현서의 elasticsearch 강좌
1.우분투에 ElasticSearch 설치하고 실행해보기

우분투 터미널에wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -입력후 비밀번호 입력sudo apt-get install apt-transport-https입력 후
2.Elastic stack의 전체 구조 간략화
ELASTICSEARCHElastic stack(ElasticSearch, Kibana, Logstash)을 이용하면 전체 텍스트 검색보다 훨씬 더 많은 것을 처리할 수 있으며, 구조 데이터 및 집계 데이터를 매우 빠르게 처리할 수 있다.단순히 검색을 위한 것이 아닌
3.Elasticsearch의 문서와 색인, TF와 IDF

이번엔 Elasticsearch의 몇가지 기본개념을 살펴보도록 하겠다.Elasticsearch에는 두 가지 중요한 논리적 개념이 존재한다. 데이터베이스적 관점에서 생각한다면 Document는 테이블 속 한 행을 의미하며 모든 Document는 고유 ID를 가질 수 있다
4.ElasticSearch의 샤드(Shard)란?
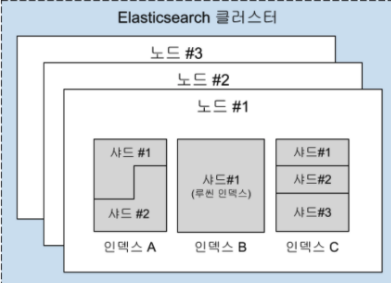
이번엔 ElasticSearch가 어떻게 복원력을 유지할 수 있는지, 우선 전체적인 ElastcSearch의 내부구조를 살펴보면 위와 같다.ES가 "클러스터"를 구성한다고 하면 여러개의 "노드"들이 묶여져 있는 모습을 볼 수 있다.그리고 각 노드는 여러개의 색인(ind
5.ElasticSearch의 매핑과 토큰화(Tokenizing)
엘라스틱서치의 Analyzer에 대해 알아보기전에 매핑에 대해 먼저 알아보자 매핑을 통해 Analyzer의 사용 여부를 결정할 수 있다.ES에서 매핑은 데이터베이스의 스키마라고 생각하면된다. 매핑은 데이터를 어떤 형식으로 저장할 것인지, 어떻게 색인화하고 Analyzi
6.curl 명령을 할때마다 콘텐츠 유형 헤더를 입력할 필요가 없도록 스크립트 작성하기

이 강좌를 전 강좌보다 먼저 작성해야했는데... 순서가 꼬여버렸다.우분투 터미널을 열고 홈 디렉터리에서mkdir bin를 통해 디렉터리 생성후cd bin생성한 bin 디렉터리로 이동한다이제 익숙한 nano 에디터를 이용하겠다nano curl우리는 내장된 curl 명령을
7.ElasticSearch로 Bulk 작업 수행하기
한번에 많은 document를 index에 올리려면 어떻게 해야할까? \_bulk 옵션을 이용해야한다.따라서 이번에는 REST 쿼리와 JSON 형식을 사용하여 많은 문서를 한 번에 가져오는방법을 살펴보겠다.먼저 우리는 홈 디렉터리에서 다음과 같은 내용을 갖는 파일을 만
8.ElasticSearch 문서 업데이트, 삭제 하기

Elasticsearch 문서는 불변이기 때문에 일단 작성된 문서는 실제로 변경할 수 없지만 이 문제를 해결할 방법이 있다.Elasticsearch는 입력한 모든 문서에 자동으로 \_version 필드를 생성하는데, 문서를 업데이트하기 위해 증가한 \_version 번
9.ElasticSearch의 동시성 제어

ElasticSearch와 같은 분산형 시스템을 다룰 때 동시성 때문에 문제가 생길 수도 있다.ElasticSearch는 어떻게 동시성 문제를 제어할까?우선 그 전에 동시성 문제가 무엇인지 알아야한다.두 클라이언트가 동시에 동일한 작업을 수행하려고 한다면 어떻게 될까?
10.ElasticSearch의 분석기(Analyzer)와 토크나이저 사용
Sometimes text fields should be exact-match Use keyword mappingSearch on analyzed text fields will return anything remotely relevantDepending on the a