Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
language-model
목록 보기
11/20
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation (ICLR 2022, link)
배경지식
- 논문에서 말하는 extrapolation이란
- 모델이 학습할 때 사용한 토큰 수보다 더 많은 수의 인풋 토큰에 대해서도 잘 동작할 수 있는지 여부
- perplexity
- 언어모델 평가 지표 중 하나
- 해당 링크 참고
- inductive bias
- 학습 데이터에 없던 새로운 데이터에 대해 예측할 때 사용하는 추가적인 가정 혹은 편향
- 보지 못한 데이터에 대해서도 귀납적 추론이 가능하도록 함
문제점
- 언어모델이 학습 시 본 시퀀스보다 추론 시에 더 긴 시퀀스를 처리해야 한다면 (extrapolation)
- 위치(position) 표현 방식을 바꿈으로써 해결 가능
- 하지만 (당시) 현재의 위치 표현 방식은 효율적이지 않음
해결책
Attention with Linear Biases (ALiBi)

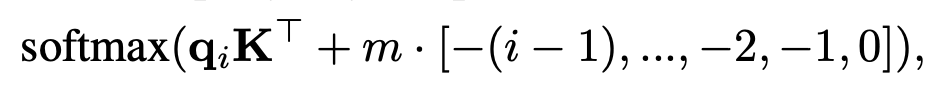
- 기존의 Transformer 모델의 position embedding은 word embedding에 추가되었음
- ALiBi의 경우 네트워크에 position embedding을 추가하지 않음
- 대신, query-key dot product를 계산할 때에 고정된 (static, non-learned) bias를 추가
- m은 학습 전 정해지는 헤드별(head-specific) slope
- n개의 헤드가 있다면, 2**(-8/n)에서 시작해 선형적으로 증가
- 예를 들어, 8개의 헤드가 있다면 1/2, 1/4, ... 1/256
- 최신성(recency)에 대해 inductive bias를 가짐
- 다시 말해, 멀리 떨어진 쿼리와 키 쌍의 어텐션 점수에 페널티를 부여

- 훈련 시 더욱 적은 비용을 사용하면서 추론 시에 더 긴 시퀀스에 대해서도 잘 동작
- 1.3B 모델을 각각 (1024 토큰, ALiBi), (2048 토큰, sinusoidal)에 대해 학습
- 2048 토큰으로 테스트하였을 시
- 유사한 perplexity, 11% 더 빠른 속도, 11% 더 적은 메모리 사용률을 보여줌
평가
- 모델
- Transformer
- 데이터셋
- WikiText-103
- Toronto BookCorpus
- CC100+RoBERTa Corpus
- 평가지표
- perplexity

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab