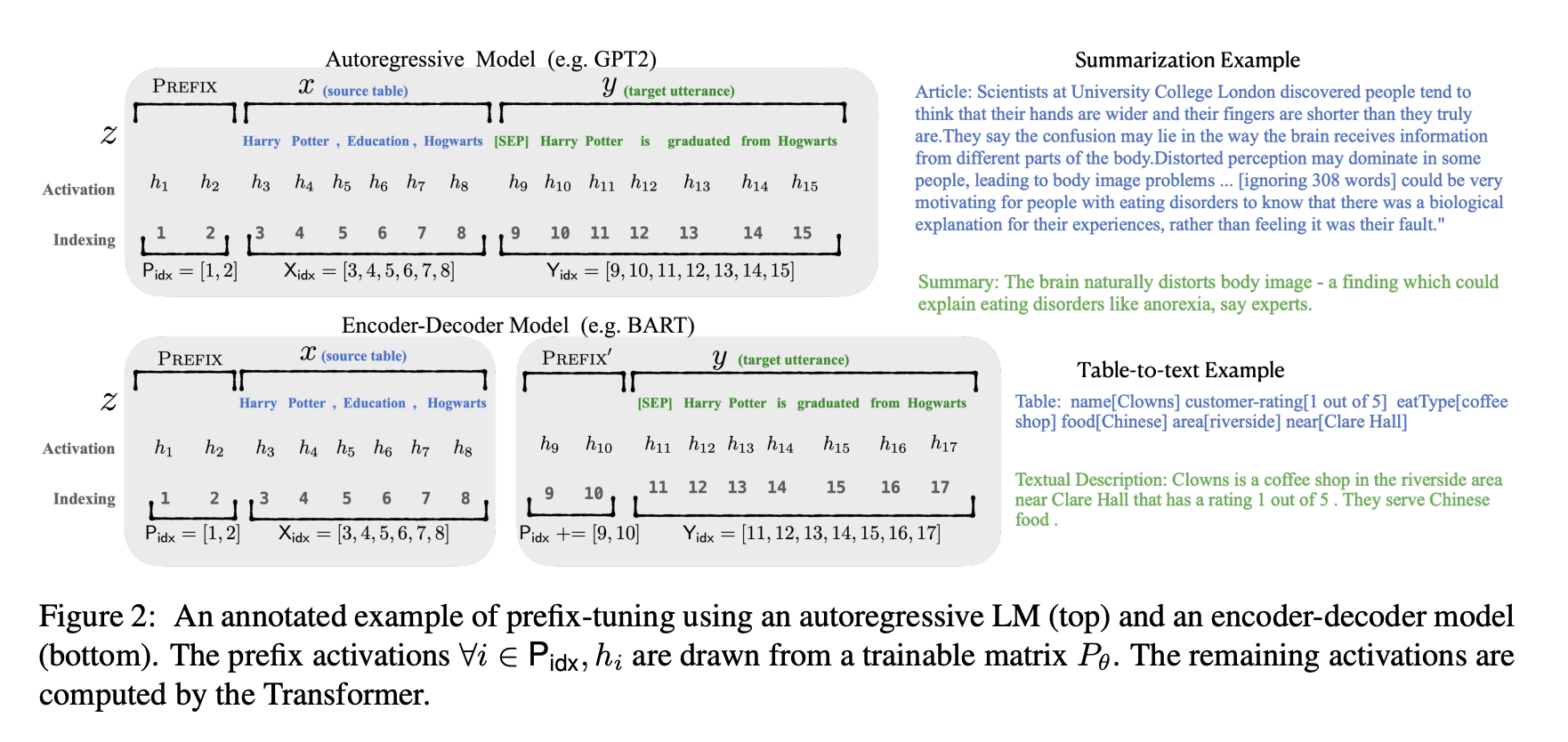
- 연속적인 단어 임베딩으로 구성된 설명(instruction)을 최적화함으로써, 모든 Transformer activation과 이후에 등장하는 연속적인 토큰들에 영향을 줌
- effects will be propagated upward to all Transformer activation layers and rightward to subsequent tokens
- 모든 레이어의 prefix를 최적화
- 안정적인 학습을 위해 MLP를 사용해 reparameterization 진행
평가
- 모델
- GPT-2
- BART
- 태스크
- table-to-text generation
- 데이터셋 / 평가기준
- E2E / BLEU, NIST, METEOR, ROUGE-L, CIDEr
- WebNLG / BLEU, METEOR, TER
- DART / BLEU, METEOR, TER, MoverScore, BERTScore, BLEURT
- abstractive summarization
- 데이터셋: XSUM
- 평가기준: ROUGE-1, ROUGE-2, ROUGE-L
- table-to-text generation
의의
- fine-tuning 대비 1000배 더 적은 파라미터만 학습 가능
- 모델의 파라미터 일부만을 학습하는 lightweight fine-tuning에 비해서도 약 30배 적은 파라미터만 학습
- 모델 크기 대비 약 0.1%의 파라미터만 학습
- 데이터가 적을 때, fine-tuning 대비 좋은 성능
- 일반적으로는 비슷하거나 살짝 낮은 성능을 보임
- fine-tuning에 비해 학습하지 않은 데이터셋에 대해서 더 나은 성능을 보임
- so-called, better extrapolation
한계
- prefix의 길이가 길어질수록 모델의 input 길이에 제약이 생김
- prefix 길이가 길어진다는 것은 학습할 파라미터가 증가한다는 것을 의미
- 표현력(=expressive power)이 늘어난다는 것이기 때문에, 더 좋은 성능을 보임 (e.g. 요약 태스크: 200)
- 하지만 prefix가 길어질수록 모델이 처리할 수 있는 제한된 길이에서 더 많은 자리를 차지하는 것이기 때문에 input length에 제약이 생김
- input에 continuous vector를 추가하는 여타 다른 prompt tuning 방식들에 비해 더 많은 parameter를 필요로 함

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab