Attention Is All You Need
NIPS 2017
분야 및 배경지식
- Transformer
- 이후 BERT, GPT 등 다양한 언어모델의 근간이 된 self-attention 기반의 모델
문제
- 거리가 멀어질수록 dependency를 학습하는 데에 어려움을 겪음 (e.g. RNN)
해결책
Transformer
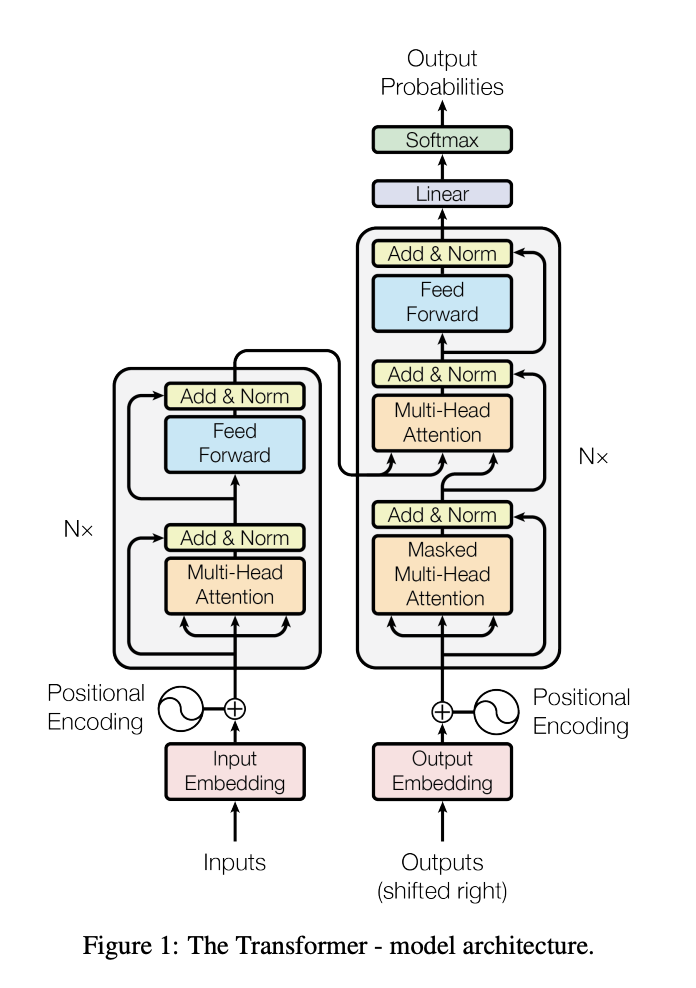
- self-attention 기반의 모델
- self-attention 메커니즘이란, 시퀀스의 representation(표현)을 계산하기 위해 단일 시퀀스 내 다른 위치들과의 관계를 활용하는 것
- encoder-decoder 구조
- encoder는 input sequence를 연속적인 representation으로 매핑
- 6개 동일한 레이어의 중첩(stack)으로 구성
- 각 레이어는 2개의 서브 레이어로 구성되어 있음
- multi-head self-attention mechanism
- 단순한 fully connected feed-forward network
- residual connection, layer normalization 사용
- decoder는 연속적인 representation으로부터 요소 하나씩 output sequence를 생성
- 6개 동일한 레이어의 중첩(stack)으로 구성
- 각 레이어는 3개의 서브 레이어로 구성되어 있음
- 2개의 서브 레이어는 encoder와 동일
- 1개의 서브 레이어는 encoder의 output에 대한 multi-head attention
- multi-head attention의 경우 이후의 위치는 참조하지 않도록 구성 (auto-regressive 특성을 위해)
- residual connection, layer normalization 사용
- encoder는 input sequence를 연속적인 representation으로 매핑
Attention
- query와 key-value 쌍을 output에 매핑하는 함수
- query, key, value, output은 모두 벡터
- output은 value의 가중합으로 표현
- scaled dot-product attention
