이번엔 ElasticSearch가 어떻게 복원력을 유지할 수 있는지 알아보겠다.
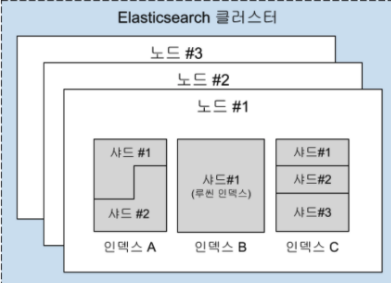
우선 전체적인 ElastcSearch의 내부구조를 살펴보면 위와 같다.
ES가 "클러스터"를 구성한다고 하면 여러개의 "노드"들이 묶여져 있는 모습을 볼 수 있다.
그리고 각 노드는 여러개의 색인(index)를 가지고 있으며 각각의 색인은 여러개의 샤드(shard)를 가질 수 있다. 하나의 물리적 서버당 여러개의 노드를 가질 수 있지만 보통 하나의 물리적 서버당 하나의 노드가 매핑된다. 만약 클러스터가 있는 경우 샤드를 여러노드에 분산시킬 수 있다.
만약 특정한 클라이언트가 Elasticsearch 클러스터의 어떤 서버와 소통하면 그 서버가 클라이언트의 관심 문서를 파악하여 특정 샤드 ID에 해시해 줄 수 있다. 특정한 문서에 해당하는 샤드를 빠르게 알아내는 수학 함수를 통해 클러스터 내 적절한 샤드를 신속하게 찾을 수 있다. 기본 개념은 색인을 여러 샤드로 분산시키고 그 샤드를 클러스터 내 여러 컴퓨터(node)에 배치하는 것이다.
그럼 이제 프라이머리(Primary) 샤드와 레플리카(Replica) 샤드에 대해 알아보겠다.
(이후 부분은 나중에 작성하겠음)

Software engineer who is interested in Server Development & Operation, SRE, Cloud Native Computing