대체로 직역되었으나, 의역한 부분이 있음을 인지하고 읽어주시면 감사하겠습니다.
data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
data2vec: 음성, 시각 및 언어의 자가 지도 학습을 위한 일반 프레임워크
0. Abstract
While the general idea of self-supervised learning is identical across modalities, the actual algorithms and objectives differ widely because they were developed with a single modality in mind.
To get us closer to general self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech, NLP or computer vision.
The core idea is to predict latent representations of the full input data based on a masked view of the input in a selfdistillation setup using a standard Transformer architecture.
Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input.
Experiments on the major benchmarks of speech recognition, image classification, and natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
Models and code are available at www.github.com/pytorch/fairseq/
tree/master/examples/data2vec.자기 지도 학습의 일반적인 아이디어는 모든 방식에서 동일하지만 실제 알고리즘과 목표는 단일 방식을 염두에 두고 개발되었기 때문에 크게 다릅니다.
(자기 지도 학습의 일반적인 아이디어는 동일하지만, Task에 따라 실제 알고리즘과 목표는 크게 다릅니다.)
일반적인 자기 지도 학습에 더 가까워지기 위해 음성, NLP 또는 컴퓨터 비전에 대해 동일한 학습 방법을 사용하는 프레임워크인 data2vec 를 제시합니다.
핵심 아이디어는 표준 Transformer 아키텍처를 사용하는 자체 증류 설정(selfdistillation setup)에서 입력의 마스크된 보기를 기반으로 전체 입력 데이터의 잠재된 표현을 예측하는 것입니다.
(keras distillation 참고)
본질적으로 지역적인 단어, 시각적 토큰 또는 인간의 언어 단위와 같은 양식별 대상(modality-specific targets)을 예측하는 대신 data2vec는 전체 입력의 정보를 포함하는 상황에 맞는 잠재 표현을 예측합니다.
-> (단어, 언어, 시각토큰 같은 양식에 맞는 대상을 예측하는 대신 전체 입력 정보를 포함하는 상황 별 잠재 표현을 예측합니다)
음성 인식, 이미지 분류 및 자연어 이해의 주요 벤치마크에 대한 실험은 새로운 기술 상태 또는 지배적인 접근 방식에 대한 경쟁력 있는 성능을 보여줍니다.
모델과 코드는 [github](Models and code are available at www.github.com/pytorch/fairseq/ tree/master/examples/data2vec.)에서 확인할 수 있습니다.
1. Introduction
Self-supervised learning builds representations of data without human annotated labels which led to significant advances in natural language processing (NLP; Peters et al. 2018; Radford et al. 2018; Devlin et al. 2019; Brown et al. 2020), speech processing (van den Oord et al., 2018; Schneider et al., 2019; Baevski et al., 2020b) as well as computer vision (Chen et al., 2020; 2021b; Caron et al., 2021; Bao et al., 2021; He et al., 2021).
Self-supervised representations have even enabled completely unsupervised learning in tasks such as machine translation (Lample et al., 2018) and speech recognition (Baevski et al., 2021).자기 지도 학습은 인간의 주석이 달린 레이블 없이 데이터 표현을 구축하여 자연어 처리, 음성 처리 및 컴퓨터 비전에서 상당한 발전을 가져왔습니다.
자가 지도 표현은 기계 번역 및 음성 인식과 같은 작업에서 완전히 비지도 학습을 가능하게 했습니다.
Research in self-supervised algorithms has focused on individual modalities which results in specific designs and learning biases.
For example, in speech processing, there is no vocabulary of speech units over which we can define a self-supervised learning task such as words in NLP1 and therefore several prominent models are equipped with mechanisms to learn an inventory of speech units (Baevski et al.,2020b; Hsu et al., 2021).
A similar problem exists for computer vision, where researchers either learn discrete visual tokens (Radford et al., 2021a; Bao et al., 2021), regress the input (He et al., 2021) or learn representations invariant to data augmentation (Chen et al., 2020; Grill et al., 2020; Caron et al., 2021).자체 지도 알고리즘에 대한 연구는 특정 설계 및 학습 편향을 초래하는 개별 양식에 초점을 맞추었습니다.
예를 들어, 음성 처리에는 NLP1의 단어와 같은 자체 지도 학습 작업을 정의할 수 있는 음성 단위의 어휘가 없으므로 여러 저명한 모델에는 음성 단위 목록을 학습하는 메커니즘이 장착되어 있습니다.
연구원이 입력을 회귀하는 개별 시각적 토큰을 배우거나 데이터 증대에 대한 불변 표현을 학습하는 컴퓨터 비전에도 유사한 문제가 있습니다.
While learning biases are certainly helpful, it is often unclear whether they will generalize to other modalities.
Moreover, leading theories on the biology of learning (Friston & Kiebel, 2009; Friston, 2010) imply that humans likely use similar learning processes to understand the visual world as they do for language.
Relatedly, general neural network architectures have been shown to perform very well compared to modality-specific counterparts (Jaegle et al., 2021).학습 편향은 확실히 도움이 되지만 다른 양식으로 일반화할지 여부는 종종 불분명합니다.
더욱이, 학습 생물학에 관한 주요 이론은 인간이 언어를 이해하는 것처럼 시각적 세계를 이해하기 위해 유사한 학습 과정을 사용할 가능성이 있음을 암시합니다.
이와 관련하여 일반적인 신경망 아키텍처는 모달리티(양식)별 대응물에 비해 매우 잘 수행되는 것으로 나타났습니다.
In an effort to get closer to machines that learn in general ways about the environment, we designed data2vec, a framework for general self-supervised learning that works for images, speech and text where the learning objective is identical in each modality.
The present work unifies the learning algorithm but still learns representations individually for each modality.
We hope that a single algorithm will make future multi-modal learning simpler, more effective and lead to models that understand the world better through multiple modalities.일반적으로 환경에 대해 학습하는 기계에 더 가까이 다가가기 위해 우리는 학습 목표가 각 모달리티에서 동일한 이미지, 음성 및 텍스트에 대해 작동하는 일반 자가 지도 학습을 위한 프레임워크인 data2vec를 설계했습니다.
현재 작업은 학습 알고리즘을 통합하지만 여전히 각 양식에 대해 개별적으로 표현을 학습합니다.
단일 알고리즘이 미래의 다중 모드 학습을 더 간단하고 효과적으로 만들고 다중 모드를 통해 세상을 더 잘 이해하는 모델로 이어지기를 바랍니다.
Our method combines masked prediction (Devlin et al., 2019; Baevski et al., 2020b; Bao et al., 2021) with the learning of latent target representations (Grill et al., 2020; Caron et al., 2021) but generalizes the latter by using multiple network layers as targets and shows that this approach works across several modalities.
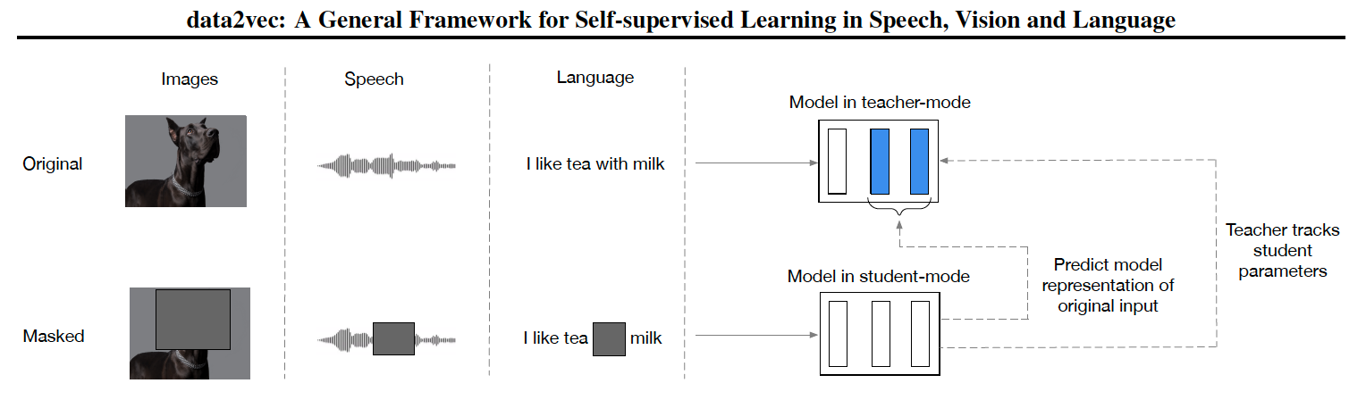
Specifically, we train an off-theshelf Transformer network (Vaswani et al., 2017) which we use either in teacher or student mode (Illustration in Figure 1): we first build representations of the full input data whose purpose is to serve as targets in the learning task (teacher mode).
Next, we encode a masked version of the input sample with which we predict the full data representations (student mode).
The weights of the teacher are an exponentially decaying average of the student (He et al., 2019; Grill et al., 2020; Caron et al., 2021).
Since different modalities have vastly different inputs, e.g., pixels vs. words, we use modality-specific feature encoders and masking strategies from the literature.우리의 방법은 마스킹된 예측과 잠재 목표 표현의 학습을 결합하지만 다중 네트워크 계층을 목표로 사용하여 후자를 일반화하고 이 접근 방식이 여러 양식에 걸쳐 작동함을 보여줍니다.
특히, 우리는 교사 또는 학생 모드에서 사용하는 기성품 Transformer 네트워크를 훈련합니다(그림 1의 그림).
먼저 학습 과제(교사 모드)의 대상 역할을 하는 목적을 가진 전체 입력 데이터의 표현을 구축합니다. .
다음으로 전체 데이터 표현(학생 모드)을 예측하는 입력 샘플의 마스크된 버전을 인코딩합니다.
교사의 가중치는 기하급수적으로 감소하는 학생의 평균입니다.
다른 양식은 픽셀 대 단어와 같이 입력이 매우 다르기 때문에 문헌의 양식별 기능 인코더 및 마스킹 전략을 사용합니다.
Since our method works with the latent network representations of the learner itself, it can be seen as a simplification of many modality-specific designs such as learning a fixed set of visual tokens (Radford et al., 2021a; van den Oord et al., 2017), or normalization of the input to create suitable targets (He et al., 2021), or the learning of a vocabulary of discrete speech units (Baevski et al., 2020b; Hsu et al., 2021).
Moreover, our target representations are continuous and contextualized, through the use of self-attention, which makes them richer than a fixed set of targets and/or targets based on local context such as used in most prior work.우리의 방법은 학습자 자체의 잠재 네트워크 표현과 함께 작동하기 때문에 고정된 시각적 토큰 세트 학습과 같은 많은 양식별 설계의 단순화로 볼 수 있습니다.
또는 입력을 정규화하여 적합한 대상을 생성하거나 이산 언어 단위의 어휘 학습을 포함합니다.
더욱이, 우리의 목표 표현은 self-attention의 사용을 통해 지속적이고 맥락화되어 대부분의 이전 작업에서 사용된 것과 같은 지역적 맥락을 기반으로 하는 고정된 목표 및/또는 목표보다 더 풍부합니다.
Experimental results show data2vec to be effective in all three modalities, setting a new state of the art for ViT-B with single models and ViT-L on ImageNet-1K, improving over the best prior work in speech processing on speech recognition (Baevski et al., 2020b; Hsu et al., 2021) and outperforming a like for like RoBERTa baseline on the GLUE natural language understanding benchmark (Liu et al., 2019).실험 결과는 data2vec가 세 가지 방식 모두에서 효과적인 것으로 나타났으며, 단일 모델을 사용하여 ViT-B와 ImageNet-1K의 ViT-L에 대한 새로운 기술을 설정하고 음성 인식에 대한 음성 처리에서 최고의 이전 작업을 개선하고 성능을 능가합니다. GLUE 자연어 이해 벤치마크에 대한 RoBERTa 기준선과 같습니다.
2. Related Work
Self-supervised learning in computer vision.
Unsupervised pre-training for computer vision has been a very active area of research with methods contrasting representations of augmentations of the same image, entirely different images (Chen et al., 2020; Grill et al., 2020; Caron et al., 2021; Chen et al., 2021b) as well as online clustering (Caron et al., 2020).
Similar to our work, both BYOL (Grill et al., 2020) and DINO (Caron et al., 2021) regress neural network representations of a momentum encoder, but our work differs in that it uses a masked prediction task and we regress multiple neural network layer representations instead of just the top layer which we find to be more effective.
Moreover, data2vec works for multiple modalities The most recent work focuses on training vision Transformers (Dosovitskiy et al., 2020) with masked prediction objectives (Bao et al., 2021; He et al., 2021; Xie et al., 2021) whose performance surpasses supervised-only training on ImageNet-1K. Several of these methods predict visual tokens (Bao et al., 2021; He et al., 2021; Dong et al., 2022) learned in a separate step before pre-training (van den Oord et al., 2017; Ramesh et al., 2021), during pretraining (Zhou et al., 2021), and others directly predict the input pixels (He et al., 2021; Xie et al., 2021).
Instead, data2vec predicts the latent representations of the input data. Another difference to this body of work is that the latent target representations are contextualized, incorporating relevant features from the entire image instead of targets which contain information isolated to the current patch, such as visual tokens or pixels.컴퓨터 비전에 대한 감독되지 않은 사전 훈련은 온라인 클러스터링뿐만 아니라 동일한 이미지, 완전히 다른 이미지의 증강 표현을 대조하는 방법으로 매우 활발한 연구 영역이었습니다.
우리의 작업과 유사하게 BYOL과 DINO는 모두 운동량 인코더의 신경망 표현을 회귀하지만 우리 작업은 마스크 예측 작업을 사용하고 우리가 더 많이 찾은 최상위 계층 대신 여러 신경망 계층 표현을 회귀한다는 점에서 다릅니다. 효과적인.
또한, data2vec는 여러 양식에 대해 작동합니다. 가장 최근 작업은 ImageNet-1K에 대한 감독 전용 교육을 능가하는 성능이 마스크된 예측 목표를 사용하여 비전 Transformers를 교육하는 데 중점을 둡니다. 이러한 방법 중 일부는 사전 훈련 전, 사전 훈련 중에 별도의 단계에서 학습된 시각적 토큰을 예측하고 다른 방법은 입력 픽셀을 직접 예측합니다.
대신, data2vec는 입력 데이터의 잠재된 표현을 예측합니다. 이 작업의 또 다른 차이점은 잠재적인 대상 표현이 컨텍스트화되어 시각적 토큰이나 픽셀과 같이 현재 패치에 격리된 정보를 포함하는 대상 대신 전체 이미지의 관련 기능을 통합한다는 것입니다.
Self-supervised learning in NLP.
Pre-training has been very successful in advancing natural language understanding (McCann et al., 2017; Peters et al., 2018; Radford et al., 2018; Baevski et al., 2019; Devlin et al., 2019; Yang et al., 2019; Brown et al., 2020).
The most prominent model is BERT (Devlin et al., 2019) which solves a masked prediction task where some of the input tokens are blanked out in order to be predicted given the remaining input.
For many languages it is easy to determine word boundaries and most methods therefore predict word or sub-word units for pretraining.
There is also work on knowledge distillation to obtain smaller BERT-style models, both for pre-training and fine-tuning (Jiao et al., 2020).
Compared to prior NLP algorithms, data2vec does not predict discrete linguistic tokens such as words, sub-words or bytes but rather a continuous and contextualized representation.
This has two advantages: first, the targets themselves are not predefined, nor is their number limited. This enables the model to adapt to a particular input example.
Second, targets are contextualized, taking context information into account.
This is unlike BERT-style models which learn a single embedding for each target which needs to fit all instances of a particular target in the data.사전 교육은 자연어 이해를 향상시키는 데 매우 성공적이었습니다.
가장 눈에 띄는 모델은 나머지 입력이 주어지면 예측하기 위해 일부 입력 토큰이 비어 있는 마스킹된 예측 작업을 해결하는 BERT입니다.
많은 언어의 경우 단어 경계를 결정하기 쉽고 대부분의 방법은 사전 훈련을 위해 단어 또는 하위 단어 단위를 예측합니다.
사전 훈련 및 미세 조정을 위해 더 작은 BERT 스타일 모델을 얻기 위한 지식 증류 작업도 있습니다.
이전 NLP 알고리즘과 비교하여 data2vec는 단어, 하위 단어 또는 바이트와 같은 개별 언어 토큰이 아니라 연속적이고 상황에 맞는 표현을 예측합니다.
여기에는 두 가지 장점이 있습니다. 첫째, 대상 자체가 미리 정의되지 않고 숫자도 제한되지 않습니다. 이렇게 하면 모델이 특정 입력 예제에 적응할 수 있습니다.
둘째, 대상은 컨텍스트 정보를 고려하여 컨텍스트화됩니다.
이것은 데이터에서 특정 대상의 모든 인스턴스에 맞아야 하는 각 대상에 대해 단일 임베딩을 학습하는 BERT 스타일 모델과 다릅니다.
Self-supervised learning in speech.
Work in selfsupervised learning for speech includes autoregressive models (van den Oord et al., 2018; Schneider et al., 2019; Baevski et al., 2020a; Chung et al., 2019) as well as bidirectional models (Baevski et al., 2020b; Hsu et al., 2021; Ao et al., 2021; Chen et al., 2021a).
Two prominent models, wav2vec 2.0 and HuBERT are based on predicting discrete units of speech, either learned jointly during pretraining (Baevski et al., 2020b), or in an iterative pipeline approach (Hsu et al., 2021) where pre training and clustering alternate.2 Another line of work directly reconstructs the input features (Eloff et al., 2019; Liu et al., 2021).
In comparison to wav2vec 2.0, data2vec directly predicts contextualized latent representations without quantization.
HuBERT discretizes representations from different layers across iterations and predicts these discretized units whereas data2vec predicts the average over multiple layers.
Similar to other modalities, there is work on distilling larger selfsupervised models into smaller models but primarily for the purpose of efficiency (Chang et al., 2021).음성에 대한 자기 지도 학습 작업에는 양방향 모델뿐만 아니라 자기회귀 모델이 포함됩니다.
두 가지 유명한 모델인 wav2vec 2.0 및 HuBERT는 사전 훈련 동안 공동으로 학습되거나 사전 훈련과 클러스터링이 교대로 학습되는 반복 파이프라인 접근 방식에서 이산 음성 단위 예측을 기반으로 합니다.2개의 또 다른 작업 라인은 입력 기능을 직접 재구성합니다.
wav2vec 2.0과 비교하여 data2vec는 양자화 없이 컨텍스트화된 잠재 표현을 직접 예측합니다.
HuBERT는 반복에 걸쳐 서로 다른 레이어의 표현을 이산화하고 이러한 이산화된 단위를 예측하는 반면 data2vec는 여러 레이어에 대한 평균을 예측합니다.
다른 양식과 유사하게 더 큰 자체 지도 모델을 더 작은 모델로 증류하는 작업이 있지만 주로 효율성을 목적으로 합니다.
Multimodal pre-training.
There has been a considerable body of research on learning representations of multiple modalities simultaneously often using paired data (Aytar et al., 2017; Radford et al., 2021b; Wang et al., 2021; Singh et al., 2021) with the aim to produce cross-modal representations which can perform well on multi-modal tasks and with modalities benefiting from each other through joint training (Alayrac et al., 2020; Akbari et al., 2021) with recent methods exploring few-shot learning (Tsimpoukelli et al., 2021).
Our work does not perform multimodal training but aims to unifiy the learning objective for self-supervised learning in different modalities.
We hope that this will enable better multimodal representations in the future.종종 쌍을 이루는 데이터를 사용하여 여러 양식의 표현을 동시에 학습하는 것에 대한 상당한 연구가 있었습니다다중 모드 작업에서 잘 수행할 수 있는 교차 모드 표현을 생성하는 것을 목표로 하며, 최근 몇 번의 학습을 탐구하는 방법을 사용하여 공동 훈련을 통해 양식이 서로에게 도움이 됩니다.
우리의 작업은 다중 모드 교육을 수행하지 않지만 다양한 모드에서 자기 지도 학습을 위한 학습 목표를 통합하는 것을 목표로 합니다.
이것이 미래에 더 나은 다중 모드 표현을 가능하게 하기를 바랍니다
3. Method
data2vec is trained by predicting the model representations of the full input data given a partial view of the input (Figure 1).
We first encode a masked version of the training sample (model in student mode) and then construct training targets by encoding the unmasked version of the input with the same model but when parameterized as an exponentially moving average of the model weights (model in teacher mode; Grill et al. 2020; Caron et al. 2021).
The target representations encode all of the information in the training sample and the learning task is for the student to predict these representations given a partial view of the input.data2vec는 입력의 부분적인 보기가 주어지면 전체 입력 데이터의 모델 표현을 예측하여 훈련됩니다(그림 1).
우리는 먼저 훈련 샘플의 마스크된 버전(학생 모드의 모델)을 인코딩한 다음 마스크되지 않은 버전의 입력을 동일한 모델로 인코딩하여 훈련 목표를 구성하지만 모델 가중치의 기하급수적으로 이동하는 평균으로 매개변수화할 때(교사 모드의 모델).
목표 표현은 훈련 샘플의 모든 정보를 인코딩하고 학습 과제는 입력에 대한 부분적인 보기가 주어졌을 때 학생이 이러한 표현을 예측하는 것입니다.
3.1. Model architecture
We use the standard Transformer architecture (Vaswani et al., 2017) with a modality-specific encoding of the input data borrowed from prior work:3 for computer vision, we use the ViT-strategy of encoding an image as a sequence of patches, each spanning 16x16 pixels, input to a linear transformation (Dosovitskiy et al., 2020; Bao et al., 2021).
Speech data is encoded using a multi-layer 1-D convolutional neural network that maps 16 kHz waveform to 50 Hz representations (Baevski et al., 2020b).
Text is pre-processed to obtain sub-word units (Sennrich et al., 2016; Devlin et al., 2019), which are then embedded in distributional space via learned embedding vectors.
We detail these methods below (§4).우리는 이전 작업에서 빌린 입력 데이터의 양식별 인코딩과 함께 표준 Transformer 아키텍처를 사용합니다. 각각 16x16 픽셀에 걸쳐 선형 변환에 입력됩니다.
음성 데이터는 16kHz 파형을 50Hz 표현에 매핑하는 다층 1D 컨벌루션 신경망을 사용하여 인코딩됩니다.
텍스트는 사전 처리되어 하위 단어 단위를 얻은 다음 학습된 포함 벡터를 통해 분포 공간에 포함됩니다.
아래에서 이러한 방법을 자세히 설명합니다(§4).
3.2. Masking
After the input sample has been embedded as a sequence of tokens, we mask part of these units by replacing them with a learned MASK embedding token and feed the sequence to the Transformer network.
For computer vision, we follow the block-wise masking strategy of Bao et al. (2021), for speech we mask spans of latent speech representations (Baevski et al., 2020b) and for language we mask tokens (Devlin et al., 2019); §4 details each strategy.입력 샘플이 토큰 시퀀스로 포함된 후 학습된 MASK 포함 토큰으로 교체하여 이러한 단위의 일부를 마스킹하고 시퀀스를 Transformer 네트워크에 공급합니다.
컴퓨터 비전의 경우 Bao et al.의 블록별 마스킹 전략을 따릅니다. 음성의 경우 잠재 음성 표현의 범위를 마스킹하고 언어의 경우 토큰을 마스킹합니다. §4는 각 전략을 자세히 설명합니다.
3.3. Training targets
The model is trained to predict the model representations of the original unmasked training sample based on an encoding of the masked sample.
We predict model representations only for time-steps which are masked.
The representations we predict are contextualized representations, encoding the particular time-step but also other information from the sample due to the use of self-attention in the Transformer network.4 This is an important difference to BERT (Devlin et al., 2019), wav2vec 2.0 (Baevski et al., 2020b) or BEiT, MAE, SimMIM, and MaskFeat (Bao et al., 2021; He et al., 2021; Xie et al., 2021; Wei et al., 2021) which predict targets lacking contextual information.
Below, we detail how we parameterize the teacher which predicts the network representations that will serve as targets as well as how we construct the final target vectors to be predicted by the model in student-mode.모델은 마스크된 샘플의 인코딩을 기반으로 원래의 마스크되지 않은 훈련 샘플의 모델 표현을 예측하도록 훈련됩니다.
마스킹된 시간 단계에 대해서만 모델 표현을 예측합니다.
우리가 예측하는 표현은 컨텍스트화된 표현이며, 특정 시간 단계를 인코딩하지만 Transformer 네트워크에서 self-attention을 사용하기 때문에 샘플의 다른 정보도 인코딩합니다. 4 이것은 BERT의 중요한 차이점입니다. 또는 BEiT, MAE, SimMIM 및 MaskFeat 상황 정보가 부족한 대상을 예측합니다.
아래에서는 타겟으로 사용될 네트워크 표현을 예측하는 교사를 매개변수화하는 방법과 학생 모드에서 모델이 예측할 최종 타겟 벡터를 구성하는 방법을 자세히 설명합니다.
Teacher parameterization.
The encoding of the unmasked training sample is parameterized by an exponentially moving average (EMA) of the model parameters (θ; Tarvainen & Valpola 2018; Grill et al. 2020; Caron et al. 2021) where the weights of the model in target-mode ∆ are:
`∆ ← τ∆ + (1 − τ ) θ`
We use a schedule for τ that linearly increases this parameter from τ0 to the target value τe over the first τn updates after which the value is kept constant for the remainder of training.
This strategy results in the teacher being updated more frequently at the beginning of training, when the model is random, and less frequently later in training, when good parameters have already been learned.
We found it more efficient and slightly more accurate to share the parameters of the feature encoder and the positional encoder between the teacher and student networks.마스킹되지 않은 훈련 샘플의 인코딩은 모델 매개변수의 지수 이동 평균(EMA)에 의해 매개변수화됩니다. 모드 ∆는 다음과 같습니다.
∆ ← τ∆ + (1 − τ) θ
첫 번째 τn 업데이트에 대해 이 매개변수를 τ0에서 목표 값 τe까지 선형적으로 증가시키는 τ에 대한 일정을 사용하고 그 후 값은 나머지 교육 동안 일정하게 유지됩니다.
이 전략을 사용하면 모델이 무작위인 경우 학습 시작 시 교사가 더 자주 업데이트되고, 좋은 매개변수가 이미 학습된 경우 학습 후반에는 덜 자주 업데이트됩니다.
우리는 교사와 학생 네트워크 간에 특징 인코더와 위치 인코더의 매개변수를 공유하는 것이 더 효율적이고 약간 더 정확하다는 것을 발견했습니다.
Targets.
Training targets are constructed based on the output of the top K blocks of the teacher network for time-steps which are masked in student-mode.
The output of block l at time-step t is denoted as [image1].
We apply a normalization to each block to obtain[image2] before averaging the top K blocks [image3] for a network with L blocks in total to obtain the training target yt for time-step t.
This creates training targets that are to be regressed by the model when in student mode.
In preliminary experiments we found that averaging performed as well as predicting each block separately with a dedicated projection while enjoying the advantage of being more efficient.시간 단계 t에서 블록 l의 출력은 [이미지1]로 표시됩니다.
시간 단계 t에 대한 훈련 목표 yt를 얻기 위해 총 L 블록이 있는 네트워크에 대해 상위 K 블록[이미지3]을 평균화하기 전에 각 블록에 정규화를 적용하여 [이미지2]를 얻습니다.
이것은 학생 모드에 있을 때 모델에 의해 회귀될 훈련 목표를 생성합니다.
예비 실험에서 우리는 평균이 더 효율적이라는 이점을 누리면서 전용 투영으로 각 블록을 개별적으로 예측할 뿐만 아니라 수행됨을 발견했습니다.
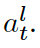
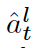
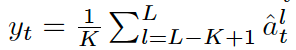
Normalizing the targets helps prevent the model from collapsing into a constant representation for all time-steps and it also prevents layers with high norm to dominate the target features.
For speech representations, we use instance normalization (Ulyanov et al., 2016) without any learned parameters over the current input sample since neighboring representations are highly correlated due to the small stride over the input data, while for NLP and vision we found parameter-less layer normalization (Ba et al., 2016) to be sufficient.
Variance-Invariance-Covariance regularization (Bardes et al., 2021) also addresses this problem but we found the above strategy to perform well and it does not introduce additional hyper-parameters.대상을 정규화하면 모델이 모든 시간 단계에 대한 일정한 표현으로 축소되는 것을 방지할 수 있으며 높은 기준을 가진 레이어가 대상 기능을 지배하는 것도 방지할 수 있습니다.
음성 표현의 경우 현재 입력 샘플에 대해 학습된 매개변수 없이 인스턴스 정규화를 사용합니다. 왜냐하면 인접 표현은 입력 데이터에 대한 작은 보폭으로 인해 높은 상관관계가 있기 때문입니다. 반면 NLP 및 비전의 경우 매개변수- 더 적은 레이어 정규화로 충분합니다.
Variance-Invariance-Covariance regularization도 이 문제를 해결하지만 위의 전략이 잘 수행되고 추가 하이퍼 매개변수를 도입하지 않는다는 것을 발견했습니다.
3.4. Objective
Given contextualized training targets yt, we use a Smooth L1 loss to regress these targets:
where β controls the transition from a squared loss to an L1 loss, depending on the size of the gap between the target yt and the model prediction ft(x) at time-step t.
The advantage of this loss is that it is less sensitive to outliers, however, we need to tune the setting of β.상황에 맞는 훈련 목표 yt가 주어지면 Smooth L1 손실을 사용하여 다음 목표를 회귀합니다.
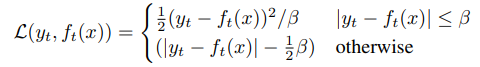
여기서 β는 시간 단계 t에서 목표 yt와 모델 예측 ft(x) 사이의 간격 크기에 따라 제곱 손실에서 L1 손실로의 전환을 제어합니다.
이 손실의 장점은 이상치에 덜 민감하지만 β 설정을 조정해야 한다는 것입니다.
4. Experimental setup
We experiment with two model sizes: data2vec Base and data2vec Large, containing either L = 12 or L = 24 Transformer blocks with H = 768 or H = 1024 hidden dimension (with 4 × H feed-forward inner-dimension).
EMA updates are performed in fp32 for numerical stability (Manohar et al., 2021).우리는 L = 12 또는 L = 24 H = 768 또는 H = 1024 은닉 차원(4 × H 피드포워드 내부 차원 포함)의 Transformer 블록 중 하나를 포함하는 data2vec Base 및 data2vec Large의 두 가지 모델 크기로 실험합니다.
EMA 업데이트는 수치적 안정성을 위해 fp32에서 수행됩니다.
4.1. Computer vision
We embed images of 224x224 pixels as patches of 16x16 pixels (Dosovitskiy et al., 2020).
Each patch is linearly transformed and a sequence of 196 representations is input to a standard Transformer.
We follow BEiT (Bao et al., 2021) by masking blocks of multiple adjacent patches where each block contains at least 16 patches with a random aspect ratio.
Different to their work, we found it more accurate to mask 60% of the patches instead of 40%. We use randomly applied resized image crops, horizontal flipping, and color jittering (Bao et al., 2021).
We use the same modified image both in teacher mode and student mode.224x224 픽셀의 이미지를 16x16 픽셀의 패치로 포함합니다.
각 패치는 선형으로 변환되고 196개의 표현 시퀀스가 표준 변환기에 입력됩니다.
우리는 BEiT에 따라 각 블록이 임의의 종횡비를 가진 최소 16개의 패치를 포함하는 여러 인접 패치의 블록을 마스킹합니다.
그들의 작업과 달리 우리는 패치의 40% 대신 60%를 마스크하는 것이 더 정확하다는 것을 발견했습니다. 무작위로 적용된 크기 조정된 이미지 자르기, 수평 뒤집기 및 색상 지터링을 사용합니다.
교사 모드와 학생 모드에서 동일한 수정 이미지를 사용합니다.
ViT-B models are pre-trained for 800 epochs.
As batch size we use 2,048 for ViT-B and 8,192 for ViT-L.
We use Adam (Kingma & Ba, 2015) and a cosine schedule (Loshchilov & Hutter, 2016) with a single cycle where we warm up the learning rate for 40 epochs to 0.002 for ViT-B and for 80 epochs to 0.001 for ViT-L after which the learning rate is annealed following the cosine schedule.
For ViT-B and ViT-L, we use β = 2, K = 6 and τ = 0.9998 as a constant value with no schedule which worked well.
We use stochastic depth with rate 0.2 (Huang et al., 2016).
For ViT-L, we train for 1,600 epochs in total, the first 800 epochs use τ = 0.9998, we then reset the learning rate schedule and the teacher weights to the student and continue for another 800 epochs with τ = 0.9999.ViT-B 모델은 800 Epoch 동안 사전 훈련됩니다.
배치 크기로 ViT-B의 경우 2,048개, ViT-L의 경우 8,192개를 사용합니다.
Adam과 코사인 일정을 사용하여 ViT-B의 경우 40 epoch의 학습률을 0.002로, ViT-의 경우 80 epoch의 학습률을 0.001로 워밍업합니다. L 그 후 학습률은 코사인 일정에 따라 어닐링됩니다.
ViT-B 및 ViT-L의 경우 β = 2, K = 6 및 τ = 0.9998을 일정 값이 없는 상수 값으로 사용합니다.
비율 0.2의 확률론적 깊이를 사용합니다.
ViT-L의 경우 총 1,600 epoch 동안 훈련하고 처음 800 epoch는 τ = 0.9998을 사용한 다음 학습률 일정과 교사 가중치를 학생에게 재설정하고 τ = 0.9999로 다른 800 epoch 동안 계속합니다.
For image classification we mean-pool the output of the last Transformer block and input it to a softmax-normalized classifier.
We fine-tune ViT-B for 100 epochs and ViT-L for 50 epochs using Adam and a cosine schedule where we warmup up the learning rate for 20 epochs to 0.004 for ViT-B and for 5 epochs to 0.004 for ViT-L after which the learning rate follows the cosine schedule.
We build on the open source implementation of BEiT (Bao et al., 2021).이미지 분류를 위해 우리는 마지막 Transformer 블록의 출력을 의미 풀링하고 이를 softmax-normalized 분류기에 입력합니다.
Adam과 코사인 일정을 사용하여 100 Epoch에 대해 ViT-B를 미세 조정하고 ViT-B에 대해 0.004로, ViT-L에 대해 5 Epoch에 대해 0.004로 워밍업하는 코사인 일정을 사용하여 ViT-L을 미세 조정합니다. 학습률은 코사인 일정을 따릅니다.
우리는 BEiT의 오픈 소스 구현을 기반으로 합니다.
4.2. Speech processing
Models are implemented in fairseq (Ott et al., 2019) and take as input 16 kHz waveform which is processed by a feature encoder (Baevski et al., 2020b) containing seven temporal convolutions with 512 channels, strides (5,2,2,2,2,2,2) and kernel widths (10,3,3,3,3,2,2).
This results in an encoder output frequency of 50 Hz with a stride of about 20ms between each sample, and a receptive field of 400 input samples or 25ms of audio.
The raw waveform input to the encoder is normalized to zero mean and unit variance.모델은 Fairseq에서 구현되고 512개 채널, 스트라이드(5,2,2,2,2,2,2) 및 커널 너비(10,3,3,3,3,2,2)를 가집니다.
그 결과 각 샘플 사이에 약 20ms의 보폭과 400개의 입력 샘플 또는 25ms의 오디오의 수용 필드가 있는 50Hz의 인코더 출력 주파수가 생성됩니다.
인코더에 대한 원시 파형 입력은 제로 평균 및 단위 분산으로 정규화됩니다.
The masking strategy for the Base model is also identical to Baevski et al. (2020b): we sample p = 0.065 of all time-steps to be starting indices and mask the subsequent ten time-steps.
This results in approximately 49% of all time-steps to be masked for a typical training sequence.
During pre-training we linearly anneal τ using τ0 = 0.999, τe = 0.9999 and τn = 30, 000, average the top K = 8 blocks as targets and found a simple L2 loss to work well.Base 모델의 마스킹 전략도 Baevski et al.과 동일합니다.
시작 인덱스가 될 모든 시간 단계의 p = 0.065를 샘플링하고 후속 10개 시간 단계를 마스킹합니다.
그 결과 일반적인 훈련 시퀀스에 대해 모든 시간 단계의 약 49%가 마스킹됩니다.
사전 훈련 동안 τ0 = 0.999, τe = 0.9999 및 τn = 30,000을 사용하여 τ를 선형으로 어닐링하고 상위 K = 8 블록을 목표로 평균화하고 간단한 L2 손실이 잘 작동함을 찾았습니다.
We optimize with Adam (Kingma & Ba, 2015), with a peak learning rate of 5 × 10−4 for data2vec Base.
The Base model uses a tri-stage scheduler which linearly warms up the learning rate over the first 3% of updates, holds it for 90% of updates and then linearly decays it over the remaining 7%.
We train data2vec Base for 400K updates with a batch size of 63 minutes of audio (61M frames).
We follow the fine-tuning regime of wav2vec 2.0 (Baevski et al., 2020b) whose hyper-parameters depend on the labeled data setup.우리는 Adam을 사용하여 최적화했으며 data2vec Base에 대한 최대 학습률은 5 × 10−4입니다.
기본 모델은 업데이트의 처음 3%에 대해 학습률을 선형적으로 워밍업하고 업데이트의 90% 동안 유지한 다음 나머지 7%에 대해 선형적으로 감쇠하는 3단계 스케줄러를 사용합니다.
63분 오디오(61M 프레임)의 배치 크기로 400K 업데이트를 위해 data2vec Base를 훈련합니다.
하이퍼 매개변수가 레이블이 지정된 데이터 설정에 따라 달라지는 wav2vec 2.0의 미세 조정 체제를 따릅니다.
4.3. Natural language processing
We build on the BERT re-implementation RoBERTa (Liu et al., 2019) available in fairseq (Ott et al., 2019).
The input data is tokenized using a byte-pair encoding (Sennrich et al., 2016) of 50K types and the model learns an embedding for each type (Devlin et al., 2019; Liu et al., 2019) Once the data is embedded, we apply the BERT masking strategy to 15% of uniformly selected tokens: 80% are replaced by a learned mask token, 10% are left unchanged and 10% are replaced by randomly selected vocabulary token; we do not use the next-sentence prediction task.
We also consider the wav2vec 2.0 strategy of masking spans of four tokens For pre-training we use τ0 = 0.999, τe = 0.9999 and τn = 100, 000, K = 10 and set β = 4.
The model is optimized with Adam over 1M updates using a tri-stage learning rate schedule (5%, 80% and 15% of updates for warm-up, holding and linearly decaying, respectively).
The peak learning rate is 2 × 10−4.
We train on 16 GPUs with a Table 1.
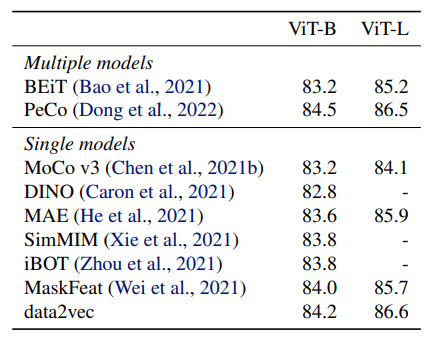
Computer vision: top-1 validation accuracy on ImageNet1K with ViT-B and ViT-L models.
data2vec ViT-B was trained for 800 epochs and ViT-L for 1,600 epochs.
We distinguish between individual models and setups composed of multiple models (BEiT/PeCo train separate visual tokenizers and PeCo also distills two MoCo-v3 models).우리는 Fairseq에서 사용할 수 있는 BERT 재구현 RoBERTa를 기반으로 합니다.
입력 데이터는 50K 유형의 바이트 쌍 인코딩을 사용하여 토큰화되고 모델은 각 유형에 대한 임베딩을 학습합니다. 임베디드, 우리는 균일하게 선택된 토큰의 15%에 BERT 마스킹 전략을 적용합니다. 80%는 학습된 마스크 토큰으로 대체되고, 10%는 변경되지 않고 남아 있고 10%는 무작위로 선택된 어휘 토큰으로 대체됩니다. 우리는 다음 문장 예측 작업을 사용하지 않습니다.
우리는 또한 4개의 토큰의 범위를 마스킹하는 wav2vec 2.0 전략을 고려합니다. 사전 훈련을 위해 τ0 = 0.999, τe = 0.9999 및 τn = 100, 000, K = 10을 사용하고 β = 4로 설정합니다.
모델은 3단계 학습률 일정(각각 워밍업, 유지 및 선형 감쇠에 대한 업데이트의 5%, 80% 및 15%)을 사용하여 1백만 개 이상의 Adam 업데이트로 최적화되었습니다.
최대 학습률은 2 × 10−4입니다.
우리는 표 1을 사용하여 16개의 GPU에서 훈련합니다.
컴퓨터 비전: ViT-B 및 ViT-L 모델이 있는 ImageNet1K에서 최고의 검증 정확도.
data2vec ViT-B는 800 epoch 동안 훈련되었고 ViT-L은 1,600 epoch 동안 훈련되었습니다.
우리는 개별 모델과 여러 모델로 구성된 설정을 구분합니다(BEiT/PeCo는 별도의 시각적 토크나이저를 교육하고 PeCo는 두 개의 MoCo-v3 모델도 증류합니다).
total batch size of 256 sequences and each sequence is up to 512 tokens.
For downstream tasks, we fine-tune the pretrained model with four different learning rates (1 × 10^−5, 2 × 10^−5, 3 × 10^−5, 4 × 10^−5) and choose the one which performs best across all considered NLP downstream tasks.256개 시퀀스의 총 배치 크기와 각 시퀀스는 최대 512개의 토큰입니다.
다운스트림 작업의 경우 사전 훈련된 모델을 4가지 다른 학습률(1 × 10^−5, 2 × 10^−5, 3 × 10^−5, 4 × 10^−5)로 미세 조정하고 고려된 모든 NLP 다운스트림 작업에서 가장 잘 수행되는 다음 중 하나를 선택합니다.
5. Result
5.1. Computer vision
To evaluate our approach for computer vision, we pretrain data2vec on the images of the ImageNet-1K training
set (Deng et al., 2009) and fine-tune the resulting model
for image classification using the labeled data of the same
benchmark (§4.1). Following standard practice, models
are evaluated in terms of top-1 accuracy on the validation
set. We distinguish between results based on a single selfsupervised model, and results which train a separate visual
tokenizer on additional data (Bao et al., 2021) or distill other
self-supervised models (Dong et al., 2022).
Table 1 shows that data2vec outperforms prior work with
ViT-B and ViT-L in the single model setting and all prior
work for ViT-L. Predicting contextualized latent representations in a masked prediction setup can perform very well
compared to approaches which predict local targets such
as the original input pixels (He et al., 2021; Xie et al.,
2021), engineered image features (Wei et al., 2021) or visual
tokens (Bao et al., 2021). It also outperforms prior selfdistillation methods (Caron et al., 2021) which regressed
the final layer of the student network while inputting two
different augmented versions of an image to the student and
teacher networks
5.2. Speech processing
For speech processing, we pre-train data2vec on the 960
hours of speech audio data from Librispeech (LS-960). This
dataset contains relatively clean speech audio from read
audiobooks in English and is a standard benchmark in the
speech community. To get a sense of performance in different resource settings, we fine-tune models for automatic
speech recognition using different amounts of labeled data,
ranging from just 10 minutes to 960 hours. We also compare to other work from the literature, including wav2vec
2.0 (Baevski et al., 2020b) and HuBERT (Hsu et al., 2021),
two popular algorithms for speech representation learning
relying on discrete units of speech.
Table 2 shows improvements for all labeled data setups with
the largest gains for 10 minutes of labeled data (20% relative WER improvement). Our results suggest that learning
discrete units is not required when rich contextualized targets are used and that learning contextualized targets during
pre-training improves performance.
Table 2. Speech processing: word error rate on the Librispeech test-other test set when fine-tuning pre-trained models on the Libri-light
low-resource labeled data setups (Kahn et al., 2020) of 10 min, 1 hour, 10 hours, the clean 100h subset of Librispeech and the full 960h of
Librispeech. Models use the 960 hours of audio from Librispeech (LS-960) as unlabeled data. We indicate the language model used
during decoding (LM). Results for all dev/test sets and other LMs can be found in the supplementary material (Table 5).

Table 2 shows improvements for all labeled data setups with
the largest gains for 10 minutes of labeled data (20% relative WER improvement). Our results suggest that learning
discrete units is not required when rich contextualized targets are used and that learning contextualized targets during
pre-training improves performance.
5.3. Natural language processing
To get a sense of how data2vec performs for language, we
adopt the same training setup as BERT (Devlin et al., 2019)
by pre-training on the Books Corpus (Zhu et al., 2015) and
English Wikipedia data over 1M updates and a batch size
of 256 sequences. We evaluate on the General Language
Understanding Evaluation (GLUE) benchmark (Wang et al.,
2018) which includes tasks for natural language inference
(MNLI, QNLI, RTE), sentence similarity (MRPC, QQP and
STS-B), grammaticality (CoLA), and sentiment analysis
(SST-2).6 We fine-tune data2vec separately on the labeled data provided by each task and report the average accuracy
on the development sets over five fine-tuning runs. We
compare to the published BERT results as well as to the
results we obtain by retraining RoBERTa in the current
setup (Baseline; Liu et al. 2019) which provides a more
suitable baseline to data2vec since we build on their open
source code.
The results (Table 3) show that data2vec outperforms the
RoBERTa baseline. When we mask spans of four BPE
tokens with masking probability 0.35 (Baevski et al., 2020b),
then results improve further.7 This strategy does not leave
tokens unmasked or uses random targets as for BERT (§4.3).
Table 3. Natural language processing: GLUE results on the development set for single-task fine-tuning of individual models. For MNLI
we report accuracy on both the matched and unmatched dev sets, for MRPC and QQP, we report the unweighted average of accuracy and
F1, for STS-B the unweighted average of Pearson and Spearman correlation, for CoLA we report Matthews correlation and for all other
tasks we report accuracy. BERT Base results are from Wu et al. (2020) and our baseline is RoBERTa re-trained in a similar setup as BERT.
We also report results with wav2vec 2.0 style masking of spans of four BPE tokens with no unmasked tokens or random targets

To our knowledge this is the first successful pre-trained
NLP model which does not use discrete units (words, subwords, characters or bytes) as the training target. Instead,
the model predicts a contextualized latent representation
emerging from self-attention over the entire unmasked text
sequence. This enables a learning task where the model
needs to predict targets with specific properties of the current
text sequence rather than representations which are generic
to every text sequence in which the particular discrete unit
occurs. Moreover, the set of training targets is not fixed, i.e.,
not a closed vocabulary, and the model can choose to define
new target types as it sees fit, akin to an open vocabulary
setting.
5.4. Ablations
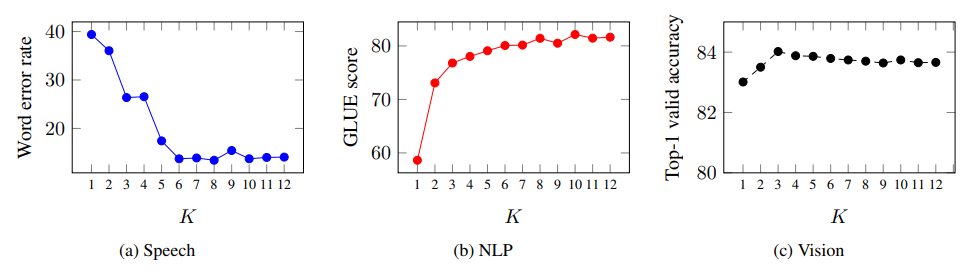
Layer-averaged targets. One of the main differences of
our method compared to BYOL is the use of targets which
are based on averaging multiple layers from the teacher network (§3.3). This idea was partly inspired by the fact that the
top layers of wav2vec 2.0 do not perform as well for downstream tasks as layers in the middle of the network (Baevski et al., 2021; Pasad et al., 2021).
In the next experiment, we measure performance for all
three modalities when averaging K = 1, . . . , 12 layers
where K = 1 corresponds to predicting only the top layer
similar to BYOL. For faster experimental turn-around, we
train Base models with L = 12 layers in total. For speech,
we pre-train for 200K updates on Librispeech, fine-tune on
the 10 hour labeled split of Libri-light (Kahn et al., 2019)
and report word error rate without a language model on devother. For NLP, we report the average GLUE score on the
validation set (§5.3) and for computer vision we pre-train
models for 300 epochs and report the top-1 accuracy on
ImageNet (§5.1).
Figure 2 shows that targets based on multiple layers improves over using only the top layer (K = 1) for all modalities. Using all layers is generally a good choice and only
slightly worse than a carefully tuned value of K. Neural
networks build features over multiple layers and different
types of features are extracted at different layers. Using
features from multiple layers enriches the self-supervised
task and improves accuracy.
Figure 2. Predicting targets which are the average of multiple layers is more robust than predicting only the top most layer (K = 1)
for most modalities. We show the performance of predicting the average of K teacher layer representations (§3.3). The effect is very
pronounced for speech and NLP while for vision there is still a slight advantage of predicting more than a single layer.
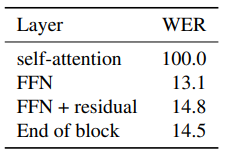
Target feature type.
Transformers blocks contain several
layers which can each serve as targets. To get a sense of how different layers impact performance, we pre-train speech
models on Librispeech using the features from different
layers as target features. Table 4 shows that the output of
the feedforward network (FFN) block works best while the
output of the self-attention block does not yield a usable
model. We believe this is because the self-attention output
is before the residual connection and features are heavily
biased towards other time-steps. This issue is alleviated by
the use of the FFN features since these include the features
before the self-attention as well.
Table 4. Effect of using different features from the teacher model as
targets: we compare using the output of the self-attention module,
the feed-forward module (FFN) as well as after the final residual connection (FFN + residual) and layer normalization (End of
block). Results are not directly comparable to the main results
since we use a reduced setup (§5.4).
6. Discussion
Modality-specific feature extractors and masking.
Our
primary is to design a single learning mechanism for different modalities. Despite the unified learning regime, we still
use modality-specific features extractors and masking strategies. This makes sense given the vastly different nature of
the input data: for example, in speech we learn from a very
high resolution input (16 kHz waveform) which contains
hundreds of thousands of samples for typical utterances.
To process this, we apply a multilayer convolutional neural network to obtain a 50 Hz feature sequence. For NLP,
inputs are of vastly lower resolution in the form of much
shorter word sequences which can be directly embedded
in distributional space via a lookup table. The type of data
also impacts how we should mask the input to create a challenging learning task: removing individual words provides
a sufficiently challenging task but for speech it is necessary to mask spans since adjacent audio samples are highly
correlated with each other.
Relatedly, there has been recent work on a Transformer
architecture that can directly operate on the raw data of
different modalities without modality-specific feature encoders (Jaegle et al., 2021). Their work is focused on supervised learning for classification tasks and we believe that
our work is complementary.
Structured and contextualized targets.
One of the main
differences of data2vec to most other masked prediction
work (Devlin et al., 2019; Baevski et al., 2020b; Ling et al.,
2020; Bao et al., 2021; He et al., 2021; Wei et al., 2021) is
that the features of the training targets are contextualized
since the features are built with self-attention over the entire
unmasked input in teacher mode. And while BYOL (Grill
et al., 2020) and DINO (Caron et al., 2021) also use latent
target representations based on the entire input, their focus is
on learning transformation-invariant representations instead
of structural information within a sample.
One exception is HuBERT (Hsu et al., 2021) which builds a
fixed set of discrete target units by clustering Transformer
layer representations. In comparison, data2vec has no limitation on the number of target units. Instead of representing
each instance of particular discrete target unit with the same
set of features, data2vec can build target features that are
specific to the current sequence.
For NLP, we believe data2vec is the first work that does not
rely on pre-defined target units. Most other work uses either
words, sub-words (Radford et al., 2018; Devlin et al., 2019),
characters (Tay et al., 2021) or even bytes (Xue et al., 2021).
Aside, defining word boundaries is not straightforward for
some Asian languages. Contextualized targets enable integrating features from the entire sequence into the training
target which provides a richer self-supervised task. Furthermore, the representation of each instance of a particular unit
(word/sub-word/character/byte) can differ for the masked
prediction task. This enables to associate a different meaning to a particular depending on the context it occurs in. It
also relieves the model from the need to learn a single set of
features for a target unit that fits all instances of this unit.
Representation collapse.
A common issue with algorithms which learn their own targets is representation collapse. This occurs when the model produces very similar
representations for all masked segments which results in
a trivial task (Jing et al., 2021). To deal with this issue,
contrastive models such as wav2vec 2.0 (Baevski et al.,
2020b) use the same target representation both as a positive
and a negative example. BYOL (Grill et al., 2020) do not
optimize the teacher parameters to minimize the loss and VicReg (Bardes et al., 2021) adds an explicit loss encouraging
variance among different representations.
We found that collapse is most likely to happen in the following scenarios: First, the learning rate is too large or the
learning rate warmup is too short which can often be solved
by tuning the respective hyperparameters. Second, τ is too
low which leads to student model collapse and is then propagated to the teacher. This can be addressed by tuning τ0,
τe and τn. Third, we found collapse to be more likely for
modalities where adjacent targets are very correlated and
where longer spans need to be masked, e.g., speech. We
address this by promoting variance through normalizing target representations over the sequence or batch (Grill et al.,
2020). For models where targets are less correlated, such as
vision and NLP, momentum tracking is sufficient.
7. Conclustion
Recent work showed that uniform model architectures can
be effective for multiple modalities (Jaegle et al., 2021). In a
similar spirit, we show that a single self-supervised learning
regime can be effective for vision, speech and language. The
key idea is to regress contextualized latent representations
based on a partial view of the input. data2vec outperforms
prior self-supervised algorithms on ImageNet-1K for ViT-B
single models and ViT-L models, it improves over prior
work on speech recognition for the low-resource setups of
Libri-light, and it outperforms RoBERTa for natural language understanding on GLUE in the original BERT setup.
A single learning method for multiple modalities will make
it easier to learn across modalities and future work may
investigate tasks such as audio-visual speech recognition or
cross-modal retrieval. Our approach still uses modalityspecific input encoders and we adopt modality-specific
masking strategies. Future work may investigate a single
masking strategy that is modality-agnostic as well as jointly
training multiple modalities.