- dot-product attention이 additive attention에 비해 더욱 빠르고 공간 효율적이며, 최적화된 행렬곱(matrix multiplication) 연산에 더욱 유리
- dot-product가 너무 커져서 softmax function이 너무 작은 gradient로 가는 상황을 방지하기 위해 root(d_k)로 나눠줌(scale)
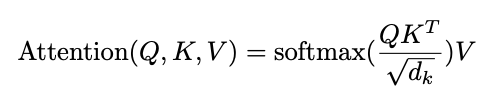
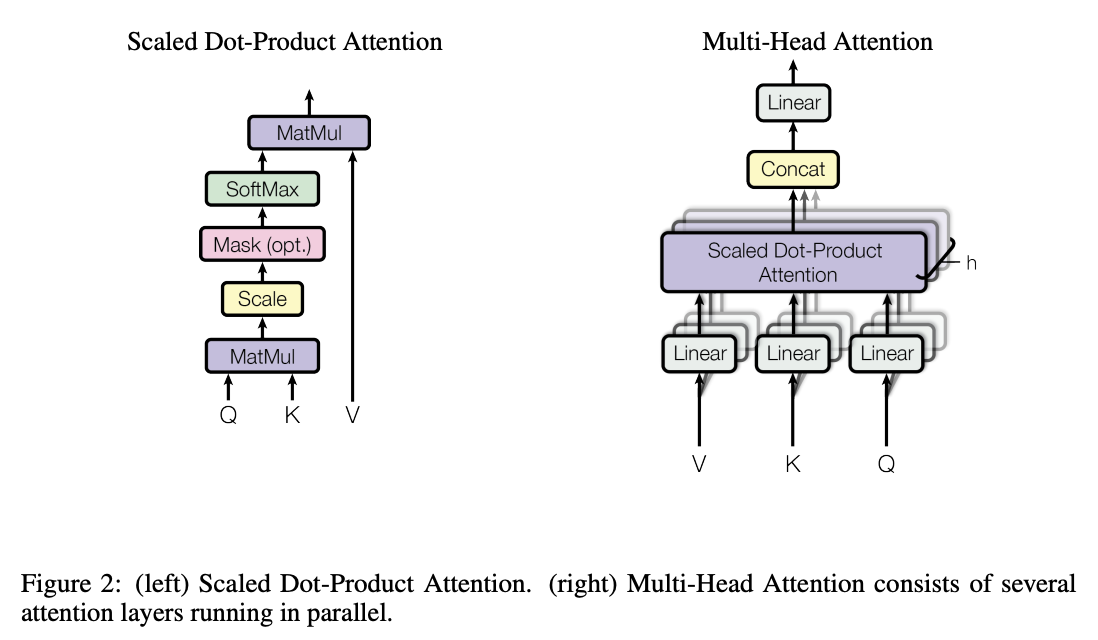
- multi-head attention
- 단일한 하나의 head attention을 사용하는 게 아니라, query, key, value를 여러 개의 다른 linear projection을 사용하여 h개의 query, key, value를 만듦 (multi-head)
- 이를 활용해 output을 만들고 이를 연결(concat)한 다음 최종 값으로 project
- multi-head attention은 모델로 하여금 다른 위치(position)에서 다른 representation subspace의 정보를 attend하도록 도와줌
Point-wise Feed-Forward Network
- linear transformation 수행
Positional Encoding
- self-attention 기반 모델이기 때문에 위치 정보가 없음
- 시퀀스 내 토큰의 위치 정보를 삽입
- 다른 빈도(frequency)를 가진 sine, cosine 함수를 활용
- 학습된 positional embedding과 유사한 성능을 보였기 때문에 sinusoidal 버전 활용
평가
- 학습 데이터 (기계번역)
- WMT 2014 영어-독일어 데이터셋
- WMT 2014 영어-프랑스어 데이터셋
의의
- 품질이 더욱 우수 (뛰어난 성능)
- self-attention을 사용함으로써 더 긴 범위의 dependency를 더욱 잘 반영할 수 있음
- 더욱 해석가능한 모델을 만들 수 있음 (interpretable)
- 더욱 잘 병렬화할 수 있음 (more parallelizable)
- 학습 시 시간 단축
- recurrent layer 대비 시간이 빠름
- 다른 태스크들에도 잘 일반화 가능

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab