EDDA: Multi-domain Recommendation with Embedding Disentangling and Domain Alignment
Cross Domain Recommendation
Wentao Ning at al
CIKM (2023)
ABSTRACT
- 존재하는 MDR(Multi-Domain Recommendation)은 두 가지 challenge를 가지고 있음
- knowledge를 분리하는 것이 어려움
→ 도메인간 일반화되는 지식 (Domain-Shared), 한 도메인에 특정한 지식 (Domain-Specific) - 적은 overlap 환경에서는 도메인간 지식 전이가 어려움
- knowledge를 분리하는 것이 어려움
- 저자는 새로운 MDR method인 EDDA를 제안
→ 두 가지 Key components (Embedding disentangling recommender + Domain alignment)
- Embedding disentangling recommender: Inter-domain part / Intra-domain part로 분리하고 모델링
→ 기존의 모델들은 model-level의 분리에만 집중했음
- Domain alignment: 랜덤워크 기법을 통해서 비슷한 사용자/아이템 쌍을 식별한 다음 비슷한 사용자/아이템 쌍이 비슷한 임베딩을 가지도록 alignment
1. INTRODUCTION
- MDR의 두 가지 challeges
- 추천 결과에 negative impact를 피하면서, 다른 도메인으로부터 유용한 정보를 활용하는 것이 어렵다.
→ inter-domain knowledge와 intra-domain knowledge를 구분해야한다. - sparsity overlap일 때, 도메인 사이에서 knowledge transfer가 어렵다.
→ overlap user, item은 도메인간 지식 전이에서 bridge로 사용이 됨.
- 추천 결과에 negative impact를 피하면서, 다른 도메인으로부터 유용한 정보를 활용하는 것이 어렵다.
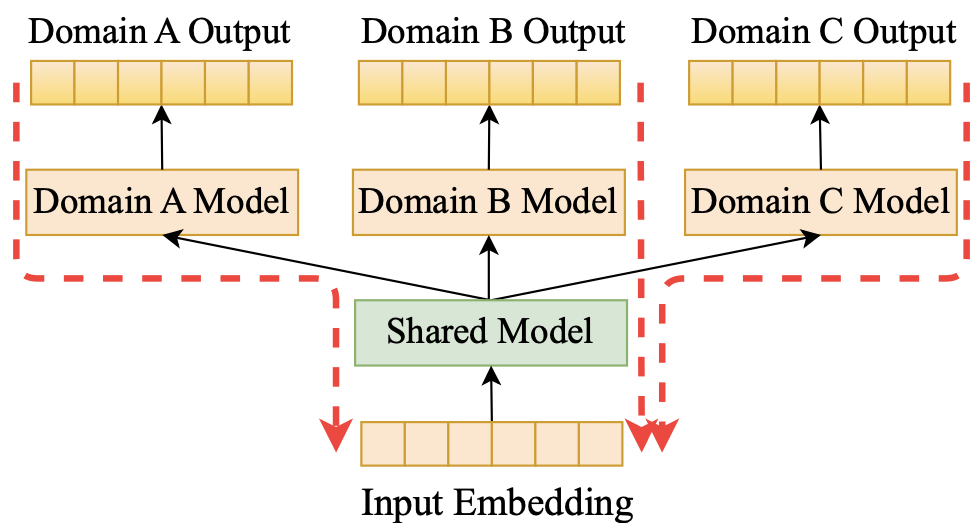
- 존재하는 대부분의 MDR methods는 domain-shared, specific information을 학습하는 두 모델을 두고 두 모델을 개선시키는 방식이다
-
STAR는 FCN(Fully-Connected Network)를 이용하여 shared, specific model을 만든다
-
TreeMS는 GAT를 이용해 shared model, FCN과 LSTM을 결합하여 specific model을 만든다
⇒ 모델은 분리해서 두 개를 사용하지만, user / item 임베딩은 단일 벡터를 사용
Gradient Conflict problem 발생
→ 두 모델에서 각각 shared, specific information을 학습 중 shared, specific information을 반영하기 위해 gradient가 다르게 적용이 됨
→ 하지만 gradient가 반대로 적용되는 경우, 상쇄되어버리기 때문에 최종 임베딩에 두 정보가 제대로 반영이 안될 수 있음
-
- Overlapping users / items에 의존하여 knowledge transfer를 수행하기 때문에 효과적인 knowledge transfer mechanism이 필요함
- 저자들은 MDR의 새로운 method인 EDDA를 제안
- ED(Embedding Disentangling) recommender + Domain Alignment
- ED recommender: Negative transfer problem을 방지하면서 다른 도메인의 knowledge를 활용
- random walk를 기반으로 한 domain alignment를 하여 다른 도메인으로부터 유사한 user / item pair를 식별함
- ED(Embedding Disentangling) recommender + Domain Alignment
2. PROBLEM DEFINITION
- Domain d
R은 user-item interaction set인데 논문에 clicks, purchase라고 기재되어있어 explicit, implicit data 모두 반영하는 거 같음
- MDR D
3. ED RECOMMENDER
- Negative transfer problem을 방지하고 각각의 도메인을 보완하기 위해 ED recommender를 제안
3.1 ED Architecture
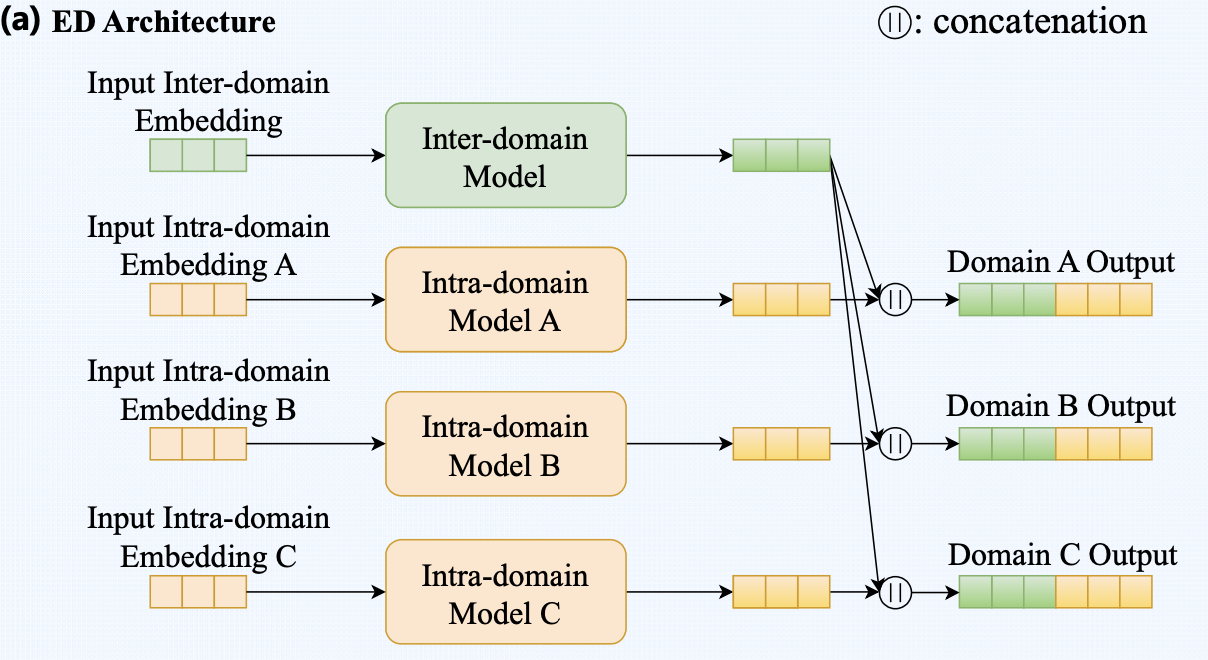
- user / item에 대한 두 개의 임베딩을 활용 (inter-domain, intra-domain embeddings)
→ 두 임베딩은 inter-domain, intra-domain model에 의해 각각 학습됨 - user 와 item 는 intra-domain embedding 와 inter-domain embedding 를 가짐
- Inter-domain model 와 Intra-domain model 를 가지고 있음
- Intra-domain representation
- Score function
-
Inner product를 사용하여 score 계산
-
Training
- Intra / Inter-domain embedding을 랜덤으로 초기화한 후, BPR loss를 사용
- : 도메인 훈련 데이터 샘플
- : observed user-item interaction, positive pair
- : unobserved user-item pair, negative pair
-
Discussion: gradient flow 관점에서 ED architecture는 intra-domain, inter-domain 파트가 분리되어 있어 간섭없이 학습이 가능함
- 학습과정 및 gradient 업데이트 과정
- 데이터셋을 학습용 데이터로 사용
- Inner-product를 이용한 score function을 BPR loss를 이용해 학습 (positive sample은 높은 점수, negative sample은 낮은 점수)
- 역전파로 인해 Inter-domain model , Intra-domain model 가중치 업데이트
