EXHANS: Exploration and Exploitation of Hard Negative Samples for Cross-Domain Sequential Recommendation
Cross Domain Recommendation
WSDM (2025)
Yidan Wang et al
Abstract
- hard negative sample은 user preference를 학습하는데 큰 역할을 함 (contrastive signal)
- 기존의 방법들은 prediction score나 popularity가 높게 예측된 아이템들을 hard negative sample로 설정
→ 높게 예측된 아이템들은 user positive signal를 나타내기 때문에 false negative sample을 고르는 게 힘듬
true negative, false negative, hard negative sampling?
negative: user-item interaction이 없을 때
- true negative sample: user가 해당 item을 실제로 싫어함
- false negative: user가 해당 item을 실제로 좋아함
- hard negative sample: 모델이 예측한 점수가 높아 실제로 좋아하는지, 싫어하는지 헷갈리는 샘플
- user cross-domain behavior를 통해 false negative를 줄여 true negative sample을 잘 찾는 연구가 존재
- 효과적으로 hard negative sample을 발견하고 활용해 cdr을 향상시키는 방법은 여전히 open question
- 저자는 cross-domain sequential recommendation을 위한 exploration exploitation of hard negative samples (EXHANS)를 제안
- For better exploration (잘찾고)
- source domain으로 부터 user preference를 활용 → target domain의 negative sampling을 guide
→ Key idea: false negative sample이 hard negative sample에 비해 user preference와 유사할 가능성이 높음 - Adaptive popularity-based score correction: 사용자의 인기아이템에 대한 다양한 취향을 설명
→ 인기 아이템들과 상호작용한 사용자들과, 인기 아이템들이 false negative sample이 될 확률이 높음
(인기아이템을 아직 보지 않은 사용자가 해당 아이템을 좋아할 확률이 높음)
- source domain으로 부터 user preference를 활용 → target domain의 negative sampling을 guide
- For better exploitation (잘활용)
- replay buffer를 설계: 얻은 negative sample을 저장
- curriculum learning framework 제안: hard negative sample의 exploration-exploitation의 균형을 담당
- For better exploration (잘찾고)
1. Introduction
- CDSR(Cross-Domain Sequential Recommendation)은 여러 도메인에서 발생한 user behavior를 따라 user preference를 모델링
- CDSR은 implicit feedback(click, purchase)를 기반으로 user preference 학습
