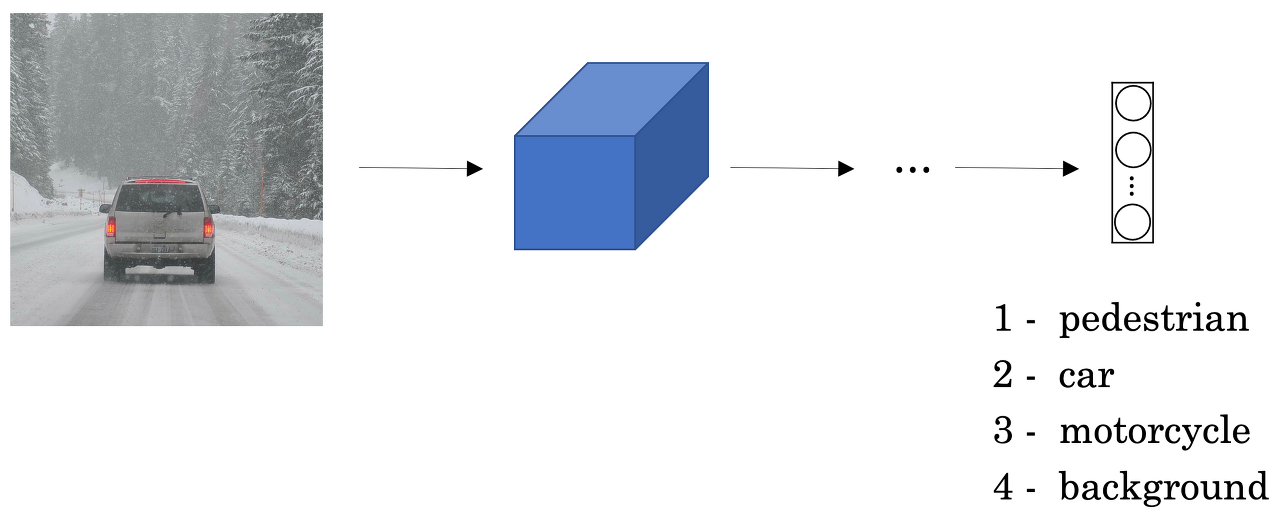
Object localization
object localization이란 이미지 데이터에서 특정 물체의 위치를 인식하는 작업이다.
일반적으로 물체의 영역을 네모 박스로 표시한다.
object localization vs object detection
localization과 detection의 차이는 물체의 수로 결정된다.
localization인 경우 한가지 물체의 위치를 박스로 표시하지만 detection인 경우 여러개의 물체의 위치를 인식하고 표시한다는 점에서 차이가 있다.
Classification with localization
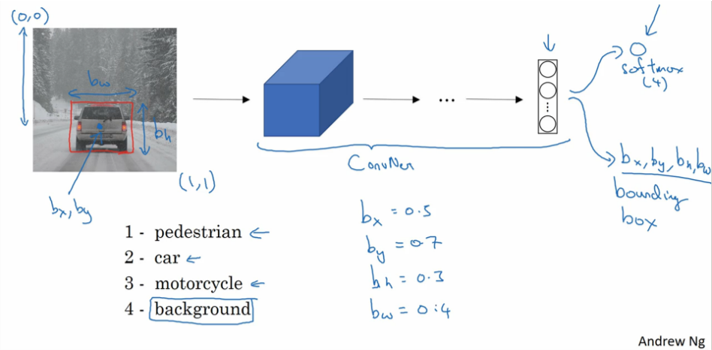
- 다중 레이어의 convolution network에 input 이미지를 입력
- 연산 후 softmax 함수를 적용한 결과 벡터 출력
- 결과 벡터를 통해 이미지를 클래스 별로 분류 및 locaization
output vector의 각 속성
: 이미지상에 물체의 존재 여부
: 물체의 중심의 x좌표
: 물체의 중심의 y좌표
: 물체의 높이
: 물체의 폭
Landmark detection
랜드마크란 이미지에서 포착하고자 하는 부분을 의미한다.
예를 들어 얼굴인식인 경우 사람의 얼굴 윤곽선을 표현할 수 있는 점, 입꼬리, 눈 등이 랜드마크가 될 수 있다.
따라서 landmark detection은 감정인식, 모션인식등에 활용될 수 있다.
Sliding Window detection
물체 인식을 하기 위한 알고리즘 중 sliding window detection에 대해 알아봅시다.

네모 박스를 왼쪽 상단에서 부터 오른쪽으로 일정 크기 만큼 이동하며 해당 영역에 물체가 존재하는지 탐지하는 방식이다.
하지만 경계가 정확하지 않으며 이미지를 작게 나눠야 하므로 컴퓨팅 자원이 너무 크다는 단점이 존재한다.
Convolutional Implementation Sliding Windows
슬라이딩 윈도의 합성곱 구현에 대해 알기 위해서는 먼저 fully connected layer를 convolutional layer로 전환하는 과정이 필요합니다.
Turning FC layer into convolutional layers
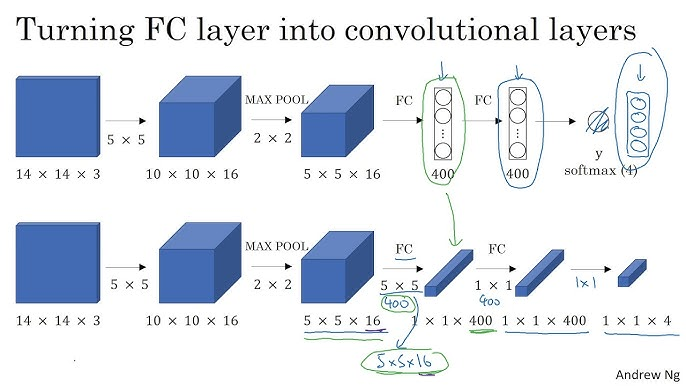
위 사진은 5x5x16의 데이터를 fc 레이어를 통해 크기가 400인 벡터로 변형합니다.
하지만 5x5x16의 데이터에 5x5의 필터를 400개 적용한다면 1x1x400의 데이터로 변형 가능합니다.
이는 fc 레이어를 적용했을때와 같은 데이터입니다.
Convolutional Implementation Sliding Windows
Convolutional Implementation Sliding Windows는 슬라이딩 윈도우의 이미지를 모두 작은 영역으로 줄이고 합성곱 연산을 한다는 단점을 보완한 방식입니다.
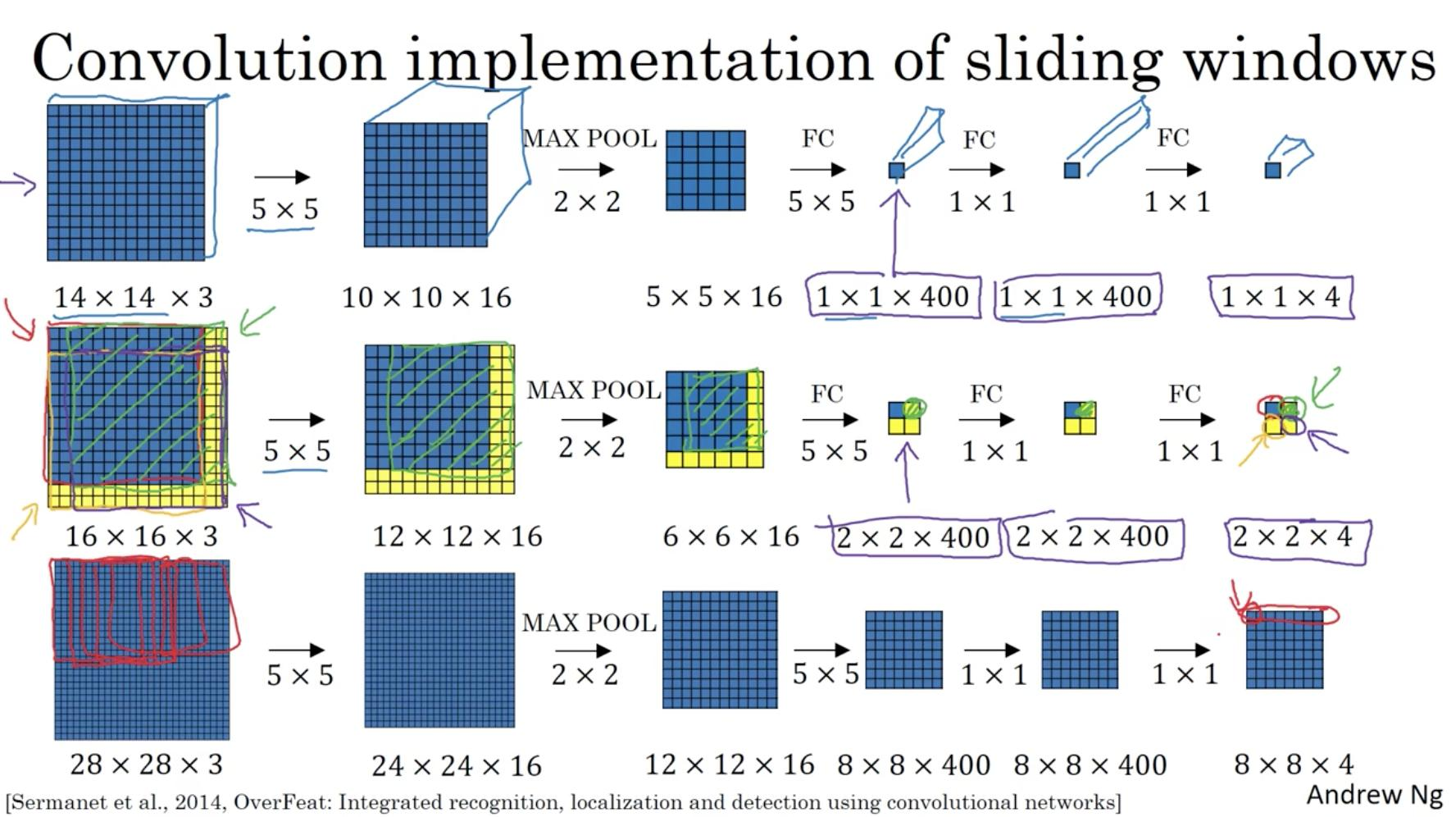
- 16x16x3의 데이터에 필터를 적용시켜 6x6x16의 데이터로 변형
- fc layer 대신 5x5x400의 필터를 적용시켜 2x2x400의 데이터로 변형
- 추가적으로 convolutin 레이어를 두번 더 적용시킴
- output은 총 4가지 부분으로 (1,1)에 해당하는 부분은 원본 이미지의 왼쪽 상단 14x14x3의 영역으로 파란색 영역이 주를 이루기 때문에 파란색으로 출력됨, 나머지 부분은 모두 노란색 영역이 포함되므로 노란색으로 출력됨
따라서 슬라이딩 윈도 처럼 여러번의 연산을 수행하지 않고 한번의 연산으로 모든 구역의 특성을 알 수 있게 되었다.
Intersection Over Union
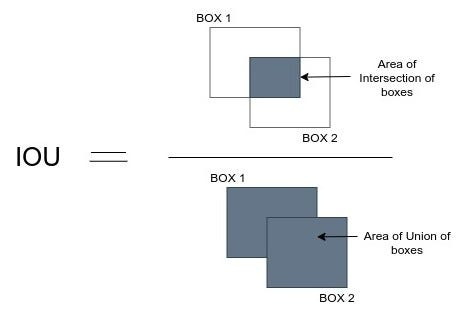
Intersection Over Union은 박스의 교집합을 박스의 합집합으로 나눈 값 입니다.