- Inter-domain, Intra-domain embedding 업데이트 (user case)
- Inter-domain embedding은 모든 도메인의 triplet으로 업데이트됨
- Intra-domain embedding은 해당 도메인 에 속하는 triplet으로만 업데이트됨
- Inter-domain, Intra-domain embedding이 다른 데이터로 학습된다는 것을 증명하기 위해 t-SNE를 이용해서 임베딩을 2차원으로 축소시켜 시각화를 진행함
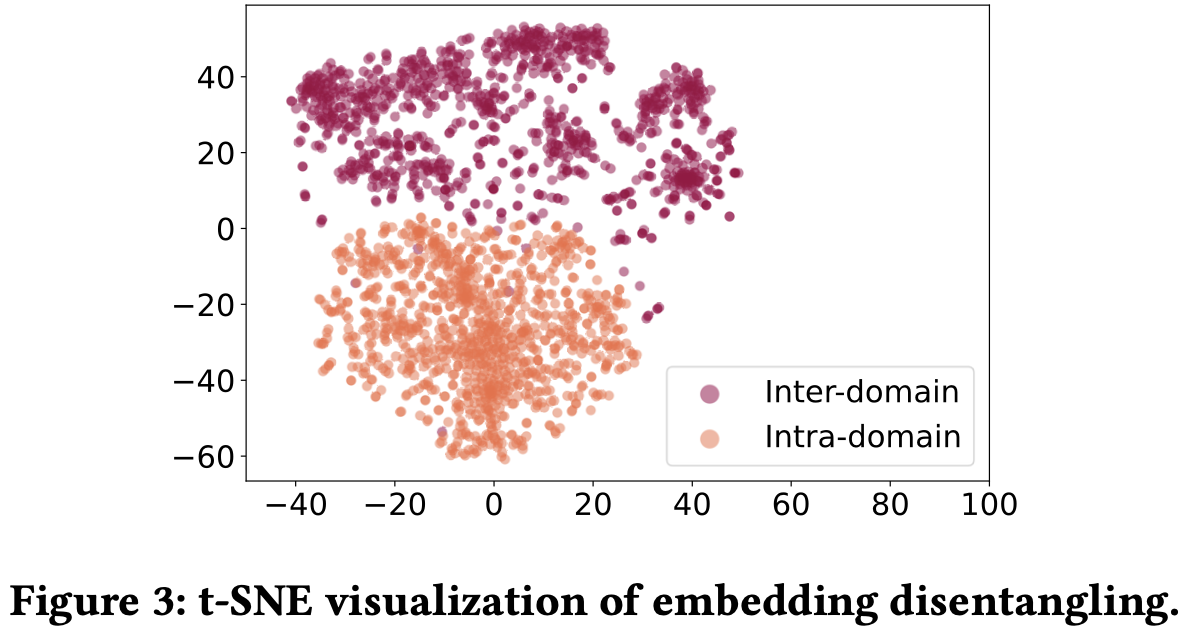
- 학습과정 및 gradient 업데이트 과정
3.2 Intra-domain and Inter-domain Models
Inter-domain Model
- 저자는 Intra-domain Model, 를 설계함
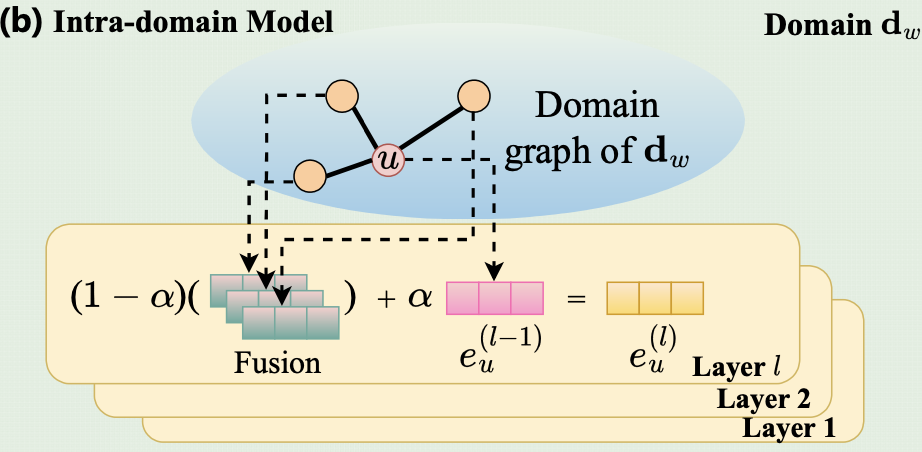
- Domain 에서의 user-item interaction은 bipartite graph 로 표현이 됨
- 는 user, item 임베딩을 반복적인 neighbor aggregation으로 학습함
→ user-item의 high-order connectivity를 포착할 수 있음
- : hyper parameter로 neighbor aggregation 과정에서 노드의 정보량을 조절함
- linear projection function, non-linear activation function을 모두 제거함
→ CF signal을 포착하는데 도움이 되지 않기 때문이 부분에 대한 내용은 LightGCN이 떠올랐다.
- 마지막 레이어의 출력은
- 0번째 레이어의 input은 , random initialized
Inter-domain model
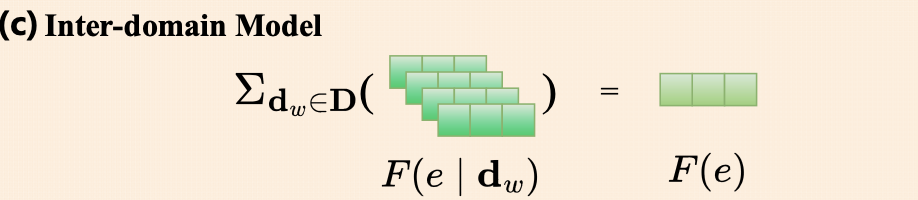
- Inter-domain model도 동일하게 를 사용하지만, input을 inter-domain embedding 를 사용
- 도메인간 general knowledge를 학습하며, 모든 도메인의 임베딩을 학습해서 합산한 후에 하나의 임베딩으로 출력
- : randomly initialized input embedding
→ Inter-domain embedding과 Inter-domain embedding은 독립적으로 초기화됨 - 모든 도메인들의 데이터를 받아서 gradient가 조정이 되기 때문에 최종적으로는 모든 도메인의 일반화된 정보를 보유한 inter-domain embedding이 됨
Inter-domain gradient, Intra-doain gradient update difference
Intra-domain gradient는 특정 도메인의 데이터셋만 학습에 사용되기 때문에 특정 도메인의 정보만을 반영하게 됨
Inter-domain gradient는 모든 도메인의 데이터셋을 학습에 사용하기 때문에 모든 도메인의 일반화된 정보를 반영하게 됨
- 는 다른 single-domain recommendation model로 대체할 수 있으며, MF로 대체했을 때 눈에 띄는 성능을 보여주었음.
4. DOMAIN ALIGNMENT
- Overlapping users/items는 도메인간 knowledge transfer에 중요한 역할을 하지만 real-world에서는 그 비중이 상당히 적음
- 다른 도메인의 다른 사용자들은 비슷한 행동 패턴을 보이고 있음
- 다른 도메인의 아이템들은 비슷한 interaction 패턴을 보이고 있음
⇒ 유사한 관심사를 가진 사용자들에 의함
- 저자들은 유사한 user/item pair를 식별하기 위한 random walk based domain alignment를 제안함
→ 유사한 user/item을 식별한 후에 그들의 intra-domain embedding을 더 가깝게 만들어야 함 - Random walk based procedure
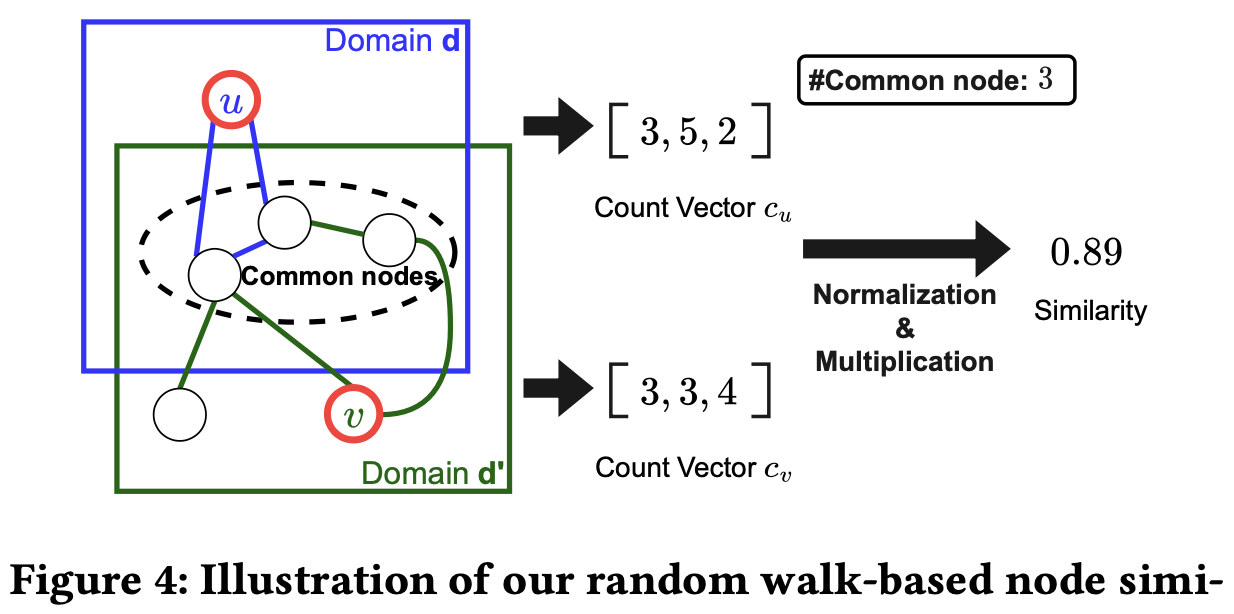
- 두 도메인 의 그래프 와 overlapped user, item node set 를 앵커 노드 집합으로 설정
- 노드 를 출발점으로 Random walk 실행
- Random walk를 진행하다 내의 노드에 도착하면 멈춤
- 내의 특정 노드에 도착한 횟수를 stop count vector 에 저장
- 의 유사도를 cosine similarity로 계산
- 특정 노드 둘을 각각 Random walk를 수행했을 때, common node set 내의 노드들에 도달한 수를 세는 stop count set 끼리 유사하면 그 두 노드는 서로 유사한 패턴을 가진 노드이다.
- 도메인별 노드간의 유사도를 구할 때, 도메인 내 모든 노드와의 유사도를 계산하기 때문에 Complexity가 높아질 수 밖에 없음 ⇒ Stop count vector 를 사용한 cosine similarity를 계산하기 때문에 complexity를 줄이고 병렬로 처리할 수 있음
- 동일한 user, item이 도메인마다 다른 행동 패턴을 가질 수 있기 때문에 에 바로 추가하지는 않음
→ overlapped user, item embedding이 반드시 비슷할 필요는 없다고 주장, 실험을 진행했었음> overlapped user, item embedding이 반드시 유사할 필요는 없다고 주장하고 이를 입증했는데, 이전 논문인 COAST에서는 “동일한 사용자는 여러 도메인에서 유사한 행동을 보인다” 라는 가정하에 시작된 논문임. 이 부분에서 두 논문의 출발점이 상이하다라는 점을 느낌 >
Exploit alignment
- Domain alignment로 얻어진 similar node pair는 여러 방면으로 학습에 도움이 됨
- similar node pair 는 similar intra-domain embedding을 가져야 함
- 하지만 다른 도메인에 있는 임베딩은 다른 차원에 존재하기 때문에 바로 두 노드의 거리를 계산하고 가까이 하는 건 적절한 방법이 아님
→ linear mapping function을 이용하여 모든 임베딩을 shared embedding space에 매핑시킴
- 임베딩간의 유사도를 squared euclidean norm으로 계산$$ l(u,v)=\vert\vert {e_u^dW_d-e_v^{d'}W_{d'}} \vert\vert^2_2 $$ - training objective $$ L_{\text{align}}=\sum_{d,d' \in D, d \neq d'} \sum_{(u,v)\in S_{dd'}}l(u,v). \ \ \ \ \ \ (7) $$
- 하지만 다른 도메인에 있는 임베딩은 다른 차원에 존재하기 때문에 바로 두 노드의 거리를 계산하고 가까이 하는 건 적절한 방법이 아님
- Overall loss function
- : Positive weight for the alignment loss
- : Trainable parameters in EDDA
- : L2 regularization
5. EXPERIMENTAL EVALUATION
- Experiment setting
- Compare out EDDA model with SOTA baselines
- Evaluate the key designs of EDDA
5.1 Experiment Settings
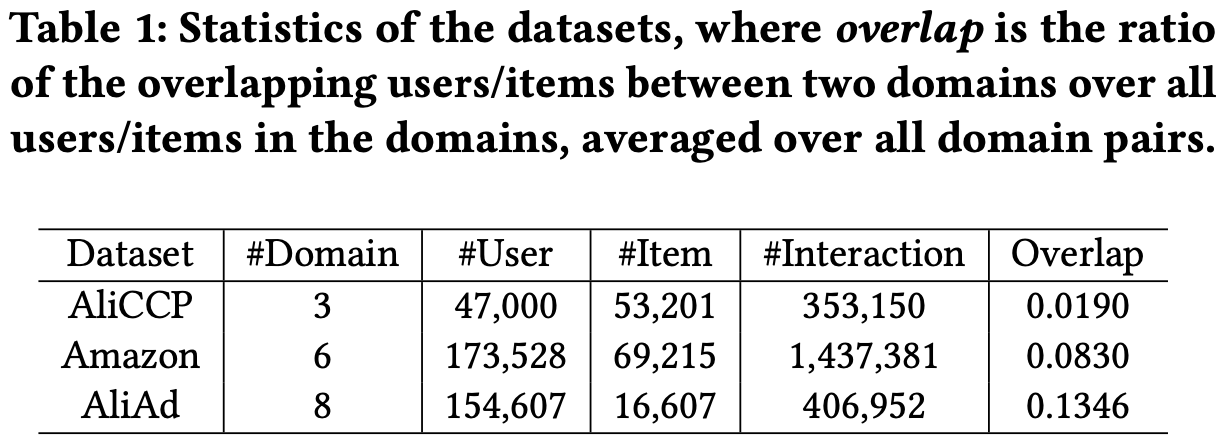
Datasets
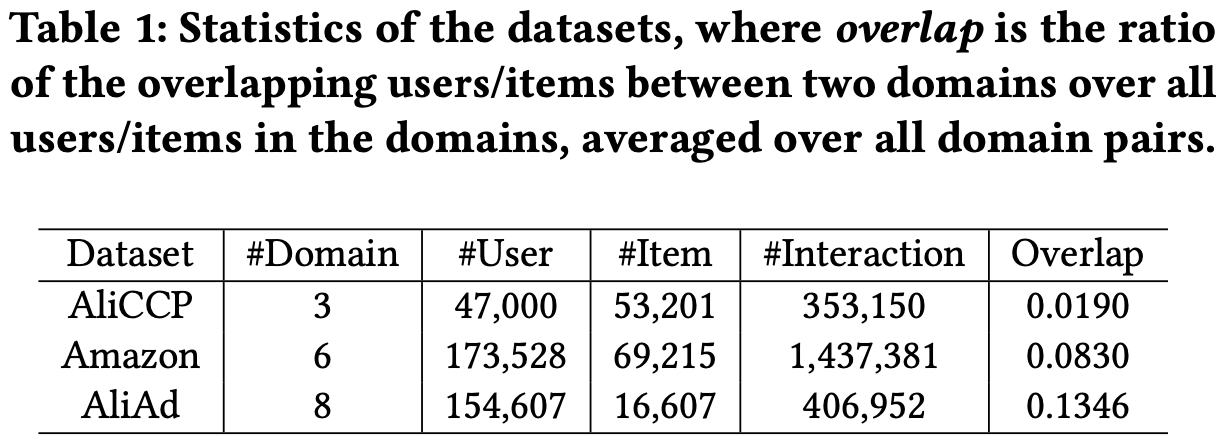
- AliCCP: Traffic log of the recommender system
- Amazon: 6 categories of items
- AliAd: display/clock records, 8 categories of ads
Baselines
- Single-domain: MF, NGCF, LightGCN
- Multi-task learning methods: CS, MMoE, PLE
- MDR methods: AFT, STAR, SAML, CATART, MGFN, TreeMS
Performance metrics
- AUC
- Recall@1
- Train : Val : Test = 7 : 1 : 2
Implementation Details (EDDA)
Model Architecture
- Inter-domain & Intra-domain Embedding Dimension: 64
- GRec (Graph-based Recommendation Model)
- Number of Layers: 2
- (Neighbor Aggregation Weight): 0.1
Training Configuration
- Batch Size: 8092
- (Domain Alignment Loss Weight): 0.03
- (L2 Regularization Coefficient): 1e-4
- Learning Rate: 0.001
- Optimizer: Adam
- Edge Dropout: 0.3
Domain Alignment Settings
- Random Walk Length: 4
- Number of Walks per Node: 500
- Top- Similar Nodes for Alignment: (Default: Select the most similar node)
5.2 Main Results: Compare with the Baselines
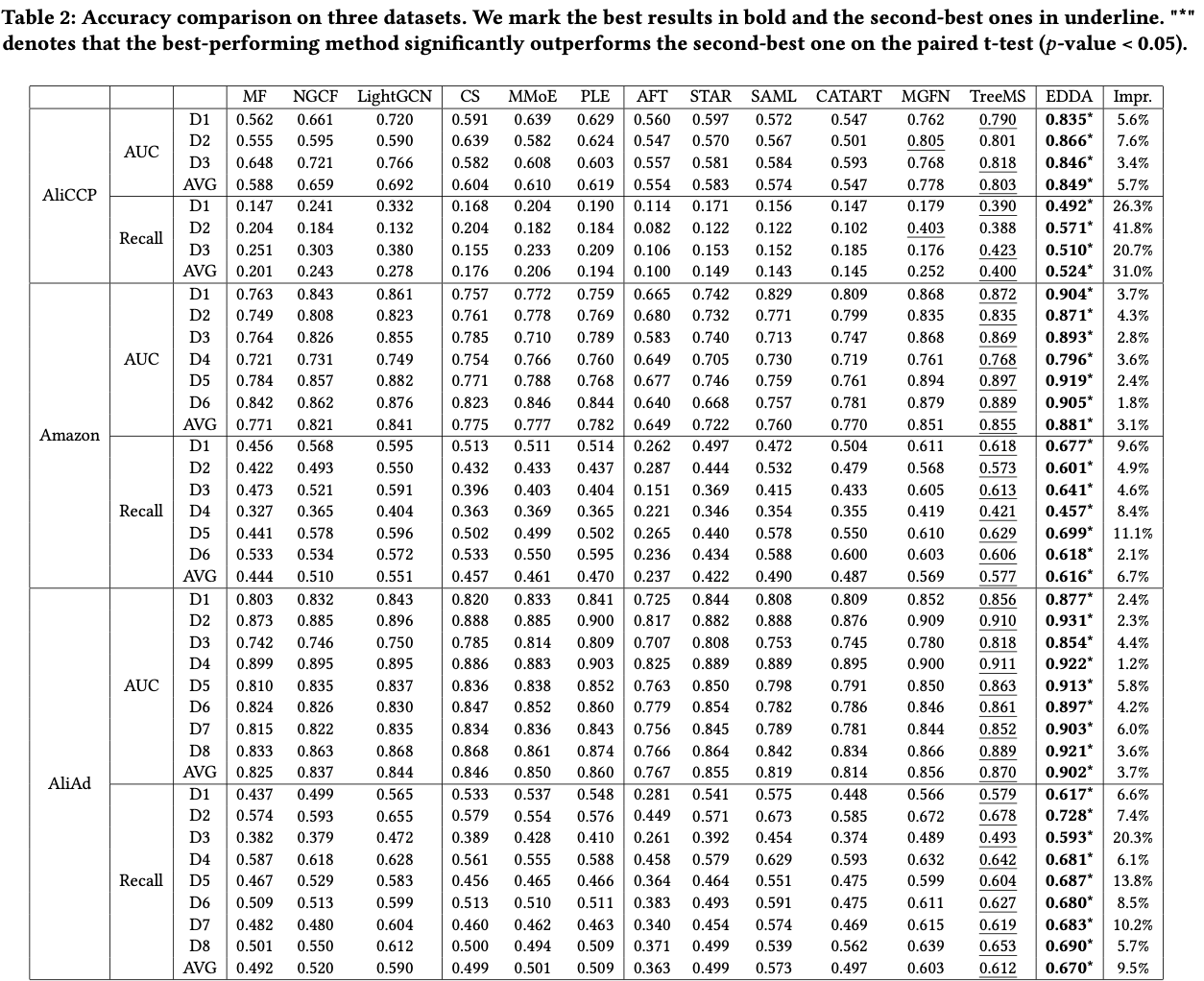
- EDDA가 일관적인 outperformance를 보여줌
- AUC & Recall(7.6% ~ 41.8%)
-
AliCCP (5.7%, 31.0%)
-
Amazon (3.1%, 6.7%)
-
AliAd (3.7%, 9.5%)
→ AliCCP가 다른 데이터셋에 비해 크기가 작고 overlap 비중이 더 적음
-
- AUC & Recall(7.6% ~ 41.8%)
- 도메인간 데이터 사이즈 편차가 클수록, 특히 작은 도메인이 존재할수록 EDDA는 높은 성능을 보임
- Amazon
- Recall: 모든 도메인에서 약 2%~11% 향상
- Amazon은 도메인간 데이터 사이즈 편차가 약 16.5배
- AliCCP
- Recall: 41.8% (D2), 20.7% (D3)
- AliCCP는 도메인간 데이터 사이즈 편차가 약 75.7배
- Amazon
- Graph-based baselines이 MLP-based baselines보다 성능이 좋음
→ neighbor aggregation으로 high-order information을 포착하기 때문
5.3 Ablation Study and Insights
Ablation study
- EDDA의 세 가지 변형모델을 설정 후, EDDA와 비교
- Inter: Inter-domain model, Inter-domain embedding만 사용
- Intra: Intra-domain model, Intra-domain embedding만 사용
- w/o DA: Domain alignment 제거
- Observation

- w/o DA 모델이 한 가지 임베딩만 사용하는 모델 (Inter, Intra)보다 성능이 좋음
→ ED Recommender가 효과적인 성능향상을 달성해냄 - Inter 모델이 Intra보다 좋은 케이스가 있고, 좋지 않은 케이스가 있다.
이 부분에 대한 내용은 굳이 논문에 들어갔어야했나라는 생각이 든다. 신빙성이 없어지는 부분
- w/o DA에 비해 EDDA가 더 높은 성능을 보이므로, Domain alignment가 중요함을 강조
- w/o DA 모델이 한 가지 임베딩만 사용하는 모델 (Inter, Intra)보다 성능이 좋음
Analyzing the gains of EDDA
- EDDA가 최고의 성능을 낼 수 있는 도메인과 데이터셋에 대해 분석
-
: domain 가 전체 도메인 중에서 얼마나 큰지를 나타냄
-
: domain 내 사용자들이 다른 도메인에서 얼마나 활발히 상호작용하는지를 나타냄
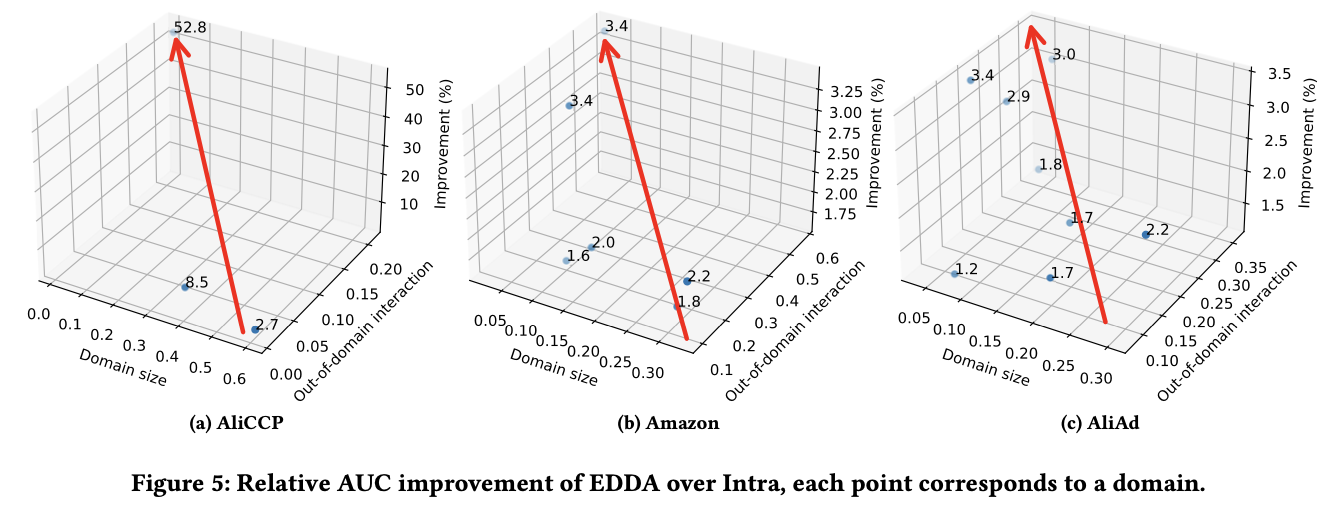
⇒ EDDA는 도메인간 정보를 공유하기 때문에 가 작아도, 가 클수록 최고의 성능을 보일 수 있음
-
Hyper-parameters
- Domain alignment weight 에 따른 성능을 비교하였음
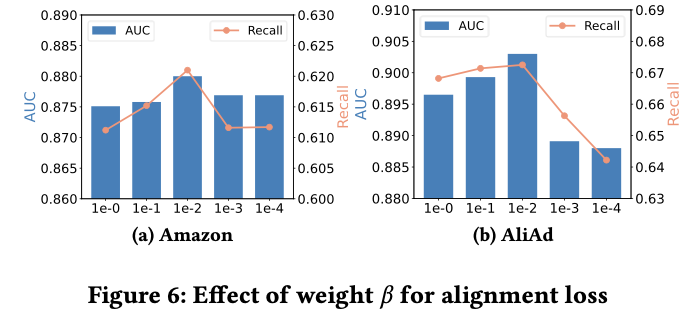
- 가 너무 작으면, 정규화 강도가 약해지고 유사한 user, item embedding을 충분히 활용하지 않음
- 가 너무 크면, 유사한 user, item pair에 과적합되어 ED loss에 영향을 끼침
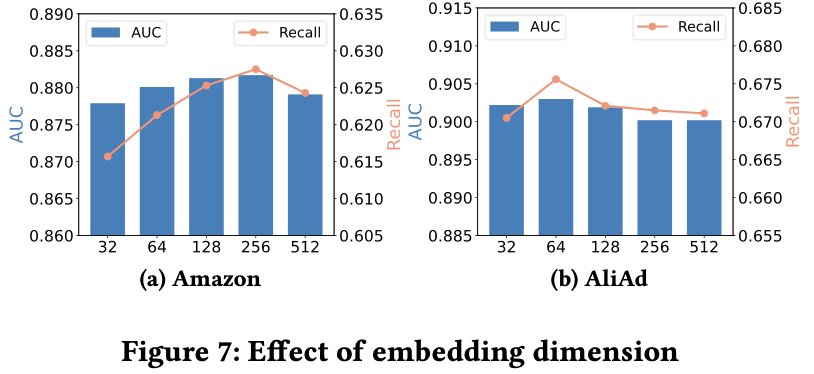
- Intra-domain, Inter-domain dimension size도 비교
Other instantiation of ED architecture
- ED Recommender, 는 다른 일반 모델로 대체할 수 있다고 했음
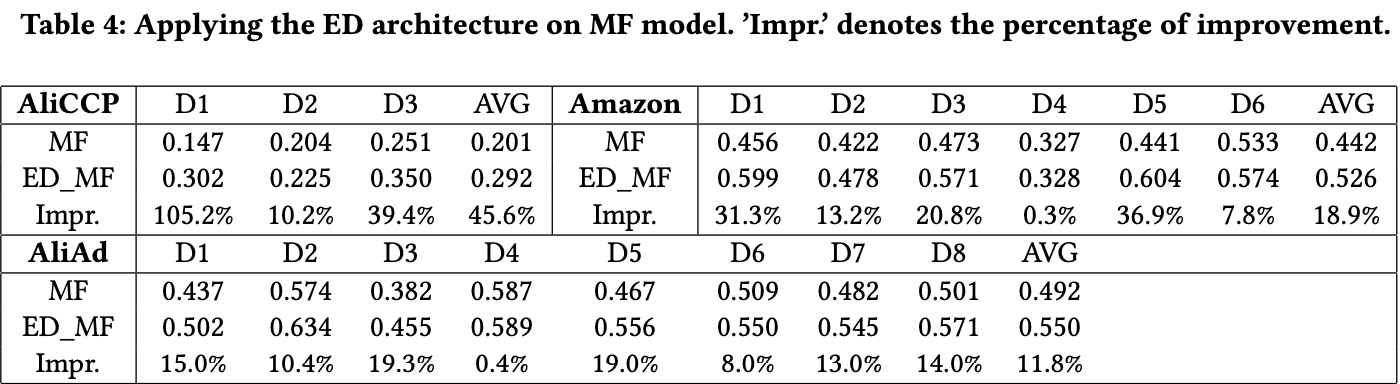
-
MF가 가장 오래되고 널리 사용되는 모델이기 때문에 MF와 비교하였음
이 부분은 조금 아쉬움. 가 다른 모델들을 사용할 수 있다고 했는데 추가 실험에서 단순 MF와 비교한 부분이 저자들의 주장을 뒷받침하기엔 좀 부족한 느낌이 듬
-
6. CONCLUSION
- MDR인 EDDA는 Embedding Disentangling & Domain Alignment 두 가지 핵심 설계로 이루어져 있음
- ED 설계로 인해 도메인들간 shared, specific representation을 다 학습할 수 있고
- DA로 인해 다른 도메인들사이에서 유사한 패턴을 가진 user, item embedding을 alignment 할 수 있었음
After Meeting
- 모델이 단순해서 Backbone 모델로 사용하기 적절한 거 같음. (Ver. w/o DA)
- Domain Alignment의 필요성은 동감하나, random walk 기반의 방식은 적절하지 않아 보임.
