One Shot Learning
아이폰의 안면 인식을 예로 들어보면 사용자의 얼굴을 한번만 인식 후 입력된 얼굴이 사용자인지 아닌지 판단 가능합니다.
이렇게 한 개 혹은 매우 적은 수의 데이터를 통해 새로운 클래스나 개념을 학습하는 것을 one shot learning이라고 합니다.
one shot learning에는 주로 siamese network가 사용됩니다.
Siamese Network
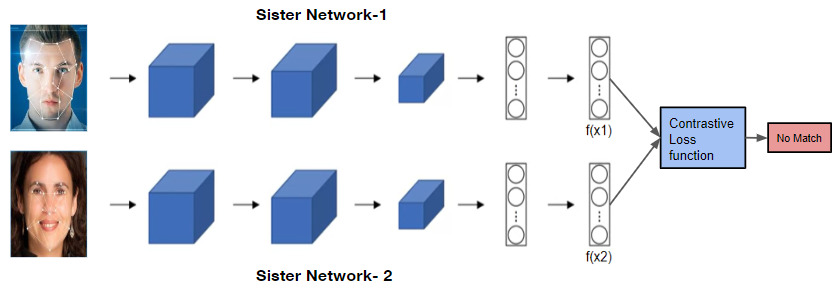
샴 네트워크는 두 이미지를 받은 후 각각에 대해 동일한 신경망을 사용하여 인코딩 시킨 후 결과 벡터들의 유사도를 비교하는 방식입니다.
위 예시 이미지를 통해 살펴보자면
첫번째 데이터의 결과 벡터는 f(x1)이고 두번째 데이터의 결과 벡터는 f(x2)입니다.
따라서 두 벡터의 유사도는 다음과 같습니다.
Triplet Loss
triplet loss는 신경망이 서로 다른 클래스 간의 거리를 최대화하고, 같은 클래스 내에서는 거리를 최소화하도록 학습시키기 위한 손실함수입니다.
triplet loss의 입력
- Anchor - 기준이 되는 데이터
- Positive - anchor와 같은 클래스에 속하는 데이터
- Negative - anchor와 다른 클래스에 속하는 데이터
tiplet loss의 수식
- : anchor vector
- : positive vector
- : negative vector
- : 벡터간 거리 함수
- : 마진(positive와 negative 간의 최소 거리 유지를 위한 임계값)
목적
anchor와 positive 사이의 거리를 최소화하며 anchor와 negative 사이의 거리는 최소 만큼 떨어져있도록 학습하는 것
Neural Style Transfer
neural style transfer은 content 이미지와 style 이미지가 주어졌을때 두 이미지를 합성하여 새로운 이미지를 생성하는 기술이다.
cost function
NST에서 사용되는 손실함수는 content와 style 두 가지 주요 요소를 기반으로 하여 생성된 이미지가 원본 이미지와 일치하는지를 측정합니다.
따라서 content loss와 style loss 두개의 조합으로 이루어집니다.
Content loss
content loss는 생성된 이미지와 content 이미지 간의 차이를 계산합니다.
Style loss
style loss는 생성된 이미지와 style 이미지 간의 차이를 계산합니다.
최종 손실 함수
𝛼,β,λ는 각각 Content, Style, Total Variation 손실의 가중치로 학습을 통해 조정되어 최적의 결과를 얻을 수 있습니다.