→ 모델 학습을 위한 positive, negative sample의 quality에 따라 성능이 결정 - implicit feedback은 일반적으로 positive sample의 의미를 담고 있음(관심이 있으니 클릭을 하고 구매를 한 것)
- 따라서 모델 학습 개선(일반화, 편향제거)을 이뤄내기 위한 negative sampling이 필수적임
- Naive solution: uniform sampling (un-interacted item들을 uniformly sample)
→ sufficient information 제공 및 gradient 계산이 ineffective
- Naive solution: uniform sampling (un-interacted item들을 uniformly sample)
Sampling hard negatives
- Hard negative sample은 user negative preference에 대한 더 가치있는 정보를 제공하고 있어 매우 중요함
- 기존의 hard negative sampling method는 prediction score or popularity가 높게 나온 item들에 더 높은 sampling 확률을 부여
negative sampling은 모델 학습 과정에서 일반화 능력이 올라가도록 하는 방법
기존의 방법은 prediction score가 높은 item을 hard negative sample로 정함
→ 모델의 학습이 완료된 후 prediction을 진행하기 때문에 앞뒤가 안맞는 거 같았다
⇒ 학습 과정 중 매번 prediction score 계산하여 hard negative sample 선택 - 기존의 방법은 false negative sample을 골라내기 어렵고, prediction score가 높은 아이템들은 positive user preference를 나타내기 때문에 학습이 잘못될 수 있음
- 최근, false negative issue를 완화하는 몇몇 연구들이 존재
- variance-based sampling method (Ding et al)
- false negative가 학습 중 분산이 더 낮은 경향이 있다는 관찰로 hard negative를 얻음
- adaptively adjust sampling method (Shi et al, Lai et al)
- false negative를 선택할 가능성을 줄임
- variance-based sampling method (Ding et al)
- 이러한 방법들은 false negative issue를 해결하여 추천 성능을 향상시킴
Limitations of existing methods
- CDSR의 negative sampling에 여전히 limitation이 존재
- For the mining of hard negative, previous work는 user cross-domain behavior를 이용해 false negative issue를 해결하는데 실패
→ sampling 연산이 너무 복잡하고 과적합의 위험이 크기 떄문
- 사용자마다 인기아이템에 대한 선호도가 다르다는 점을 negative sampling process는 고려해야함 (인기아이템 ≠ hard negative) - For the utilization of hard negative, 기존의 방법은 얻은 negative sample을 잘 사용하고 있지 않음
→ 모델 학습을 위한 negative sample중 일부만 valuable
- high quality인 hard negative sample을 사용해야 함이 부분에 대한 근거는 작성되어있지 않음
- For the mining of hard negative, previous work는 user cross-domain behavior를 이용해 false negative issue를 해결하는데 실패
Motivation
- 위의 두 limitation을 해결하기 위한 저자들의 points
- source domain의 user preference는 hard negative인지 false negative인지 구별을 잘 해야함
- false negative sample은 user preference와 일치할 가능성이 높음
- 책 도메인(s)에서 사용자가 해리포터 소설을 선호한다면, 영화 도메인(t)에서 해리포터 영화를 선호할 가능성이 높음 (영화를 보지 않았다고 가정) → false negative
- false negative는 negative sample에서 제외시켜야 함
- false negative sample은 user preference와 일치할 가능성이 높음
- 아이템들의 상대적인 인기도를 고려해야함 → 인기아이템에 대한 선호도가 다 다르기 때문
- 저자는 더 인기있는 아이템일수록 더 많은 사용자들이 상호작용함을 주장 → 해당 인기아이템이 false negative일 가능성이 더 큼
- 학습 초기에는 hard negative mining에 집중, 후에 exploitation
- source domain의 user preference는 hard negative인지 false negative인지 구별을 잘 해야함
Proposed method
- 저는 EXHANS를 제안
Exploration
- hard negative sample을 exploration하기 위해 user preference 기반의 negative sampling score를 formulate
- source domain에서는 preference prediction이 낮고, target domain에서는 preference prediction이 높을 때, negative sampling 확률을 높게 부여 (false negative 제외하는 작업)
- 사용자마다 인기아이템에 대한 선호도가 다르기 때문에, negative sampling score를 조정하는 adaptive popularity-based score correction을 소개
- false negative issue를 완화
- adaptive popularity debias를 수행
Exploitation
- replay buffer를 활용하여 얻은 hard negative sample을 캐시 후, optimization process에서 reuse
- curriculum based learning strategy는 exploration과 exploitation의 adaptively balance를 위해 제안됨
→ 학습 초기에는 exploration에 더 많은 비중, 이후 exploitation에 더 많은 비중
2. Notations and Task Definition
- source domain - target domain 간의 CDSR scenario
- Item set
- User set
- User behavior sequence
- Cross-domain interaction sequence (only overlapping user)
- user 의 historical interaction이 주어질 때, CDSR은 이를 토대로 다음에 상호작용할 target domain에 있는 item을 예측함
