📚 머신러닝 1주차에는 핸즈온 머신러닝 3장 분류모델의 예제인 타이타닉 생존자 예측 문제를 함께 풀어보았다.
[0] 데이터 출처(Kaggle)
#https://www.kaggle.com/c/titanic[1] 필요한 라이브러리 가져오기(우선 데이터 전처리부터)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline[2] os.environ을 이용하여 Kaggle API Username, Key 세팅하기
Kaggle 홈페이지에서 발급받을 수 있음
os.environ['KAGGLE_USERNAME'] = 'KAGGLE_USERNAME'
os.environ['KAGGLE_KEY'] = 'KAGGLE_KEY'[3] 데이터 가져오기
!kaggle competitions download -c titanic
!unzip '*.zip'
!ls[4] 데이터 열어보기
df_t = pd.read_csv('train.csv')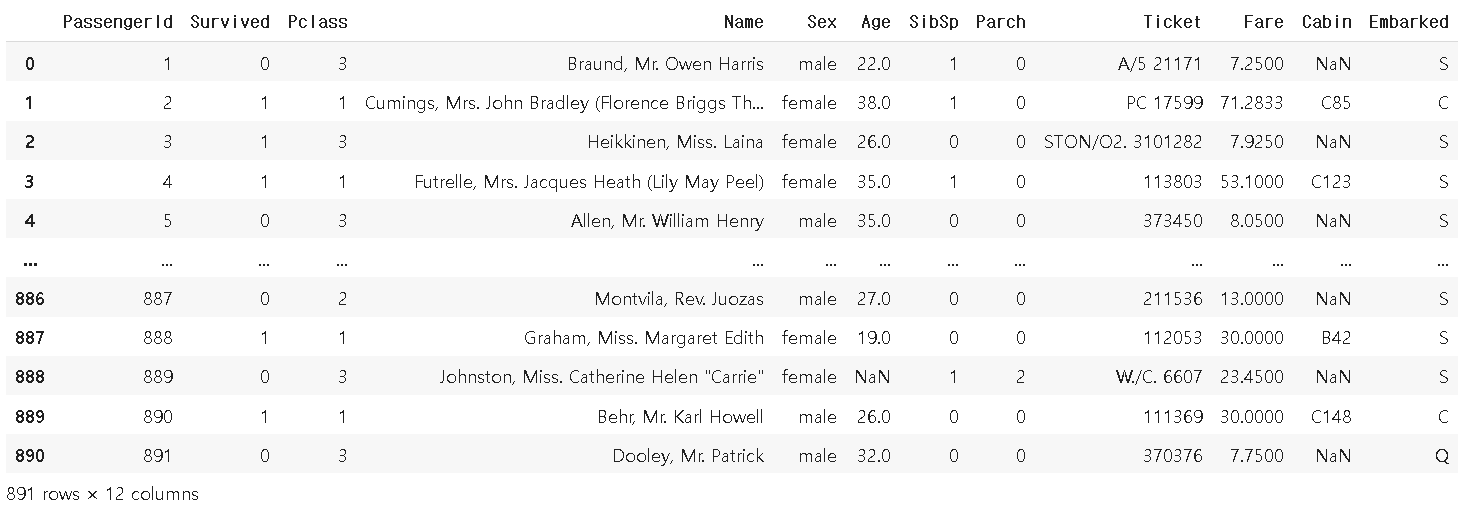
[5] 데이터 정보보기
df_t.info()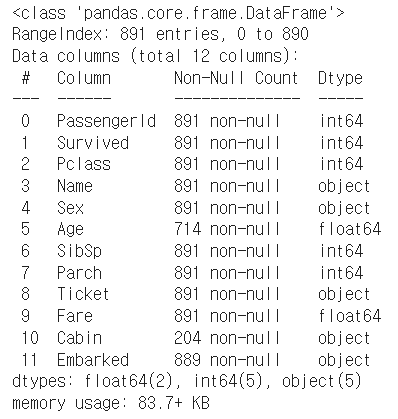
- 총 11개의 변수를 확인할 수 있다.
- 사이트를 참고해보니 변수의 설명은 다음과 같다.
PassengerId: 승객 고유 번호
Survived: 생존여부(1 = 생존, 0 = 사망)
Pclass: 객실 등급(1st = 1, 2nd = 2, 3rd = 3)
Name: 승객 이름
Sex: 성별
Age: 나이
SibSp: 함께 탑승한 형재자매or배우자 수
ParCh: 함께 탑승한 부모or자녀 수
Ticket: 티켓 번호
Fare: 티켓 요금
Cabin: 객실 번호
Embarked: 탑승 장소(C = Cherbourg, Q = Queenstown S = Southampton)
[6] int,float 변수 통계치 살펴보기
df_t.describe()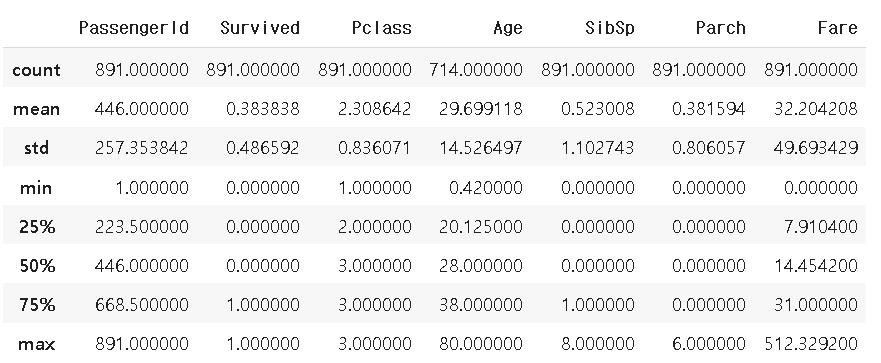
- 데이터로 확인할 수 있는 사실
탑승자 38% 생존
탑승자 평균연령 29.6
티켓 등급은 2.3으로 대부분 3rd
[7] object 변수 통계치 살펴보기
df_t.describe(include=['O'])
- 데이터로 확인할 수 있는 사실
탑승자 남성 수가 577명
동일한 티켓으로 탑승한 인원 중 가장 많은 수 7명
한 객실에 최대 수용인원 4명
[8] train data에서 '성별'에 따른 생존율 비교
#grouby(): 같은 값을 하나로 묶어 통계 또는 집계 결과를 얻기 위해 사용하는 것
#sort_values(): 정한 기준으로 정렬, ascending = true 오름차순
#as_index : 새로 인덱싱을 할지말지 결정하는 것)
df_t[['Sex', 'Survived']].groupby(['Sex'], as_index = True).mean().sort_values(by = 'Survived', ascending = False)
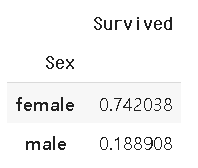
- 여성의 생존율이 더 높음을 알 수 있다!
[9] train data에서 '객실 등급'에 따른 생존율 비교
df_t[['Pclass', 'Survived']].groupby(['Pclass'], as_index = False).mean().sort_values(by = 'Survived', ascending = False)
-객실 등급이 높을 수록 생존률이 높다!
[10] 연령에 따른 생존 여부 시각화 하기(너무 많은 나이의 분포로 0세부터 20세까지만), train data에서 '나이'에 따른 생존율 비교
df_agv = df_t[['Age', 'Survived']].groupby(['Age'], as_index = False).mean().sort_values(by = 'Survived', ascending = False)
[11] Age의 데이터 타입 변경하기
df_agv['Age'] = df_agv['Age'].astype(int)[12] 변경 되었는지 확인하기
df_agv.info()
[13] barplot으로 시각화
sns.barplot(data=df_agv, x='Age', y='Survived')
plt.axis([0, 20, 0, 1])
plt.show()
💡 마무리
- 1주차에는 타이타닉 데이터가 어떻게 구성되어 있는지 살펴보았다.
- 다음에는 본격적으로 데이터 전처리와 분석을 진행할 예정이다.

헉 너무 멋있어요 ..!😎