DisenCDR: Learning Disentangled Representations for Cross-Domain Recommendation
Cross Domain Recommendation
JiangXia Cao at al
SIGIR 2022
ABSTRACT
- domain-specific information은 target-domain의 추천 품질 향상에는 쓸모가 없음
- domain-shared, domain-specific information을 직접 aggregating 하는 것은 target-domain의 성능에 안좋음 ⇒ CDR의 핵심 challenges
- 저자들은 domain-shared, domain-specific information을 분리(Disentangle)하는 모델, DisenCDR을 제안함
- Disentangle regularizer
- Exclusive regularizer
- Information regularizer
1. INTRODUCTION
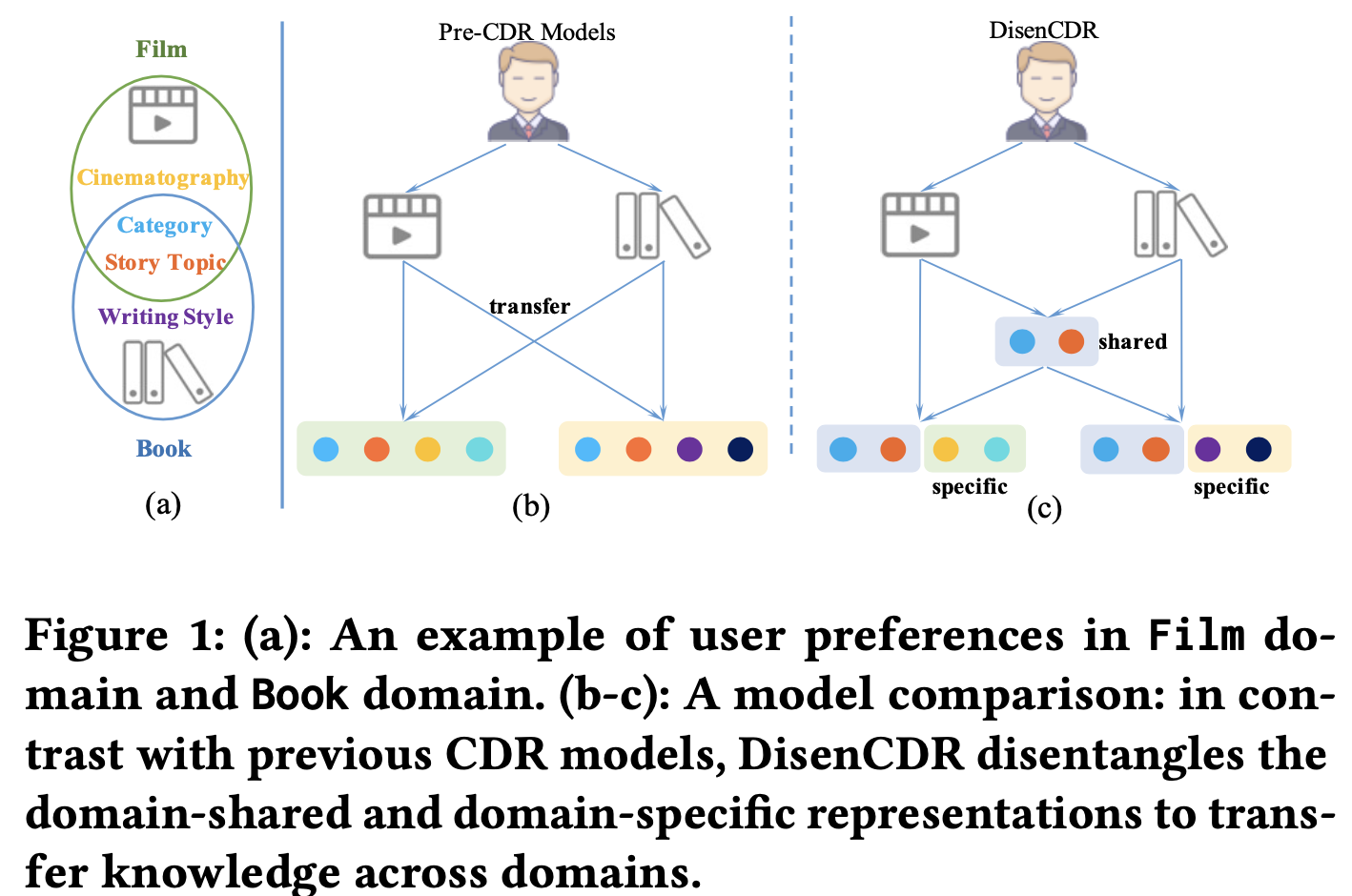
- CoNeT: MLP를 base encoder로 사용
- DDTCDR: latent orthogonal mapping function을 학습시켜, CoNeT을 확장
- PPGN: GCN을 여러층으로 쌓아 유저간 유사도를 전달
- BiTGCF: 각 도메인의 interaction information aggregator로 LightCGN을 사용 + function transger layer를 추가
⇒ domain-shared, domain-specific information을 분리하는데 중점을 두지 않아, 모델의 전송 효과에 한계가 있다. negative transfer 문제가 있지만, 기존의 CDR method는 이를 무시함
- DisenCDR은 세 가지 분리된 representation을 학습함
- One domain-shared representation
- Two domain-specific representations
- 세 가지 representation을 얻기 위해 아래의 세 가지를 제안
- VBGE (Variational Bipartite Graph Encoder)
- Exclusive regularizer: domain-shared, specific representation에 각 역할을 충실히 하도록 해줌, 분리에 집중
- informative regularizer: domain-shared representation이 의미있도록 충분히 값을 넣어줌, 제역할을 다하게 만들어줌
- domain-shared, specific information을 잘 분리해서 shared information만을 도메인간에 전달
2. PROBLEM DEFINITION
- 도메인 X, Y 구성
- X, Y interaction matrix
- Domain-Shared Representation
- Domain-X-Specific, Domain-Y-Specific User Representation
- Domain-X-Specific, Domain-Y-Specific Item Representation
3. METHODOLOGY
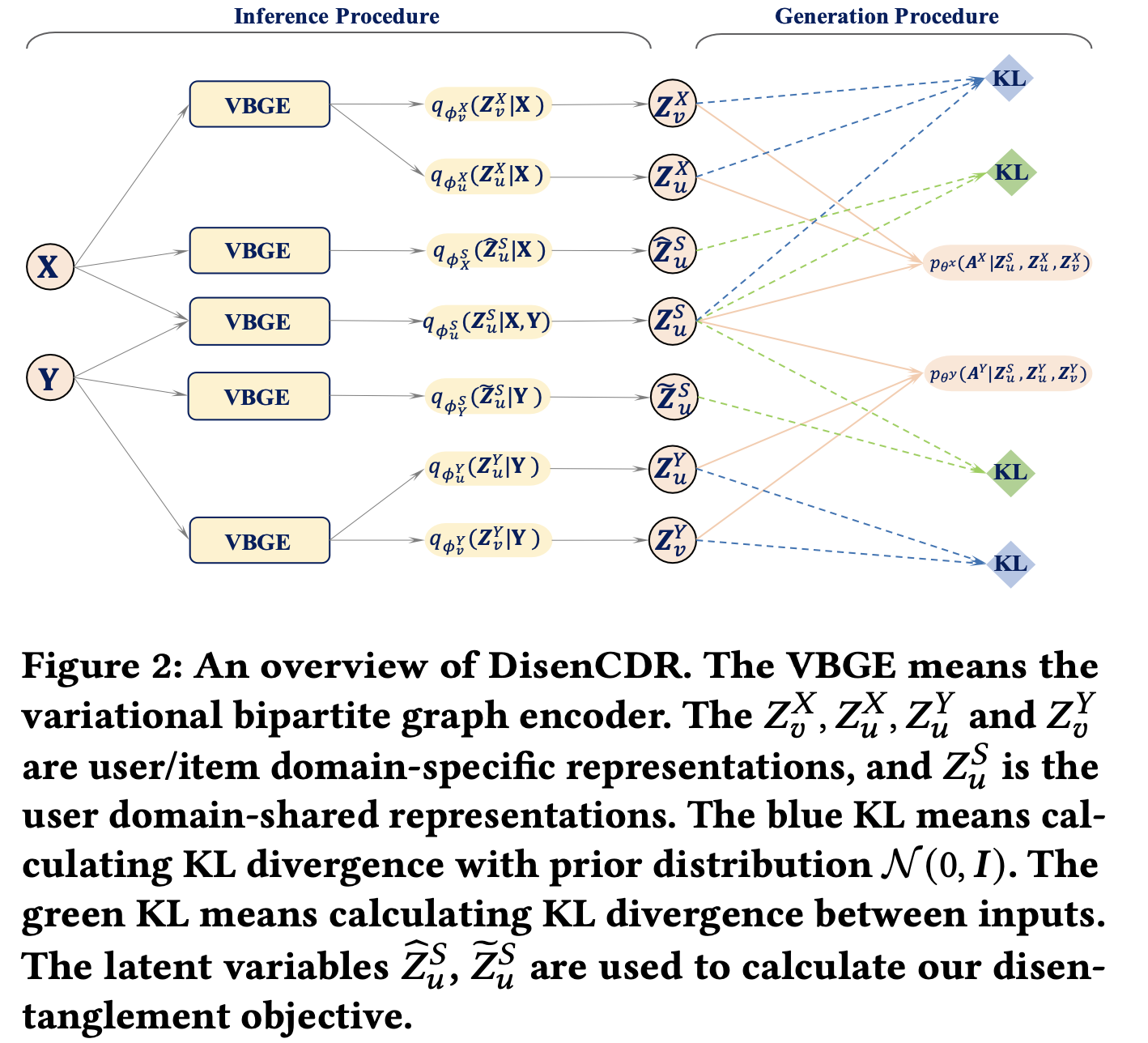
- DisenCDR overview
- Inference Procedure
- 도메인들에서 shared, specific information을 분리해내(Disentangle) representation으로 encoding 하는 단계
- VBGE (Variable Bipartite Graph Encoder)를 이용하여 도메인의 user, item 임베딩에서 어떤 정보들이 domain-shared, specific-user, specific-item에 들어가야 하는지를 구분지음 (approximate posterior)
- Generation Procedure
- Disentangled domain-shared, specific representation을 decoding하여 observed interaction을 잘 복원하는 단계
- exclusive, informative regularizer로 인해 representation이 잘 분리된 상태를 유지하도록 함
3.1 Embedding Layer
- user와 item을 저차원 벡터 공간으로 임베딩
- : Domain-shared initialized embedding matrix
- : Domain-X-Specific, Domain-Y-Specific initialized embedding matrices
- : Two item sets in domain X and Y
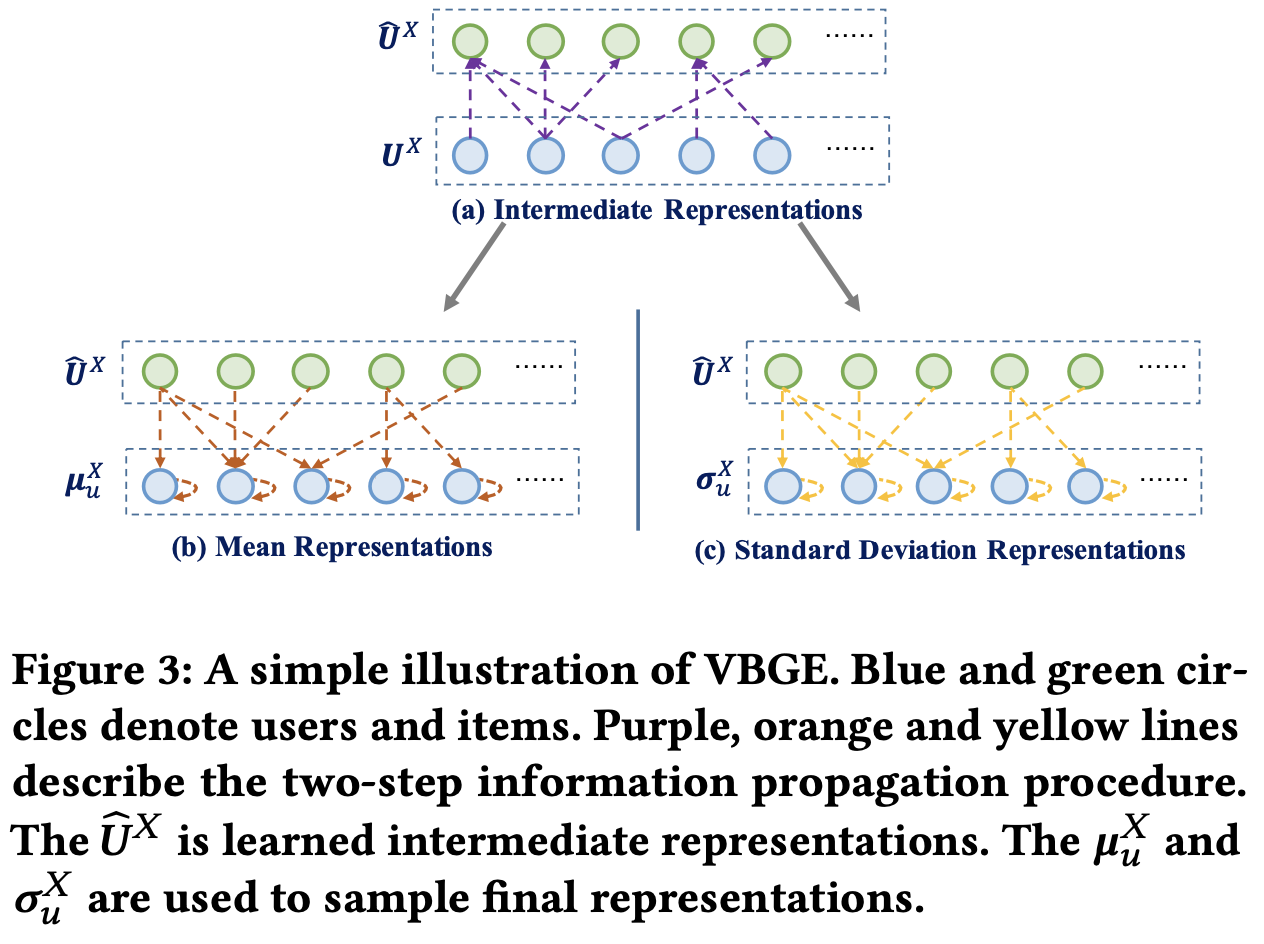
3.2 Variational Bipartite Graph Encoder
Domain-Specific Representation
- user-item interaction graph는 heterogeneous bipartite graph임
- 2-hop 관계의 유저 임베딩을 얻어낸 후, 이를 활용하여 도메인 특화 표현을 만들어낼 수 있음
- Intermediate Representation (user → item → user)
-
: LeakyReLU
-
: 2-hop 관계의 유저들의 representation
-
Domain-X-Specific representation
-
: concatenation operation
-
: Softplus function
-
: 평균, : 표준편차 (가우시안 분포)
-
는 로 샘플링한 확률값이기 때문에, 역전파가 불가능
-
Reparameterization trick of VAE (Variational Auto Encoder)
- 확률값을 담고 있는 를 학습 가능한 파라미터로 만들기 위해 VAE를 이용
⇒ 이 방법을 이용하여 Domain-X-Specific User Representation, Domain-X-Specific Item Representation, Domain-Y-Specific User Representation, Domain-Y-Specific Item Representation 을 구할 수 있음
Domain-Shared Representation
- VBGE는 도메인간 상호작용을 이용하여 domain-shared representation도 만들어낼 수 있음
3.3 Generation and Inference
- VAE 관점에서 DisenCDR은 도메인 X, Y에서의 user-item상호작용을 shared, specific으로 잘 분리해내어 학습(Inference), 이를 joint distribution 를 정확하게 잘 복원하는 것(Generation)을 목표로 함.
- VAE Encoder: Inference / Decoder: Generation 구조
3.3.1 Generation Procedure
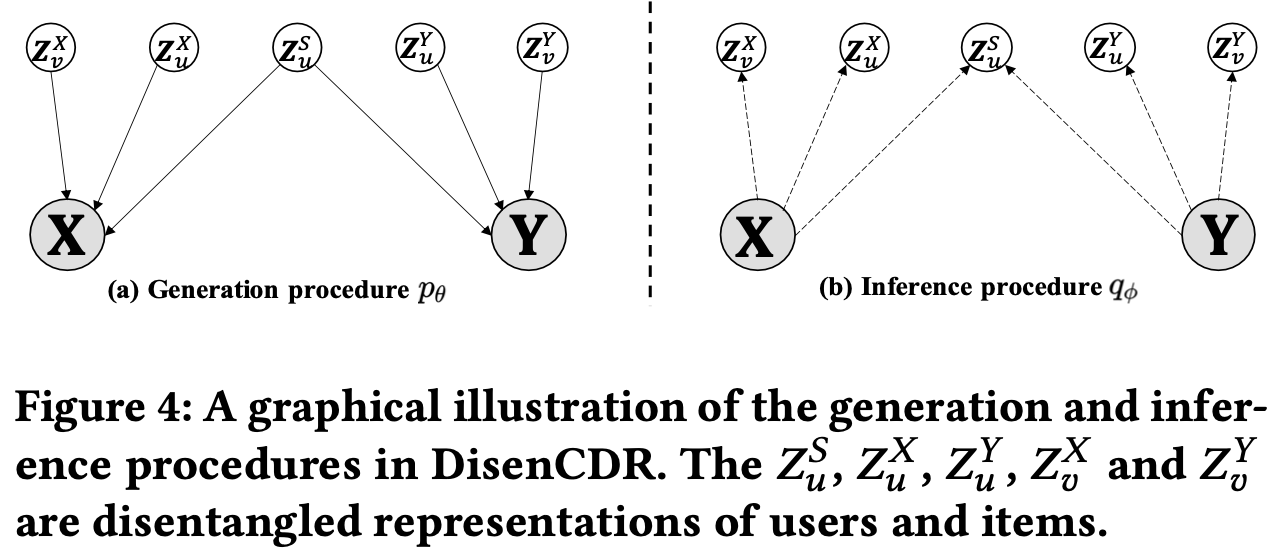
수식이 복잡하지만 목적은 분리한 표현을 이용하여 본래 상호작용으로 복원하는 것이 목표
- Prior distributions:
-
가우시안 분포로 설정
-
Decoders:
-
Decoder 는 관찰된 상호작용인 를 복원하는 것이 목표
- : Score function, MLP와 다양한 score function이 있지만 저자는 빠른 학습 속도를 위해 inner product를 사용
-
3.3.2 Inference Procedure
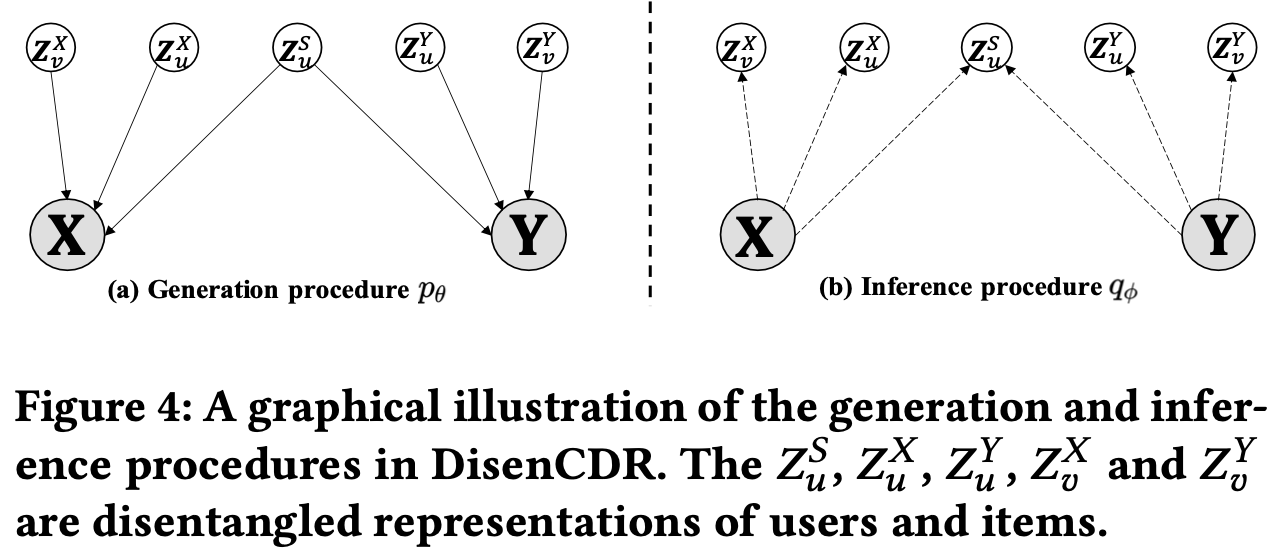
- , Posterior distribution을 직접 구하는 것은 매우 어려움 → Amortized Inference를 통해서 Posterior를 신경망을 통해 근사해내는 방법을 사용
- : Amortized Inference를 위한 학습 파라미터 → VBGE가 이를 학습함
- 수식 (7)은 형식적으로 domain interaction을 분리만 한 것이지, 각각의 파라미터에 실제로 잘 분리되어 값이 들어가는지는 보장할 수 없음 → Exclusive, Informative regularizer의 필요성
3.4 Disentanglement Objective
- Ideal Domain-Shared, Specific representation은 mutual exclusive 해야함 → Regularizer를 고안
- 이해를 돕기 위한 two mutual information definition을 소개
-
Definition 3.1. Conditional Mutual Information
-
Definition 3.2. Interaction Information
-
3.4.1 Exclusive regularizer
- domain-shared, specific representation에 겹치는 값이 들어가지 않도록 도와주는 regularizer → 잘 분리하게 도와주는 regularizer
- Minimize mutual information between domain-shared, specific representation
- Minimize
- : domain-specific representation만 보았을 때, X의 내용이 얼마나 담겨있는지
domain-X-specific representation은 X에 특화된 정보를 담은 표현인데, 왜 최소화 되어야 하는지 이해가 안감
조사한 결과 ⇒ 해당 표현은 X에 특화된 정보만 담아야 함. 즉, shared information은 들어가면 안됨. 그래서 이런 표현을 사용한 것으로 생각이 됨. - : domain-shared representation만 보았을 때, X의 내용이 얼마나 담겨있는지
- : domain-specific representation만 보았을 때, X의 내용이 얼마나 담겨있는지
- Maximize
- : domain-specific, shared representation을 더했을 때, X의 내용이 얼마나 들어있는지
- Exclusive regularizer로 충분히 disentangled representation을 얻지 못함. ⇒ domain-shared representation의 정보가 충분하지않더라도 분리시킬 수 있기 때문 → informative regularizer를 고안
3.4.2 Informative regularizer
- domain-shared representation에 충분한 정보를 담아주기 위한 정규화기법
- 를 최대화 해야함
-
Maximize
- : X만 보더라도 X-Y간의 공유 정보를 잘 담고 있어야 함.
-
Minimize
- : 두 값이 같아져야함. 즉, 다른 도메인 없이도 공유 정보를 잘 담고 있어야 함.
3.4.3 Objective Function
- 도메인들로부터 분리된 표현을 얻기 위한 최종 목적 함수
ELBO ?
목적함수의 근사식의 최대값을 통해 문제를 해결하는 방식
- ELBO 항: 수식 (12)의 많은 항들이 ELBO에 나타남 / KL divergence에서 측정할 수 있음
- decoding 항은 observed interaction을 복원하는 것을 목표로 함. → log-likelihood를 최대화하여 측정
- : 도메인 X, Y의 공유 정보를 최대한 많이 담아야 하는 항
- 두 개의 VBGE를 더 사용해서 를 계산, KL divergence를 계산해야한다. (Informative regularization)
- Algorithm

- Embedding layer 및 VBGE 초기화
- domain-shared, specific user representation 생성
- domain-shared, specific item representation 생성
- 만들어진 representation을 샘플링 후, 미니배치 추출 (실제값)
- representation을 decoding하여 실제값과 비교하며 손실 계산
- informative 정규화 항 계산
- 손실함수에 대입하여 전체적인 손실을 줄인 후, 파라미터 업데이트
- (수렴때까지 위 과정을 반복 2-7)
- domain-share, specific representation return
3.4.4 Time Complexity
- DisenCDR은 미니 배치 방식을 사용하여 최적화 됨
- Inference Procedure:
- Generation Procedure:
4. EXPERIMENTS
- 4가지에 대해서 실험할 예정
- RQ1: 다른 SOTA 모델들을 능가하는 성능을 보여주는가
- RQ2: Disentanglement가 성능 향상에 영향을 미치는가
- RQ3: 제대로 Disentanglement가 이뤄졌는가
- RQ4: 하이퍼파라미터에 따른 결과가 어떤가
4.1 Datasets
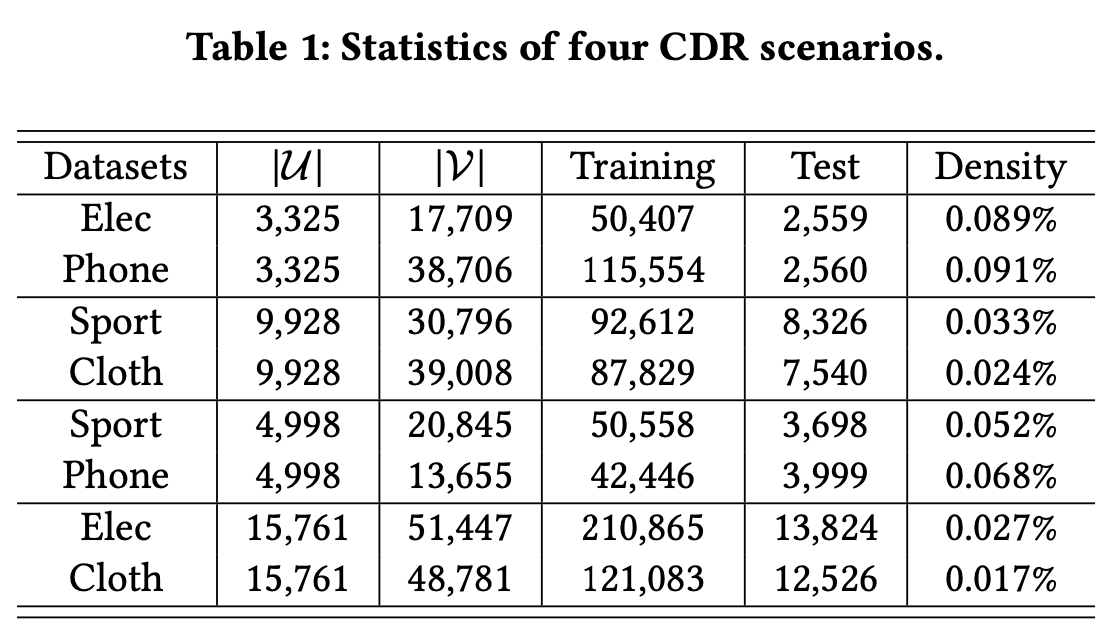
- Amazon dataset: Elec-Phone, Sport-Cloth, Sport-Phone, Elec-Cloth
4.2 Experiment Setting
4.2.1 Evaluation Protocol
- Leave-One-Out (1-999)
- HR, NDCG@10
4.2.2 Compared Methods
- Single-domain methods: BPRMF, NeuMF, NGCF, LightGCN
- Cross-domain methods: CDFM, CoNet, DDTCDR, PPGN, BiTGCF
4.2.3 Implementation Details (100 Epochs)
-
Embedding dimension: 128
-
Mini-batch size: 1024
-
Learning rate: 0.001
-
L2 regularization coefficient: 0.0005
-
Dropout: 0.3
-
Graph encoder: 1~4
-
Negative sampling: 1
-
Loss: Cross entrophy
-
Optimizer: Adam
-
LeakyReLU: 0.1
-
: {0.1, 0.3, 0.5, 0.7, 0.9}
4.3 Performance Comparison (RQ1)
- 다른 SOTA 모델들보다 성능이 좋은가
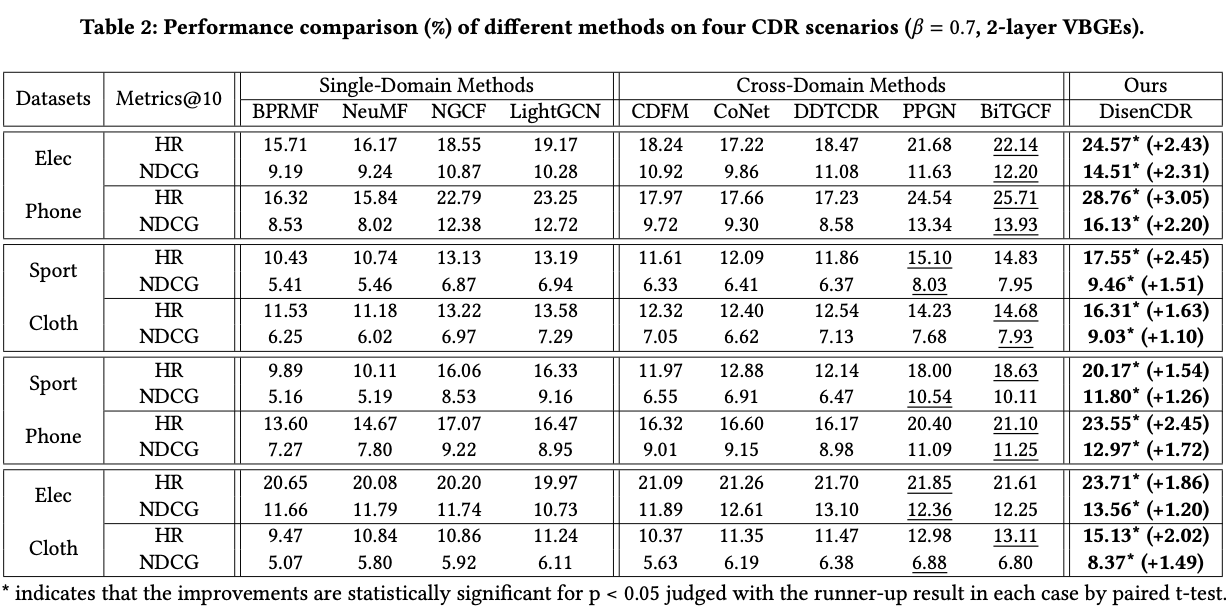
- SOTA 모델에 비해 DisenCDR이 최고의 성능을 보였음 → disentangled repesentation을 학습하고, domain-shared 정보를 전이하는 것이 성능 향상에 큰 도움이 되었음을 입증
4.4 Discussion of Model Variants (RQ2)
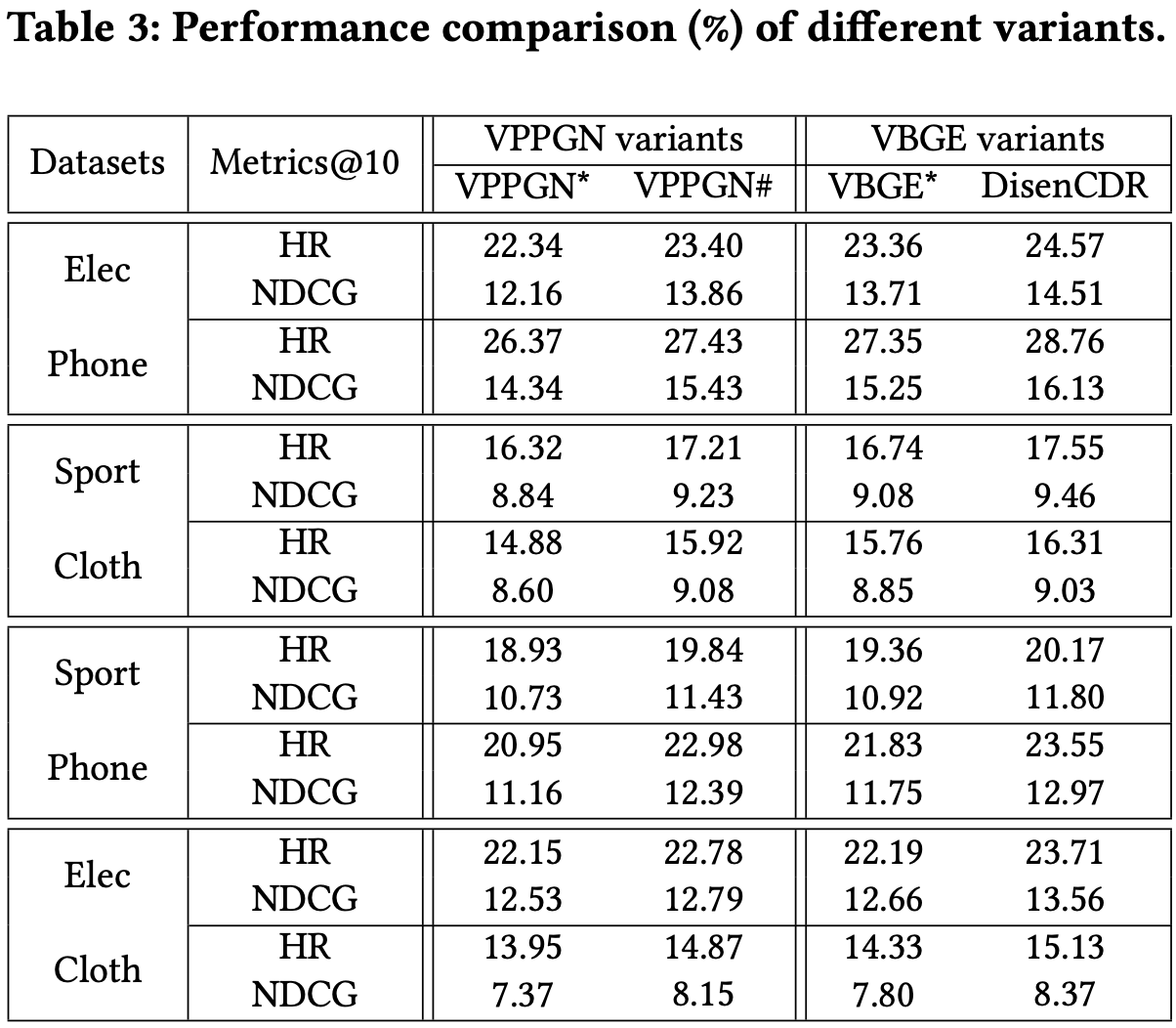
- Disentanglement가 성능향상에 영향을 미치는가
- 이를 평가하기 위해 VBGE를 VPPGN (DisenCDR에 PGN을 적용)으로 대체하여 학습 후 두 모델을 비교하였음
- VPPGN*: Standard ELBO
- VPPGN#: Disentanglement objective
- VPPGN#이 BiTGCF를 뛰어넘음 → 두 개의 다른 인코더 (Inference, Generation) 전략이 효과적이다
- VPPGN#이 VPPGN*보다 안정적인 성능 향상을 보임 → 저자가 제안한 목적함수 (Inference, Generation)이 user domain-shared representation 학습에 유용함을 입증
- VBGE가 VPPGN보다 robust한 성능을 보여줌 → VBGE가 user간의 정보만 학습하기 때문임
- 저자들이 제안한 Disentanglement objective가 효과가 있음
4.5 Analysis of Disentanglement (RQ3)
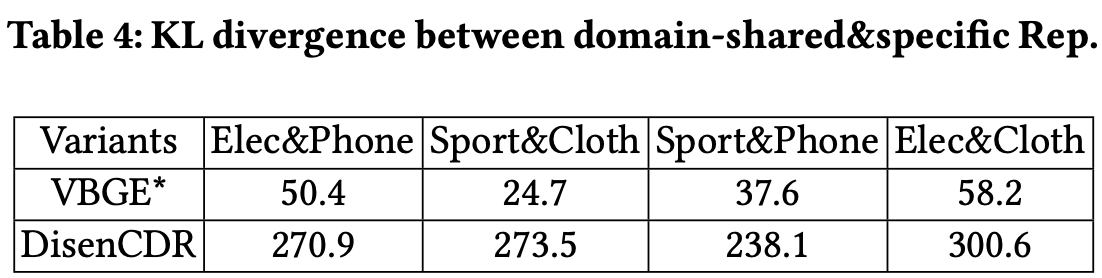
- 제대로 Disentanglement가 이뤄지는가
-
DisenCDR과 VBGE* (Standard ELBO)를 분석하였음
- Mutual information을 측정하는 KL divergence의 평균을 계산
- DisenCDR의 KL이 더 높게 나옴 → domain-shared, domain-specific representation을 더 잘 분리함을 입증
-
VBGE* (Standard ELBO)와 DisenCDR을 비교하였음
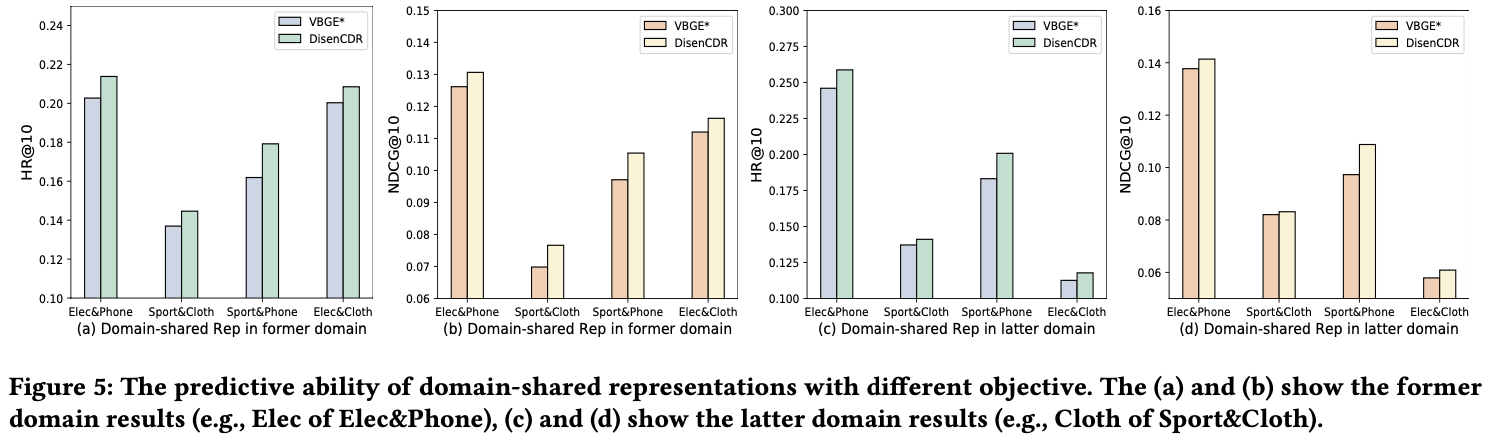
-
domain-shared representation만 사용
-
DisenCDR의 성능이 전부 좋음
→ Disentanglement objective가 domain-shared representation을 더 잘 학습함
-
Observed interaction의 수에 따른 목적함수의 효과성을 분석함
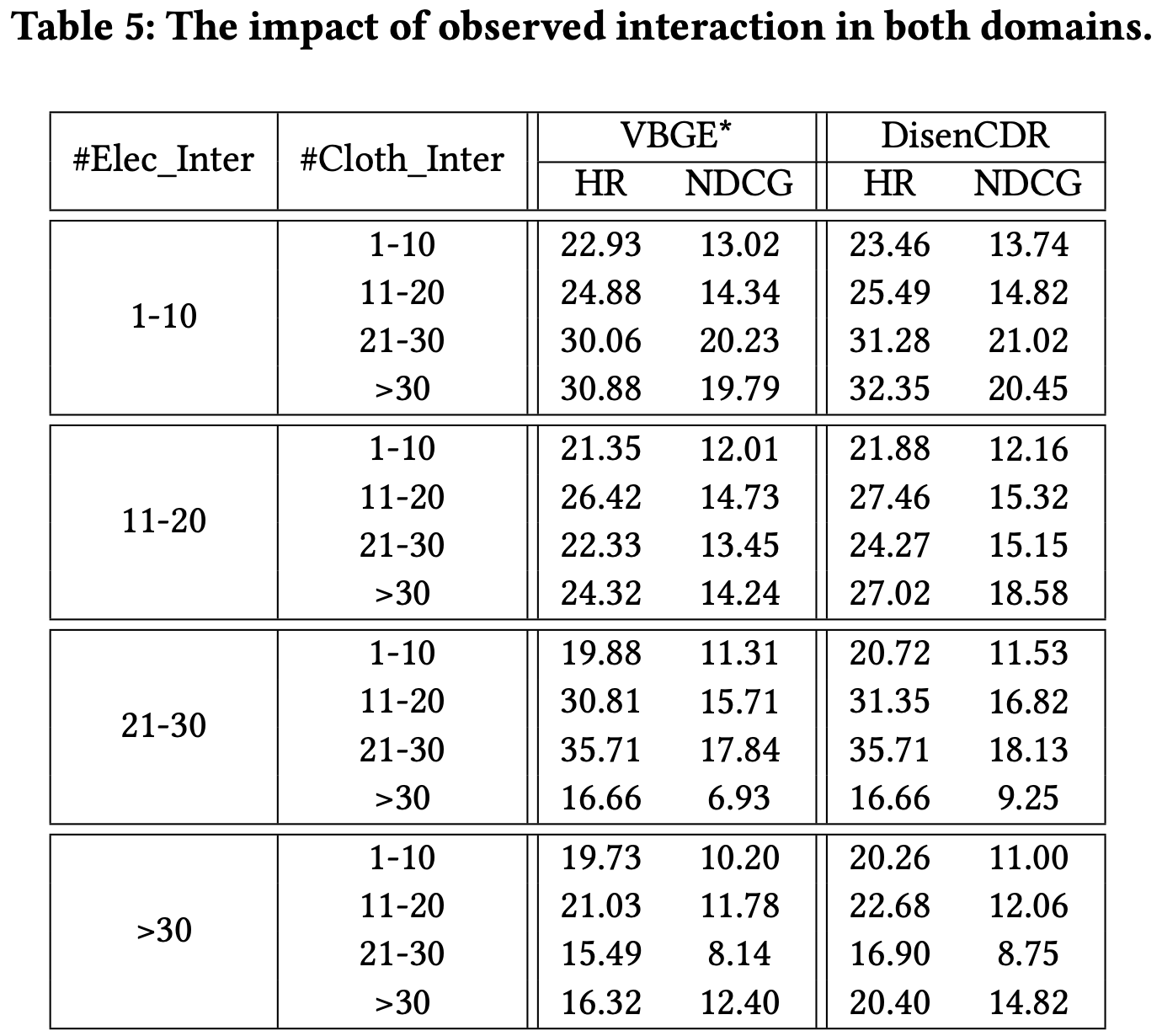
- Elec: target domain, Cloth: source domain으로 가정
- Elec의 interaction 수가 적더라도 Cloth의 상호작용이 많을수록 추천성능이 좋아짐 → Cloth의 풍부한 정보가 domain-shared representation으로 잘 학습되어 Elec의 sparse 문제를 해결함
- DisenCDR이 VBGE*보다 전반적으로 성능이 좋음 → Standard ELBO보다 shared information을 더 잘 추출하기 때문임
-
4.6 Parameter Sensitivity (RQ4)
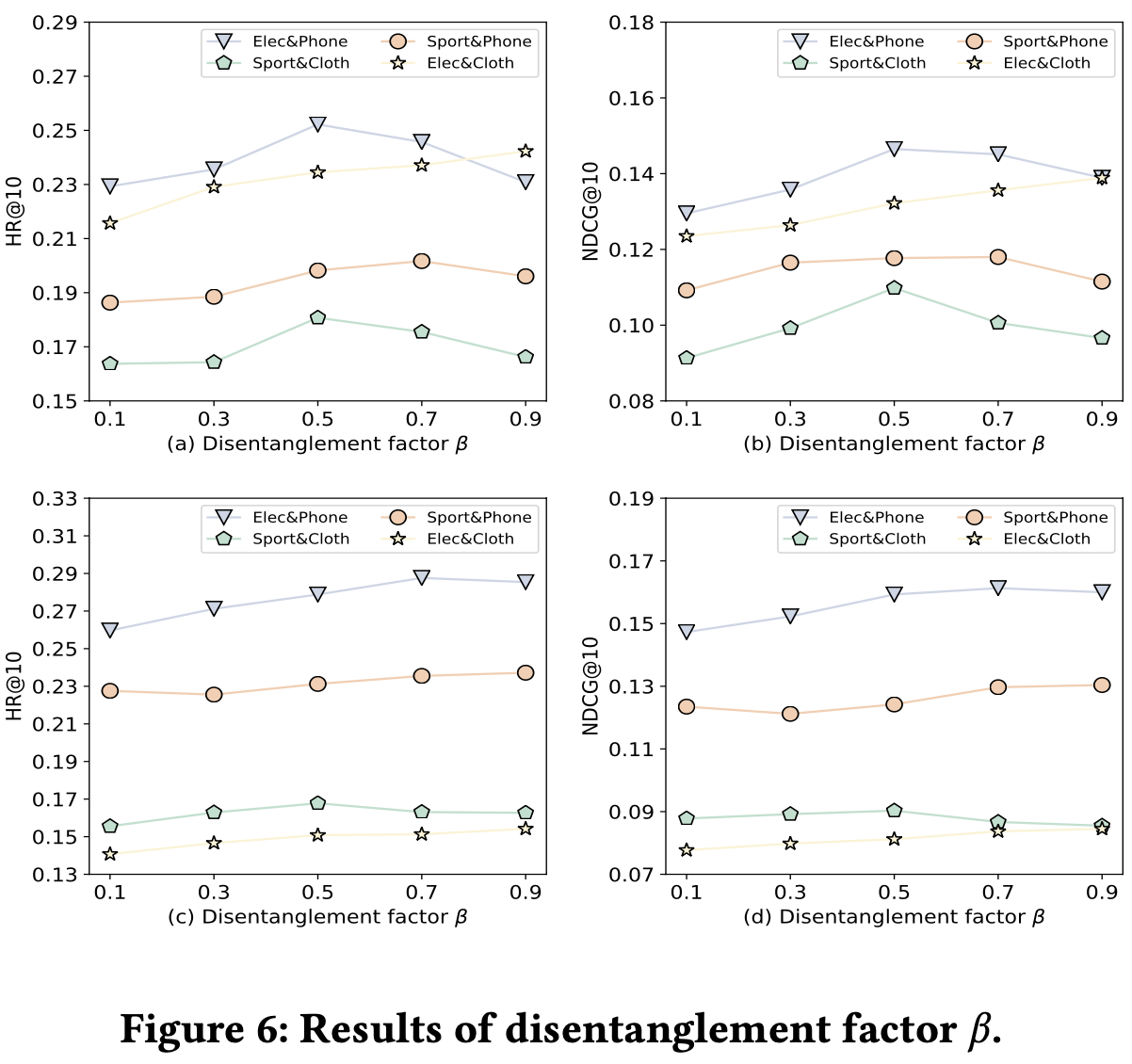
- 하이퍼파라미터에 따른 결과가 어떤가 (Disentanglement parameter , VBGE layer number)
- Disentanglement 강도를 조정하는 정규화 파라미터 에 따른 성능을 분석
- interaction scenario가 클수록 를 크게 설정할 수 있음을 발견 → larger interaction scenario일수록 domain-specific information이 더 많기 때문에 강하게 분리를 해줘야 함.
- VBGE의 레이어 수에 따른 결과를 분석하였음
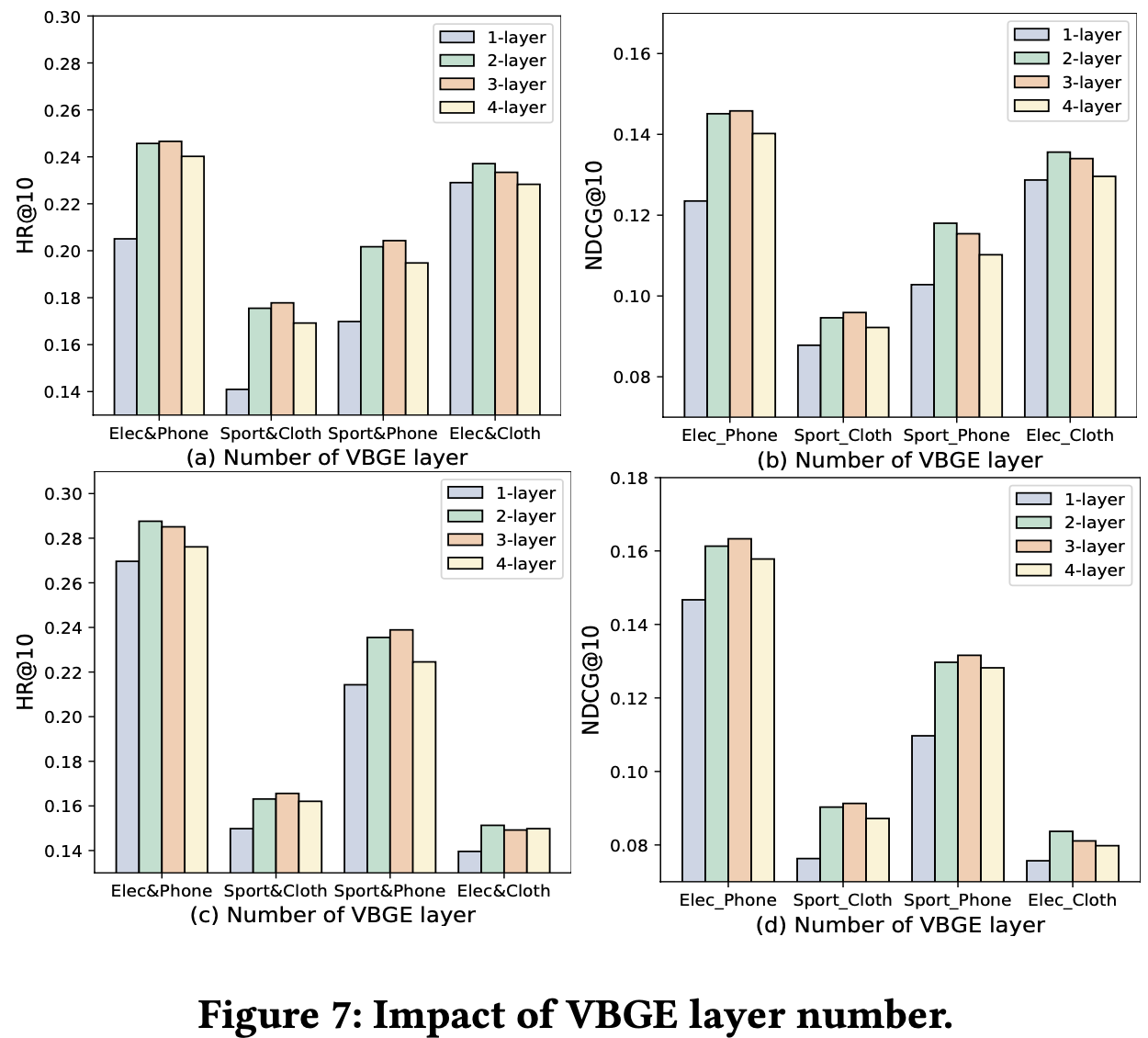
- 2-3개의 레이어를 사용하는 것이 가장 좋은 성능을 보임 → 더 늘리면 over-smoothing problem 발생해서 떨어짐
- 2-3개의 레이어를 사용하는 것이 가장 좋은 성능을 보임 → 더 늘리면 over-smoothing problem 발생해서 떨어짐
6. CONCLUSION
- 저자가 제안한 DisenCDR은 exclusive regularizer를 이용하여 domain-shared, specific representation을 잘 분리할 수 있고, informative regularizer를 이용하여 domain-shared representation에 최대한의 도메인 공유 정보를 담기 떄문에 추천을 더 잘해줌
- 실험을 통해 증명을 했으며 multi-domain recommendation을 위한 learning disentanglement representation을 분석 할 예정임
💡
- DisenCDR은 현재 대부분의 CDR 논문에서 등장하는 shared, specific 정보를 분리하는 것을 다루는 방법을 기술적으로 잘 풀어낸 논문임
- Overlapped user를 이용한 데이터셋을 이용하므로 practical한 상황에 잘 적용시킬 수 있을지는 모르겠음