따라서 실제 결정 상자와 예측 결정 상자가 겹칠 수록 iou의 값은 높게 측정됩니다.
Nonmax Suppression
박스를 이용해서 물체를 탐지하다 보면 한 물체에 대한 박스가 여러개 발생해 여러개의 물체로 인식하는 문제가 발생할 수 있습니다.
따라서 가장 정확도가 높은 박스 하나를 선택하고 나머지는 버리는 과정이 필요합니다.

해당 이미지에서는 한 사람을 탐지한 박스가 총 3개입니다.
Nonmax Suppression은 가장 확률이 높은 박스를 선택하고 선택된 박스와의 iou가 높은 나머지 박스들을 억제합니다.
따라서 확률이 가장 높은 초록색 박스가 남고 나머지 iou가 높은 주변 박스들은 제외됩니다.
Anchor Boxes
앵커박스는 객체가 있을 법한 곳에 설정된 박스이다.
이를 통하여 해당 앵커 박스의 영역에 실제 객체가 있는지 탐색할 수 있습니다.
추가적으로 여러개의 앵커박스를 통해 한 박스 내에 여러개의 물체를 인식하는 것도 가능합니다.
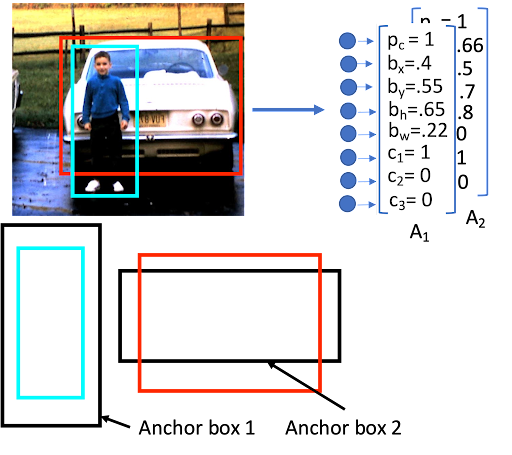
ex) 앵커 박스가 두개인 경우
위의 배경에서 자동차를 인식하는 경우 결과 벡터는 크기가 8이였다.
하지만 앵커 박스를 통해 한 박스 안에서 두개의 물체를 탐지하는 경우 각 앵커박스마다 벡터를 가지므로 8x2의 데이터가 된다.
1번째 차원인 경우 세로로 긴 앵커에 대한 값으로 사람을 탐지하고
2번째 차원인 경우 가로로 긴 앵커에 대한 값으로 자동차를 탐지한다.
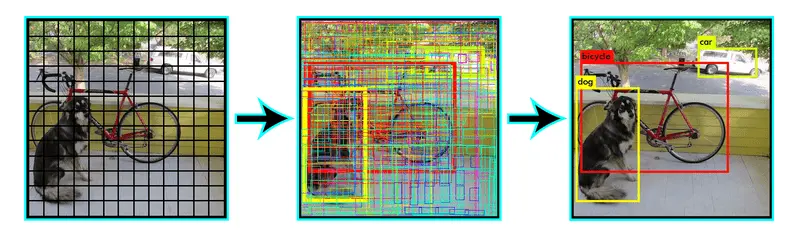
YOLO Algorithm
YOLO 알고리즘의 작동 방식
- 입력 이미지를 n x n의 그리드로 분할
- 각 그리드에 대해 경계 상자를 예측
- 각 그리드의 클래스 확률 예측
R-CNN
R-CNN은 모든 영역을 탐색하는 방식과는 달리 객체가 존재할 법한 영역에 대해서만 탐색을 진행한다.
작동 방식
- 객체 후보 영역 추출
- CNN을 통한 특징 추출
- 클래스 분류 및 경계 상자 조정
