Basic Models
sequence to sequence model
시퀀스-투-시퀀스 모델은 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델입니다. 예를들어 챗봇과 기계 번역이 그러한 대표적인 예입니다. 그 외에도 내용 요약과 STT에서 사용될 수 있습니다.
SEQ2SEQ 모델은 크게 인코더와 디코더라는 두개의 모듈로 구성됩니다. 인코더는 입력 문장의 모든 단어들을 순차적으로 입력받은 후 마지막에 이 모든 단어 정보들을 압축해서 하나의 벡터로 만드는데, 이를 컨텍스트 벡터라고 합니다. 디코더는 컨텍스트 벡터를 받아 단어를 하나씩 순차적으로 출력합니다.
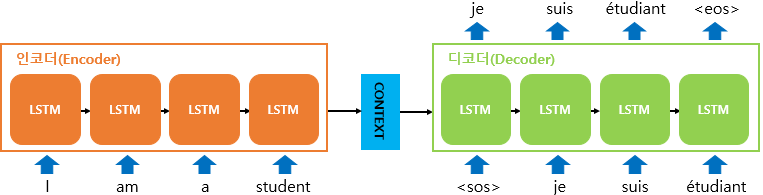
image captioning
이미지 캡셔닝 모델은 컨볼루셔널 레이어와 FC레이어를 함께 사용하여 이미지 데이터의 특징을 추출한 후 해당 특징을 LSTM모델에 입력하여 문장을 출력하는 모델입니다.
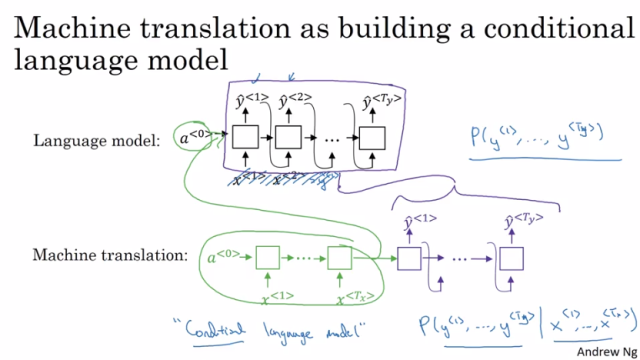
machine translation as building a conditional language model
language model
언어 모델은 주어진 문맥에서 다음 단어가 무엇일지를 예측하는 모델입니다. RNN을 기반으로 하여 순차적으로 입력을 받은 후 이전 단계의 정보를 기억하면서 다음 단어를 예측하는 구조입니다.
machine translation
기계 번역 모델은 인코더 셀과 디코더 셀로 나누어져 있으며 인코더에서 입력 문장을 순차적으로 입력받은 후 디코더 셀에서 데이터를 순차적으로 출력합니다.
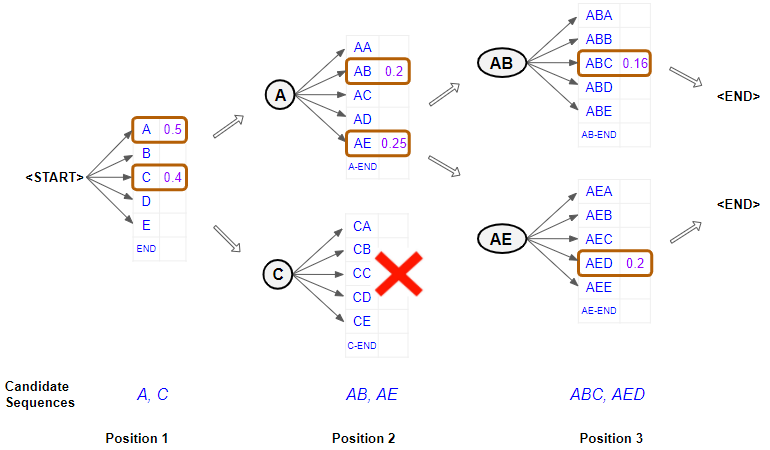
greedy search
그리디 서치는 그 순간에서 가장 확률이 높은 단어를 선택하는 방식이다.
예를 들어 jane is 라는 두 단어가 있고 뒤의 단어를 예측한다고 해보자. 그리디 서치를 사용한다면 확률이 높은 going을 선정할 것이다. 하지만 이렇게 되면 전체 문맥에 어울리지 못하는 단어가 선정될 수 있다는 단점이 존재한다. 따라서 Beam search 알고리즘을 통해 해당 문제를 해결한다.
beam search
기계 번역이나 자연어 생성과 같은 작업에서 문장 생성의 최적화를 위해 사용하는 탐색 알고리즘입니다. 순차적으로 여러개의 가능성 중에서 가장 가능성이 높은 후보들을 추적하고, 최종적으로 최적의 결과를 선택하는 방식입니다.
beam search는 모든 가능한 문장을 탐색하지 않고, 빔 너비로 불리는 고정된 개수의 후보군만을 유지하면서 탐색 범위를 좁히는 방식으로 동작합니다.
length normalization
beam search 과정에서 긴 문장이 불리하게 선택되지 않도록 문장의 길이에 따른 확률값을 조정하는 방법입니다. beam search는 누적 확률을 기반으로 문장을 생성하는데, 긴 문장은 더 많은 단어들이 곱해지기 때문에 확률값이 작아져 짧은 문장에 비해 불리해질 수 있습니다.
길이 보정 방식에는 평균을 내는 방식과 확률 값을 계산할 때 길이 정규화 계수 알파를 도입하여 문장의 길이에 의존하지 않도록 조정하는 방법이 있습니다.
Error Analysis in Beam Search
기계 번역이나 자연어 생성에서 beam search 알고리즘이 선택한 문장이 왜 최적의 문장이 아닐 수 있는지, 그리고 그로 인해 발생한 오류를 분석하는 과정입니다.
beam search 알고리즘에서 발생할 수 있는 오류 유형은 다음과 같습니다.
- 부적절한 너비 선택으로 너비가 너무 넓으면 무의미한 후보 문장이 남을 수 있고 너비가 좁다면 중요한 후보 문장을 탐색하지 못할 수 있습니다.
- 탐색 공간 가지치기로 인하여 잠재적으로 좋은 문장을 놓칠 수 있습니다.
- 노출 편향으로 잘못된 초기 선택이 연쇄적으로 오류를 일으켜 문장의 전체 품질이 떨어질 수 있습니다.
- 매 단계마다 가장 가능성 높은 후보군을 선택하므로 국소 최적해에 빠질 수 있습니다.
Bleu Score
기계 번역이나 자연어 생성 모델의 성능을 평가하는 대표적인 지표입니다. 기계 번역 시스템이 생성한 번역 문장이 실제로 사림이 번역한 문장과 얼마나 유사한지 측정하기 위해 사용됩니다. n-gram기반의 정밀도를 계산하여 번역의 정확성을 측정합니다.
n-gram이란 문장을 연속된 n개의 단어로 분할한 단어 묶음입니다. n=1이면 unigram, n=2이먄 biagram이라 부릅니다. bleu score는 n-gram 정밀도를 기반으로 평가되며, 1개 이상의 단어가 연속으로 이어지는 경우가 얼마나 참조 문장과 일치하는지 계산합니다.
clipping은 동일한 단어가 여러번 등장하는 경우, 참조 문장에서 해당 단어가 등장한 횟수만큼만 일치하는 것으로 계산하는 방법입니다. 예를들어 참조 문장에서 the가 2번 등장했는데 생성 문장에서 the가 3번 생성된 경우, 2번만 일치한 것으로 계산합니다.
bleu score는 짧은 문장이 유리해지는 문제를 방지하기 위해 bp를 사용합니다. 생성된 문장의 길이가 참조 문장의 길이보다 크다면 bp가 1이 되며, 그 반대의 경우에는 가 됩니다.
BLEU Score는 unigram, bigram, trigram, 4-gram 정밀도를 모두 결합하여 계산됩니다.
attention model
attention 모델은 입력 시퀀스에서 중요한 부분에 더 많은 가중치를 부여하여 번역이나 요약 등의 작업에서 모델이 더 관련성 있는 정보를 학습할 수 있도록 도와줍니다. 해당 메커니즘은 특히 입력 시퀀스가 길어지거나 복잡해질 때 모델 성능을 크게 향상 시킵니다.
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점마다, 인코더에서의 전체 입력 문장을 다시 한번 참고한다는 점입니다. 단, 전체 문장을 전부 동일한 비율로 참고하는 것이 아닌, 해당 시점에서 예측해야할 단어와 연관 있는 입력 단어 부분을 좀 더 집중해서 보게 됩니다.
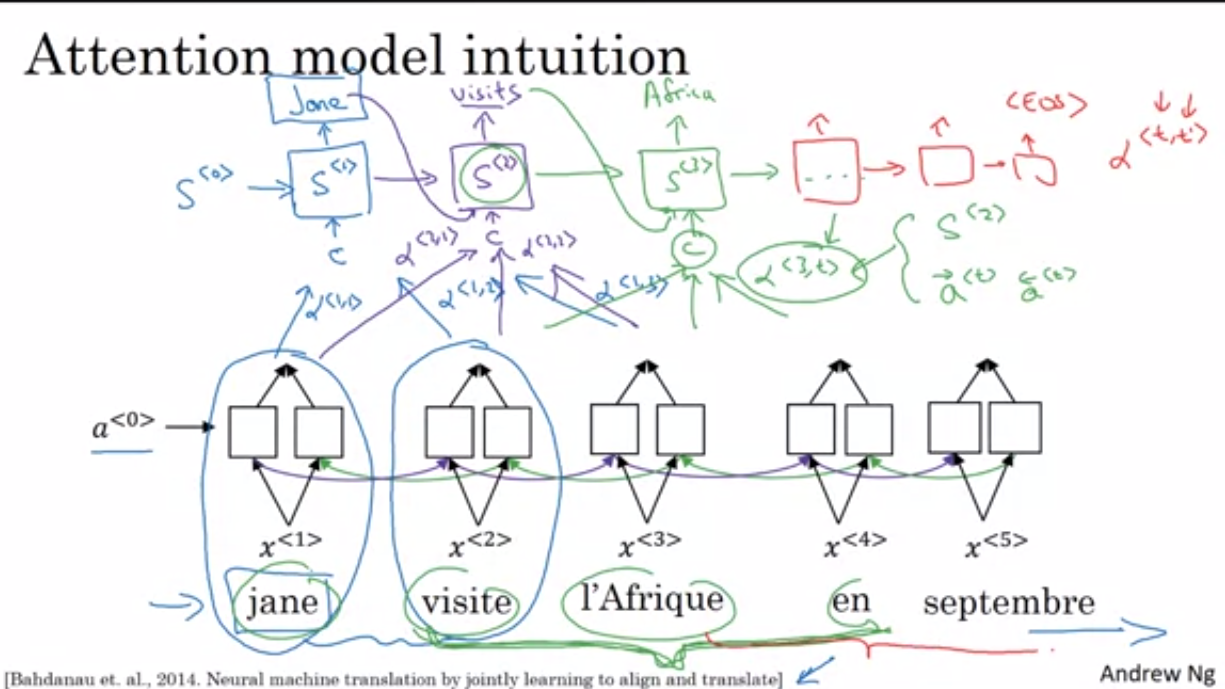
<어텐션 모델은 더 공부해야함>
speech recognition
음성 인식은 음성 신호를 텍스트로 변환하는 기술을 말합니다. 음성 인식은 자연어 처리와 신호 처리 기술을 결합하여 사용자의 음성을 분석하고, 그 음성이 의미하는 문장이나 단어를 텍스트 형태로 출력하는 과정입니다.
RNN 인코더를 사용하여 시퀀스 데이터를 처리합니다. 해당 단계에서 어텐션 메커니즘이 적용되어 입력 시퀀스의 각 부분이 전체 시퀀스에서 어떻게 상관관계가 있는지를 학습합니다. 디코더에서 이전 시간 단계의 출력과 인코더의 컨텍스트 벡터를 결합하여 다음 단어를 예측합니다.
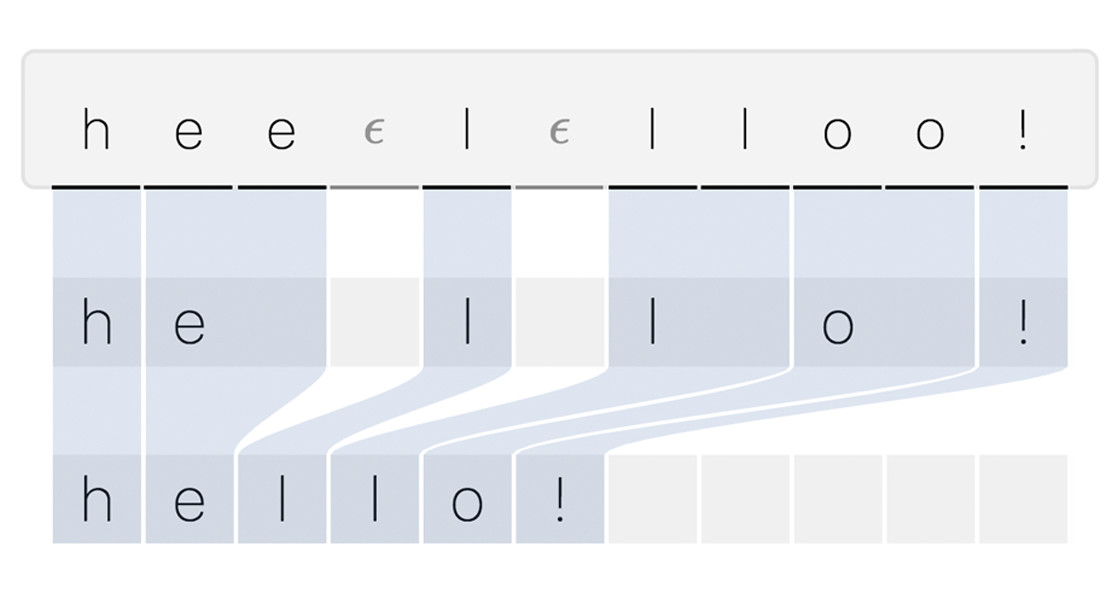
Connectionist Temporal Classification
음성 인식과 같은 시퀀스 변환 작업에서 주로 사용되는 손실 함수입니다. 입력 음성 신호에 대해 모델은 확률 분포를 출력합니다. 예를들어 특정 시간 프레임에서 H,E,L,O,Blank 각각의 확률을 예측합니다.
Trigger Word Detection
특정 단어 또는 구문을 음성 데이터에서 인식하는 기술입니다. 해당 기술은 주로 음성 인식 시스템에서 사용되며, 사용자의 명령이나 질문을 인식하여 시스템이 반응하도록 하는 역할을 합니다.
RNN모델을 이용하여 구현됩니다. RNN모델의 입력으로 시퀀스한 음성 데이터가 주어지고, 해당 모델은 특정한 단어 또는 구문을 인식하면 출력값으로 1을 리턴하고 그 외의 경우에는 0을 리턴합니다.
