RLPROMPT: Optimizing Discrete Text Prompts with Reinforcement Learning
EMNLP 2022
분야 및 배경지식
- 강화학습 (reinforcement learning)
- policy
- 현재 상태(state)를 받으면 그에 맞는 행동(action)을 리턴해주는 함수
- reward
- 선택된 action이 좋은지 나쁜지를 판단
- 강화학습은 누적 reward를 최대화하는 것이 목표
- policy
- Prompt
- 모델의 전체 파라미터를 업데이트해야 하는 fine-tuning과 다르게, 언어모델로 하여금 원하는 결과를 생성할 수 있도록 input에 추가적인 텍스트를 붙이는 방법
- soft prompt
- 자연어가 아니라 학습 가능한 연속적인 벡터로 이루어진 프롬프트
- 해석 가능성이 떨어지고, 언어모델 간 재사용이 어려우며, gradient가 접근 불가능할 때 적용이 어려움
- discrete prompt
- 자연어로 이루어진 프롬프트
- prompt space를 체계적으로 탐색하지 못하는 경우가 빈번, 최적화가 어려움
문제
- soft prompt, discrete prompt는 위에서 언급한 각각의 한계가 존재
해결책
RLPrompt
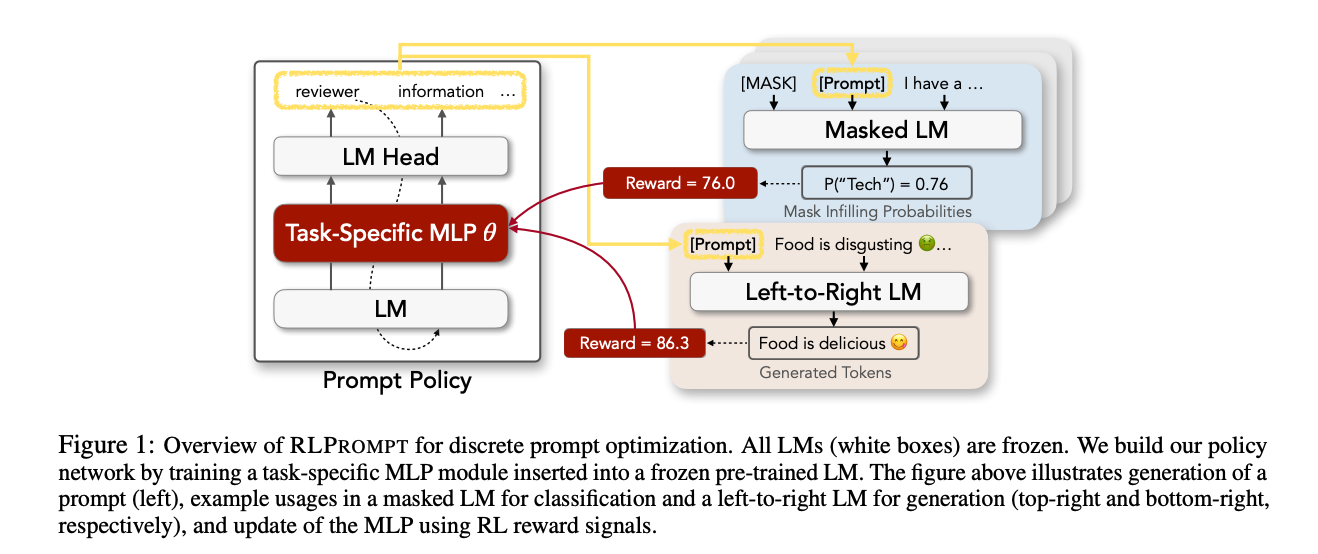
- 강화학습을 사용한 모델을 이용하여 최적화된 자연어 프롬프트를 생성하는 방법
- 토큰을 모두 생성한 이후 전체 프롬프트에 대해 태스크 reward를 계산, 이를 활용해 policy 업데이트
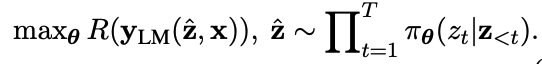
- pi for policy, z for prompt, R for reward, x for input
- 학습 효율성과 강화학습의 성공을 위해 두 가지 reward engineering 도입
- input-specific z-score reward (인풋-특화 z-score reward)
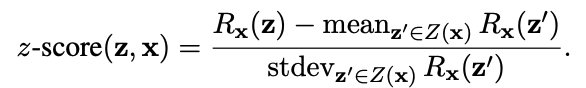
- reward를 특정 input에 대한 평균과 표준편차를 활용해 정규화하여, 특정 input에 대한 z-score를 계산
- piecewise reward
- adversarial prompt의 영향을 줄이고 태스크의 우선순위와 강건성을 더욱 잘 표현하기 위함
- 텍스트 분류의 경우, 레이블에 대한 확률을 활용하여 [Gap_z(c) = 프롬프트가 정답 레이블을 예측할 확률 - 정답이 아닌 레이블을 예측할 확률의 최대값]으로 정의, Gap_z(c)가 0보다 크다면 correct = 1을 부여