- recommender의 학습 목표는 ranking loss를 아래에 맞게 optimize
- interacted positive sample : prediction을 높게
- interacted negative sample : prediction을 낮게
3. Methodology
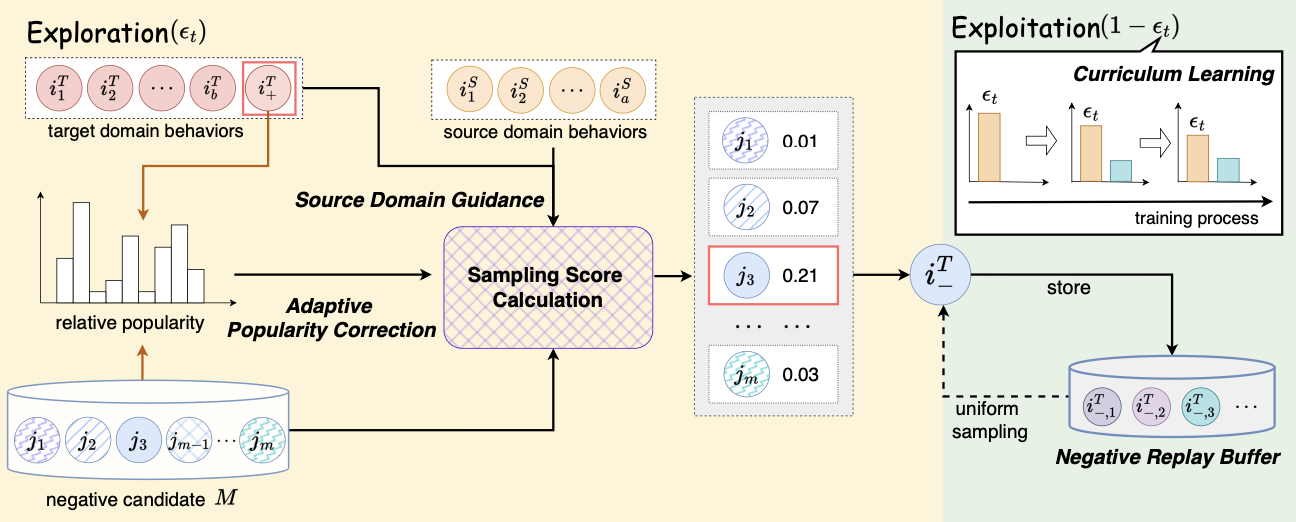
- Exploration ()
- unobserved item들 중에서 hard negative sample을 mining
- negative sampling score based on user preference를 정의
- Exploitation ()
- Exploration에서 얻은 high quality negative sample을 fully utilize
- 얻은 hard negative sample을 cache하는 replay buffer를 소개
→ optimization process에서 reuse
- Curriculum learning-based strategy ()
- Exploration과 Exploitation의 balance
3.1 Exploration of Hard Negatives
- 먼저 uniform sampling을 진행하여 negative candidate set 을 설정 (from target domain)
- 그 다음, 에 있는 sample 중 sampling score가 높은 sample이 hard negative sample이 되도록 parameter를 update
- sampling score calculation에는 source domain user preference와 상대적인 item popularity를 사용이 돼, false negative를 제외시킴
3.1.1 Cross-domain pretraining
- source domain user preference를 얻기 위해 user, item representation이 필요
→ 2-stage training strategy (cross-domain pretraining & target-domain fine-tunning)
Cross-domain pretraining
- source domain sequence + target domain sequence ⇒ cross-domain sequence 를 구함
- Sequencial recommender가 를 학습 → All item embedding을 얻음
- 를 학습하여 source-domain user preference representation을 얻음
Target-domain fine-tunning
- uniform sampling으로 얻은 sample은 negative sample로 활용
- 를 학습한 pretrained recommender에 negative sample을 추가하여 fine-tunning 진행
- 저자는 Recommender로 SASRec를 사용 (default sequencial recommender)
- EXHANS는 plug-and-play module임
→ CDSR의 sampling function만 EXHANS로 교체하면 됨
3.1.2 Source domain guidance
- Source domain user preference가 hard negative와 false negative를 구분할 수 있음
- 저자는 false negative sample이 source-target domain에서의 preference와 일치할 확률이 높다고 주장
- source-target domain sequential recommender를 이용하여 user preference representation을 얻음
- : sequential recommender (source, target)
- : encoder of pre-trained recommender
- uniform sampling을 통해 얻은 sample set 의 item 에 대한 user interest를 계산
- negative sampling score function
- : weight of source domain user preference
- 최종 negative sampling score가 높게 나온다는 건, target domain user preference는 높게, source domain user preference는 낮게를 의미
→ false negative의 risk를 줄임
Adaptive popularity correction
- Item popularity는 sample harness의 중요한 지표
- 기존의 방식은 popular item에 대해 static한 probability를 부여
→ 사용자마다 인기 아이템에 대한 다른 선호도를 가지고 있음 - 만약, 사용자가 여러 인기아이템들에 방문했다면, 인기아이템들은 false negative sample일 확률이 높음
- item popularity influence를 조정하는 adaptive popular correction을 제안
- 에 대해서, ground-truth인 과 비교해 relative popularity를 구함
- : Item frequency
- weight coefficient
- : temperature coefficient
- 는 hard negative sampling score function에서 다음과 같이 쓰임
- negative sample 는 에 있는 아이템들 중 score가 가장 높은 아이템
- EXHANS는 user cross-domain behavior와 item popularity를 이용하여 high quality의 hard negative sample을 explore (better exploration)
3.2 Exploitation of Hard Negatives
- explored hard negative instance를 최대한 활용하기 위해 negative replay buffer를 설계하여 를 cache
- curriculum learning-based -greedy algorithm으로 exploration과 exploitation의 balance를 잡음
- : exploration에 더 큰 비중
- : exploitation에 더 큰 비중
3.2.1 Negative Replay Buffer
- 학습 과정에서 negative replay buffer는 explored hard negative를 저장
- 저장된 hard negative는 high quality이기 때문에, uniform sampling을 통해 exploitation에 사용
- EXHANS가 학습되면서 hard negative sample set의 distribution이 변화하기 때문에 (더 좋은 hard negative sample이 들어감) replay buffer 역시 지속적으로 update 되어야 함
- buffer에 있는 negative instance를 사용하기 전에 수식으로 score를 재계산하고 top-n item들로만 버퍼를 최신화
3.2.2 Curriculum Learning
- 학습 과정에서 exploration과 exploitation의 trade-off는 adaptively evolve되어야 함
- 학습 초기에는 exploration에 중점을 두어 high quality hard negative sample을 찾아야 함
- 학습이 진행되면서, exploitation의 비중을 점차 키워 explored hard negative를 최대한 활용 해야함
- 으로 exploration과 exploitation의 trade-off를 control
- 학습 초기에는 로 설정, 이후 epoch에 따라 의 값을 감소시켜 exploitation에 집중
- : epoch 의 update rate
-
학습 초반, training loss가 빨리 떨어지니, 큼 → 가 빠르게 감소 → exploration
-
학습 중반, loss 변화가 작아 작음 → 은 완만히 감소 → exploitation
-
: hyperparameter
-
- : epoch 의 update rate
4. Experiments
- Three Research Questions
- EXHANS와 다른 negative sampling method와의 비교
- EXHANS를 recommendation model에 배포했을 때, 성능 비교
- EXHANS의 components에 따른 성능
4.1 Experimental Setup
4.1.1 Datasets
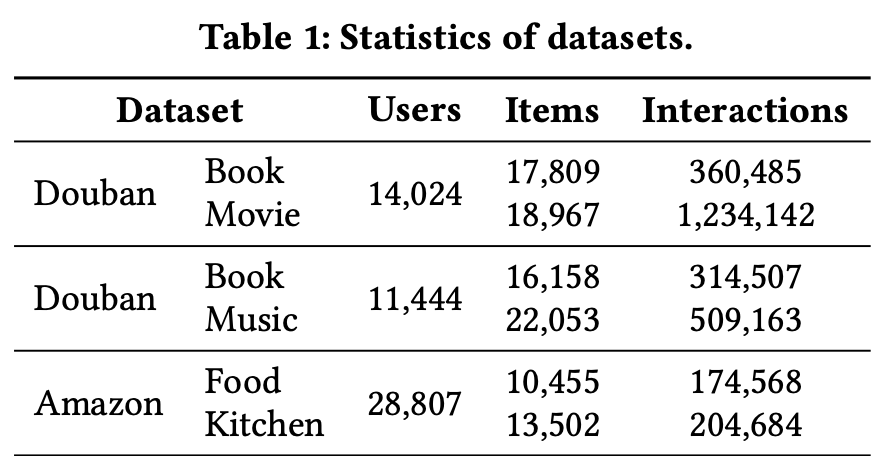
- Douban platform
- Book, Movie, Music
- Book ↔ Movie
- Book ↔ Music
- Amazon dataset
- Grocery and Courmet Food, Home and Kitchen
- Food ↔ Kitchen
4.1.2 Evaluation Protocols
- Recall@k
- NDCG@k
- Train : Val : Test = 8 : 1 : 1
4.1.3 Baselines
- CDSR의 negative sampling methods
- Uniform
- Hard negative-focused method
- DNS
- MixGCF
- False negative-mitigated methods
- GNNO
- SRNS
- DNS+
- CDSR-tailored method
- RealHNS
4.1.4 Implement Details
- Defalut recommender: SASRec
- Sequence length
- Douban: 128
- Amazon: 20
- Item embedding size: 64
- : 100
- Replay buffer size: 100
- Sampling Hyperparameter
- : 0.3
- : 1
- : 0.1
- Book ↔ Movie: {0.2, 0.4}
- Book ↔ Music: {0.5, 0.5}
- Food ↔ Kitchen: {0.7, 0.7}
- : 5
- Optimizer: AdamW
- Learning rate: 1e-3
- Batch size: 1024
4.2 Performance Comparison (RQ1)
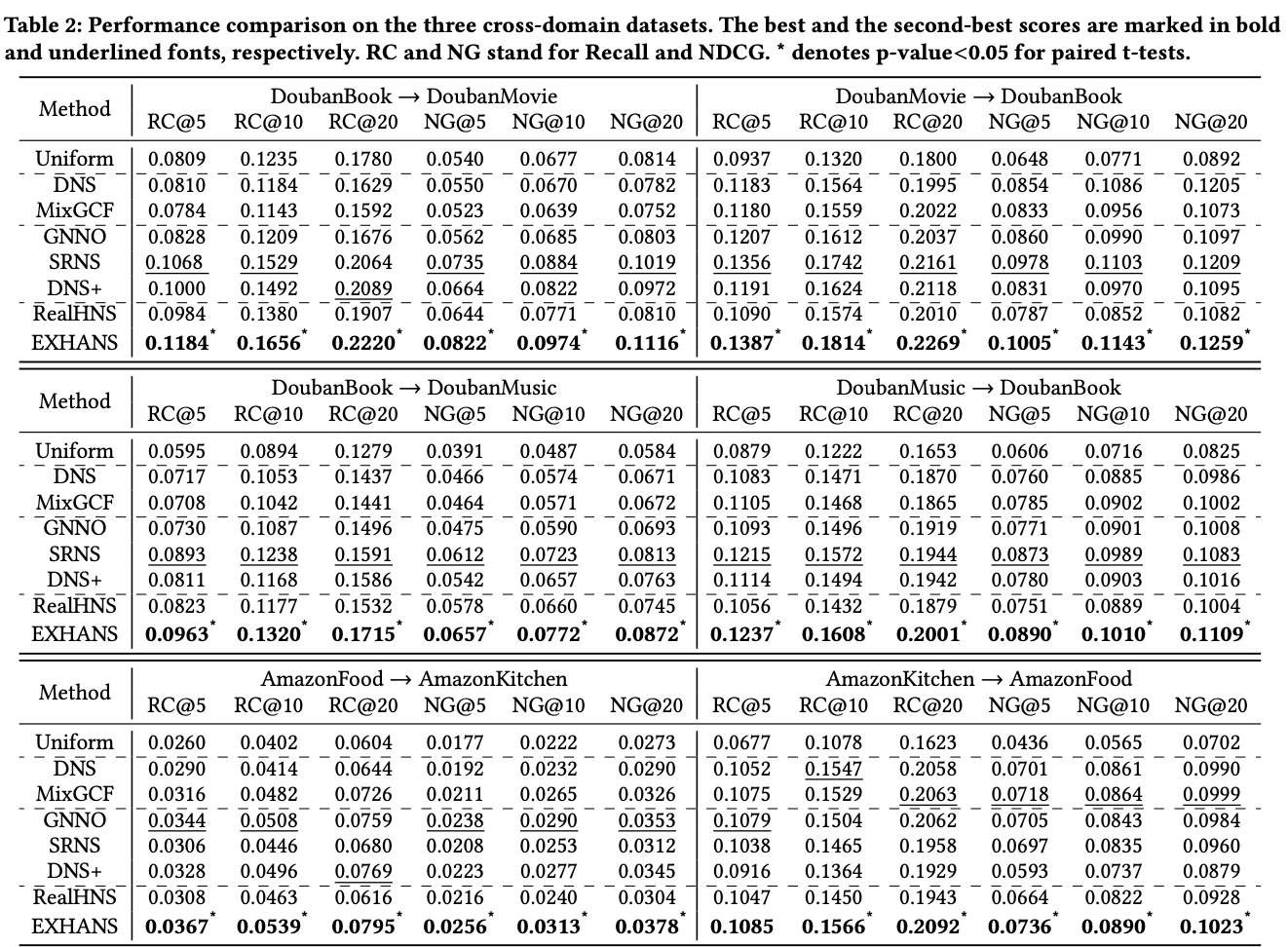
- EXHANS가 false negative issue를 해결하여 high quality hard negative를 잘 선별함
- EXHANS는 popularity bias를 해결함
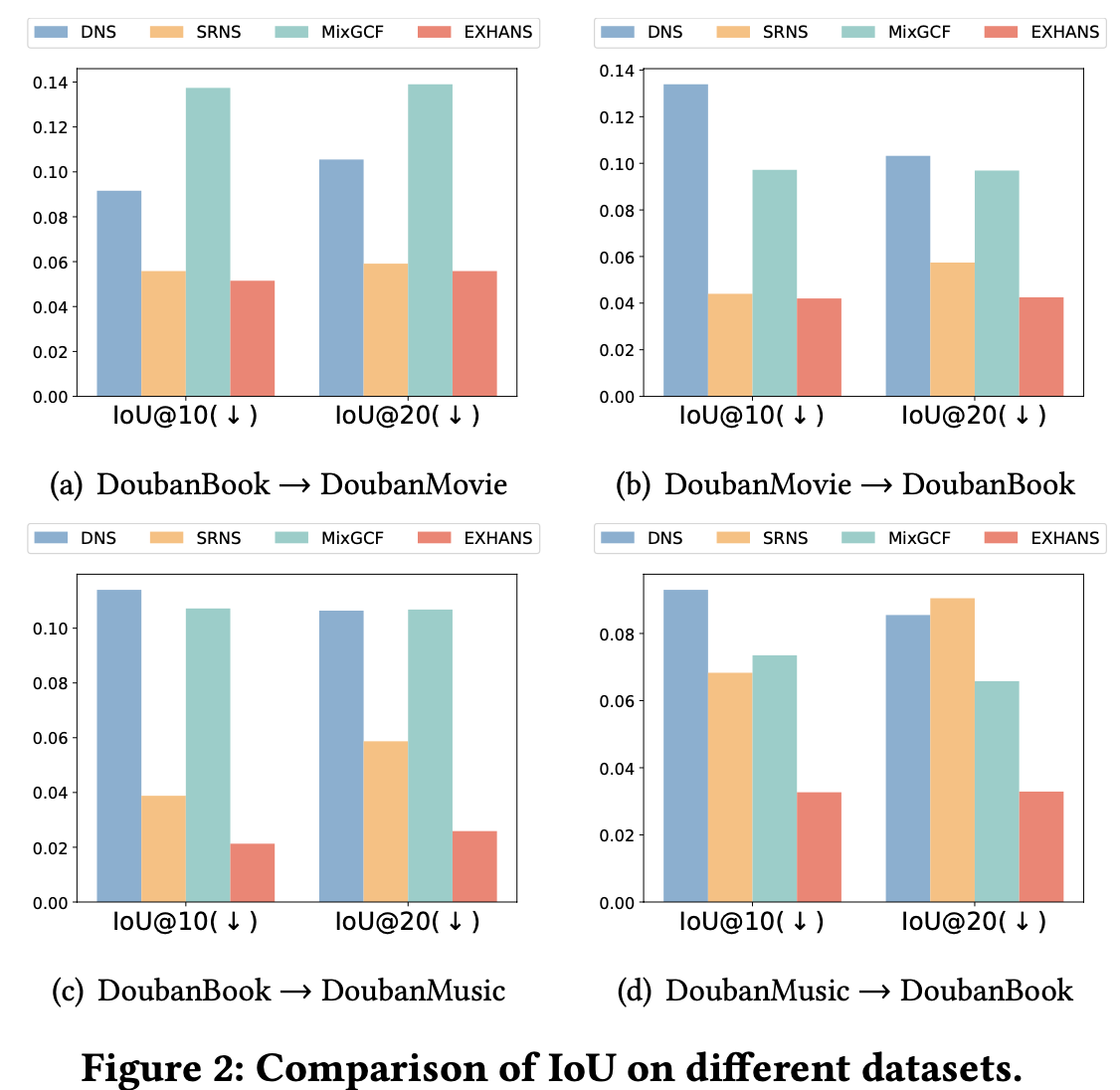
- IoU(Interaction of Union)
- adaptive popularity score correction으로 인해 popularity bias를 완화함
Answer to RQ1
- SOTA negative sampling method를 능가
- popularity bias를 줄여주어 더 나은 추천을 제공
- EXHANS의 효과를 입증
4.3 Generalization Evaluation (RQ2)
- EXHANS는 plug-and-play method로 추천 모델의 sampler를 EXHANS로 바로 바꾸어 적용시킬 수 있음
- 세 가지 recommendation model (Tri-CDR, GRU4Rec, SASRec)에 EXHANS를 적용
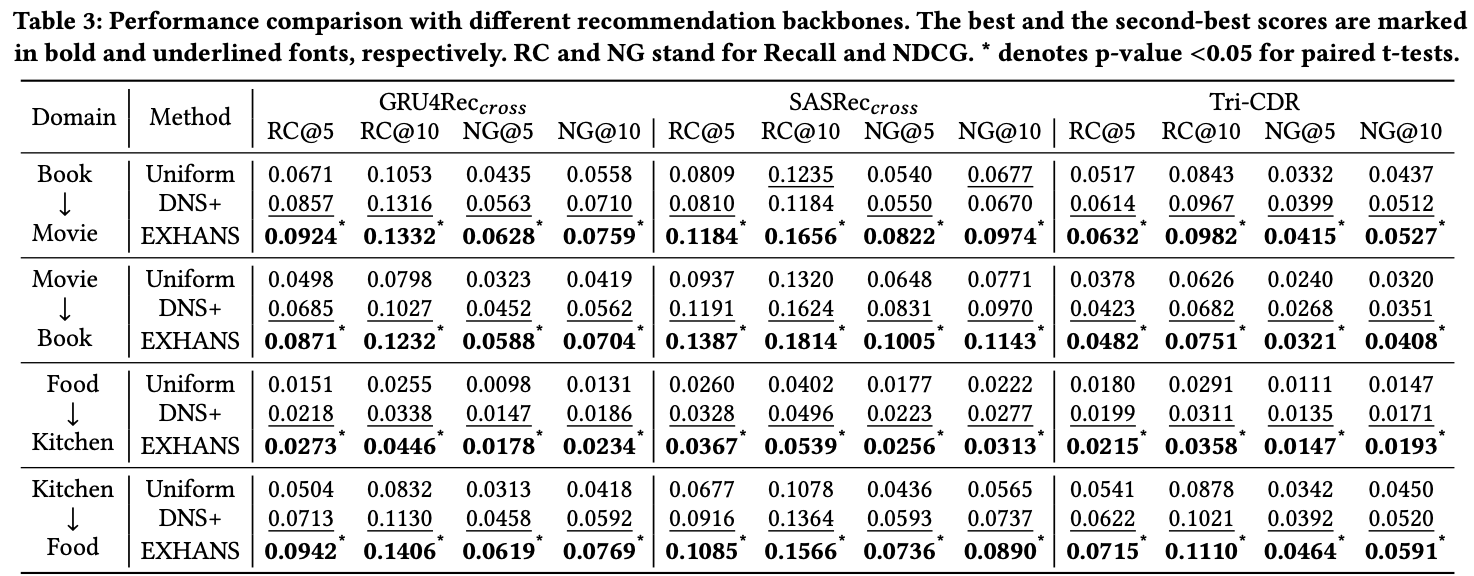
Answer to RQ2
- EXHANS is effective plug-and-play negative sampling method
4.4 Ablation Study (RQ3)
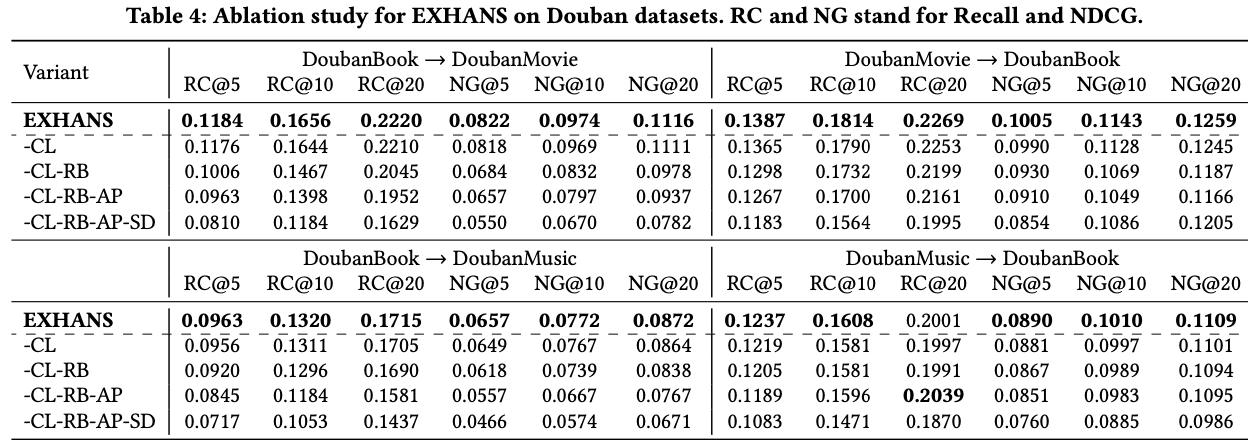
- CL(Curriculum Learning ): exploration-exploitation의 balance
- RB(Replay Buffer): explored high quality hard negative sample을 활용할 수 있음
- AP(Adaptive Popularity correction): popularity bias mitigate
- SD(Source Domain guidance): source domain에서의 user preference를 hard negative에서 제외 (false negative issue)
5. Conclusion and Future Work
- CDSR에서 사용되는 negative sampling challenge를 두 가지 관점(exploration, exploitation)에서 접근하고 이를 해결
- source domain guidance, adaptive popularity correction, curriculum learning 등 저자들이 고안한 EXHANS는 실험에서도 그 우수함을 입증
My Opinions
-
EXHANS를 통해 CDSR 이라는 분야에 대해서 알게 되었음. 또한, negative sample이라는 개념을 이번 논문을 통해 확실하게 각인시킴
-
EXHANS와 같은 sampler는 당장에는 우리의 연구에 적용시킬 순 없을 거 같지만, persona를 정의한다면 multi-persona를 잘 구분짓는 persona sampler를 고안할 때 아이디어를 가져올 수 있을 거 같음
-
How to define the persona?
- 하나의 도메인을 예로 든다면 (패션 도메인), 패션도메인에는 다양한 카테고리가 존재 (상의, 하의, 신발, 가방 등) 우리가 생각하는 multi-persona, persona는 이러한 다양한 카테고리 속에서 사용자의 선호도가 다 다르다는 것.
- 예로 들면, ‘나’를 기준으로 상의 중에서는 다양한 상의 종류중에서 셔츠를 선호하고, 셔츠 중에서도 단색 셔츠보다는 체크셔츠를 선호
하의는 데님팬츠보다는 코튼팬츠를, 그 중에서도 통이 넓은 벌룬핏 코튼 팬츨르 선호 - 이러한 선호도를 임베딩 차원에 매핑시켰을 때, 선호하는 아이템들이 매핑되는 특정 공간이 존재, 이 공간의 방향벡터가 다 다를 것으로 생각함.
그렇다면 이 방향벡터가 사용자의 persona를 의미하는 게 아닐까?
After Meeting
+) Questions
Q1: Hard negative가 BPR optimization에서 중요한 이유
A1:
- BPR loss:
- BPR loss의 gradient 크기는 negative pair의 prediction score가 결정
- easy negative: prediction score가 낮게 나오기 때문에 시그모이드 내부의 값이 커짐 → 에 가까워지기 때문에 gradient 작음
- hard negative: prediction score가 높게 나오기 때문에 시그모이드 내부의 값이 작아짐 (0 or 음수) → 에 가까워지기 때문에 gradient가 큼
- ⇒ 동일한 epoch에 비해 loss가 더 많이 감소 ⇒ hard negative로 학습을 해야함
Q2: Negative candidate set 안에 negative sampling score가 가장 높은 아이템을 뽑을 때 별도 regularizer나 loss가 존재?
“Then the item which has the highest sampling score within 𝑀 is selected as the negative sample for parameter updates.” - EXHANS
- 해당 구문에 의해 생긴 의문점. EXHANS에는 별도로 소개된 loss function, regularizer가 없다.
- parameter update한다는 것은 EXHANS가 적용된 CDSR의 user, item embedding을 업데이트하는 CDSR 내부의 parameter를 의미
- 전체적인 학습과정은
⓵ user / item representation 생성 → ⓶ negative sampling (EXHANS) → ⓷ BPR Loss → ⓸ CDSR parameter update → ⓵ → …- epoch를 거치며 BPR loss에 의해 user, item representation이 갱신되기 때문에 선택되는 negative sample도 달라짐
Q3: EXHANS에서 주장한 학습초기엔 탐색, 중반 이후엔 활용 커리큘럼 전략의 이유
- 학습 초반에는 user, item representation에 의미있는 값이 들어있지 않아 EXHANS가 negative sample을 선별해도 BPR loss의 gradient가 크지 않을 확률이 높음
→ 을 학습 초반에 1로 설정하여 exploration에 집중 - 이후 loss의 하락폭에 따라 의 하락폭이 결정되어 exploitation에 집중
Q4: EQ. 2 (source user preference)를 계산할 때 왜 만 쓰는지?
- EXHANS의 목적은 target domain에서의 recommendation을 위한 CDSR의 학습성능을 올릴 수 있도록 hard negative sample을 잘 찾는 것
- 저자는 기본적으로 “source domain preference가 target domain preference로 이어질 가능성이 크다”라는 전제하에 EXHANS를 제안
- 즉, eq. 2는 () source domain에서의 사용자 선호도를 (취향을) tatget domain item에 대보면, 그 아이템이 false negative인지 hard negative인지 빠르게 알 수 있다를 의미한다.
- 그래서 target domain item들과의 dot product를 진행하는 것
Q5: EQ. 3의 네 가지 경우별 해석 및 저자의 주장과의 연결성
- 저자의 주장: “source domain preference가 target domain preference로 이어질 가능성이 크다”
| No. | (source preference) | (target preference) | negative case (EXHANS) | why |
|---|---|---|---|---|
| 1 | high | high | false | 두 도메인에서의 선호도가 높다는 건, positive sample을 의미 → negative로 사용하면 오염됨 |
| 2 | low | low | easy | 두 도메인에서의 선호도가 낮은건 확실한 negative → 모델이 이미 잘 구분하기 때문에 gradient가 작아 학습에 미미한 도움 |
| 3 | high | low | false (potential) | 저자의 주장대로라면, target domain에서도 높게 나와야 하는데 그렇지 않음 → 모델이 잘못 예측한 것 → 싫어하는지 좋아하는지 모름 → 실제로 좋아할 가능성이 있기 때문에 false로 분류하여 학습을 피함 |
| 4 | low | high | hard | 저자의 주장을 역으로 생각하면 |
”소스 선호도가 낮으면 타겟 선호도도 낮을 것이다.”
→ easy negative
이 경우에는 소스에서는 낮게 나왔는데, 타겟에서는 높게 나왔음
즉, 모델이 해당 아이템에 대해 헷갈려한다. → hard negative |
의문점
No 3, 4.에 대해서 두 경우 모두 저자의 주장과는 반대로 모델이 예측함
저자는 No 4.에 대한 예시만 들고있기 때문에 해당 case는 타당한 거 같음
그러나 No 3.도 4와 동일한 예시로 보이는데 (방향만 반대), 왜 이 경우에는 실제로 좋아할 가능성이 있는 것으로 보고 false negative로 분류하는지가 의문
