EXIT: An Explicit Interest Transfer Framework for Cross-Domain Recommendation
Cross Domain Recommendation
Lei Huang at al
CIKM 2024
Abstract

- 도메인간의 implicit feedback을 기반으로 모델링하고 도메인간 추천을 향상시키기 위한 representation을 학습하기 때문에 복잡한 네트워크를 사용함
- 도메인간 transfer knowledge가 unsupervised로 이루어지기 때문에 negative transfer 문제가 발생
- 저자는 이러한 문제를 해결하기 위한 EXIT 모델을 제안
- source domains에서 benefical interest만을 라벨링하여 지도학습
- scene selector network도 소개
- interest transfer 강도를 모델링하는 네트워크
- Offline, Online 두 환경의 실험에서 의미있는 성능을 보임
- 중국 Meituan App의 온라인 홈페이지 추천시스템에 적용시킨 사례
- 복잡한 네트워크 구조나 학습 과정없이 EXIT는 쉽게 추천 시스템에 사용될 수 있음
Interest VS Knowledge
기존의 논문에서 많이 나오던 knowledge 대신 interest 용어가 더 자주 사용이 됨
knowledge transfer: 모델이 학습한 representation, domain-shared representation을 전송
interest transfer: user가 explicit feedback으로 남긴 더 정확한 사용자의 선호도를 전송. knowledge에서 더 들어간 하위개념
1. Introduction
- CDR의 두 가지 challenge
- 검색 도메인과 추천 도메인의 차이: 검색 도메인은 explicit needs에 대응되지만 추천 도메인은 유저의 latent needs를 예측하는 방식
- 즉, 검색 도메인은 유저가 직접 입력, 추천 도메인은 유저가 좋아할만한 것들을 예측
- 사용자가 explicit needs를 위해 검색 도메인을 사용했지만, 추천 도메인이 이를 사용자의 interest로 받아들이고 추천을 진행
- Negative transfer
- 한 플랫폼내에 여러 business model이 있는 것은 negative transfer 문제를 해결하는 것을 더 어렵게 만듬 (음식배달, 온라인 쇼핑몰, 호텔 예약 등)
- 사용자의 상황에 따라 각 buisness에 대한 사용자의 interest가 다양해지기 때문에 각 상황에 맞는 interest를 찾는 것이 중요함
- 검색 도메인과 추천 도메인의 차이: 검색 도메인은 explicit needs에 대응되지만 추천 도메인은 유저의 latent needs를 예측하는 방식
⇒ CDR method는 source domain signal중 benefitcial signal을 구별할 줄 알아야한다.
-
검색에서의 구매가 앞으로 지속적일지 불분명
-
어느 맥락에서 발생한 신호인지 보고 골라야함
-
이전 CDR methods의 방식
- 데이터 증강을 위한 다른 도메인을 연결하는 유사한 정보를 활용
- 머신러닝을 사용
- 유저 아이템 임베딩, rating pattern을 학습 in 소스 도메인
- 학습한 것들을 타겟 도메인으로 전송
- 도메인과 비즈니스 간의 큰 차이를 가지고 있는 시나리오에는 비효율적임
- negative transfer의 영향이 최소화 되는 도메인 간의 지식 전이를 용이하게 함 → 소스도메인과 타겟도메인의 차이가 큰 시나리오에서는 어려움
- 기존의 CDR methods는 도메인 간 지식을 전이할 때, 별도의 감독하에 이뤄지지 않음 → 어떤 지식이 interest signal인지 모름 → 전이 자체가 implicit하고 uncontrollable
- interest transfer를 위한 implicit modeling은 interest를 잘 구별할 수 없어서 negative transfer를 초래할 가능성이 더 높아짐
-
EXIT를 제안
- 사용자의 context를 기반으로 target domain에 도움이 되는 source domain의 interest를 선택적으로 전이할 수 있다.
- negative transfer 문제를 예방할 수 있음
-
요약
- 지도학습을 이용하여 도메인간 interest transfer를 진행
- interest combination label 설계하여 지도학습에서 사용
- interset combination label과 함께 사용되는 scene selector network를 제안 scene selector network는 문맥을 통해 interest의 intensity를 설정
Introduction 까지 읽고 든 생각
1. 해당 논문에서 제안하는 EXIT라는 CDR 모델은 negative transfer를 줄이는 것에 중점을 둔 모델인 거 같다.
2. UniCDR, DisenCDR은 domain-shared information을 추출하여 전이시키는 방식이지만, EXIT는 source domain에서의 user signal 중 target domain에 도움이 되는 interest signal을 구별해서 interest만 전이하는 방식. 이 때 해당 signal의 context를 종합적으로 판단 (우산을 구매했을 때, 그 당시에 날씨가 어땠는지)
3. 개인적으로 CDR은 도메인간 유사도가 높을 때 가치가 있다고 판단한다. EXIT는 도메인간 유사도가 낮아도 (패션-음식) 추천 품질을 높일 수 있다고 하는데, 현실적으로 봤을 때, 여러 도메인을 다루는 하나의 플랫폼 내의 추천 품질을 올리는데 큰 기여를 한다고 생각.