- 텍스트 스타일 변환의 경우, content와 style을 바탕으로 reward function 정의
- 자세한 식은 논문의 Appendix 참고
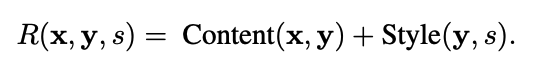
- 텍스트 분류의 경우, 레이블에 대한 확률을 활용하여 [Gap_z(c) = 프롬프트가 정답 레이블을 예측할 확률 - 정답이 아닌 레이블을 예측할 확률의 최대값]으로 정의, Gap_z(c)가 0보다 크다면 correct = 1을 부여
- adversarial prompt의 영향을 줄이고 태스크의 우선순위와 강건성을 더욱 잘 표현하기 위함
- input-specific z-score reward (인풋-특화 z-score reward)
평가
- 태스크
- few-shot classification
- 감정분류: SST-2, Yelp Polarity, MR, CR, SST-5, Yelp
- 주제분류: AG's News
- Subj, TREC, Yahoo, DBPedia
- unsupervised text style transfer
- Yelp sentiment transfer
- Shakespeare authorship transfer
- few-shot classification
- 모델
- policy network
- distilGPT-2에 추가된 MLP layer
- distilGPT-2는 frozen
- MLP layer만 최적의 프롬프트 토큰을 생성하도록 학습
- language model
- RoBERTa
- GPT-2
- policy network
- 강화학습
- off-the-shelf RL 알고리즘을 사용하여 reward objective 최적화
- soft Q-learning 활용
의의
- 여러 모델에 대해 동시에 사용할 수 있는 자연어 프롬프트를 생성
- 모델의 gradient를 알지 못해도 프롬프트 공간을 효율적으로 탐색 가능
- gradient 연산은 비용이 많이 듦
- 최근 모델의 추론 API만 사용할 수 있는 경우가 빈번 (gradient 공개 X)
한계
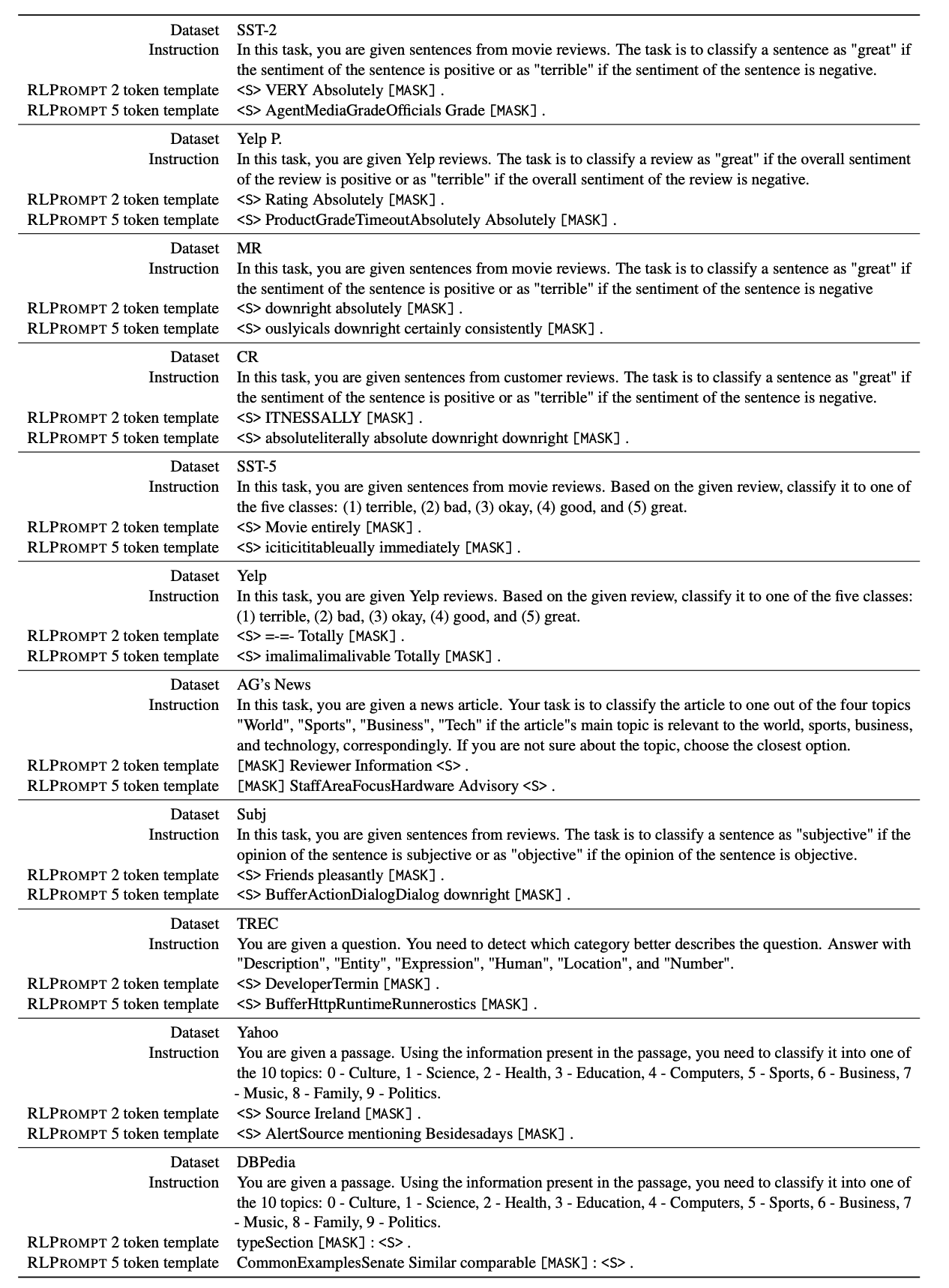
- 생성된 프롬프트가 문법적으로 옳지 않고 무의미한 단어의 나열로 이루어짐
- 자연어 프롬프트의 주요한 의의가 해석 가능성인데, 최적화된 프롬프트는 해석 가능성이 떨어짐
- GPT-3와 같은 큰 모델에서 적용 가능한지 확인되지 않음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab