엘라스틱서치의 토큰화에 대해 알아보기전에 매핑에 대해 먼저 알아보자 매핑을 통해 어떠한 방식으로 데이터를 토큰화 할지 결정할 수 있다.
ES에서 매핑은 데이터베이스의 스키마라고 생각하면된다.
매핑은 데이터를 어떤 형식으로 저장할 것인지, 어떻게 색인화하고 Analyzing할 것인지 ElasticSearch에게 알려준다. 만약 매핑을 하지 않는다면 숫자 형식의 데이터가 문자형태로 저장되고 이로인해 나중에 통계를 내는 작업을 수행할때 문제가 생길 수 있다.
ES mapping의 예: year라는 데이터를 date형식으로 매핑한다.
curl -XPUT 127.0.0.1:9200/movies -d '
{
"mapping": {
"properties": {
"year": {"type": "date"}
}
}
}색인을 생성하면서 매핑을 수행하고
매핑시에는 데이터 토큰화 옵션을 정할 수 도 있다.
'는 백틱이 아닌 작은 따옴표이며, 우분투 터미널에서는 ctrl + v 버튼을 누른 상태에서 tab 버튼을 눌러야 실제 tab 버튼이 작동한 것처럼 할 수 있다.
curl -XPUT 127.0.0.1:9200/movies -d '
{
"mapping": {
"properties": {
"genre": {"index": "not_analyzed"}
}
}
}analyzed는 analyzer를 이용한 tokenize(토큰화) 수행을 통해 색인한다는 의미이다.
ex) "this is my test a sentence"라는 string이 주어졌을때 analyzer를 통과하면 다음과 같이 분리된다.
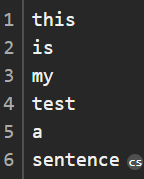
not_analyzed는 정확한 값이 일치되도록 색인하겠다는 의미이다. analyzer를 이용하지 않기 때문에 색인 속도가 빠르다.
(분석이 필요 없는 경우 사용)
ex) "big data" 라는 string이 주어졌을 때 "big data" 로 검색해야 문서가 출력된다.
no는 색인을 하지 않으며 검색이 불가능하다.
Analyzer에는 기본적으로 세 가지 기능이 있다.
Character Filters
Remove Html encoding, convert & to and
Tokenizer
Splits strings on whitespace / punctuation / non-letters
Token Filter
big to large, boxes, boxing to box
Analyzer에는 여러 종류가 존재한다.
1.Standard
2.Simple
3.Whitespace
4.Language
적재적소에 필요한 분석기를 사용하도록 하자
매핑이 잘 되었는지 확인하기 위해서는 다음과 같은 명령어를 이용하면 된다.
curl -XGET 127.0.0.1:9200/movies/_mapping결과를 예쁘게 확인하고 싶으면 다음과 같이 pretty 옵션을 주도록 하자
curl -XGET 127.0.0.1:9200/movies/_mapping?pretty