
https://velog.io/@mooh2jj/예약-시스템에서-동시성-제어와-더블부킹중복요청은-어떻게-막을까
에서 현재 개선 사항으로 조회성능을 높이기위해 pk키와 대리키에 uqiue 등 인덱스를 설정하여 그 성능을 비교 분석해보았습니다.
Mysql 의 실행계획(EXPLAIN)을 참고삼아 측정해보았습니다.
표본은 100만 건이 넘은 건수가 있는 테이블 reservataion에서 해보았습니다.
100만 건수 표본개수를 만들기 위해 insert 작업을 Junit5 TestCode에서 실행했습니다.
기존에 작업한 쿼리들을 잘 확인하고 싶기에 h2 데이터베이스가 아닌 현재 사용중인 MySQL 데이터베이스에 작업할려고 합니다.
JPA를 사용할 때는 Test 클래스에서는 자동으로 임베디드 h2 데이터베이스에 입력이 됩니다. 이를 MYSQL로 바꾸기 위해 Test 전용 applciation.yml을 만들어 보았습니다.
IntelliJ 설정
1) Run tests using: Gradle -> IntelliJ로 설정
기존의 Gradle로 설정되어 test를 실행하면 굉장히 느려집니다. intelliJ로 바꿔줍니다.
2) vm option heap 메모리 설정
Edit Custom VM Options에서 쉽게 heap 메모리를 설정할 수 있습니다.
Xmx2048m -> xmx4096m으로 바꿔줍시다.
Code 설정
application-test.yml
spring:
config:
activate:
on-profile: test
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ward_study?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Seoul&characterEncoding=UTF-8
username: root
password: 1234
jpa:
open-in-view: true
hibernate:
ddl-auto: update
naming:
physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
use-new-id-generator-mappings: false
show-sql: true
properties:
hibernate.format_sql: true
dialect: org.hibernate.dialect.MySQL8Dialect
logging:
level:
org.hibernate.SQL: debugInsertTest 설정 어노테이션
@Slf4j
@Import(JpaAuditingConfig.class)
@ActiveProfiles("test")
@DataJpaTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
@Rollback(value = false)
public class InsertTest {
...
}
-
@Import(JpaAuditingConfig.class)
JPA에 create_date, update_date를 자동으로 생성해주는 Auditing MapperClass를 사용하면
EnableJpaAuditing을 사용하는 Config 파일을 설정해줍시다. -
@ActiveProfiles("test")
application-test.yml의n-profile: test를 매핑해주는 것입니다. -
@DataJpaTest
단순 JPA Data Repository를 사용하는 Test하면 이 어노테이션을 사용해줍니다. 내부적으로 @Transactional을 내장하고 있기에 굳이 클래스단위에 @Transactional을 걸어주지 않아도 됩니다. -
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
TEST를 할시에는 default로 h2 임베디드 데이터베이스에 설정됩니다. 이를 막아줍니다. -
@Rollback(value = false)
Test일시, 자동적으로 rollback을 시전해줍니다. 저는 DB 데이타까지 보기를 원하기에 이를 false 처리해준 겁니다.
자, 이제 설정 셋팅이 완료되었습니다.
insert test 메서드를 만들어줍시다.
아쉽게도 JPA에서는 bulkInsert 기능이 없다고 합니다. 그래서 반복문을 통해서 한건씩 save해주는 방식으로 했습니다.
LocalDateTime random 값을 만들어주기위한 디팬더시는 아래와 같습니다.
implementation group: 'com.namics.oss', name: 'java-random', version: '1.2.2'InsertTest 메서드 부분
@Autowired
private ReservationRepository reservationRepository;
@Test
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 백만건 insert
LongStream.rangeClosed(1, 100*10000).forEach( i -> {
Reservation reservation = Reservation.builder()
.startTime(random())
.endTime(random())
.build();
reservationRepository.save(reservation);
}
);
stopWatch.stop();
log.info("객체 생성 시간: {}", stopWatch.getTotalTimeSeconds());
}
public LocalDateTime random() {
LocalDateTime now = LocalDateTime.now();
int year = 60 * 60 * 24 * 365;
return now.plusSeconds((long) RandomData.randomInteger(-2 * year, 2 * year));
}헉.. 완료 후 백만 건이 입력되었습니다.
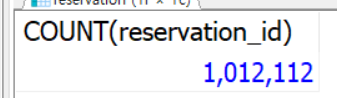
시간이 많이 걸립니다.(대략 1,043초 걸렸네요.)

자, 이제 sql 쿼리를 날려봅시다. 성능 측정은 explain과 제가 사용하고 있는 SQL 툴인 Hedisql로 쿼리 실행시간으로 확인해볼 겁니다.
저의 경우, ward-study 프로젝트에서 reservation 테이블의 pk인 reservation_id가 BIGINT타입의 pk키로 설정되었고
대리키인 reservation_token 필드가 VACHAR타입의 컬럼으로 되어있습니다.
reservation_token는 특별히 랜덤한 값으로 두었기에 이미 식별자로 되었다고 생각했기에, unique키 설정은 굳이 안해왔는데요. 실제 DB에서도 성능이 차이가 있는지/없는지 확인해보겠습니다.
쿼리 측정
reservation_id
SELECT r.start_time, r.end_time, COUNT(r.reservation_id)
FROM reservation r
WHERE 1=1
AND r.reservation_id BETWEEN 0 AND 100000
AND r.start_time BETWEEN '2021-06-14' AND '2024-02-19'
group by r.reservation_id, r.start_time
;pk 인덱스를 설정하지 않은 경우
/* 영향 받은 행: 0 찾은 행: 66,988 경고: 0 지속 시간 1 쿼리: 0.937 초 (+ 0.016 초 네트워크) */pk 인덱스를 설정한 경우
/* 영향 받은 행: 0 찾은 행: 66,988 경고: 0 지속 시간 1 쿼리: 0.157 초 (+ 0.031 초 네트워크) */확실히, pk 인덱스를 걸지 않는 경우와 하는 경우는 차이가 많이 납니다. 100만건 중 6.7만건을 조회하는데 0.8초나 차이로 83.2% 정도 조회 성능이 개선이 되었습니다.
reservation_token
그럼 reservation_token입니다. String 타입에 UUID로 generate한 값인데 성능 개선이 많이 이루어졌을까요?
SELECT r.start_time, r.end_time, COUNT(r.reservation_token)
FROM reservation r
WHERE 1=1
AND r.reservation_token LIKE '%H%'
AND r.start_time BETWEEN '2021-06-14' AND '2024-02-19'
group by r.reservation_token, r.start_time
;unique 키를 설정하지 않은 경우
/* 영향 받은 행: 0 찾은 행: 235,640 경고: 0 지속 시간 1 쿼리: 1.532 초 (+ 0.093 초 네트워크) */unique 키를 설정한 경우
/* 영향 받은 행: 0 찾은 행: 235,640 경고: 0 지속 시간 1 쿼리: 1.141 초 (+ 0.109 초 네트워크) */unique 키를 설정해도 성능적으로 더 빠르게 나타나는 것을 확인할 수 있었습니다. 0.4초 좋아지네요. 약 25% 개선이 되었습니다.
실제 DB에서 대리키(랜덤값)도 인덱스를 걸어줘도 성능 개선이 이루어졌습니다.
실행계획
reservation_id
1) 인덱스를 설정하지 않은 경우
explain SELECT r.start_time, r.end_time, COUNT(r.reservation_id)
FROM reservation r
WHERE 1=1
AND r.reservation_id BETWEEN 0 AND 100000
AND r.start_time BETWEEN '2021-06-14' AND '2024-02-19'
group by r.reservation_id, r.start_time
;
2) 인덱스를 설정한 경우

실행계획에서 눈여겨 볼 요소들은 type, rows, filtered, extra 가 있습니다.
인덱스를 설정시 바껴진 내용을 보면,
type - range
rows - 208,560
type은 인덱스의 타입을 의미하고, range는
인덱스를 이용하여 범위 검색을 할 때 접근 방법을 뜻합니다. index를 탔다는 얘기이지요.
✔ index 실행계획 type 종류
- all : 테이블 전체를 스캔할 때
- range : 인덱스를 이용하여 범위 검색을 할 때
- index : 인덱스 전체를 스캔할 때
rows는
이 접근 방식을 사용해 몇 행을 가져왔는가를 표시합니다.
최초에 접근하는 테이블에 대해서 쿼리 전체에 의해 접근하는 행 수, 그 이후에 테이블에 대해서는 1행의 조인으로 평균 몇 행에 접근했는가를 표시합니다.
단, 어디까지나 통계 값으로 계산한 값이므로 실제 행 수와 반드시 일치하지 않습니다.
filtered는
행 데이터를 가져와 WHERE 구의 검색 조건이 적용되면 몇행이 남는지를 표시합니다.
이 값도 통계 값 바탕으로 계산한 값이므로 현실의 값과 반드시 일치하지 않습니다.
reservation_token
1) 인덱스를 설정하지 않은 경우
explain SELECT r.start_time, r.end_time, COUNT(r.reservation_token)
FROM reservation r
WHERE 1=1
AND r.reservation_token LIKE '%H%'
AND r.start_time BETWEEN '2021-06-14' AND '2024-02-19'
group by r.reservation_token, r.start_time
;
2) 인덱스를 설정한 경우

변경된 요소로 filtered가 있습니다.
인덱스를 설정할시 filtered의 값이 줄어드네요. 어쨌든 unique를 걸어도 조금이지만 성능이 좋아진다는 것을 알 수 있었습니다.
조회외 다른 DML(insert, update, delete)에서의 성능 차이는 확인해보지 못했지만, 조회 성능을 더 올리고 싶을 땐, DB 테이블의 칼럼의 unique 키 설정을 해줘도 될 것 같습니다.
참고