도메인간 유사도가 높을 때, shared information을 추출하는 방식을 사용하는 것보다 나을지 궁금함.
2. Related Work
- Single-domain recommendation
- Cross-domain recommendation
3. Proposed Framework
3.1 Problem Setup
- CTCVR을 향상시키는 것에 집중함
- CTCVR (Click-Through Conversion Rate): 사용자가 추천리스트에 있는 아이템을 클릭 후, 구매까지 할 확률
- Meituan App내의 다른 도메인들이 각각 source, target 도메인이기 때문에 동일한 user, item set을 가지고 있음.
- CTCVR (Click-Through Conversion Rate): 사용자가 추천리스트에 있는 아이템을 클릭 후, 구매까지 할 확률
3.2 The Overall Framework
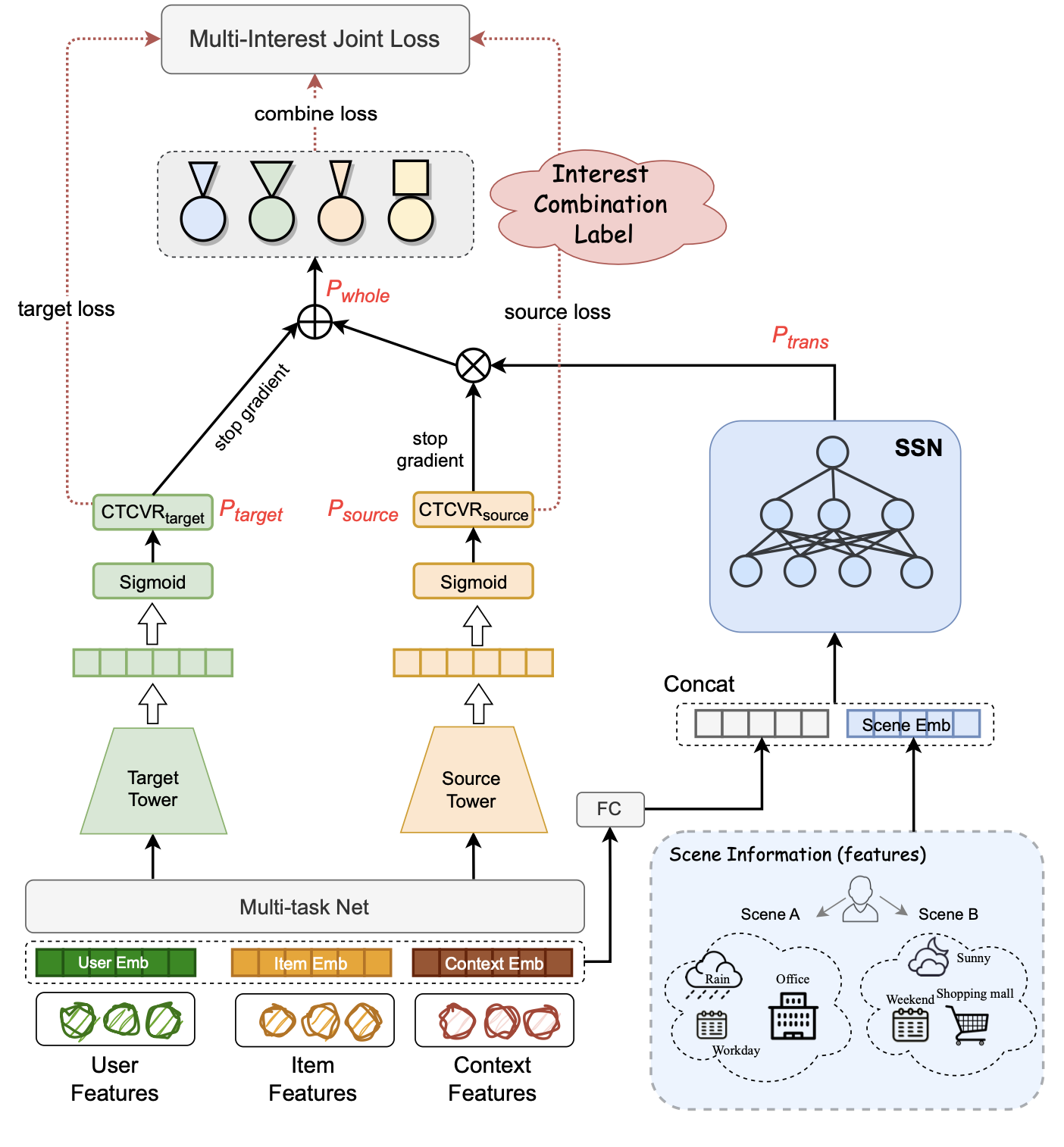
- 전체과정
-
source와 target 도메인에서 CTCVR 계산 → 각각 source interest, target interest 산출
-
prediction interest와 실제값 비교하여 source loss, target loss 산출
-
SSN을 통해 scene에 따른 interest transfer intensity 도출
-
interest와 transfer intensity를 결합하여 최종 추천 확률 산출
-
최종 확률과 Interest Combination Label 비교하여 combine loss 산출
-
세 가지 loss(source, target, combine)를 합산하여 전체 loss 계산
어떤 기준으로 Labeling을 하는지 알아야 함.
target interest와 어떻게 combine하는지 알아야 함.
-
- 세 가지 구성요소
- IPN (Interest Prediction Network)
- target, source domain의 user의 CTCVR을 예측 → Interest
- 즉, interest를 생성 및 학습하는 네트워크
- ICL (Interest Combine Label)
- user’s complete interest를 위한 ground-truth
- interest transfer process중 전달할 신호를 고를 때 사용이 됨. (supervised learning)
- SSN (Scene Selector Network)
- 사용자의 맥락 (context, scene feature)을 받아 해당 맥락에서 interest를 타겟 도메인으로 전이시키는 것이 괜찮은가?를 계산하는 네트워크
- : context embedding이 네트워크를 통해 확률값을 계산
- 세 가지 구성요소를 통해서 user’s complete interest를 얻음
- IPN (Interest Prediction Network)
3.3 Interest Prediction Network
- IPN에서는 해당 interest를 구함
3.3.1 Feature Embedding
- IPN에는 세 가지 feature가 Input으로 들어감
-
User feature (user profile), Item feature (item attributes), context feature (hour, weekday)
-
세 가지 feature를 저차원으로 임베딩한 후, 최종 feature embedding을 계산
-
: Concatenation
-
3.3.2 Multi-domain Interest Aggregation
- 여러 소스 도메인에서의 interest를 집계하여 하나의 unified representation을 구해야함
- n개의 소스 도메인이 있다면 소스 도메인 label (ground-truth)는 다음과 같음
-
사용자가 i번째 소스 도메인에서 아이템을 구매함 →
-
하나의 플랫폼 안에 많은 서브도메인이 있을 때, 각각의 서브도메인에 대한 라벨을 다 예측하려면 모델의 파라미터가 증가하고 추론 속도 하락으로 인해 도메인의 구매이력만 보는 것으로 단순화 시켰음
서브도메인에 대한 자세한 이력을 확인하지 않고 도메인의 구매이력만 본다는 것이 정교한 추천이 되지 않을 것으로 생각
-
3.3.3 Interest Prediction Tower
- feature vector representation V를 input →
- 이 target domain label인 와 동일해지도록 학습
- feature vector representation V를 input →
- 이 source domain label인 와 동일해지도록 학습
3.4 Interest Combination Label
- Interest transfer process는 타겟도메인에 전달할만한 interest만을 transfer해야하기 때문에 명확한 라벨이 필요하다. → ICL이 이 명확한 라벨임
- interest transfer probability 를 통해 Interest를 transfer할지말지를 결정
- 모델 학습 과정에서 는 타겟도메인에 유용하면 1에 가깝게, 필요없으면 0에 가깝게 유도된다.
3.4.1 Combination Label Construction
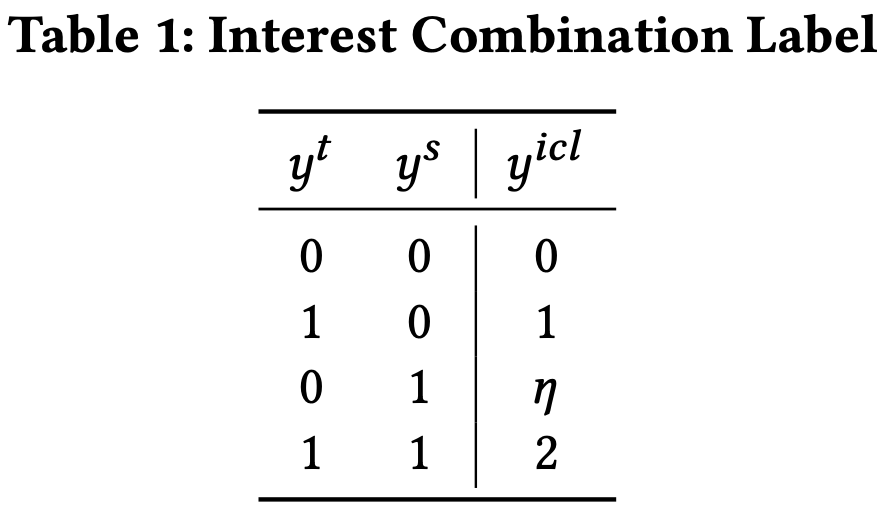
- 는 group consistency interest를 의미 → 해당 interest에 대한 다른 사람들의 반응을 본다.
- or : source domain에서 interest를 전송할 필요가 없음 → 이 되도록 학습
- : 사용자가 두 도메인에서 같은 아이템을 구매했다는 것을 나타냄 → source domain interest는 target domain으로 전이시켜야 함 → ICL을 2로 설정 이 되도록 학습
예시) 사용자가 무신사(신발-가방 도메인)에서 아디다스 신발을 구매하고, 아디다스 가방도 구매했다면, 아디다스 브랜드에 대한 선호도(Interest)는 가방도메인으로 전이시킬만하다고 판단
- : source domain의 interest를 target domain으로 전송하는 것이 불확실하다. → group consistency interest 를 통해 추가적으로 확인
예시) 사용자가 무신사 (신발-가방 도메인)에서 아디다스 신발을 구매하고, 가방은 구매하지 않았다면, 다른 사용자들은 어떤 행동을 보였는지를 본다.
만약, 다른 사용자들도 동일하게 가방은 구매하지 않았다면, 아디다스 신발에 대한 관심은 가방에서는 필요없다고 판단
다른 사용자들은 가방까지 구매했다면, 가방 도메인으로 전송시킬만하다라고 판단
3.4.2 Group Consistency Interest
- 여러 사용자들이 소스도메인과 타겟도메인에서 동일한 아이템을 구매했는데, 한 사용자는 소스도메인에서만 구매를 했다. → 추천 시스템에서는 사용자에게 추천해주지 않음 → 사용자가 진짜로 그 아이템에 관심이 없는지 아니면 몰라서 구매를 안한건지 모르기 때문에 추천을 해줘야 함
- Group Consistency Interest 수식
- 매일 업데이트할 때, spark tools를 사용하면 시간 효율적이다/
3.5 Scene Selector Network
- 사용자는 상황에 따라 interest가 달라지기 때문에 scene도 고려를 해야함
- interest transfer probability가 실제 사용자의 interest 변화와 같아지도록 transfer 강도를 학습함
예시) 사용자가 취업준비생일 때는 무신사에 캐주얼한 의류들이 추천되다가, 취업후, 포멀한 의류들이 추천되어야 한다.
취준시기, 취업후 맥락은 사용자의 행동패턴을 통해 얻을 수 있음. (평일 낮 시간대에 앱을 사용 → 평일 낮 시간대에 사용이 확 줄음) - transfer intensity 유도 과정
- user, item, context embedding을 Fully-connected layer에 입력해 concatenation embedding을 구함
- 자세한 context를 임베딩시킨 과 concatenation하여 MLP에 입력해 을 구함
- 을 다시 한 번 Fully-connected layer에 입력 후, activation function을 통해 최종 transfer intensity 를 구함
- SSN의 내부 파라미터는 (FC, MLP) ICL을 ground-truth로 설정하여 학습이 됨
- 와 의 차이?
둘 다 context feature를 담고 있지만, 은 더 자세한 정보를 담고 있음
하지만 둘 다 사람이 feature를 추출해서 저차원으로 임베딩시킨 값임
✅ [미팅 이후, 추가조사]
논문에서는 , 의 의미에 대한 내용을 자세하게 담고 있지는 않고 있음.
(하단 토글버튼에서 해당 논문의 내용을 첨부)
: 유저, 아이템, 컨텍스트 임베딩을 FC를 이용한 압축된 임베딩
: scene 정보를 강화시키기 위한 scene feature만을 모아놓은 임베딩
즉, 내의 scene feature (age, type, hour, etc.)들은 각각에 해당하는 유저, 아이템, 컨텍스트 임베딩에 속할 수 있는 값이긴 하나, scene information을 강조하기 위해서 추가적으로 lookup해서 추출한 feature 임베딩으로 생각이 됨.
는 interest에 대한 전반적인 정보를 담고 있는 것이고, 은 interest가 발생한 맥락의 정보를 집중적으로 담고 있는 것
이 둘을 결합하여 interest transfer intensity 를 구하는 것
- 첨부내용

- SSN의 중요성?
는 ICL을 ground-truth에 의해 SSN의 파라미터가 조정되므로 의존적이다. context를 보고 정하는 것이 아니라 ICL에 의해 정해지는 거 같은 느낌이 들었다.
- 와 의 차이?
3.6 Multi-Interest Joint Loss
- 해당 값은 CTCVR 값임 → 해당 값은 실제 레이블인 를 따라가며 학습
- 은 0 or 1인 이진값임 → cross-entropy를 통해 Label을 따라가도록 학습
- supervision signal인 ICL에 의해 SSN의 산출물 이 조정됨
- L1 loss
- ICL은 continuous value이기 때문에, predicted interest ()와 ICL를 L1 loss를 따라 학습
- 최종 Loss
- : Training set
- : Training sample
- : Number of training set samples
3.7 Online Serving
- 최종 예측값을 0~1 사이의 값으로 범위를 설정함.
4. Experiments
4.1 Datasets
4.1.1 Large-Scale Industrial Offline Dataset
- Meituan App을 이용하여 자체 데이터셋 구축
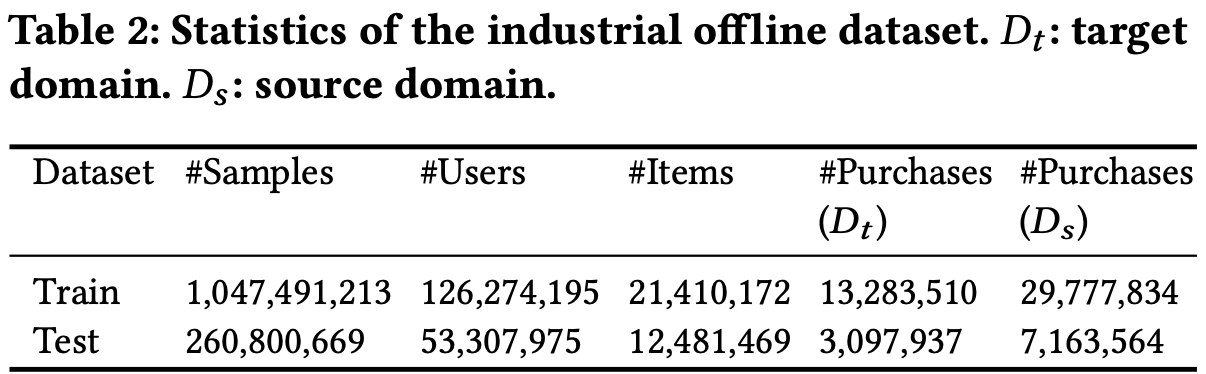
- : Homepage recommendation domain
- : Search domain & Channel section domain
- Amazon dataset은 사용자와 아이템을 동시에 공유하지 않기 때문에 사용하지 않음
4.1.2 Online Dataset
- 다양한 모델의 성능을 정확하게 평가하기 위해 온라인 서비스에서 평가를 진행함
- cross-domain 추천에서는 타겟도메인에 없던 아이템이 소스도메인의 영향으로 인해 추천이 될 수 있으므로 더 넓은 interest space가 필요함
- EXIT와 다른 baseline들을 Meituan homepage recommendation에 적용을 시켜 평가를 진행
- 각 버킷에는 백만명의 사용자 1억개의 아이템을 포함함
4.2 Compared Baselines
- Single-domain baselines: LR, DNN, DeepFM, DCN
- Cross-domain baselines: MVDNN, CoNet, MiNet, STAR, UniCDR
4.3 Evaluation Metrics
- Offline experiments:
- ROC Curve (AUC): 얼마나 잘 맞췄는지
- Logloss: 얼마나 덜 틀렸는지
- Online tests A/B (Meituan의 실제 사용중인 모델과 비교하는 테스트)
- CTCVR (Click Through Conversion Rate): 사용자가 클릭하고 얼마나 실제로 구매로 이어졌는가
- GTV (Gross Transaction Value): 아이템이 얼마나 팔렷는가 (총매출)
- NFR (Negative Feedback Rate): 사용자가 얼마나 만족을 하는가 (후기)
4.4 Parameter Settings
- Embedding dimension: 8
- Batch size: 384
- Optimizer: Adam
- 실험 방법
- Offline experiment: 3번 실행 후, 평균 결과
- Online test A/B: 7일동안 실험 후, 평균 결과
- Multi-Task Network
- EXIT: MMoE 구조를 사용하며, shared experts를 2개 사용
- target, source tower: 2-DNN layers, PReLU
- SSN
- User-side: gender, occupation, age
- Item-side: item level 1, 2, 3 category, item business
- Context-side: hour, day of the week, request page (검색, 추천, 채널 섹션), connection type (Wifi, Cellular)
- Multi-Interest joint loss
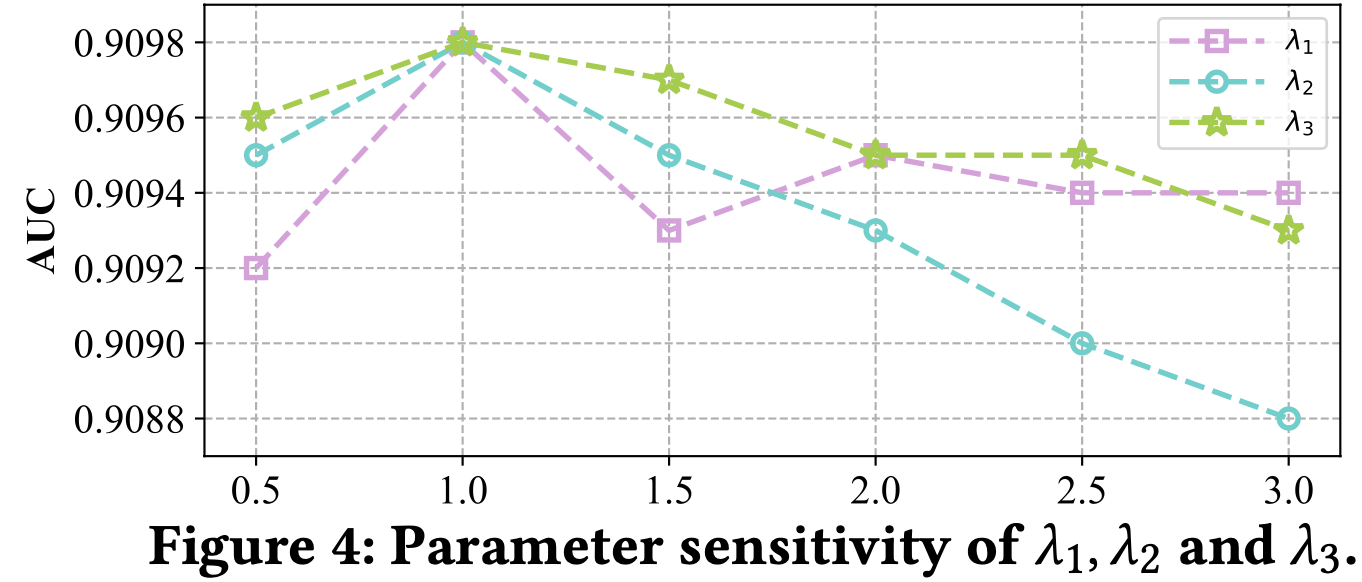
- 를 조정하며 실험 → 모두 1로 설정하는 것이 제일 잘 나왔음
4.5 Overall Performance Comparison
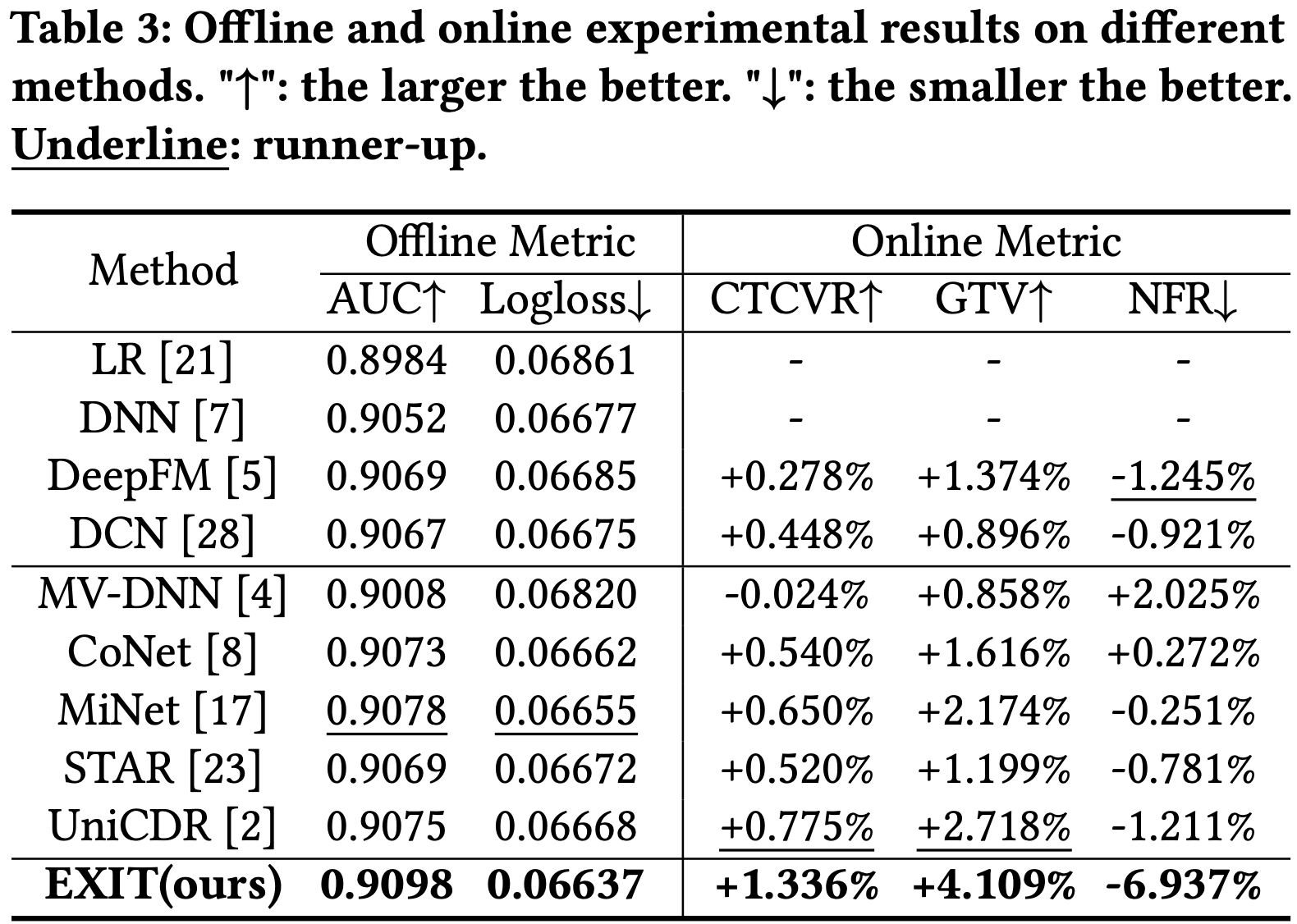
- Offline experiment: Cross-domain baseline이 Single-domain baselines보다 좋음
- Online A/B test
- CTCVR, GTV: Cross-domain baseline이 더 잘 나옴 → 이전의 논문에서 나온 NDCG와 HR과 같은 지표로만 평가하는 것이 CDR 모델의 성능을 제대로 반영하지 못함을 입증
- NFR: CDR baseline이 DeepFM, DCN보다 더 안좋게 나옴 → negative transfer 문제가 원인
- EXIT: target domain에 적합한 interest만 전이시키는 방법이 성능과 더불어 negative transfer 문제도 예방함을 입증
Introduction 부분까지만 읽었을 때의 나는 domain-shared information을 추출하는 방식이 (UniCDR, DisenCDR) 이 방법보다 더 나은지가 궁금했던 점이었는데, 실험 결과를 보고난 후, supervised learning이 더 나은 것을 알 수 있었다.
→ 이 실험은 하나의 도메인 (Meituan)내에 수많은 서브도메인 (음식배달, 호텔 예약 등)이 담겨있는 환경에서 실험을 진행했다. 하지만 여전히 내 생각은 CDR은 유사한 도메인간(의류-신발)에 사용되어야 의미가 있다고 생각하기 때문에 이러한 데이터셋인 Amazon dataset으로 실험을 했을 때의 결과도 궁금해졌음
4.6 Ablation Study
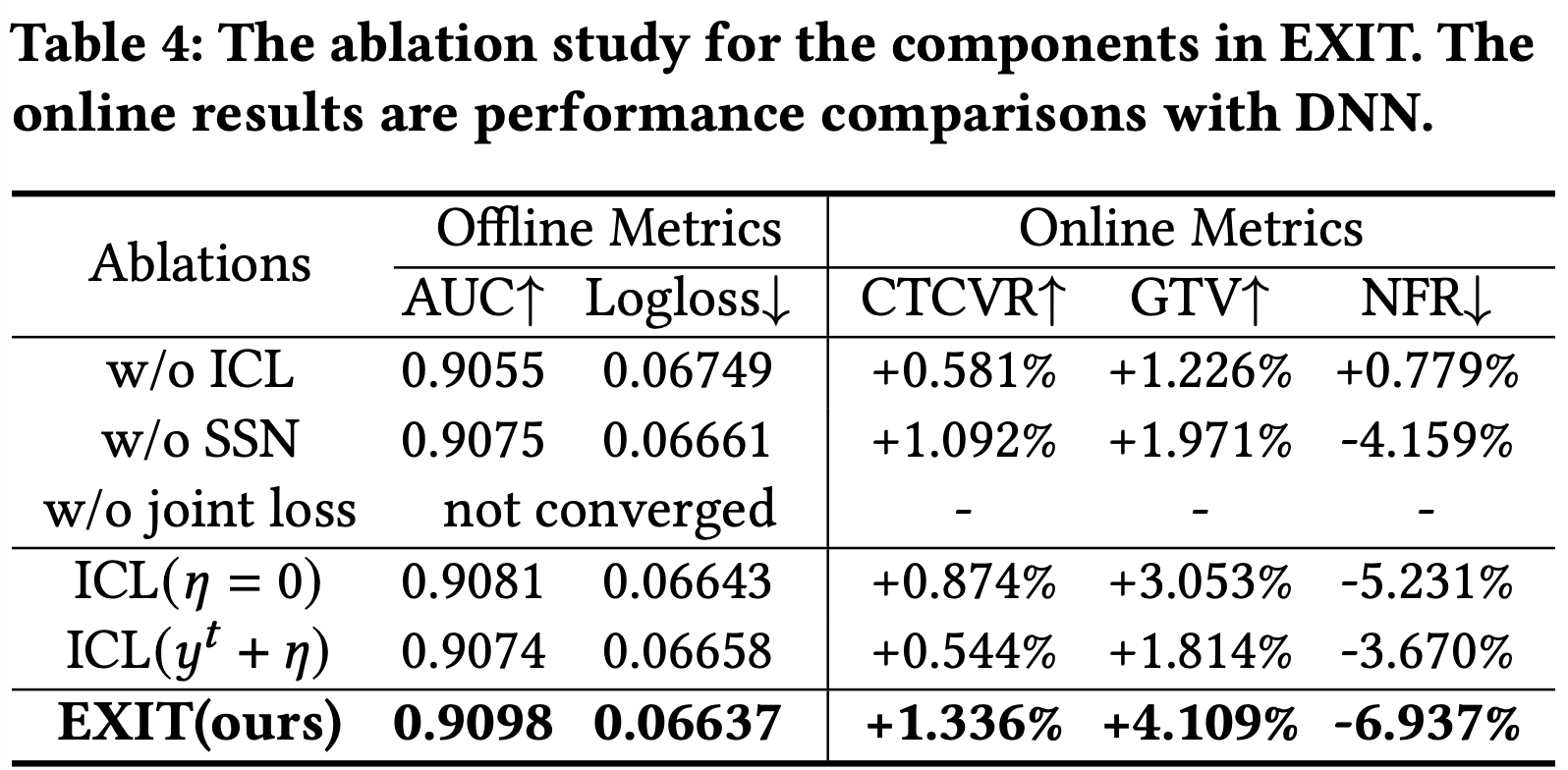
- EXIT내의 모든 components가 꼭 있어야 한다!
4.6.1 Effect of the Main Components
- ICL 제거: Unsupervised learning 방식으로 전환
- NFR이 증가하였는데, negative transfer로 인해 사용자 경험 하락
- SSN 제거: 를 산출하지 않고 를 구함
- Scene information이 중요하다
- joint loss: L1 loss, cross-entropy를 따로 사용하지 않고 L1 loss만 사용
- source domain interest와 target domain interest는 분리해서 학습하여야 함
4.6.2 Effect of the Group Consistency Interest
- : ICL을 설정할 때, 다른 사용자들의 경향도 파악하는 것
- : 사용자 개인의 성향만을 보겠다는 것을 의미
- : 모든 시나리오에서 다른 사용자들의 경향을 파악하겠다.
- 둘 다 기존의 EXIT보다 성능이 낮게 나옴 → Group Consistency Interest는 필요할 때에만 봐야 한다
4.7 Online Deployment
- EXIT를 Meituan homepage recommendation system에 배포하여 3월 2주동안 테스트를 실시하였음
- CTCVR을 예측하는 모델만 EXIT로 대체
- CTCVR: +1.23%, GTV: +3.65%, NFR: -6.62%
- EXIT의 성능을 입증시켜줌
- 현재는 교체된 상태로 서비스중임
5. Case Study
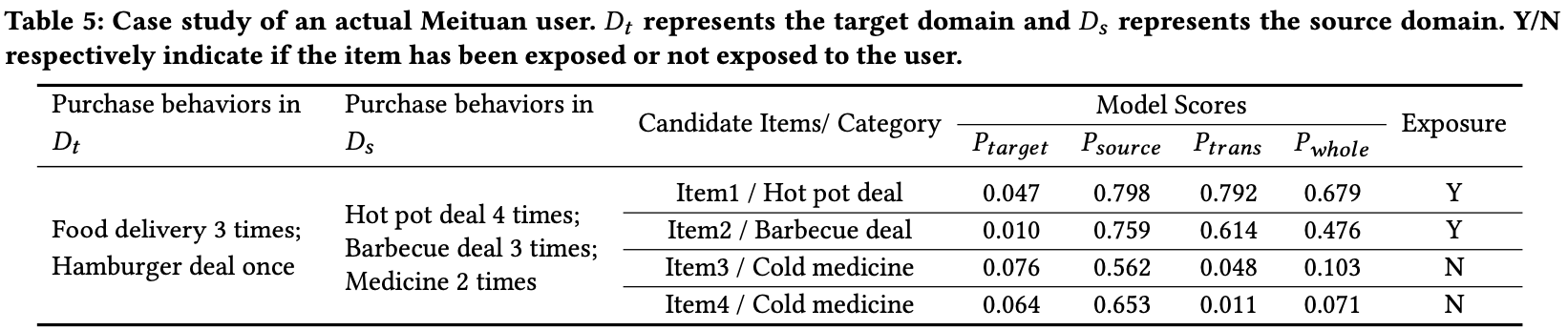
- EXIT의 내부 추론 과정을 볼 수 있음
6. Conclusion
- EXIT는 ICL을 이용한 supervised learning으로 모델을 훈련시켜 explicit interest만 도메인간 전이시킨다. → negative transfer를 예방
- ICL과 함께 SSN을 도입하여 interest transfer intensity를 조정하여 상황에 따른 정교한 추천을 진행
- Offline, Online 실험에서 모두 best performance를 달성
- 저자들은 향후 item, user의 중복없이 knowledge transfer model을 연구할 계획
EXIT 모델을 보고난 후, 이 모델은 쿠팡같은 다양한 상품군들을 판매하는 플랫폼에 적합한 모델이라는 것을 알게되었다. 물론, 저자들도 그걸 알고 Meituan이라는 플랫폼에 적용시킨 것이겠지만…
무신사와 29CM처럼 비슷한 상품군을 다루면서도 고객층과 브랜드 정체성이 달라 제품의 ‘느낌’이나 미학이 차별화되는 플랫폼에서도 효과적으로 적용될 수 있을까?
나는 CDR은 비슷한 상품군을 판매하는 플랫폼에 사용하는 것이 더 적합할 것이라 생각한다. 즉, 같은 옷이라도 무신사의 대중적 감성과 29CM의 프리미엄, 미니멀한 감성은 서로 다르므로, 도메인 간에 공유되는 정보를 추출하되 각 플랫폼에 맞게 조정하여 추천할 필요가 있다는 생각이 든다.
EXIT는 Meituan과 같은 통합 플랫폼 외에도 각 도메인의 특성에 맞는 추천이 가능한지 이런 시나리오에 대한 추가적인 실험을 진행했을 때 어땠을까 하는 생각이 들었다.
EXIT 논문은 기존에 봐왔던 CDR의 시나리오와는 다른 모습을 보이고 있다.
기존에는 카테고리가 다른 두 도메인을 대상으로 봐왔지만, EXIT에서는 하나의 플랫폼내의 검색 영역, 추천 영역을 소스-타겟 도메인으로 보고 내용을 진행한다.
CDR scenario를 다르게 볼 수 있는 시각도 있구나 하는게 이 논문을 통해 얻을 수 있는 insight이다.
