오늘은 기본적인 파이프라인 구축 예시인 iris 데이터를 활용해보겠습니다!
전체 코드는 이 레포지터리에서 클론하셔서 사용하실 수 있습니다.
전체 구조
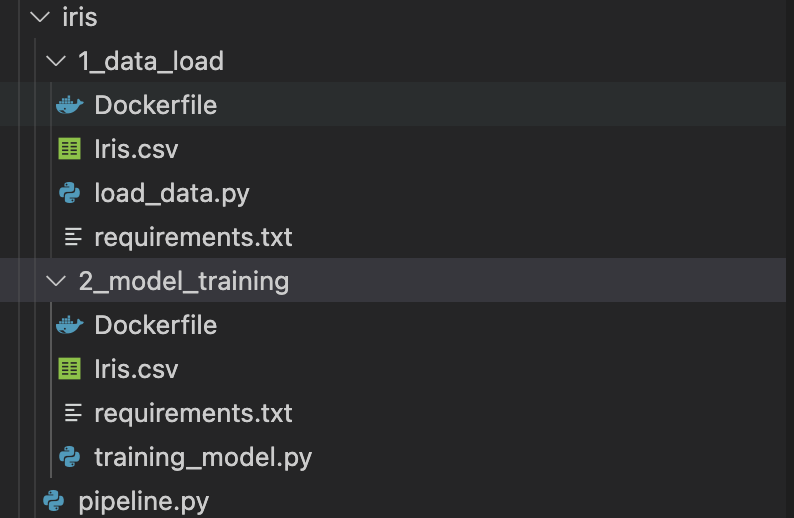
- 2개의 디렉토리와 pipeline.py 파일
- 디렉토리 : load, ML model training : kubeflow의 각 단계(컴포넌트)에 해당되는 디렉토리입니다.
- pipeline.py : kubeflow에서 사용할 파이프라인 구축 코드입니다. 파이썬 SDK(dsl)를 활용합니다.
- 각 디렉토리에는 아래와 같은 파일이 존재합니다.
- Dockerfile : kubeflow는 k8s 환경, 즉 docker container 환경을 사용합니다.(1.2버전 이후론 containerd가 기본입니다.) 그에 필요한 도커 이미지를 생성할 수 있도록 dockerfile이 존재합니다.
- 파이썬 파일 : 각 컨테이너 단계에서(쿠버플로 파이프라인 단계) 실행할 코드가 파이썬 기반으로 작성되어 있습니다.
- requirements.txt : 각 파이프라인 단계에서 파이썬 코드가 실행될 떄 필요한 패키지를 설치할 수 있도록 환경을 세팅해주는 파일입니다.
Kubeflow에서 사용하는 각 파일 설명
이제 각 파일의 세부내용을 살펴봅시다.
먼저 data_preprocessing입니다.
data_load
- 이번 예제에선 단순히 data를 load하는 용도입니다.
- 수집 및 정제 등 다양한 알고리즘을 활용할 수도 있겠죠?
파일명은 마음대로 정의해도 됩니다. 나중에 도커 파일에 잘 넣어주기만 하면 됩니다.
import pandas as pd
import argparse
if __name__ == "__main__":
argument_parser = argparse.ArgumentParser()
argument_parser.add_argument(
'--data_path', type=str,
help="Input data path"
)
args = argument_parser.parse_args()
data = pd.read_csv(args.data_path)
print(data.shape)
print("load data")
data.to_csv('/iris.csv', index=False)간단한 iris data는 케글 등에서 쉽게 다운로드 받으실 수 있습니다.(데이터를 다뤄보신 분이라면 iris data는 너무 익숙하실테니 따로 설명하진 않겠습니다.)
argument를 받는 부분이 있습니다. 현재는 단 1개의 argument, data_path를 받게 작성되어 있습니다.
이 코드는 단순히 데이터를 로드하고 shape를 확인한 후 해당 경로(/)에서 iris.csv 이름으로 데이터를 저장하도록 되어 있습니다. (이렇게 저장하는 이유는 추후 파이프라인 부분에서 설명합니다.)
이제 이 파일을 실행할 수 있도록 Dockerfile을 만들어주면 됩니다.
FROM python:3
ENV PYTHONUNBUFFERED 1
RUN mkdir /code
WORKDIR /code
COPY . /code/
RUN pip install -r requirements.txt
ENTRYPOINT ["python", "load_data.py"]requirements.txt를 만드는 방법은 다들 알고 계시겠죠?
간편하게 freeze를 사용해도 좋고, 추가로 필요한 패키지가 있다면 별도로 넣어주셔도 됩니다.
FROM 파트가 python:3로 되어 있는데 추후 training_model 부분과 다르므로 유의합시다.
ML model training
training_model.py는 로드된 데이터를 활용해 ML 모델을 만드는 코드를 구현합니다.(sklearn으로 구현되어 있습니다.)
import argparse
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from io import StringIO
def load_data(data):
d = StringIO(data)
iris = pd.read_csv(d, sep=',')
print(iris.shape)
return iris
def get_train_test_data(iris):
encode = LabelEncoder()
iris.Species = encode.fit_transform(iris.Species)
train , test = train_test_split(iris, test_size=0.2, random_state=0)
print('shape of training data : ', train.shape)
print('shape of testing data', test.shape)
X_train = train.drop(columns=['Species'], axis=1)
y_train = train['Species']
X_test = test.drop(columns=['Species'], axis=1)
y_test = test['Species']
return X_train, X_test, y_train, y_test
if __name__ == "__main__":
argument_parser = argparse.ArgumentParser()
argument_parser.add_argument(
'--data',
type=str,
help="Input data csv"
)
args = argument_parser.parse_args()
iris = args.data
iris = load_data(iris)
X_train, X_test, y_train, y_test = get_train_test_data(iris)
model = LogisticRegression()
model.fit(X_train, y_train)
predict = model.predict(X_test)
print('\nAccuracy Score on test data : ')
print(accuracy_score(y_test, predict))역시나 모델 생성코드는 마음대로 생성해도 됩니다.
다만 주의할 것이 앞에서 로드한 데이터를 data argument로 받아야 합니다.
그래서 데이터를 받을 수 있도록 설정이 필요합니다.
또한 앞선 load data 부분에서 iris.csv파일을 저장했는데 이 데이터를 파이프라인 단계에서 사용하려면 StringIO로 변환해주어야 합니다.
StringIO로 변환하는 건 Python의 from io import StringIO를 활용하면 됩니다.
마찬가지로 모델 트레이닝 컴포넌트도 도커파일을 만들어줍니다.
FROM frolvlad/alpine-python-machinelearning
ENV PYTHONUNBUFFERED 1
RUN mkdir /code
WORKDIR /code
COPY . /code/
RUN pip install -r requirements.txt
ENTRYPOINT ["python", "training_model.py"]위와는 다르게 FROM이 frolvlad/alpine-python-machinelearning로 되어 있습니다.
해당 도커 이미지는 scikit-learn이 미리 설치되어 있는 환경입니다.
따라서 해당 환경을 사용해 도커 이미지를 만듭니다.
이제 2개의 Dockerfile을 가지게 되었습니다.
하나는 데이터 load용 컨테이너, 하나는 모델 훈련을 위한 컨테이너입니다.
Kubeflow에서 사용할 Docker image 생성
위에서 kubeflow에서 사용할 Python 코드와 Dockerfile 개발을 마쳤습니다.
이 코드를 실제로 kubeflow 환경(컨테이너를 기반으로 하는 kubernetes 환경)에서 사용할 수 있도록 이미지를 만들어주고 배포합시다.
- Dockerfile이 있는 경로에서 docker build를 이용하면 됩니다.
- 데이터 전처리 디렉터리부터 시작합시다!
-docker build -t kf_iris_preprocessing .- 현재 위치라는 의미인
.을 까먹지 않도록 합니다.
- 현재 위치라는 의미인
- 이제 도커 이미지가 만들어졌습니다! 이 이미지를 사용할 수 있도록 도커 허브에 배포하도록 합시다.
- docker hub에 배포할 수 있도록 명령어에 태그를 달아줍니다.
-docker tag kf_iris_preprocessing:latest moey920/kf_iris_preprocessing:0.5
- docker hub로 push 해줍니다.docker push moey920/kf_iris_preprocessing:0.5
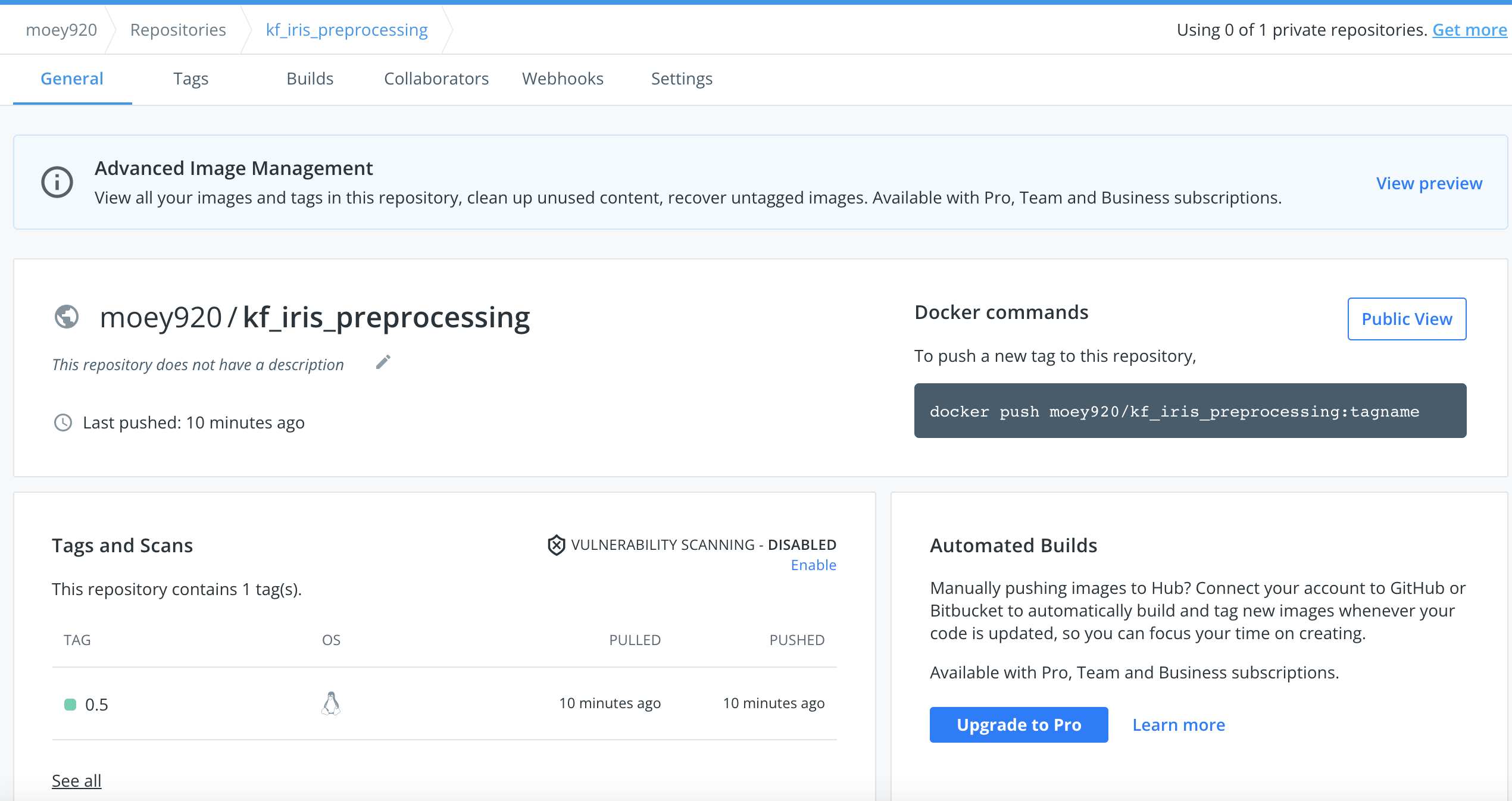
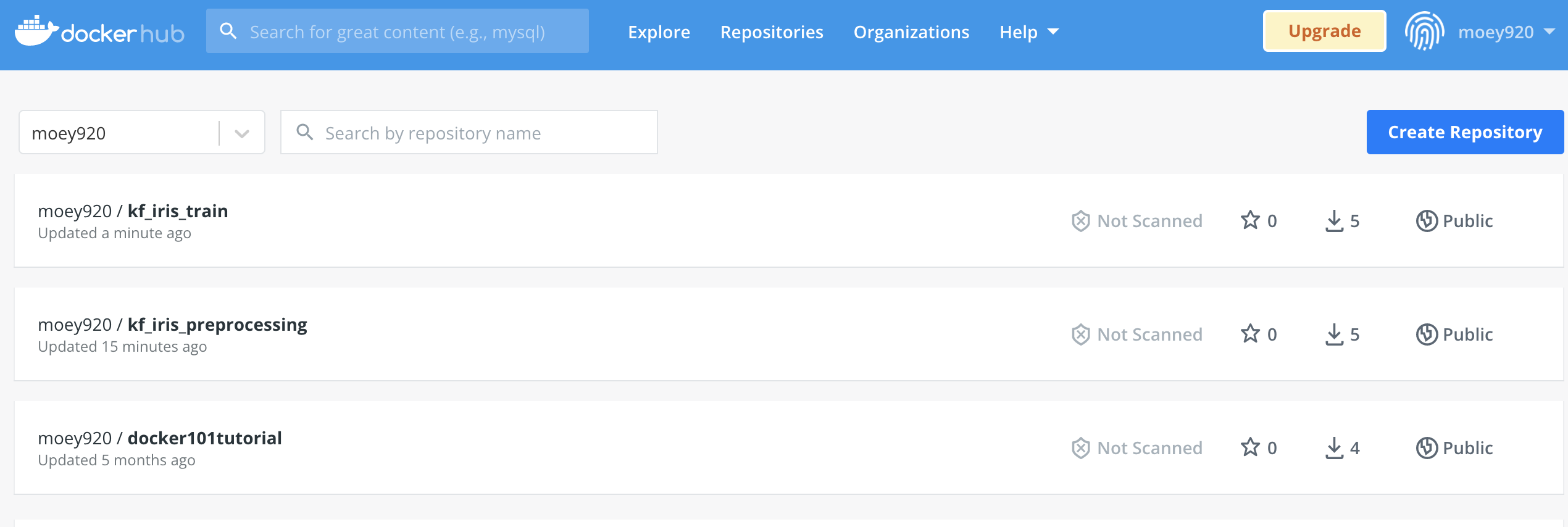
- 도커 허브에 들어가보면 이미지가 정상적으로 push된 것을 확인할 수 있습니다.
- model_training 디렉토리도 동일하게 진행해줍니다.
-docker build -t kf_iris_train .
-docker tag kf_iris_train:latest moey920/kf_iris_train:0.5
-docker push moey920/kf_iris_train:0.5
Kubeflow 사용을 위한 Pipeline 코드 구축
이전 포스팅에서 Pipeline을 구현하는 방법 중 하나로 파이썬 SDK를 이용해봤습니다.
이번에서 kfp라는 패키지를 활용해서 파이프라인을 구축해봅시다.
import kfp
import kfp.components as comp
from kfp import dsl
@dsl.pipeline(
name='kf-iris',
description='musma rnd iris test'
)
def kf_iris_pipeline():
add_p = dsl.ContainerOp(
name="load iris data pipeline",
image="moey920/kf_iris_preprocessing:0.5",
arguments=[
'--data_path', './Iris.csv'
],
file_outputs={'iris' : '/iris.csv'}
)
ml = dsl.ContainerOp(
name="training pipeline",
image="moey920/kf_iris_train:0.5",
arguments=[
'--data', add_p.outputs['iris']
]
)
ml.after(add_p)
if __name__ == "__main__":
import kfp.compiler as compiler
compiler.Compiler().compile(kf_iris_pipeline, __file__ + ".tar.gz")중요한 부분은 다음과 같습니다.
- 파이프라인 이름 구성
name='kf-iris' - 파이프라인 함수 생성
def kf_iris_pipeline(): - 각 파이프라인에서 사용되는 name과 image(도커 컨테이너를 만들기 위한 이미지), 그리고 각 컨테이너 환경에서 사용되는 arguments 설정(아까 파이썬 파일을 구현할 때 argument를 지정했죠?)
- ml.after(add_p)와 같은 순서
- 순서에서 ml 부분은 arguments로 add_p에서 나온output['iris']를 사용합니다.- add_p 부분에서 자세히 보면
file_outputs={'iris' : '/iris.csv'}으로 구현되었는데, 해당 부분은 load_data.py에서 저장한 경로를 지정한 것입니다.
- add_p 부분에서 자세히 보면
kubeflow에서 사용되는 파이프라인 단계의 도커 이미지는 이전에 만들어놨던 이미지들을 사용하면 됩니다.
이렇게 pipeline.py 파일이 구출되었으면 아래와 같은 명령어로 tar.gz 파일을 생성해줍니다.
dsl-compile --py pipeline.py --output kf_iris_pipeline.tar.gz

Kubeflow에서 파이프라인 실행
-
pipeline을 클릭한 후 upload pipeline, create
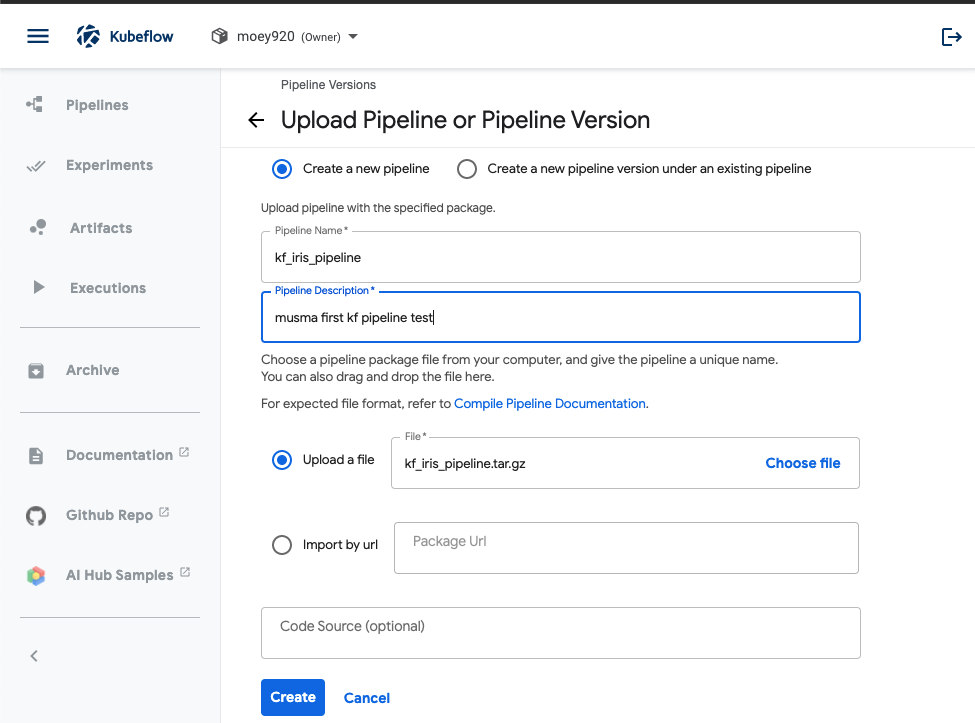
-
정상적으로 진행되셨다면 pipeline graph가 나옵니다. 여기서 experiment까지 생성해봅시다. +Create experiment 버튼을 클릭합니다.
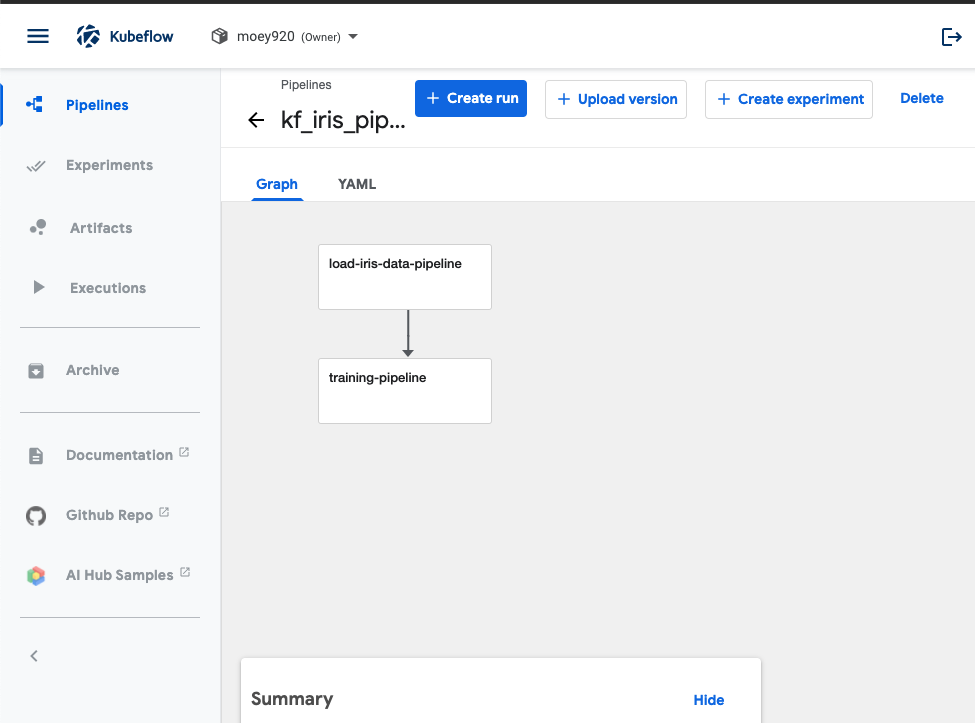
-
experiment 이름을 입력하고 넘어갑니다.
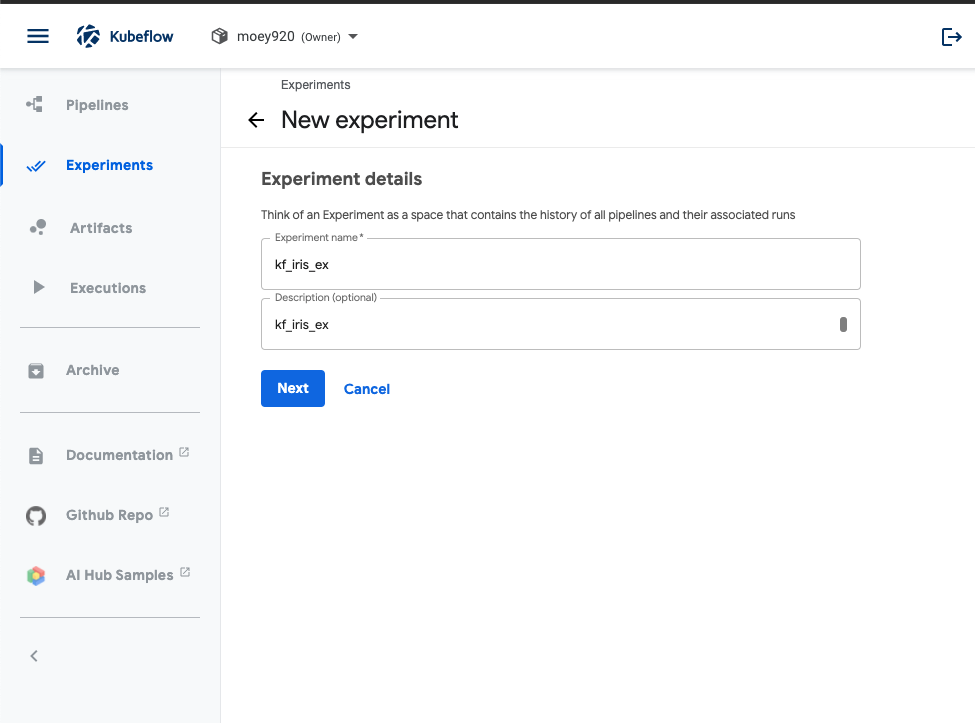
-
파이프라인-experiment-run을 생성하면 자동으로 필수 사항들이 입력하고 Run을 Start 하는 버튼이 나옵니다. Run을 실행해봅시다!
-
Run을 실행시킨 Experiments 페이지로 리다이렉션되고, 여기서 Run name을 클릭하거나 Status를 확인하면 상태를 확인해볼 수 있습니다.
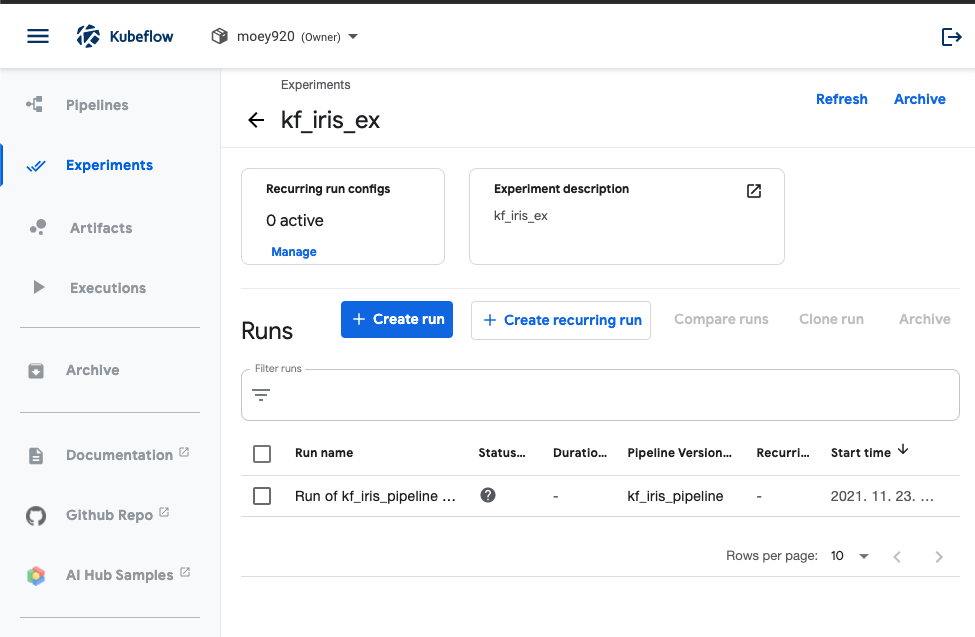
-
그래프의 각 단계를 클릭하면 로그를 확인할 수 있습니다. 원래는 간단한 데이터로 만든 워크플로라 빠르게 실행이 되야하는데 저는 아직도 ContainerCreating 단계에 빠져있네요.
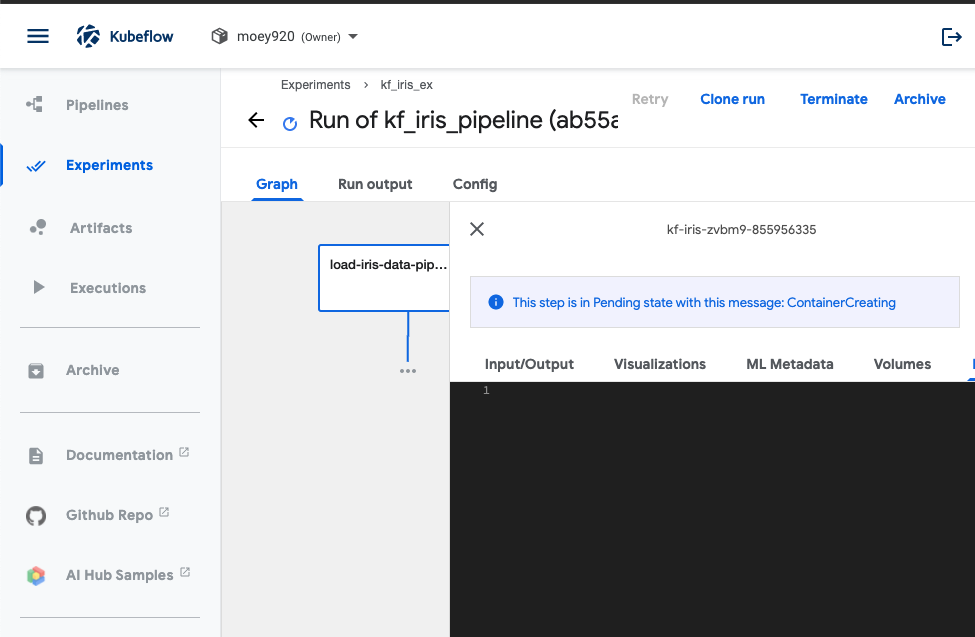
-
그래프는 2단계가 생성됩니다. 전부 초록색 상태로 바뀌면(빨간색은 실패, 그대로 대기중인 상태라면 k8s 개발환경에 뭔가 문제가 있는 것입니다.) 성공입니다.
- log를 보면 실제로 정확도를 측정한 로그값을 확인할 수 있습니다. 이제 실제로 파이프라인을 실행시켜봤습니다. 고생하셨습니다!
이슈
Experiments, Run 삭제
파이프라인과 다르게 Experiments와 Run에서는 Delete 버튼이 없습니다.
experiments - run에서 각 Run을 체크한 후 Archive 버튼을 누르면 해당 런을 Archive할 수 있습니다.
이후에 Archive에 들어가 각 런을 체크한 후 Delete해주시면 됩니다.
experiments는 어떻게 삭제하는지 모르겠습니다.
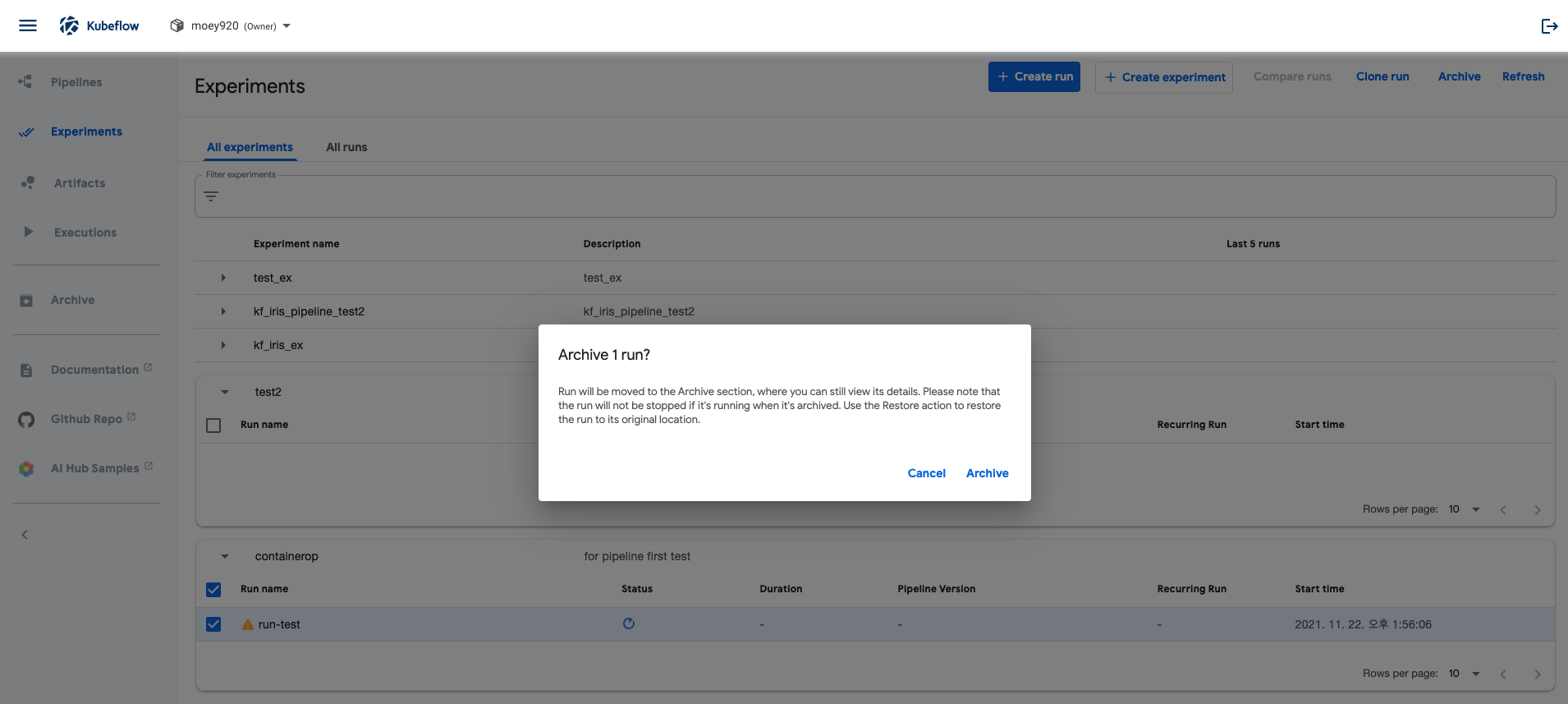
Pipeline Run Error
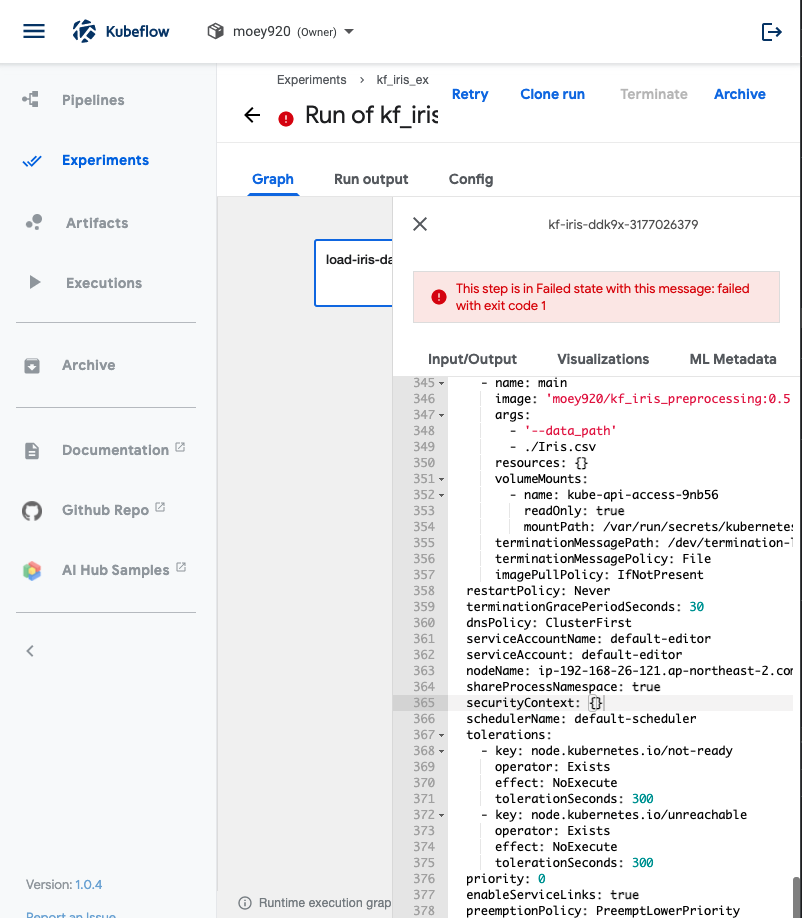
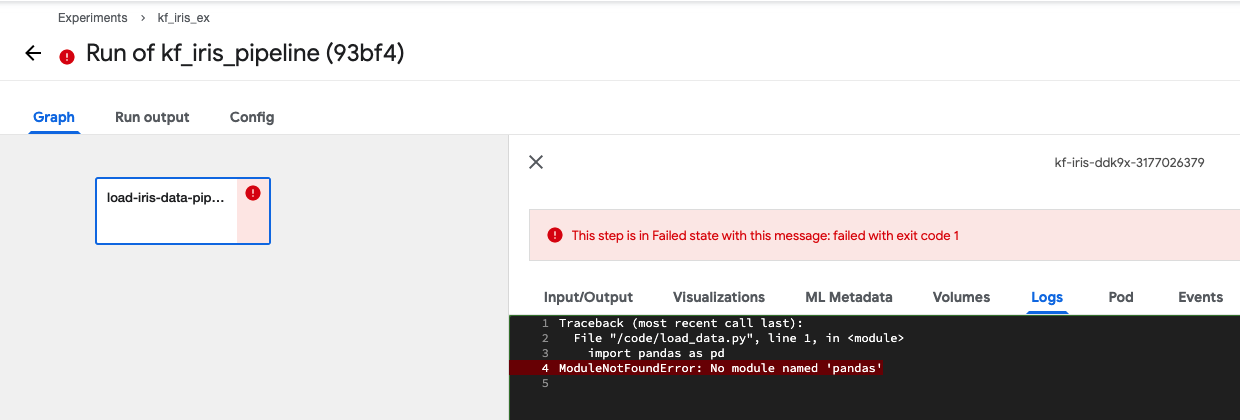
- Run logs를 확인해보니 모듈을 찾을 수 없다는 에러가 나옵니다.
- 도커 파일을 만들 때 사용한 requirments.txt를 확인해보니 내용이 비어있군요. 다시 작성하여 도커 이미지 빌드부터 다시 시작해보겠습니다.
- 깃 허브 내용은 requirments.txt를 수정하여 merge 해놓을 것이나, 혹시 필요하신 분은 아래를 참고해주시기 바랍니다.
- 1. data_preprocessing :pandas==1.2.4 argparse==1.4.0
- 2. model_training :
attrs==21.2.0
cachetools==4.2.4
certifi==2021.10.8
charset-normalizer==2.0.7
click==8.0.3
cloudpickle==2.0.0
Deprecated==1.2.13
docstring-parser==0.12
fire==0.4.0
google-api-core==1.31.3
google-api-python-client==1.12.8
google-auth==1.35.0
google-auth-httplib2==0.1.0
google-cloud-core==2.1.0
google-cloud-storage==1.42.3
google-crc32c==1.3.0
google-resumable-media==2.1.0
googleapis-common-protos==1.53.0
httplib2==0.20.2
idna==3.3
importlib-metadata==4.8.1
joblib==1.1.0
jsonschema==3.2.0
kfp==1.8.9
kfp-pipeline-spec==0.1.13
kfp-server-api==1.7.1
kubernetes==18.20.0
numpy==1.21.4
oauthlib==3.1.1
packaging==21.2
pandas==1.3.4
protobuf==3.17.3
pyasn1==0.4.8
pyasn1-modules==0.2.8
pydantic==1.8.2
pyparsing==2.4.7
pyrsistent==0.18.0
python-dateutil==2.8.2
pytz==2021.3
PyYAML==5.4.1
requests==2.26.0
requests-oauthlib==1.3.0
requests-toolbelt==0.9.1
rsa==4.7.2
scikit-learn==1.0.1
scipy==1.7.2
six==1.16.0
strip-hints==0.1.10
tabulate==0.8.9
termcolor==1.1.0
threadpoolctl==3.0.0
typer==0.4.0
typing-extensions==3.10.0.2
uritemplate==3.0.1
urllib3==1.26.7
websocket-client==1.2.1
wrapt==1.13.3
zipp==3.6.0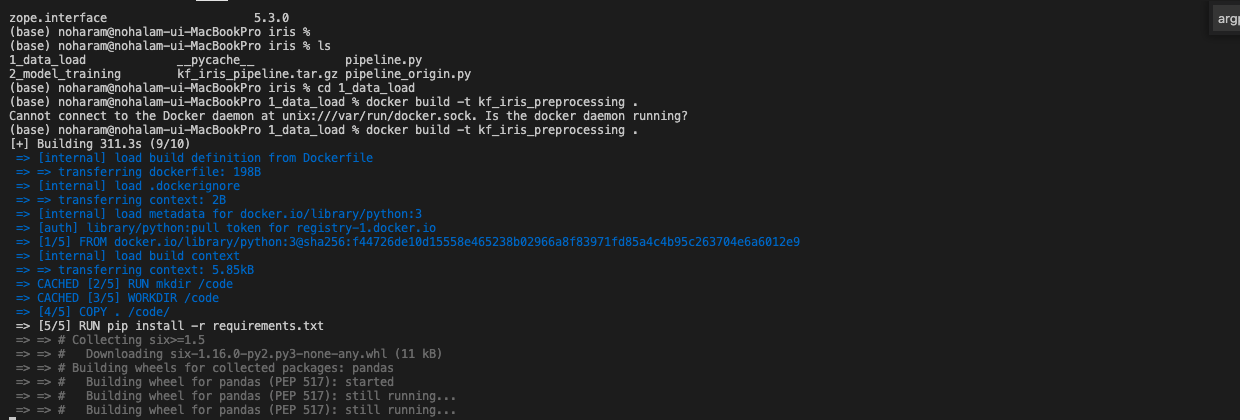
클러스터 내 SDK를 사용하여 jupyter notebook에서 Kubeflow Pipeline 인증
- kfp를 사용하기 위해 쿠키를 KFP에 전달해야 합니다. kubeflow에 로그인한 후 다음 단계에 따라 쿠키를 가져옵니다.
- 관리자 도구 - Application - Storage - Cookies - AWSELBAuthSessionCookie-0
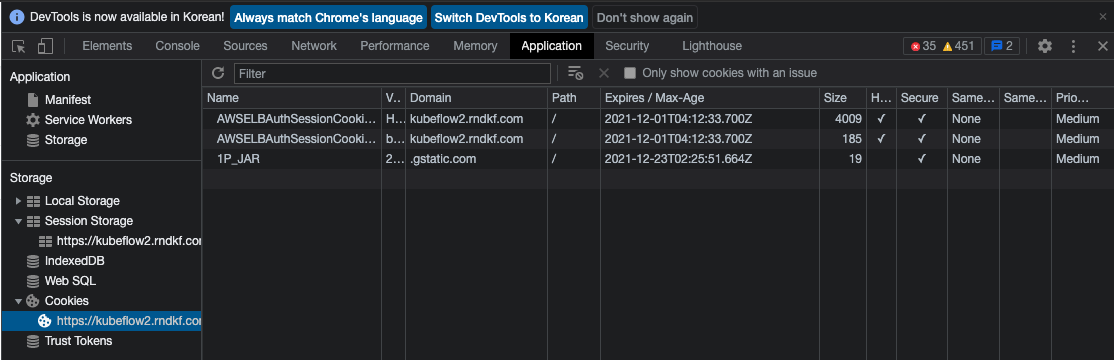
- 관리자 도구 - Application - Storage - Cookies - AWSELBAuthSessionCookie-0
- 쿠키를 얻으면 kfp에 cookies를 전달하여 인증할 수 있습니다. 매니페스트를 기반으로 한 코드 스니펫을 살펴보세요.
kubectl get ingress -n istio-system에서 ADDRESS 필드 값을 가져오면 됩니다.
import kfp
alb_session_cookie0='AWSELBAuthSessionCookie-0=<cookie0>'
alb_session_cookie1='AWSELBAuthSessionCookie-1=<cookie1>'
client = kfp.Client(host='https://<aws_alb_host>/pipeline', cookies=f"{alb_session_cookie0};{alb_session_cookie1}")
client.list_experiments(namespace="<your_namespace>")