Chuang Zhao at al
2023 WWW
ABSTRACT
- 각 도메인의 user embedding을 독립적으로 훈련하고, 단순 aggregation하는 기존의 CDR 방식은 user-item cross-domain similarity를 무시하는 방법임
- 사용자의 관심의 정렬과 기존의 사용자의 관심 분포를 무시하는 방법임
- 저자가 제안하는 COAST는 user interest alignment와 entity 사이에서의 cross-domain similarity를 제공
- Unified heterogeneous graph
- redefine the message passing mechanism → user-item의 high-order 유사성을 포착
interest alignment가 뭐지?
⇒ “같은 사용자라면 여러 도메인에서도 유사한 관심사를 가지고 있다”
이 가정을 interest alignment라고 함.
cross-domain similarity를 무시한다고 했는데, 무슨 의미인지 모르겠음
⇒ 기존 CDR의 방식은 도메인별로 독립적으로 임베딩을 학습 후, 이를 단순 aggregation하기 때문에 도메인간의 관계는 제대로 학습할 수 없음
1. INTRODUCTION
- CDR은 네 가지 분류로 나눌 수 있음
- Collective MF
- Mapping-based
- GNN-based
- Representation combination (overlapping entities)
- COAST는 해당 방법을 차용했음
- 일반적으로 각 도메인의 임베딩 학습 → aggregation하는 방식
- 위의 방법들은 세 가지 challenges가 존재한다.
- explicit dataset과 fully overlapping users에 대해서만 실험을 진행했다.
→ real world에서는 partial overlapping users와 implicit dataset이 훨씬 더 많다. - 각 도메인별로 representation 학습 후 aggregation 하는 방식은 user-item 사이의 high-order similarities를 무시함
→ 도메인간 관계를 무시 (예, 사용자가 소셜 도메인들에서 공포장르를 선호한다) - 추천 작업에 집중한 목적함수만으로는 도메인간 user interest alignment를 보장할 수 없다.
→ 추천모델이 추천정확도에만 집중하기 때문에 user interest alignment를 제대로 파악한채로 결과를 내놓는지 확인할 수 없음
- explicit dataset과 fully overlapping users에 대해서만 실험을 진행했다.
- 이러한 세 가지 challenges를 해결하기 위해 COAST를 제안
- partial overlapping users 환경
- comments, tags, user/item profiles에서 implicit data를 추출
- 도메인들을 하나의 unified cross-domain heterogenous graph로 표현
→ user-user, user-item 관점에서 deep insight를 얻을 수 있음
- user-user:
- 같은 사용자는 다른 도메인에서 같은 interest distribution을 가지고 있다.
- 동일 사용자에 대해 K개의 interest representation을 정해놓고 도메인간 representation들이 동일하게 나오도록 유도
⇒ 하나의 distribution으로 유도됨
- 사용자별 interest distribution이 다르게 나타나 instance-level에서 잘 구별할 수 있게 됨
- user-item:
- 사용자가 도메인에서 상호작용한 아이템은 그 사용자에 대한 직접적인 interest이다.
- 동일 사용자는 각 도메인에서 상호작용한 아이템에 대한 representation을 동일하도록 강제시킨다.
⇒ 각 도메인에서 일관된 gradient를 가지게 함
- Gradient alignment 기법을 사용하여 gradient가 한 방향으로 흐르게 강제하며, 고차항까지 적용시킨다.
K개의 interest를 설정한다는 방식에서 이전에 대희님이 발표한 K개의 intent를 설정한다는 개념과 비슷한 느낌이 들었다.
이후의 방식에서도 비슷한 방식을 사용하는지 알아봐야겠다.
2. PROPOSED METHOD
2.1 Problem Formulation
- Source / Target Domain
- : user-item interaction (Explicit, Implicit feedback)
- : user, item attribute (사용자 프로필, 아이템 설명 등)
- / : Overlapping user
2.2 Overview of COAST Framework
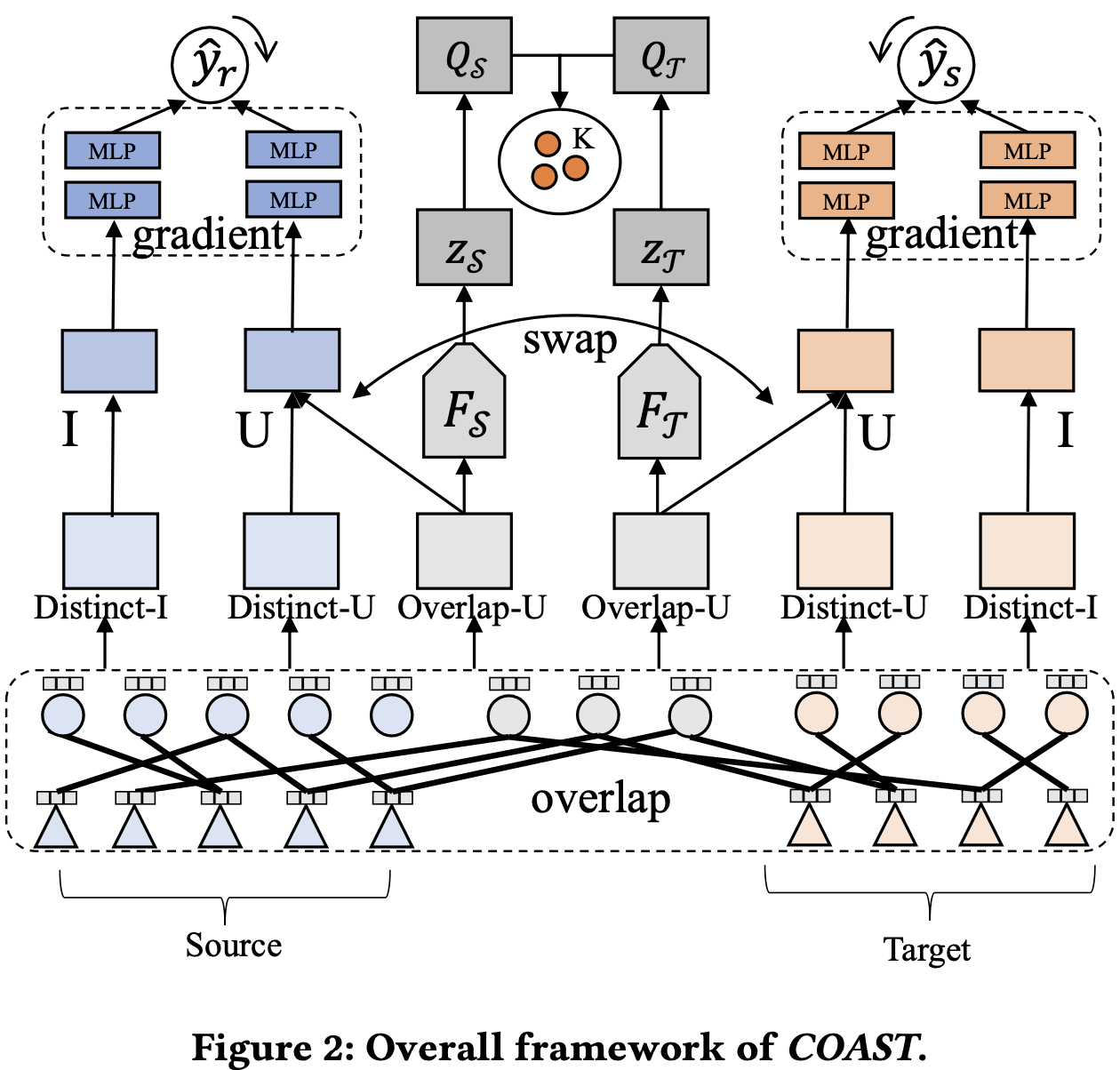
- 하나의 unified cross-domain heterogeneous graph 생성
- GCN의 massage passing 매커니즘을 향상시켜 사용자와 아이템의 similarity를 잘 포착하게 함
- overlap user는 contrastive learning를 이용하여 user-user alignment를 보장
- gradient alignment를 이용하여 user-item alignment를 보장
- Negative sampling을 이용한 두 도메인의 supervision loss를 최소화
- 세 가지 Loss (contrastive learning, gradient alignment, negative sampling)을 합산하여 최종 손실 계산
2.3 Cross-domain Graph Convolution
2.3.1 Construction
- User, item 노드는 소스 도메인, 타겟 도메인 별로 나뉘지만 저자가 정의한 heterogeneous graph에서는 모두 동일한 노드로 봄. (유저, 아이템 두 가지의 노드)
- 초기 임베딩 → 세 가지 케이스로 분류해서 다른 방식으로 초기화
- Numerical attributes: normalization
- Category attributes: one-hot encoding
- Text attributes: 모든 텍스트를 연결해 doc2vec으로 하나의 text embedding으로 초기화
- Overlap user의 경우에는 max pooling을 이용하여 구함
2.3.2 Propagation
- Message passing mechanism
- 소스 도메인과 타겟 도메인의 이웃 정보를 함께 가져옴
- 각 도메인마다 다른 가중치 행렬을 두어 분리
- User embedding update
- self-loop + 이웃 메시지를 합산하여 업데이트
- 이웃 메시지에는 소스 도메인, 타겟 도메인의 정보 둘 다 반영되어 있음
- Stacking of GNN layers
- l번 째 모든 노드의 임베딩의 업데이트 과정은 자기자신 + 소스 도메인 정보 + 타겟 도메인 정보
2.4 User Interest Alignment
- 이전의 연구방법은 도메인별로 representation을 구해 단순히 aggregation하는 방식
→ user interest alignment를 무시하는 방법 - user-user, user-item 관점에서 interest alignment를 하고자 함
2.4.1 User-User Alignment
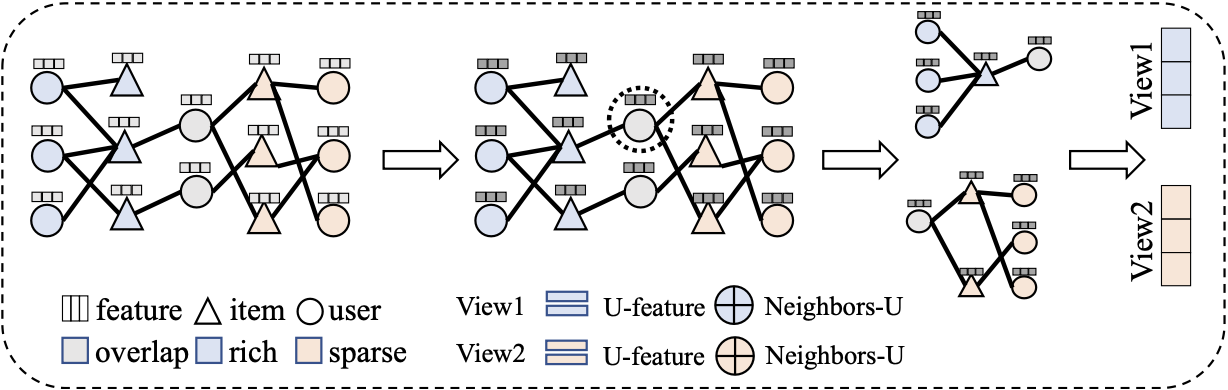
- 두 도메인에서의 overlap user는 소스 도메인과 타겟 도메인 두 개의 view의 user representation을 가지고 있음.
- 동일한 사용자라면 이 두 개의 representation을 동일하게 만들어줘야함
- user embedding은 먼저 2-hop 이웃의 정보를 반영해서 만들어냄
이 때, attention score 을 곱해 중요도에 따른 상대성을 부여 - 그 후, Feature extractor 를 통과시켜 최종 representation 를 생성
Feature Extractor 에 대한 설명이 논문에서는 언급되지 않았음.
신경망을 한 번 더 통과시켜 생성하는 것으로 예상이 됨. - 최종 representation을 contrastive learning을 통해 동일한 사용자의 representation을 가깝게 만듬
이 때, “사용자는 K개의 interest를 가지고 있다”라는 전제를 만족시켜야함.
- k개의 interest를 로 둔다.
- 는 각각 를 가 있는 공간에 매핑시켜 구한 interest distribution임
- interest distribution 는 와 와의 유사도를 구하여 소프트맥스를 취해 확률값으로 변환된 값
- 동일한 사용자면 동일한 distribution을 가져야하기 때문에 cross-entropy를 이용하여 두 distribution의 차이를 최소화함.
- temperature parameter 를 통해 negative example에서도 분류를 잘할 수 있음.
- target-source, source-target 두 시나리오 모두 적용하여 user-user alignment loss를 얻는다.
2.4.2 User-Item Alignment
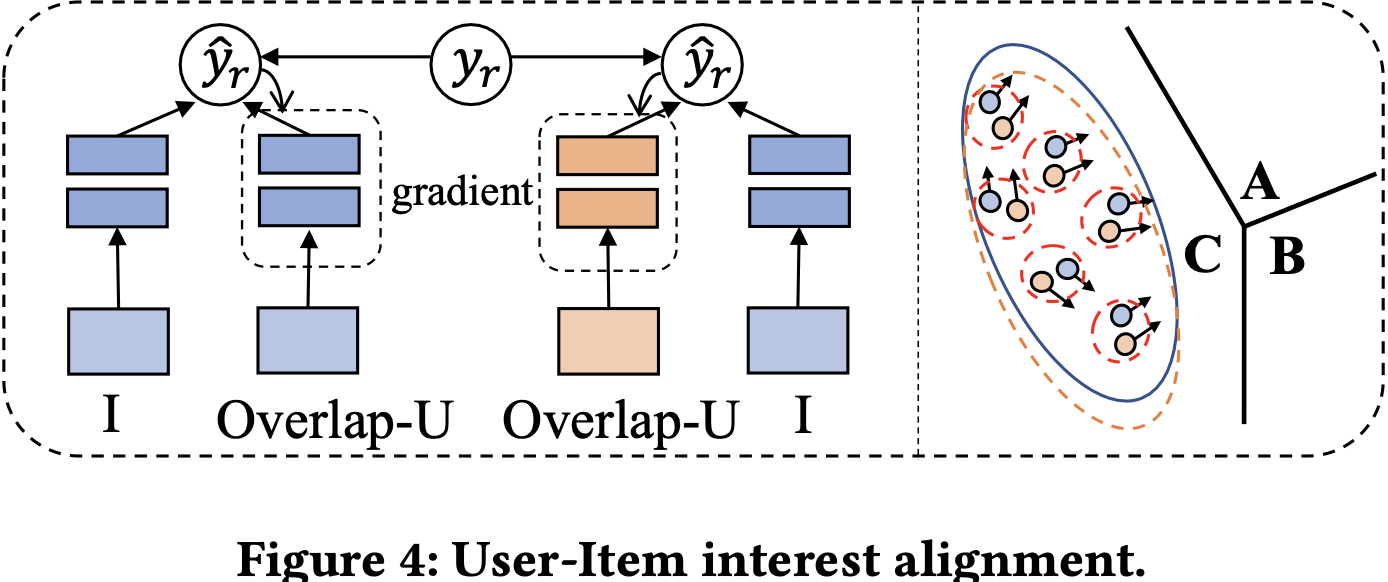
- “사용자가 상호작용한 아이템들은 도메인 불문 유사한 interest로 인해 생긴것이다.”라는 전제조건을 충족시키기 위해서는 도메인간 상호작용한 아이템들의 학습 gradient를 동일한 방향으로 강제하기 위함.
- : user-item interaction score를 학습하는 과정에서의 gradient를 의미
- user-item interaction score를 구할 때, 두 임베딩 을 tower structure (MLP)에 한 번 더 거치게 되는데, 이는 더 풍부한 표현을 얻기 위함.
- 그렇게 정의된 두 gradient는 cosine similarity를 통해 동일한 방향으로 흐르도록 강제함.
2.5 Model Optimization
2.5.1 Supervised Estimation
- user-item interaction prediction score를 구할 때, user, item embedding은 MLP를 한번 더 거쳐서 cosine similarity를 구함.
(+) 정규화항을 통해 과적합을 방지
- source domain, target domain의 prediction score는 Binary Cross-Entropy 손실함수를 이용하여 최소화됨.
- 이 때, {Positive, Negative}로 이루어져 있음.
- Supervised loss는 source domain loss, target domain loss를 합산
2.5.2 Total Loss
- COAST의 최종 Loss는 Supervised loss와 User-User alignment loss, User-Item alignment loss 세 loss를 적절히 사용하여 얻어짐.
3. EXPERIMENTS
3.1 Experimental Settings
3.1.1 Data Sets
- Douban data set:
books, movies, music
shared user ID를 통해 overlap user를 식별 (Partial overlapping user)
COAST는 dual domain을 타겟으로하기 때문에 movie-book, movie-music, book-music으로 분리 - Industrial data set:
mall, community 두 시나리오에서의 추천 향상을 위해 mall-community를 만들었음.
3.1.2 Parameter Settings
- Parameters
- Framework: PyTorch
- Embedding Size: 64
- Parameter Initialization: Kaiming method
- Optimizer: Adam, with an initial learning rate of 5e-4
- Batch Size: 4096
- Maximum Epochs: 100
- User’s Interest (K): 256
- Regularization Weight (): 1e-2
- Alignment Weight (): 1e-3
- Evaluation Metrics
- Leave-one-out (99)
- Metrics:
- HR@10
- NDCG@10
3.1.3 Baselines
- Single-domain: NMF, LightGCN
- Cross-domain:
- Mapping-based: MVDNN, DTCDR
- Representation-combination-based: DDTCDR, DML, GADTCDR, CDRIB
3.2 Comparison with Baselines
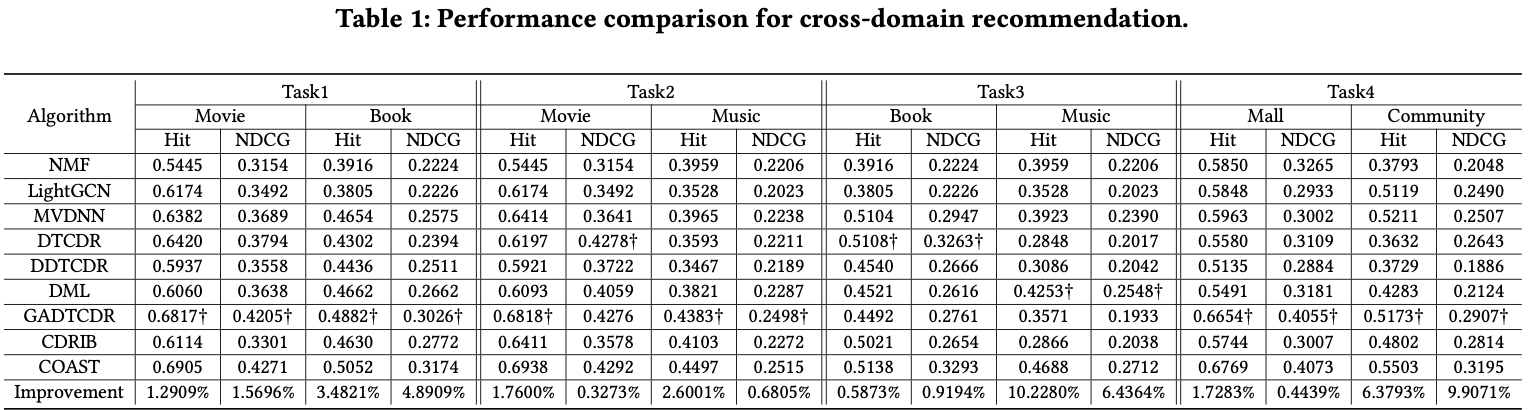
- 모든 task에서 COAST가 성능이 일관되게 잘 나왔음. (0.32%~10.22%)
- some interesting findings
-
대부분의 task에서 CDR methods가 Single-domain methods를 능가함.
→ 도메인간 지식 전이가 효과가 있음.
DDTCDT, DML은 overlapping user의 비율에 의존하기 때문에 underperform한 모습을 보임 -
Implicit feedback도 반영하는 baseline이 explicit feedback만 반영하는 baseline을 능가함.
→ content similarities를 포착의 중요성을 나타냄 -
Representation-combination-baselines이 mapping-based baseline을 능가함
→ 도메인간 user representation의 복잡성을 더 잘 표현함 -
Source domain에서의 interaction이 많을수록 target domain의 추천성능이 향상됨.
-
COAST는 movie-music task보다 movie-book task에서 추천 성능이 더 잘 나옴.
→ 데이터셋의 크기와 overlapping user의 수 때문인 것으로 생각됨. (향후 연구 예정)
-
3.3 Robust Testing
- Overlapping user의 수, 하이퍼파라미터에 따른 실험 결과를 확인
3.3.1 Length N
- 평가지표인 HR@N, NDCG@N에 따른 실험 결과
- N = 3 일 때, 향상률이 가장 높았음.
3.3.2 Overlap Ratio M
- Overlapping user ratio에 따른 실험 결과
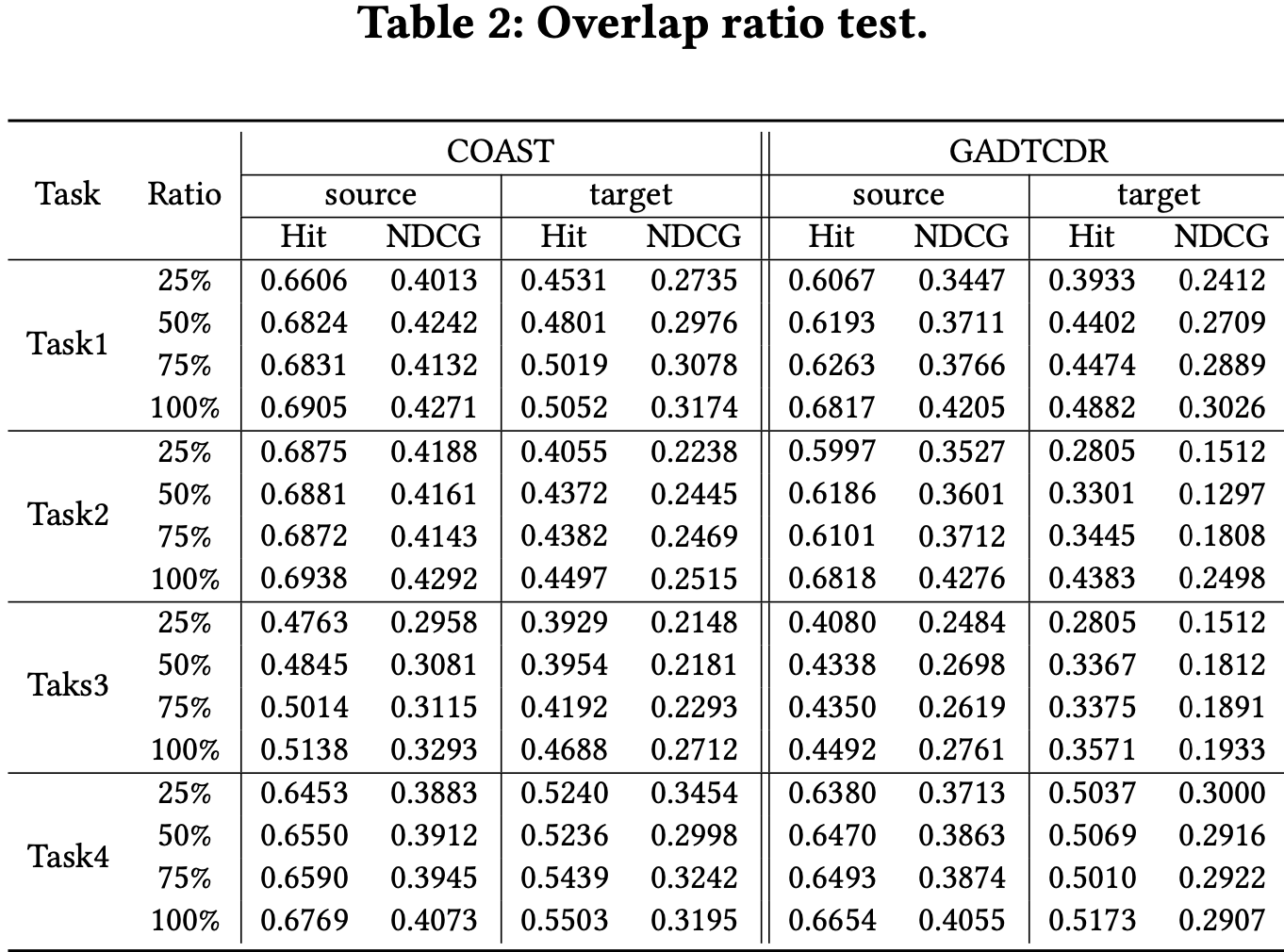
- Overlapping user ratio가 증가할수록 추천 성능도 꾸준히 상승
- COAST는 ratio에 따른 결과가 robust함.
→ Unified cross-domain heterogeneous graph, Message passing mechanism, User interest alignment로 인해 partial overlapping user 환경에서도 추천을 잘 수행하기 때문.
3.3.3 Ablation Studies
- COAST와 5가지의 COAST 변형 모델들을 비교하였음.
- COAST-NF: Explicit feedback만 사용
- COAST-NS: Unified graph 대신 각 도메인 별로(source-target) representation 학습
- COAST-NM: GCN message passing mechanism 사용
- COAST-NU: User-User alignment 제거
- COAST-NI: User-Item alignment 제거

3.3.4 Hyper-testing
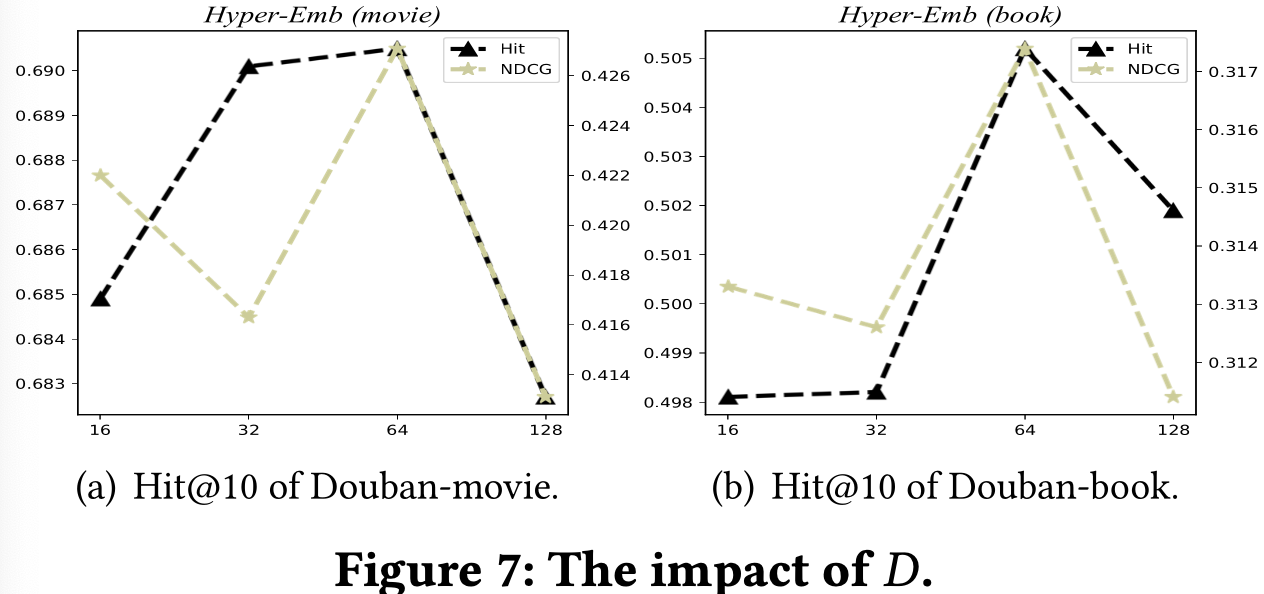
- Embedding size D
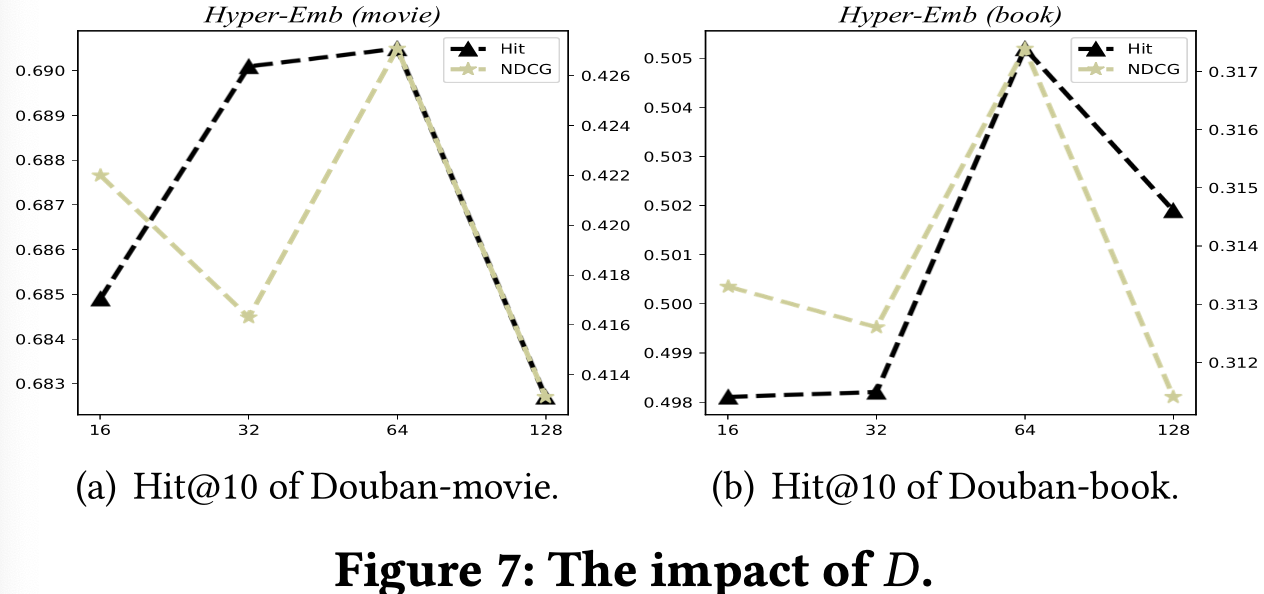
- D = 64일 때 best performance
그 이상으로 갈수록 모델의 수렴속도가 느려지고 과적합이 발생
- D = 64일 때 best performance
- Number of Interests K
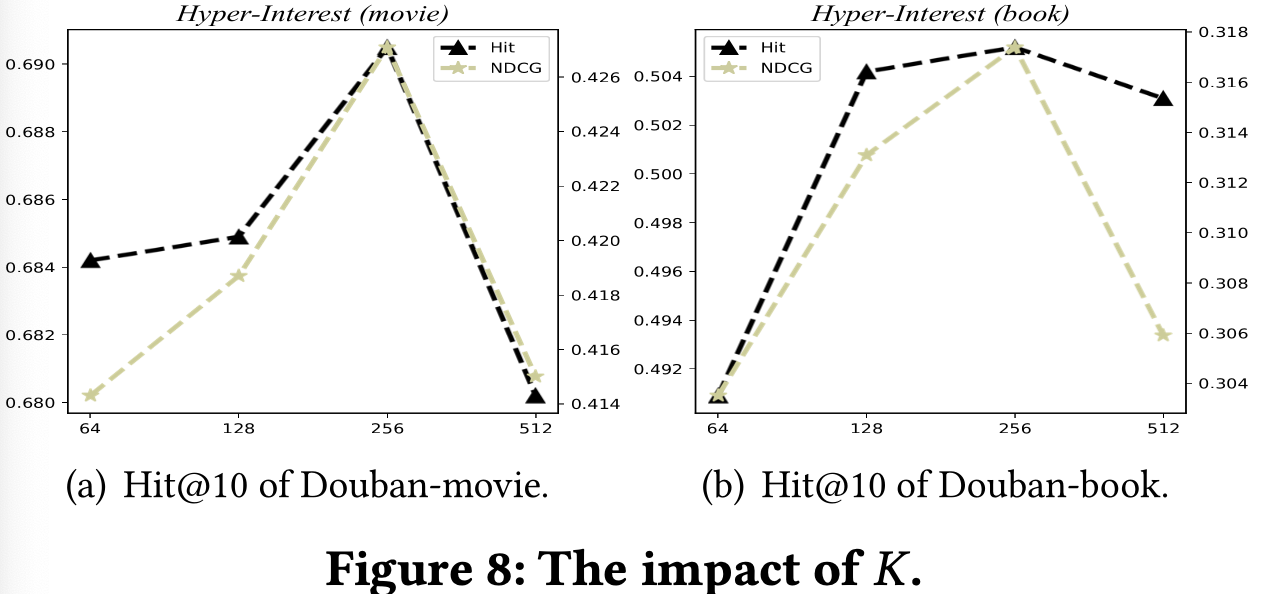
- COAST는 K에 민감하다.
→ K는 사용자의 구체적인 관심을 나타내는 것이 아닌 추상적인 분포이기 때문임. - 아이템과 사용자의 수가 많아지면 관심사 또한 많아지기 때문에 K를 증가시키면 됨.
INTRODUCTION에서 K개의 intent를 설정하는 것과 비슷하다고 느껴졌는데, 여기서 차이점이 드러났다. intent는 구체적인 관심사 하나하나를 말하는 반면, interest는 추상적인 관심사를 나타낸다.
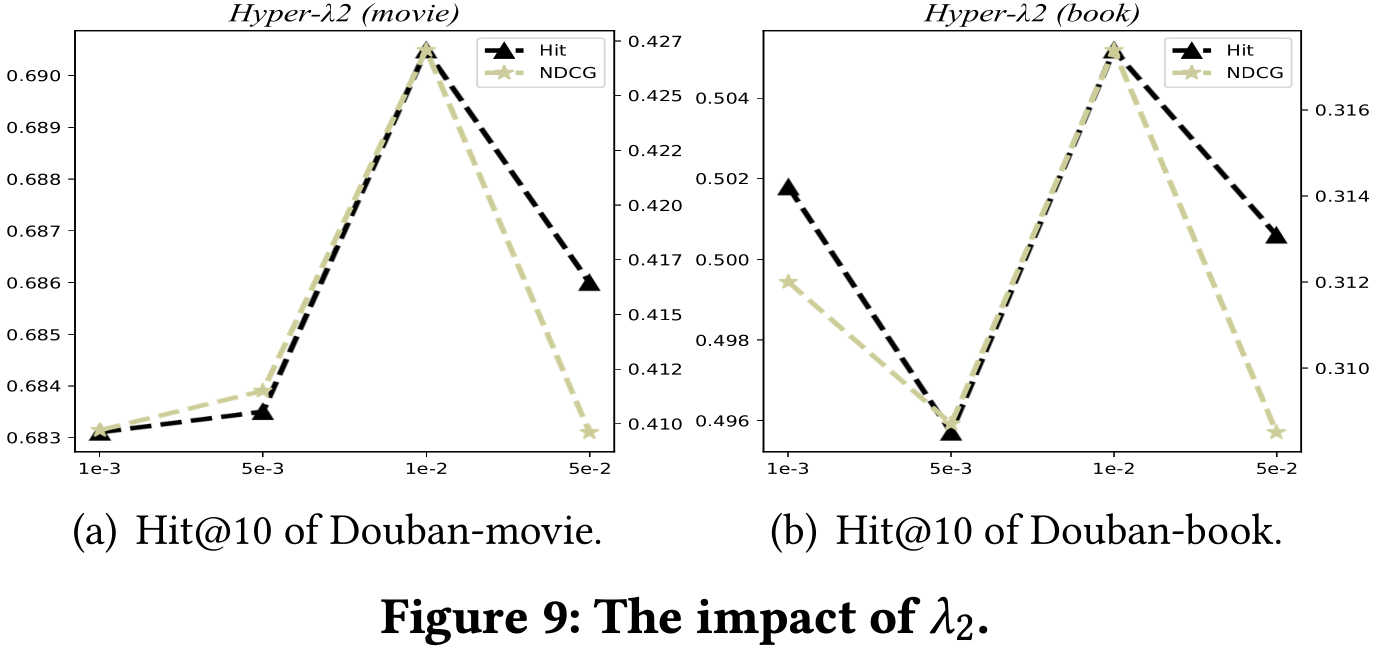
- Consistency weight 는 User alignment의 가중치를 담당하고 있음.
- 가 증가하면, user alignment (User-User, User-Item)을 더욱 강하게 설정하기 때문에 일관된 도메인간 user representation을 얻을 수 있음.
- 가 감소하면, 단순히 도메인간 representation을 aggregation하는 효과를 얻어 일관된 representation을 얻을 수 없음.
- COAST는 K에 민감하다.
4. CONCLUSION
-
COAST는 dual cross-domain recommendation에서 향상된 성능을 보여줌.
-
두 도메인에서의 user-item interaction을 unified cross-domain heterogeneous graph로 표현, 개선된 message passing mechanism, user interest alignment를 이용하였음.
-
향후에는 multi-domain recommendation으로 확장시킬 예정임
COAST는 overlapping user ratio 보다도 두 도메인간의 유사도가 높을 때 큰 효용이 있어보인다.
