Cross-Domain Latent Factors Sharing via Implicit Matrix Factorization
Cross Domain Recommendation
목록 보기
5/11
Abdulaziz Samra
RecSys 2024
ABSTRACT
- Data sparsity 문제를 해결하기 위해 제안되는 CDR의 model architecture는 너무 복잡하다. → 실제로 적용하기 어려움
- Matrix Factorization은 single-domain에서 가장 쉽게 쓰이는 추천 방식
- 저자는 CDR Scenario에서 사용할 수 있는 CDIMF(Cross Domain Implicit Matrix Factorization)을 제안함
- Alternating Direction Method of Multiplier
- Alternating Least Square
1. INTRODUCTION
- 추천 알고리즘으로는 MF와 Neural Network가 주로 산업에 사용되고 있다.
- MF 알고리즘이 neural network를 능가하는 성능으로 강력한 베이스라인임을 보여주는 연구가 있음
- 특히, MF 알고리즘은 사용하기가 쉽고 추론 속도가 빠름
- 이런 알고리즘들도 Data sparsity와 Cold start 문제가 있음
→ CDR이 제안되었다.
- 두 도메인간의 데이터를 공유할 때, 사용자의 개인 정보도 함께 공유되는것을 막아야 함
- 원본 데이터 행렬로의 복원을 어렵게 하는 두 행렬의 교환 방식
- 저자는 CDIMF를 제안하였음. ALS 모델을 기반으로 함
2. PROBLEM STATEMENT
- MF (Matrix Factorization) - Single Domain
where:
- : User-Item Interaction Matrix
- : User Latent Factor
- : Item Latent Factor
- : 최소가 되도록 학습
- : 정규화
기존 MF와의 차이점
- 가중치행렬 C 추가
- ALS 기반의 모델이기 때문에, implicit data도 학습 가능
- explicit data와 implicit data간의 중요도를 다르게 설정 가능
- 정규화항 추가
- 하이퍼파라미터 와 대각행렬 를 추가하여 정규화(과적합방지)
⇒ 여기까지는 단일 도메인 MF
- Multi Domain
- 모든 도메인에서의 user latent vector는 동일해야함
- overlapped user는 각 도메인간 일관성을 유지해야하기 때문
- 각 도메인의 패턴을 서로 반영하면서 정보 공유가 가능함
3. RELATED WORK
IMF
- ALS 기반의 IMF 모델은 다양한 딥러닝 기법이 등장한 이후에도 강력한 CF 베이스라인 모델임
- 하지만 이는 단일 도메인에서만 동작함
⇒ CDIMF는 이 문제를 해결하였음
- 개인정보를 보호할 수 있음 → implicit data 사용으로 인해, 개인정보 노출 위험이 낮아지기 때문, MF 기법을 활용하여 latent vector만 저장하기 때문
- CDR Scenario로 확장할 수 있음. → 도메인 별로 독립적으로 학습하여 도메인간의 가중치를 저장할 수 있음. overlapped user 가중치를 동일하게 설정하여 overlapped user 정보를 공유할 수 있음.
ADMM (Alternating Direction Method of Multipliers)
- 제약조건이 있을 때의 최적화기법
- IMF 목적함수를 최적화하기 위한 방법으로 사용
- CDIMF에서 도메인간 overlapped user latent vector는 동일해야한다는 제약조건이 있음
CDIMF는 overlapped item, full overlapped user가 없어야함.
UniCDR의 Contrastive loss와 다르게 간단하고 연산 효율성이 장점인 MF 모델을 CDR scenario로 확장시켰다고 한다.
4. PROPOSED MODEL
- ADMM (Alternating Direction Method of Multipliers)
- 모든 도메인에서의 overlapped user의 latent vector는 동일해야함
- 이러한 제약조건이 있기 때문에 제약조건이 있을 때의 최적화기법인 ADMM을 사용
- 를 최소화하면서 와 가 유사해지도록 하는 게 목표.
