[Paper Review]BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Paper Review
이번에 리뷰할 논문은 BERT 논문이다.
BERT는 2018년 구글이 발표한 pre-trained model로 GPT와 자주 비교가 되는 논문이다.
공개 당시 11개의 NLP task에서 SoTA를 달성하며 매우 뛰어난 모델로 평가를 받았으며, 지금도 계속해서 RoBERTa, ALBERT, BART 등 매우 많은 BERT 계열의 모델이 쏟아져 나오고 있다.
우선 BERT를 읽기 전에 읽으면 좋을 논문으로는
정도가 있을 것 같다. 여기서 제일 중요한건 Transformer겠지만...

BERT INTRODUCTION
BERT의 특징을 짧게 정리하자면 다음과 같다.
1. Pre-trained Model
2. Bidirectional Representation
3. Masked Language Model
4. Next Sentence Prediction
Pre-trained Model
GPT와 BERT를 필두로 하여 NLP에서도 pre-trained model들이 대세가 되었다. 비전 영역에서는 이미 상당수의 논문들이 pre-train + fine-tuning 구조의 모델이 좋은 성능을 나타내는 것이 증명된 상태였고 이제 NLP 영역에서도 확인되기 시작한 것이였다.
Pre-trained model은 대량의 unlabled data를 이용해 학습을 진행하고 각각의 downstream task에 맞는 labeled data로 fine-tuning을 진행하는 방식으로 학습을 한다.
Labeled data는 unlabeled data에 비해 적은 양의 데이터를 갖고 있고, labeled data로 처음부터 학습을 진행하게 되면 task-specific한 모델을 만들게 된다.
하지만 unlabeled data를 활용해 사전 학습을 진행하게 되면 각각의 downstream task에 적용할 때 적은 수의 parameter만 처음부터 학습시키면 된다.
게다가 이미 어느정도 학습이 되어있기 때문에 비교적 적은 양의 labeled data만 있으면 상당히 좋은 성능을 얻을 수 있다.
BERT는 fine-tuning시 입력과 출력만 task에 맞춰 바꾸면 바로 fine-tuning이 가능해진다. 이 부분이 꽤나 장점인 걸로 보인다. 예를 들어 sentence pair가 필요한 QA같은 task나 pair를 쓰지않는 classification task 각각에 맞춰 fine-tuning을 진행할 때 모델의 구조를 바꾸거나 모델의 많은 parameter를 처음부터 학습하지 않아도 돼서 실 사용시 비용 절감에 큰 유리함을 가져올 것으로 보인다.
Bidirectional Representation
BERT의 저자는 같은 해에 나왔던 GPT 모델의 단점을 unidirectional representation으로 꼽았다. 직관적으로 생각해보면 한쪽 방향으로만의 정보는 양방향에서 얻어진 정보보다 질이 떨어지는 것은 당연할 것이다. 그런데 왜 GPT는 Left-to-Right의 정보만을 이용해 학습을 진행했을까?
이는 bidirectional conditioning을 사용하게 되면 자칫 간접적으로 예측해야하는 단어를 컨닝할 수 있게 되기에 어쩔 수 없이 unidirectional conditioning을 사용한 것이다.
BERT는 이러한 문제를 masking을 이용해서 해결했다.
Masked Language Model
Masked LM(MLM)은 단순히 원래의 input sequence의 일부 단어들을 [MASK] 라는 특수한 토큰으로 교체해주고 마스킹된 부분만 예측하며 학습하는 방식이다.
이는 cloze task에서 착안된 방식이라고 하는데, cloze task는 그냥 문장 빈칸채우기 문제라고 생각하면 된다.
Masking의 진행은 우선 무작위로 각 position을 15% 선택하고 그 중 80%만 [MASK] 토큰으로 교체한다. 나머지 20% 중 10%는 그대로, 10%는 랜덤한 단어로 바꿔주게 된다.
이렇게 masking을 진행하는 이유는 pre-train과 fine-tuning간의 괴리를 줄이기 위해 고안해낸 방법이다. 왜냐하면 우리가 실생활에서 [MASK]라는 단어를 절대 사용하는 일이 없기에 pre-training에서 사용된 [MASK]가 fine-tuning에서 등장하지 않기 때문이다.
사실 이 부분에 대한 내용을 논문에서 읽었을 때 든 생각이, 그래도 결국 [MASK]라는 토큰을 사용한다는 사실에는 변함이 없어 큰 영향이 없지않나? 그럴거면 아예 전부 랜덤 단어로 교체하는 방식이 더 말에 맞지 않나? 하는 생각이 들었다. 논문 마지막 페이지에서 ablation study를 진행하며 masking 비율별 성능을 비교하는데 뚜렷한 차이라 느껴질만큼의 결과는 보이지않아 여전히 의문이긴 하다.
Next Sentence Prediction
BERT의 pre-training시 MLM과 함께 사용된 NSP이다. 이 task는 QA, NLI와 같이 문장 쌍이 입력으로 사용되고 두 문장 사이의 관계 파악이 중요한 task의 성능 향상을 위해 사용한 학습 방식이다.
학습 방식은 우선 두 문장 A, B를 입력으로 받고, 문장 B가 실제로 A 다음에 나오는 문장인지(IsNext), 아니면 corpus의 랜덤한 문장인지(NotNext)를 분류하는 classification으로 진행된다. IsNext와 NotNext는 각각 50%의 확률로 선택하며 classification은 출력단의 [CLS] 토큰의 값을 통해 진행한다.
얘도 사실 좀 궁금증이 생겼던게 NLI task야 두 문장의 관계를 파악하는 task라 NSP가 효과가 있다는 것은 이해가 되는데 QA는... 사실 잘 모르겠다.
내가 QA task에 관심이 없어서 잘 모르는 것일 수도 있는데 QA는 답을 찾을 수 있는 문서와 질문이 주어지고, 그에 대한 답을 출력으로 뱉어내는 task로 알고 있는데, 과연 여기서 어떤 부분이 QA에 관련이 있는지 와닿지는 않는다.
MODEL ARCHITECTURE
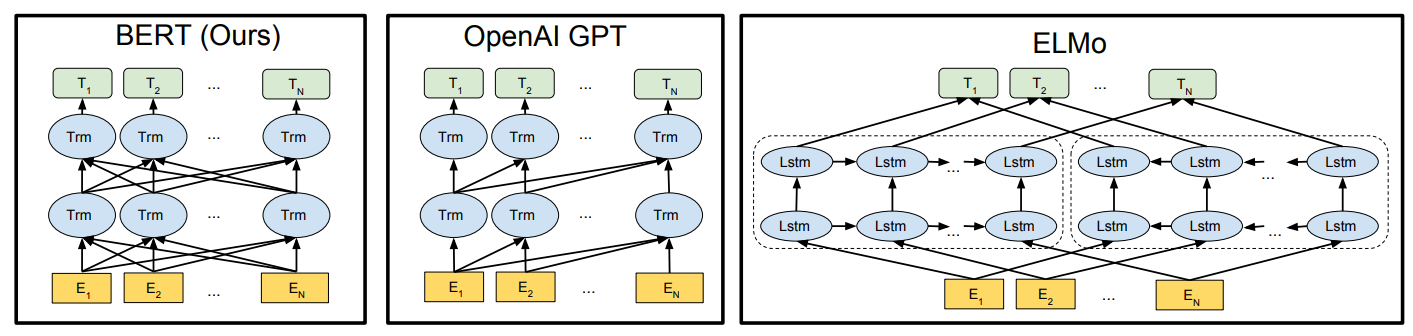
BERT의 모델 구조는 Transformer에 기반해있다.
Transformer encoder 부분만을 뗀 것을 쌓아올려 여러층으로 구성된다. Transformer 구조에 기반하기 때문에 자연스럽게 bidirectional representation을 학습 가능하게 된다(Self-Attention 덕분).
BERT와 자주 비교가 되는 모델들은 GPT와 ELMo가 있다. GPT의 경우, 같은 Transformer 기반의 fine-tuning approach를 사용하며 unidirectional representation을 사용한다는 차이점, ELMo의 경우, feature-based approach를 사용하나 bidirectional representation을 사용한다는 공통점을 갖고 있다.
여기서 feature-based는 pre-train된 word representation을 task-specific model에 사용하는 방법을 말하고, fine-tuning은 pre-trained word-representation과 task-agnostic model을 추가 labeled data로 일부만 학습시키는 방법을 일컫는다.
저자는 GPT와의 비교를 위해 BERT 모델을 두 종류 만들었으며 각 값들은 다음과 같다.
BERT Base
- Number of Layers : 12
- Hidden Size : 768
- Number of Self-Attention Head : 12
- Total Parameters : 110M
BERT LARGE
- Number of Layers : 24
- Hidden Size : 1024
- Number of Self-Attention Head : 16
- Total Parameters : 340M
여기서 BERT BASE 모델이 GPT와 모델 크기를 맞춰 비교를 쉽게 했고 여기서 내가 생각하는 주요 관점은 MLM을 이용한 bidirectional representation의 성능의 뛰어난 정도라고 생각한다. GPT도 Transformer 기반의 모델이라는 것은 같으니 MLM이 아마 주요 관점이 될 것 같다.
Input Representation
저자는 우선 BERT에 사용한 word embedding 기법은 WordPiece Embedding을 사용했다. WordPiece Embedding은 BPE와 상당히 유사한 방법이라고 한다. WordPiece 논문을 아직 안읽어봐서 우선 BPE 기준으로 간략하게 설명해보자면, BPE는 우선 단어를 어절 단위로 끊고, 끊어진 각 토큰들을 character단위로 쪼갠 뒤, 많이 등장한 character 짝끼리 묶어서 vocabulary를 업데이트하는 과정을 반복해 vocabulary를 완성한다. 이러한 방법은 subword 단위로 분리한 것들을 vocab으로 쓰기에 OOV(Out of Vocab) 문제에 강한 경향이 있다.

BERT는 Input을 세 가지 embedding을 더해서 받는데, 각각을 Token Embedding, Segment Embedding, Position Embedding이라고 한다.
Token embedding은 우리가 익히 알고 있는 word embedding이라고 생각하면 된다.
위의 그림을 보면 조금 특이한 embedding을 볼 수 있는데, [CLS], [SEP] 토큰을 볼 수 있다. 여기서 [CLS]는 입력 맨 앞에 추가된 토큰으로 이는 마지막 hidden state에서 classification에 사용된다(NSP에 이용).
그리고 [SEP]은 문장과 문장을 구분해주기 위해서 추가 되었다.
Segment embedding은 BERT의 downstream task의 핸들링을 위해 만들어졌다고 보면 되는데, sentence pair가 입력으로 필요한 QA나 NLI 같은 task들은 문장간 구분이 뚜렷하게 이루어져야 하기 때문에 각 문장이 문장 A와 B 중 어디에 속해있는지 나타내줄 수 있는 segment embedding을 넣었다.
마지막으로 Position embedding은 Transformer 구조 특성상 누락되는 각 단어 토큰들의 위치 정보를 나타내기 위해 사용된다.
이렇게 총 세 종류의 임베딩을 모두 더하고 masking을 추가하여 최종 입력으로 사용한다.
Pre-training & Fine-tuning
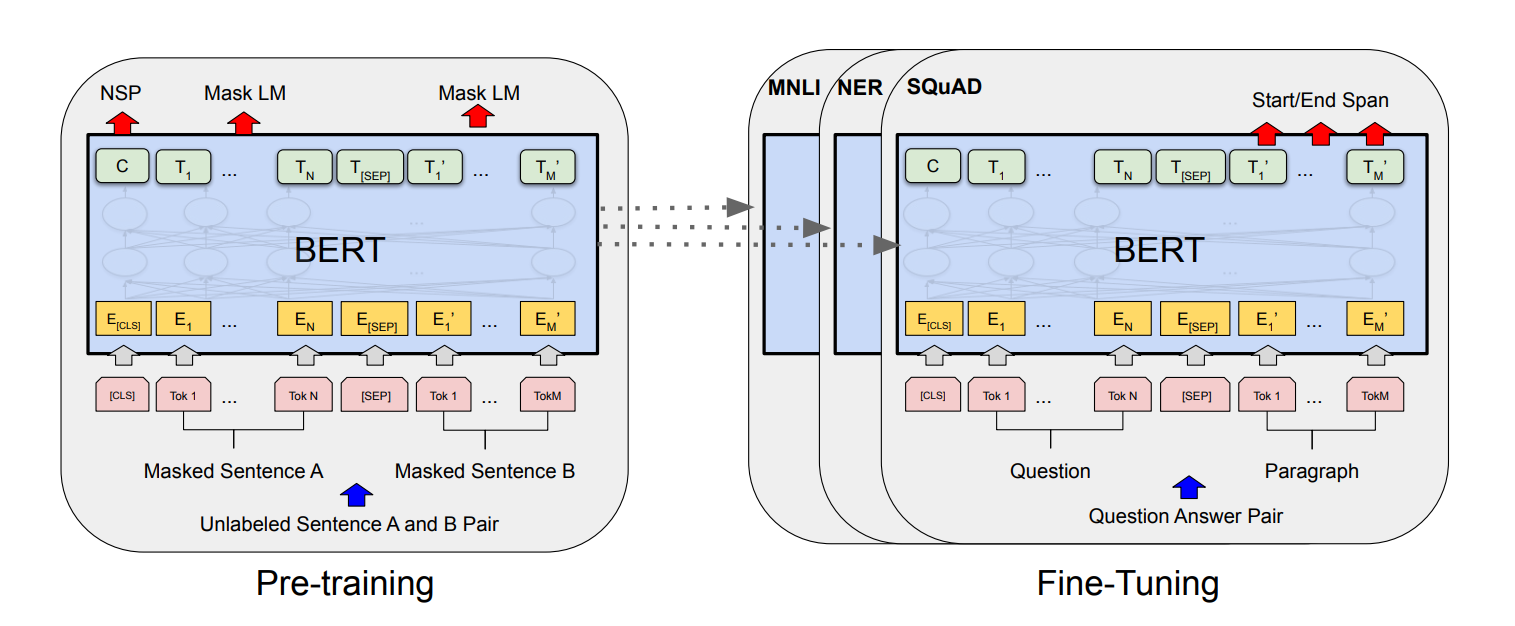
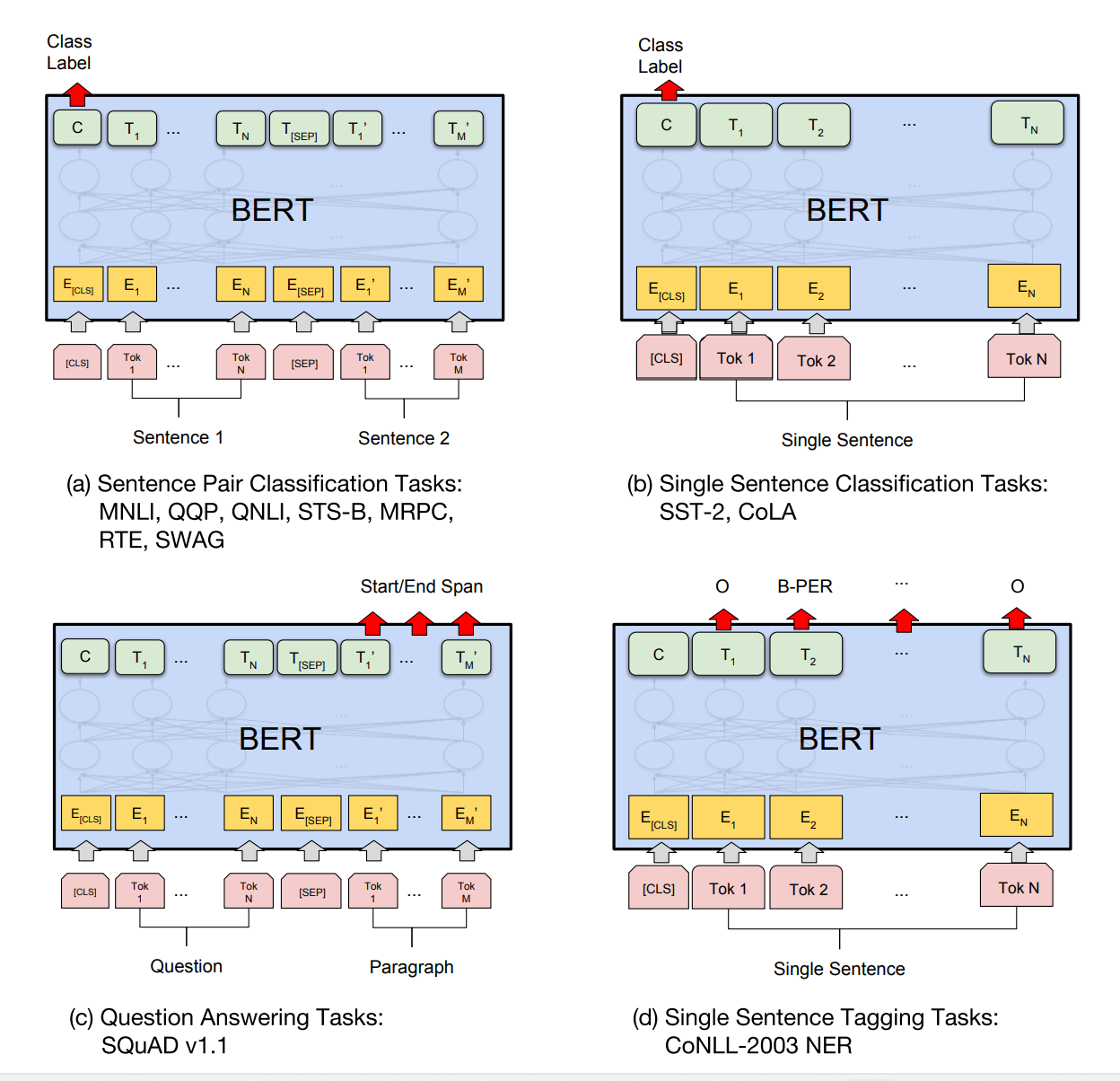
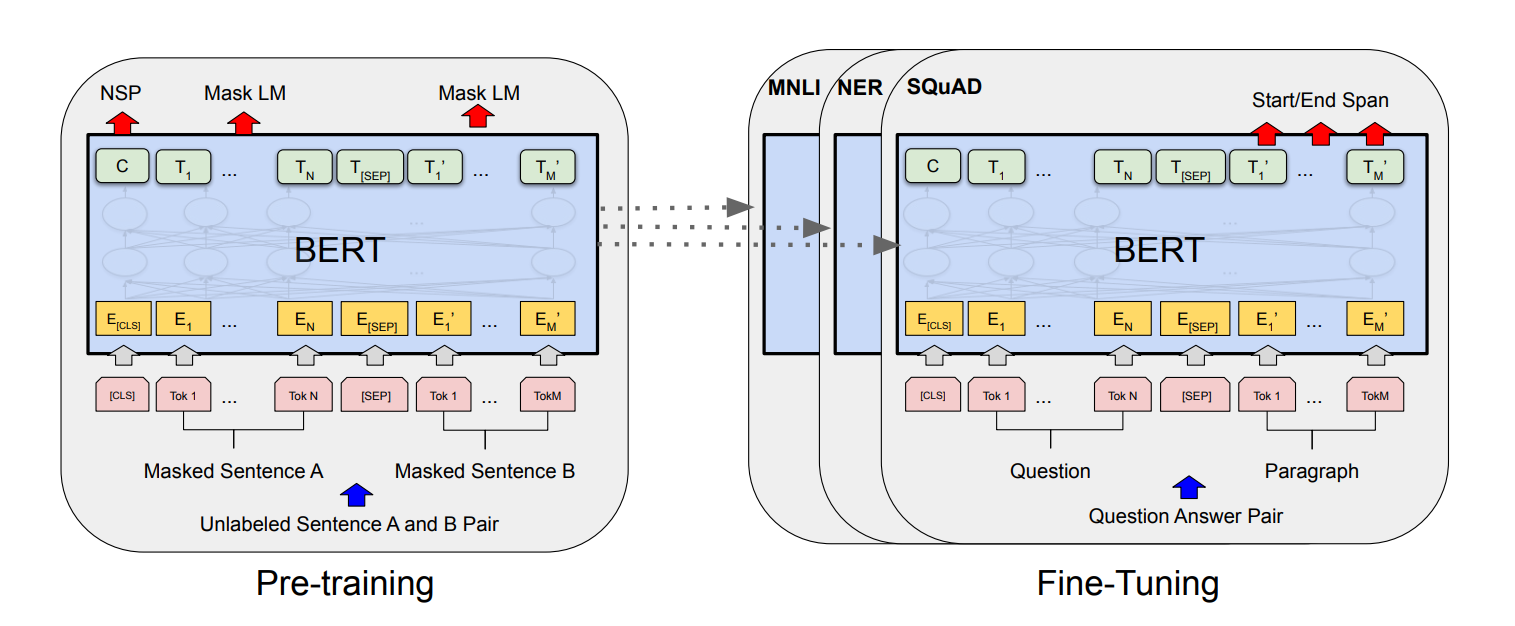
위의 사진에서 왼쪽은 BERT의 pre-training시의 모델 구조, 오른쪽은 fine-tuning시의 모델 구조를 나타낸다. 그리고 아래는 각 downstream task별 fine-tuning시 입력을 보여준다.
그림에서 알 수 있듯이 각각의 downstream task에 적용될 때 BERT의 모델 구조는 변하지않는다. 그저 입출력의 형태의 변화만 있어 fine-tuning에 매우 용이하다.
저자가 말하기를 fine-tuning시에 Cloud TPU 하나로 1시간, GPU 하나로 몇시간만 fine-tuning하면 학습이 완료된다고 한다. 아마 이게 pre-train된 모델 자체를 끌어다 사용해서 가능한 일이지 않을까 생각든다.
Experiments
BERT는 논문에서 진행한 11개의 성능 평가에서 꽤나 유의미한 성능 향상을 가져오며 모두 SoTA를 달성했다. 실험 결과 표는 논문에 잘 나와있으니 직접 검색해서 보면 된다.
그리고 저자는 Ablation study를 진행했다.
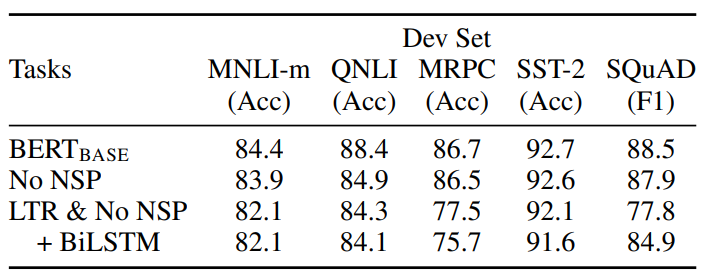
Pre-train Task
이는 pre-train task NSP와 MLM이 성능에 끼치는 영향에 대한 실험이다.
순서대로 base model, NSP 제거, NSP와 MLM 제거(단방향 정보 사용), layer 최상단에 BiLSTM layer 추가 를 나타낸다.
결과를 보게 되면 NSP task가 QA(SQuAD)와 NLI(MNLI-m, QNLI) 성능에 영향을 끼침을 알 수 있고, MLM, bidirectional을 제거한 경우 MRPC(문장 유사성), SQuAD의 성능에서 매우 큰 폭의 성능 하락을 관찰할 수 있었다.
아마 이 결과는 생각해보면 당연할 수도 있는 것 같다. 문장 사이의 관계를 학습하기위한 NSP가 제거되면 NLI의 성능은 자연스레 떨어질 것이고, 양방향 정보가 중요한 QA에서 단방향 정보만을 사용하면 떨어질 것이다.
SQuAD를 보면 최상단 layer에 BiLSTM을 추가하여 학습했을 때 성능이 큰 폭으로 향상됨을 볼 수 있는데 이 또한 QA에서 양방향 정보가 중요함을 시사한다고 본다. 근데 이렇게 BiLSTM을 쓰는거는 비용이 비싸기도 하고 Transformer에 비해 성능이 떨어져서 안쓴다.
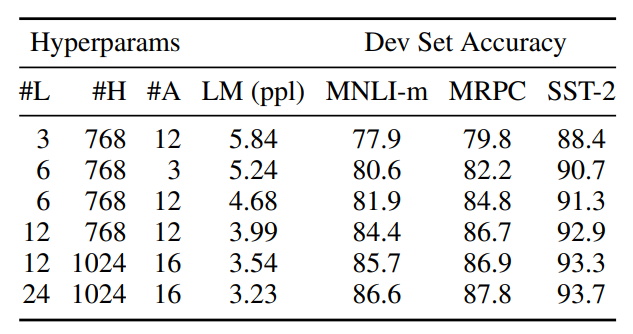
Model Size
여기서는 모델의 크기와 성능의 관계에 대해서 실험을 진행한다.
논문에서 BERT base와 large 모델에 대해 실험한 결과만 봐도 알 수 있듯이 모델의 크기가 커지면 커질수록 모델의 성능 또한 좋아진다(GPT에서도 똑같이 말하고 GPT는 그래서 차기작에서 미친듯이 모델 크기를 키워버렸다...).
이전에 feature-based approach를 주로 사용하던 시절에는 hidden state의 dimension을 1000이상으로 늘리는 것은 의미가 없다고 주장했으나, 저자는 그건 feature-based라서 그렇고 fine-tuning에서는 미리 학습을 많이 해놔서 오히려 많은게 좋다고 한다.
Masking Rate
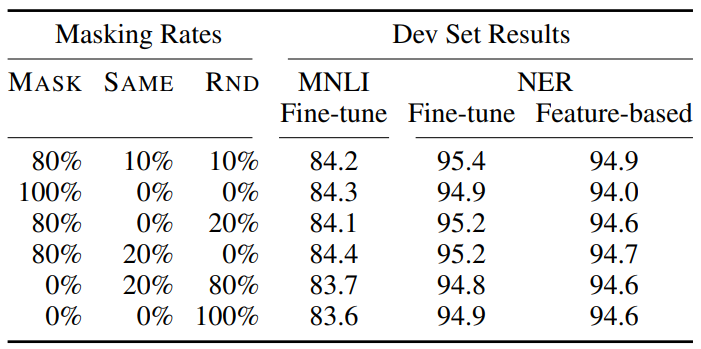
사실 이 결과는 크게 와닿지 않는다. Masking rate별로 성능차이는 보여주지만 모든 면에서 월등히 뛰어난 것 같지는 않고... mismatch를 줄이기 위해 비율을 설정하고 masking을 진행한 이유도 생각보다 막 와닿지는 않는다...
Number of Training Step
기존의 LM들은 unidirectional 구조를 가지고 모든 단어에 대해 prediction을 진행했다. 그에 반해 BERT는 masking한 15%의 단어에 대한 prediction을 진행했고, 이는 곧 모델이 수렴하기까지 더 오래 학습을 해야된다는 점을 이야기한다.
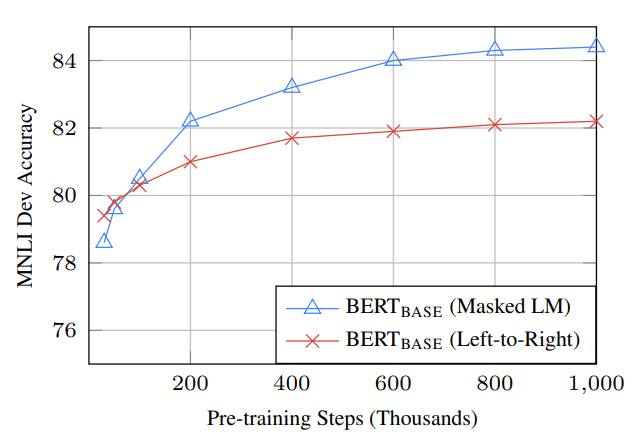
그런데 이게 신기한 점이 MLM을 사용하는 BERT와 이를 제거하고 단방향(LTR) 표현을 학습하는 BERT의 성능 수렴 속도를 보면 이른 시점에서 MLM을 사용한 BERT가 성능이 좋아짐을 볼 수 있다.
물론 수렴 속도가 느리긴 하지만 성능의 개선을 보면 어느정도는 감수할만 하다고 한다.
그리고 하나 더 알 수 있는 사실은, pre-training을 더 길게할수록 성능이 크진 않지만 개선됨을 확인할 수 있었다고 한다.
마무리
BERT는 이후 나오는 논문들에 매우 거대한 영향을 준 논문이다. 인용수만 봐도 3만이 넘으니...
읽고나서 조금 의문이 남았던 점은 masking rate로 masking을 하더라도 mismatch는 크게 줄이지 못한 것 같은데 이에 대한 설명이 조금 더 있었으면 좋았을 듯하다.
그리고 ablation study에서 MLM만 제거한 채로 NSP를 사용했을 때는 성능이 어느정도 나올지 궁금했는데 없던 것이 아쉬웠다.
그래도 Transformer라는 벽을 다시 넘고 읽으니 수월하게 읽혔고 MLM 기법이 매우 신박하다 생각이 든다. 어린애들 학습 방법에서 영감을 가져온걸로 보아 어린이 교육방법이 꽤 ai에서 많이 쓰일지도 모르겠다는 생각이 든다.
velog로 이사온 후 처음 써보는 글이다. Github 블로그에 비해선 진짜 천국인 것 같다.
이전에 써둔 글 중에 맘에 드는 글은 옮겨 두던가 해야겠다.
