About transformer
트랜스포머는 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 어텐션만으로 구현한 모델입니다. 이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 RNN보다 우수한 성능을 보여주었습니다.
기존의 seq2seq
기존의 seq2seq 모델은 인코더-디코더로 설계되어 있어, 인코더가 입력 시퀀스를 하나의 벡터로 압축하는 과정에서 입력 시퀀스의 정보가 일부 손실된다는 단점이 있었고 이를 보정하기 위하여 어텐션을 사용하였습니다.
transformer
seq2seq 구조에서는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점을 가지는 구조였다면, 트랜스포머는 인코더와 디코더의 단위가 N개로 구성되는 구조입니다.
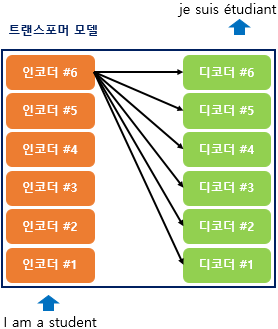
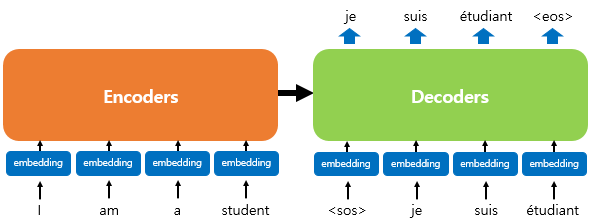
위 그림은 인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는 트랜스포머의 구조를 보여줍니다. 디코더는 기존의 seq2seq과 유사하지만 RNN이 사용되지 않습니다.
positional encoding
트랜스포머는 RNN을 사용하지 않으므로 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하는 다른 방식이 필요합니다. 트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하는 포지셔널 인코딩을 사용합니다.

해당 그림은 입력으로 사용되는 임베딩 벡터들이 트랜스포머의 입력으로 사용되기 전에 포지셔널 인코딩의 값이 더해지는 것을 보여줍니다.
Attention
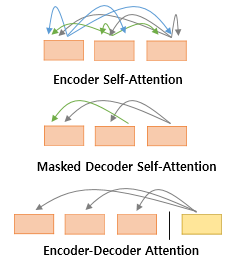
첫번째 그림인 셀프 어텐션은 인코더에서 이루어지지만, 두번째 그림인 셀프 어텐션과 세번째 그림인 인코더-디코더 어텐션은 디코더에서 이루어집니다.
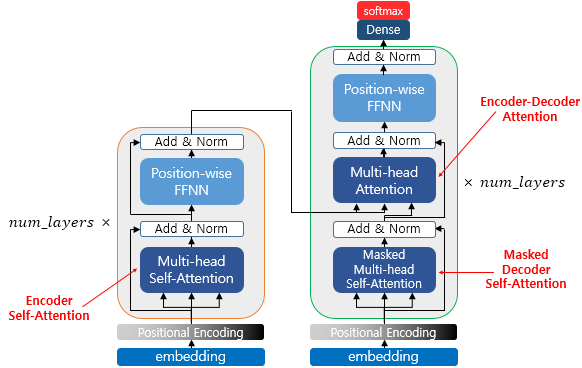
위 그림은 트랜스포머의 아키텍쳐에서 세가지 어텐션이 각각 어디에서 이루어지는지를 보여줍니다. 세게의 어텐션에 추가적으로 멀티헤드라는 이름이 붙습니다.
self attention
어텐션 함수는 주어진 쿼리에 대해서 모든 키와의 유사도를 각각 구합니다. 그리고 구해낸 유사도를 가중치로 하여 키와 맵핑되어 있는 각각의 값에 반영해줍니다. 이후 유사도가 반영된 값을 모두 가중합하여 리턴합니다.
multi-head attention
기본 어텐션 메커니즘을 여러번 적용하여 다양한 관점에서 입력 정보를 처리할 수 있게 해줍니다, 각 어텐션 head는 서로 다른 초기화된 Q,K,V를 사용하여 독립적으로 계산합니다. head가 각각 독립적으로 작동하기 때문에 병렬처리가 가능하여 학습 속도를 향상시킬 수 있습니다.