- : 1번의 최적화 과정에 와 를 얼마나 가깝게 할 것인지를 결정
- 순으로 최적화 진행
- 도메인간 일반적인 user factor를 얻어야 하기 때문에 Optimization Objective는 (9)와 같음
4.1 Update Iterations for CDIMF
- 패널티 변수 는 이후 실험에서 정보 공유의 속도에 영향을 준다고 한다.
- 이중변수 은 제약조건 을 위함이다.
- : 전체 도메인 수
- : proximal operator
- : 모든 도메인에서의 평균
- (11) 설명
- user latent vector X와 item latent vector Y는 도메인 i에서 IMF가 이뤄짐
- X는 shared variable Z에 수렴하도록 점진적으로 최적화됨
- (12) 설명
- 최적화된 X와 이중변수 U의 평균을 Proximal operation을 통해 업데이트
- (13) 설명
- X와 Z의 차이를 줄여주는 이증변수 U 업데이트
4.2 Proximal Operator Options
- X와 Z를 가깝게 만들면서 를 최소화한다.
- 2가지 케이스를 고려하였음
4.2.1 Identity Operator
4.2.2 L2 Regularization
- 이를 풀면 아래와 같은 식을 얻을 수 있음.
- Z를 업데이트할 때, 벡터 크기를 조정하여 Overfitting을 방지
- 가 클수록 Z의 크기를 더 작게 만들고, 작으면 Z를 거의 변경하지 않음.
- Z를 안정적으로 업데이트할 수 있음.
4.3 Details of the used ALS solver
- ALS는 MF를 할 때, 두 행을 번갈아가면서 업데이트하기 때문에 하이퍼파라미터를 조정하기 쉬움
- 한 번에 조정하는 jointly 방식보다 계산량도 줄어들고 점진적으로 조정이 가능함
- : latent factors
- 손실함수 는 세 부분으로 구성되어 있음
- 관찰된 user-item 상호작용 loss
- 모든 user-item 쌍의 예측 점수가 0에 가까워지도록 유도
- 하이퍼파라미터 가 이 항의 기여도를 조정
- 에 의해 정규화를 담당
- 에 의해 사용자 및 아이템의 인기도에 따른 정규화 강도 적용 가능
- : 모든 아이템을 동등하게, : 인기있는 아이템에 강한 정규화
- : 관찰된 상호작용에 더 큰 값을 둠
- : 사용자와 상호작용한 아이템 수가 많을수록 강한 정규화 적용
- : 아이템과 상호작용한 사용자 수가 많을수록 강한 정규화 적용
4.4 Derivation of equations for the iterations of the ALS solver
- ALS 기반의 CDIMF 모델에서 user, item latent factor 업데이트 과정을 수학적으로 유도
- Generic formula
- 이 문제는 A가 convex하기 때문에, 미분했을 때 0이 나올 때가 최적의 해임.
- 에 대해서 미분한 결과물 ⬇️
- : element-wise square
- 수식 (26)을 행 단위로 풀어서 각 행을 독립적으로 업데이트 ⬇️
- : A, H의 각 행
- : P, C의 각 행
- : 대각행렬 R의 scalar
Transpose:
- 각 행(single user, item factor)을 독립적으로 업데이트를 진행하기 때문에 병렬로 진행할 수 있음
- 변수 A, B, H는 상황에 맞게 다르게 치환해야함.
- Shared users
- X : user latent factor
- Y : item latent factor
- Z : 도메인간 공유되는 사용자 벡터
- U : ADMM을 위한 이중변수
- Non-Shared users
- 도메인간 공유되지 않는 사용자는 ADMM을 통한 최적화가 필요없기 때문에 H = 0으로 설정
- Items
- p, c는 user-item interaction matrix P, weight matrix C의 열(아이템)
4.5 Algorithm and Complexity

-
user, item latent vector를 정규분포로 초기화
-
domain-shared user vector, ADMM 이중변수 0으로 초기화
-
ALS 기반 MF 시작 → X, Y를 최적화하여 P와 유사하게 만들어냄
-
ADMM 관련 변수 업데이트 → X를 domain-shared user Z와 유사하게 만들어냄
-
ALS 기반 MF의 한 epoch당 복잡도는
-
domain-shared user vector Z를 업데이트할 때의 복잡도는
5. EXPERIMENTAL SETUP
- 다음과 같은 실험을 구상하였음.
- 사용된 데이터셋과 전처리 과정을 공개
- 검증 방법과 행렬을 소개
- 다른 모델들과 비교하였음
- 코드는 깃허브에 공개
5.1 Datasets
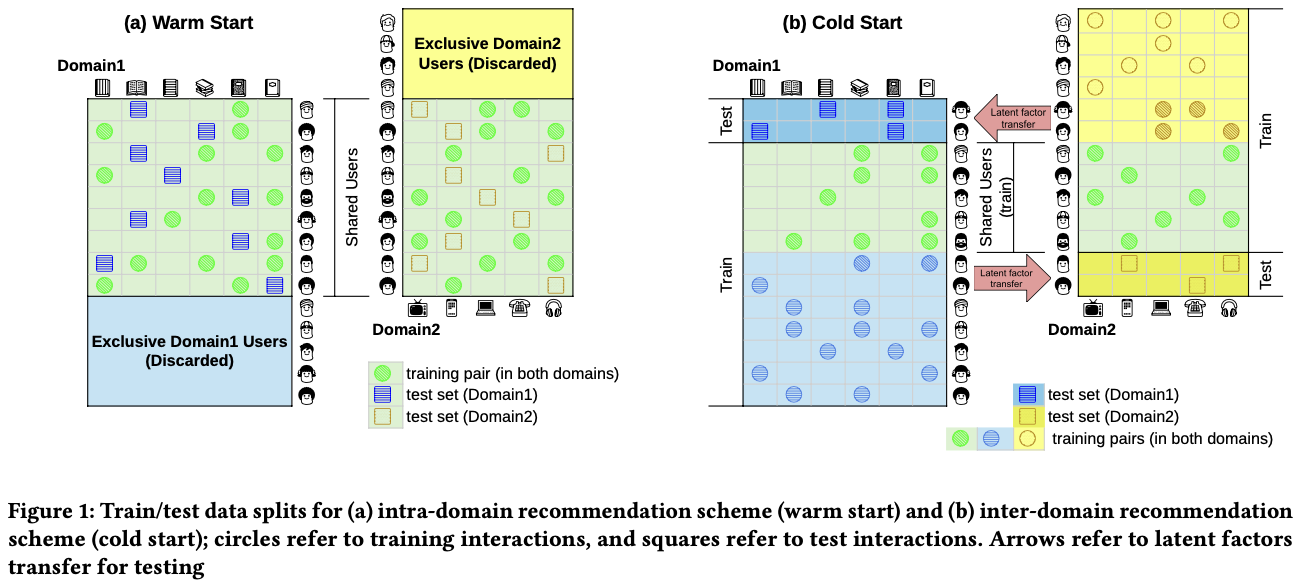
- Amazon 데이터셋 사용
- two cross-domain scenario : dual-intra-users, dual-inter-users
- 도메인 내의 추천 품질을 향상시키기 (warm-start problem, intra-domain rec) - Figure 1 left
- train/test 데이터셋 생성을 위해 공유되지 않은 사용자는 제거
- 각 사용자에게 하나의 아이템만 샘플링됨. (leave-one-out)
- 한 도메인에서 다른 도메인으로의 넘어가는 사용자에게 아이템을 추천 (cold-start problem, inter-domain rec) - Figure 1 right
- 공유된 사용자의 history는 한 쪽 도메인에서만 사용, 다른 도메인에서는 history 확인 불가
- 도메인 내의 추천 품질을 향상시키기 (warm-start problem, intra-domain rec) - Figure 1 left
- user : 5개 이상 아이템 상호작용, item : 10명 이상의 유저 상호작용만을 사용
5.2 Evaluation Method and Metrics
- 평가지표 : NDCG@10, HR@10
5.3 Baselines
- Single-domain baselines : BPRMF, NeuMF, NGCF, LightGCN
- Intra-domain CDR baselines : CoNet, DDTCDR, Bi-TGCF, DisenCDR, UniCDR
- Inter-domain cDR baselines : SSCDr, TMCDR, SA-VAE, CDRIB, UniCDR
6. RESULTS
- 이전의 baseline들과의 실험결과 비교
- CDIMF 내부의 하이퍼파라미터 차이 비교
6.1 Performance Comparison
Warm-Start
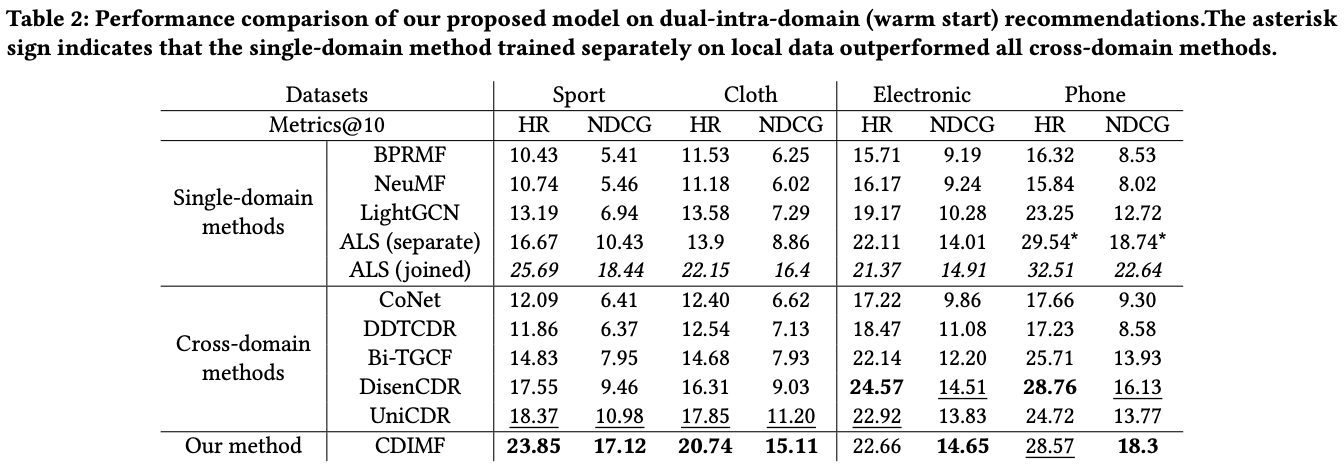
- 대부분의 실험에서 유의미한 결과를 보여줌
- HR@10에서는 top score를 달성하지 못했지만, NDCG@10에서는 top score를 달성했다.
- 단순히 맞히기만 하면 되는 HR보다 순위까지 고려하는 NDCG에서 top score를 달성한게 더 유의미함
- ALS(separate)가 일부 데이터셋(Phone)에서 다른 CDR baseline보다 높은 성능을 보임 → 도메인간 지식 전이가 무조건적인 성능 향상으로 이어지지 않음
Cold-Start
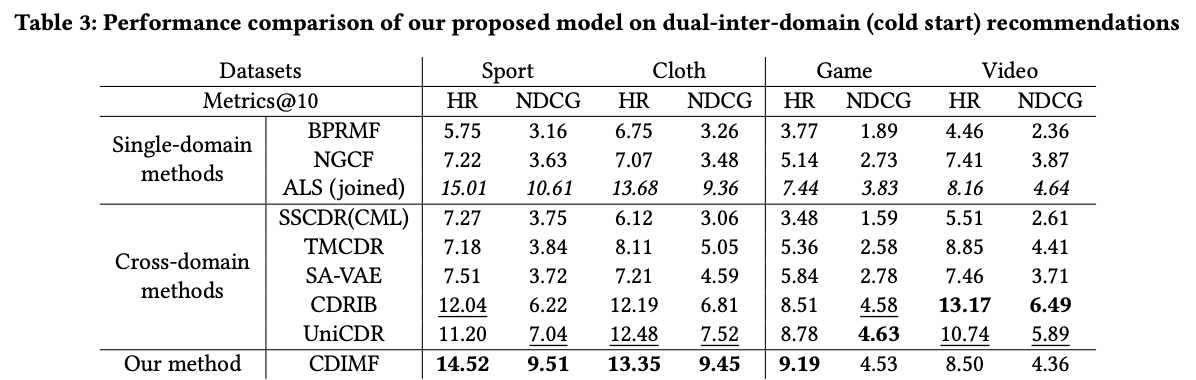
- 대부분의 실험에서 탁월한 성능을 보이고 있지만 warm-start 실험의 증가폭보다는 덜함
- ALS(jointed)가 Game-Video 실험에서 CD baseline과 CDIMF보다 낮은 성능을 보임
- 단순히 MF만으로 도메인간 연관성을 반영하는 것이 어려워보임
General Observation
- CDIMF가 혼합된 데이터셋으로 훈련한 ALS 모델에 비해 점수가 약간 낮음
- CDIMF는 cross-domain ALS의 변형버전임.
- ALS(joined)와는 달리 CDIMF는 도메인간 사용자 정보를 명시적으로 공유하지 않음 (ADMM 을 이용하여 implicit하게 사용자 정보 공유)
- single-domain method들이 cross-domain method와 competing performance를 보임
- 도메인 간 "Compatibility"를 평가하는 연구가 필요함.
- 즉, 어떤 도메인 쌍에서 Cross-Domain 학습이 유리한지 미리 판단하는 연구가 의미 있을 수 있음.
6.2 Hyperparameters Discussion
- ALS parameters
- penalty parameter : X와 Z를 얼마나 가깝게 유도할것인가. (k마다)
- proximal operator
- aggregation period
6.2.1 The effect of sharing parameter p
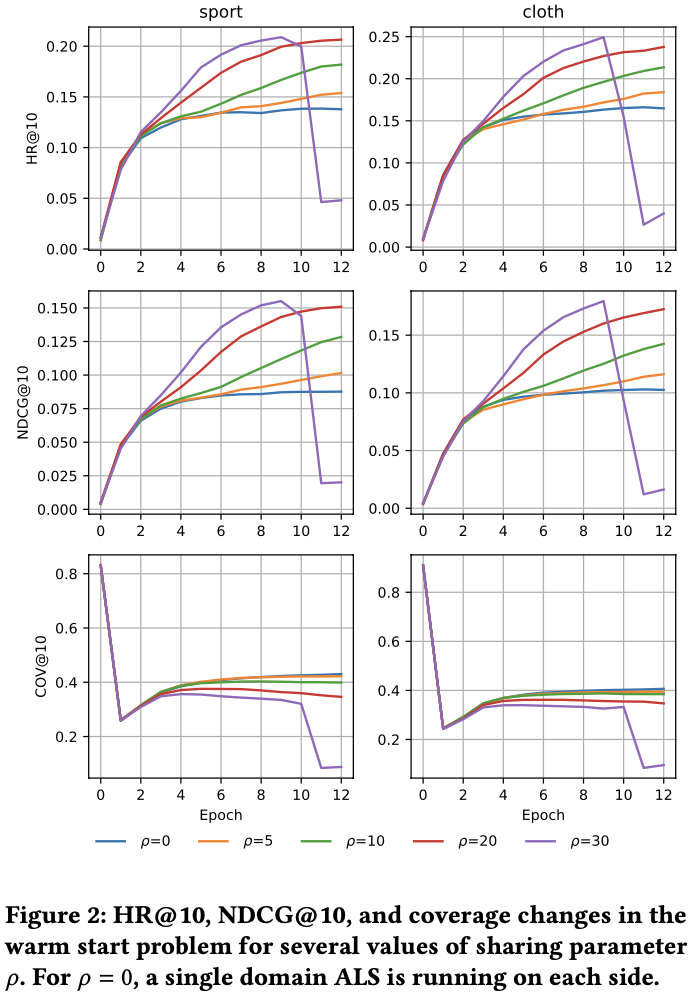
- p는 ADMM 과정에서 user latent vector X와 overlapped-user vector Z를 얼마나 가깝게 유지할 것인지를 조절함
- p가 CDIMF에서 학습률과 학습 속도를 조절한다.
- : 도메인간 공유를 하지 않음. → 각 도메인이 독립적으로 학습
- single-domain ALS와 동일함.
- : ADMM 최적화 과정 중 X를 Z에 더 가깝게 만들도록 강제
- 가 증가하면 X와 Z가 빠르게 정렬이 됨. → 도메인간 공유 정보가 빨리 학습 → Cross-domain knowledge 전이속도가 증가
- 가 너무 증가하면 모델이 수렴하지 못함 (Divergence)
- X가 Z와 일치하도록 강제되기 때문에, 특정 아이템 벡터들이 비정상적으로 커지는 문제 발생
- : 도메인간 공유를 하지 않음. → 각 도메인이 독립적으로 학습
6.2.2 The effect of proximal operator
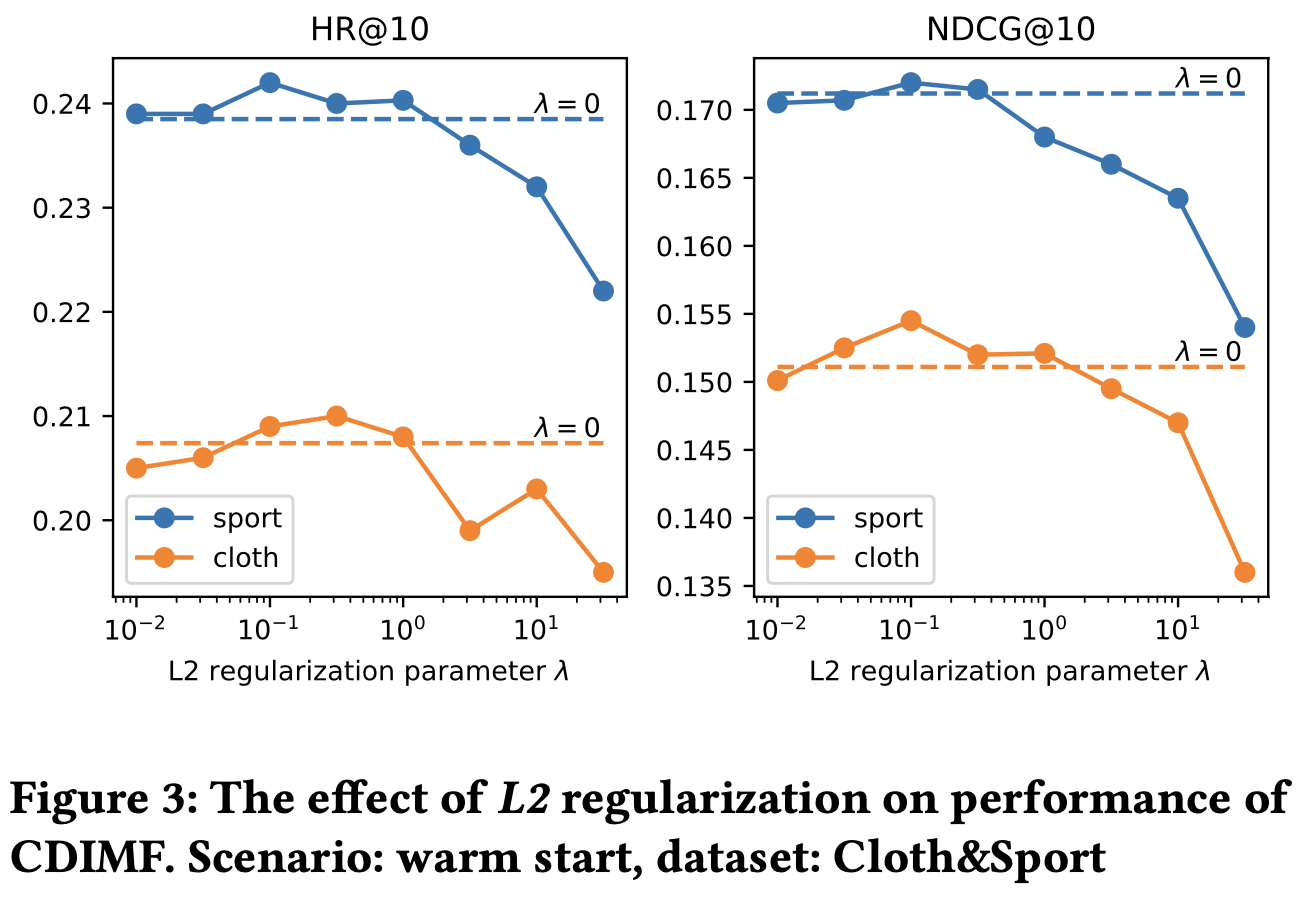
- proximal operator를 L2 정규화로 설정했을 때 성능 변화를 다루고 있음
- L2 정규화로 설정을 하게 되면 Z의 크기를 제한하여 과적합을 방지하고, 안정적인 학습을 유도하는 역할
- 하지만 실제로 실험한 결과 의 값을 변화시켜도 성능 증가폭은 미미함
- hyperparameter tunning이 오래걸리고 최적의 값을 찾더라도 증가폭이 미미하기 때문에 proximal operator는 identity operator로 사용
6.2.3 The effect of aggregation period
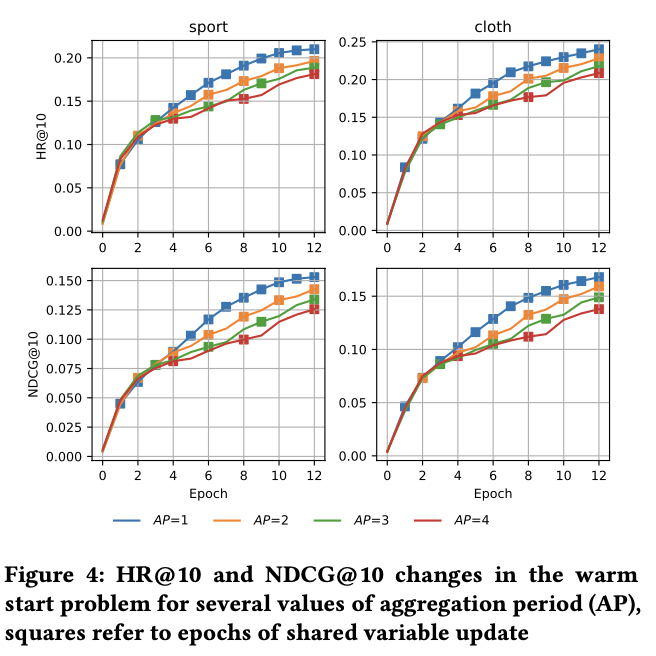
- CDIMF는 ALS를 통해 X를 한 번 최적화한 다음 ADMM을 통해 X, Z, U를 다시 한 번 최적화함.
- 이 주기를 AP(Aggregation Period)라고 함. AP 주기를 짧게할수록 모델의 성능이 빠르게 향상이 되지만, communication load가 증가하는 trade-off 관계가 발생
- AP 주기를 길게 가져가면 Z가 느리게 업데이트 되어 communication load는 줄일 수 있지만, 학습 속도가 느려짐
- 비동기방식으로 Z를 업데이트해도 이전의 Z 값으로 ALS를 실행하기 때문에 성능은 유지시킬 수 있음
6.3 Privacy Considerations
- 도메인간 정보를 공유할 때 직접 X를 공유하지 않고, ADMM을 이용하여 암시적으로 공유()하기 때문에 사용자의 개인정보를 보호할 수 있음.
7. CONCLUSION
- 저자가 제안한 모델인 CDIMF는 대부분의 경우에 SOTA CDR 모델을 뛰어넘는 성능을 보임
- Key Advantage : competitive performance와 computational efficiency
- dual-domain 환경에서 실험을 진행했지만 multi-domain 환경에서 또한, 약간의 조정으로 뛰어난 성능을 보일 것으로 보임
