TEMPERA: Test-Time Prompt Editing via Reinforcement Learning
ICLR 2023
분야 및 배경지식
- prompt, in-context learning
- 언어모델의 규모가 커짐에 따라, 몇 개의 in-context 예시(demonstration)를 포함한 프롬프트가 주어지면 특정한 태스크를 수행할 수 있게 됨 (별도의 모델 파라미터 학습 X)
- in-context 프롬프트가 어떻게 작성되는가, 어떠한 예시를 선택하는가에 따라 성능이 크게 변화
- 강화학습
- 주어진 환경과 상태(state)에서 agent가 누적 리워드(reward)의 기댓값을 최대화할 수 있는 방향으로 행동(action)을 선택하도록 학습
- 상태가 주어졌을 때 행동을 선택하는 함수를 policy(=π)라고 부르며, 최근 policy를 표현할 때 neural network를 활용하는 경우가 많음 (Deep Reinforcement Learning)
문제점
- zero-shot이나 few-shot learning 시에 프롬프트를 잘 선택하는 것이 중요
- 각 쿼리에 따라 좋은 프롬프트가 다를 수 있다는 사실이 간과됨
- 쿼리마다 다른 프롬프트를 찾는 것은 black-box 최적화의 비효율성을 감안하였을 때 실현 어려움
해결책
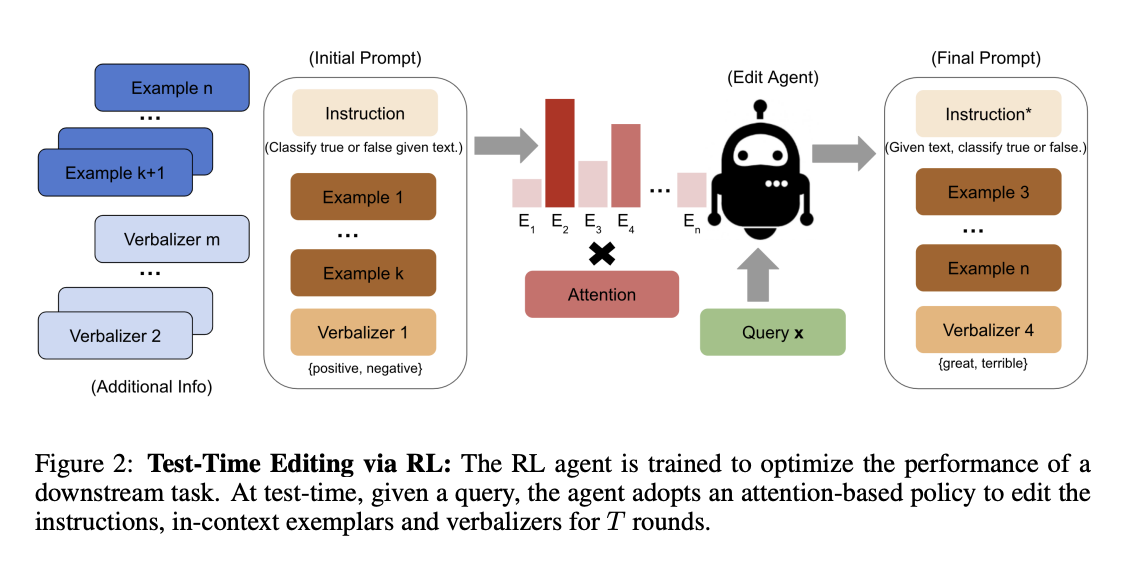
TEMPERA (TEst-tiMe Prompt editing using Reinforcement leArning)
- 각각의 쿼리에 대해서 (query-dependent) 해석가능한 프롬프트를 제공
- 테스트 시에 추가적인 학습 없이 각각의 쿼리에 대해서 적용 가능하다는 점에서 test-time editing이라고 칭함
- test-time edit != test-time optimization
- attention-based policy를 활용하여 강화학습 방식으로 instruction, in-context exemplars, verbalizers를 수정
- instruction: 태스크가 어떻게 수행되어야 하는지를 설명
- in-context demonstration: 몇몇 예시와 이에 대응하는 레이블(정답) 정보
- verbalization: 레이블로 선택될 키워드 디자인
- 강화학습
- state (상태)
- 사전학습 언어모델의 last hidden states를 state로 상정하여 이를 policy에 사용
- action (행동)

- 선택할 수 있는 action space의 범위를 효율적으로 제한
- instruction: 토큰화한 후 위치 바꾸기, 삭제, 혹은 추가
- in-context exemplars: 랜덤하게 선택한 후 순서 변경
- verbalizer: 자유롭게 선택
- reward (리워드; 보상)
- 시간 t에서 생성된 프롬프트가 정답 레이블을 예측할 확률과 정답이 아닌 레이블을 예측할 확률 중 최댓값을 구하고, 그 둘의 차이를 score로 상정
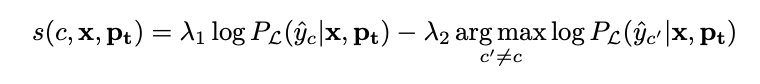
- 리워드는 즉각적인 보상을 의미
- 이를 현재 프롬프트의 점수와 이전 프롬프트의 점수 차로 가정한다면 누적 리워드는 마지막 프롬프트와 처음 프롬프트 사이의 점수 차로 정의 가능
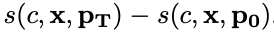
- 시간 t에서 생성된 프롬프트가 정답 레이블을 예측할 확률과 정답이 아닌 레이블을 예측할 확률 중 최댓값을 구하고, 그 둘의 차이를 score로 상정
- attention-based policy
- PPO를 학습 알고리즘으로 사용
- 이밖에도 reward 정규화, observation 정규화, policy 학습 시 action history 고려 등
- state (상태)
평가
- 데이터셋
- SST-2, Yelp reviews, MR, CR, AG News, RTE, QNLI, SNLI, MNLI, MRPC
- 모델
- policy (강화학습 모델)
- GPT 구조를 따르며, encoder layer 사용
- policy와 baseline은 동일한 attention-based encoder를 공유
- baseline (사전학습 모델)
- RoBERTa-large
- policy (강화학습 모델)
의의
- 기존의 태스크 기반 프롬프트와 다르게 각 쿼리에 따라 다른 프롬프트를 효율적인 방식으로 제공
- 사람의 사전 지식을 사용할 수 있으며 유연성, 실현가능성, 해석가능성을 충족
- 특히 action space를 효율적으로 줄임으로써 제한된 범위 내에서 최적화 달성
한계
- instruction, exemplar, verbalizer 등이 사전에(=수정 이전에) 존재해야 가능

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab