Chapter 7 모델 평가
1) 분류 모델 평가의 개념
-
대부분 다양한 모델, 파라미터를 두고 상대적으로 비교
-
회귀 모델은 실제 값과의 에러치를 가지고 계산함
-
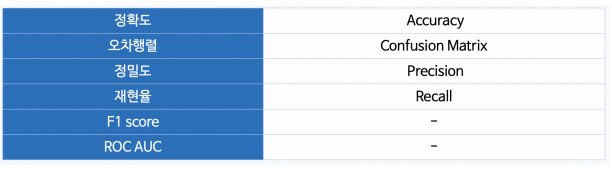
분류 모델의 평가 항목
-
이진 분류 모델의 평가

-
Accuracy: 전체 데이터 중 맞게 예측한 것의 비율
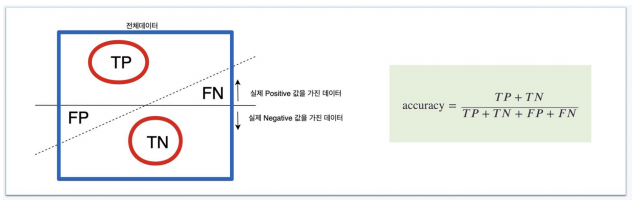
-
Precision: 양성으로 예측한 것 중에서 실제 양성의 비율
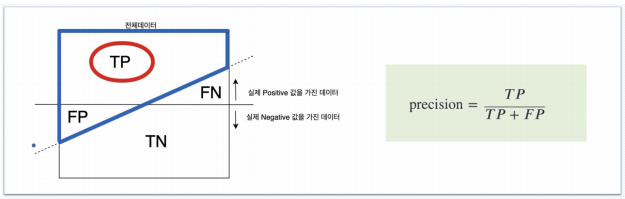
-
Recall(= TPR:True Positive Rate): 참인 데이터들 중에서 참이라고 예측된 것
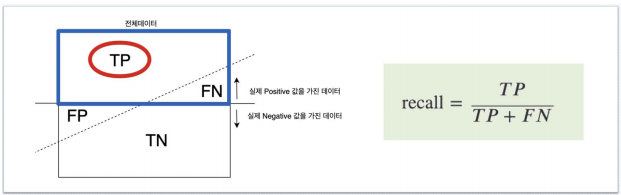
-
Fall-out(=FPR: False Positive Ratio): 실제 양성이 아닌데, 양성이라고 잘못 예측한 경우
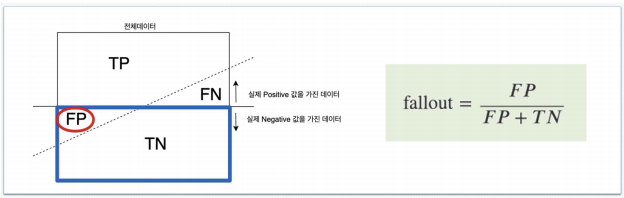
-
분류 모델은 그 결과를 속할 비율(확률)을 반환
-> Threshold = 0.4

- F1-Score: Recall과 Precision을 결합한 지표, 두 지표가 어느 한쪽으로 치우치지 않고 둘 다 높은 값을 가질수록 높은 값을 가짐

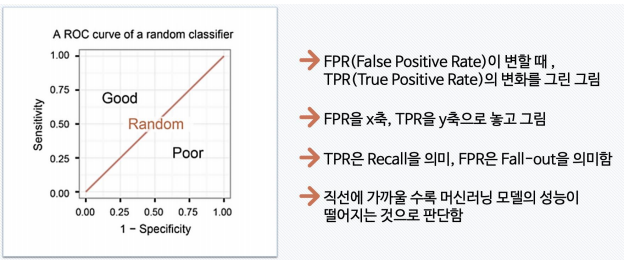
2) ROC와 AUC
- ROC 곡선
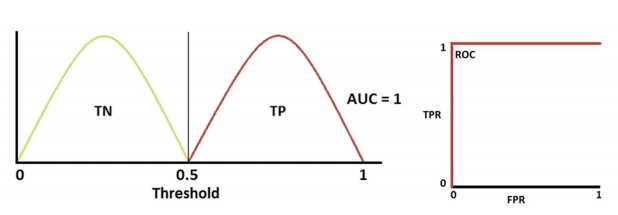
-> 완벽 분류
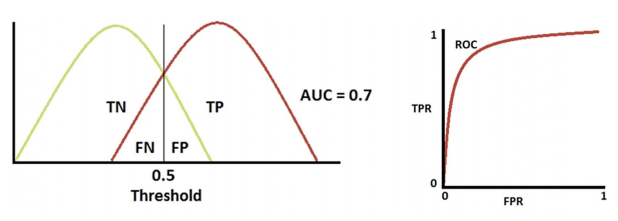
-> 분류가 잘 된 경우
-> 분류성능이 나쁜 경우
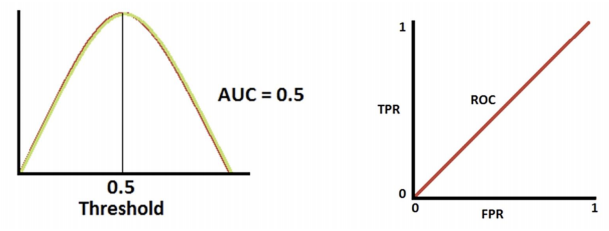
- AUC: ROC 곡선 아래의 면적으로 일반적으로 1에 가까울수록 좋은 수치

Chapter 8 Pipeline
- Jupyter Notebook 상황에서 데이터의 전처리와 여러 알고리즘의 반복 실행, 하이퍼 파라미터의 튜닝 과정을 번갈아 하다 보면 코드의 실행 순서에 혼돈이 있을 수 있음
- 이걸 class로 만들어서 진행해도 되지만, sklearn에는 Pipeline 기능이 있음
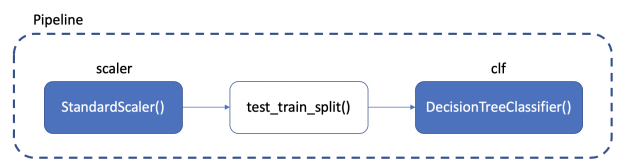
-> 여기서 test_train_split은 Pipeline 내부가 아님
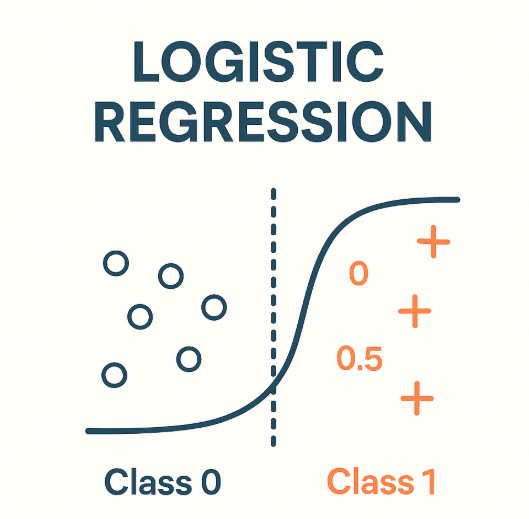
Chapter 9 Logistic Regression
- 이름은 regression이지만 분류기
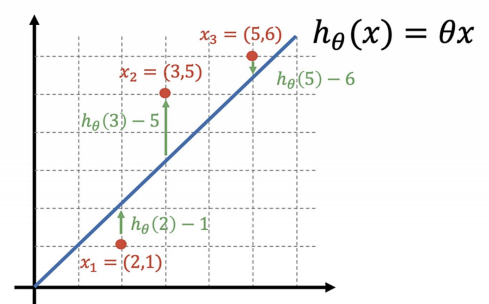
비용함수
-
비용 함수를 최소화할 수 있으면 최적의 직선을 찾을 수 있음


-
비용함수의 최솟값 구하기
1) 랜덤하게 임의의 점 선택
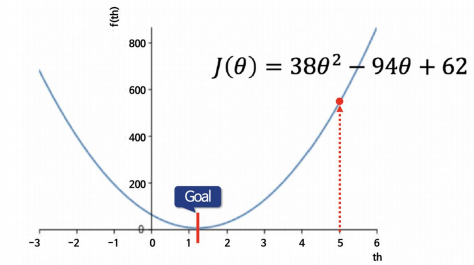
2) 임의의 점에서 미분(편미분) 값을 계산해서 업데이트

3) 목표점의 오른쪽/왼쪽 일 경우
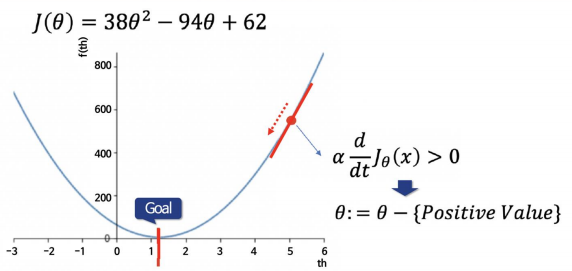
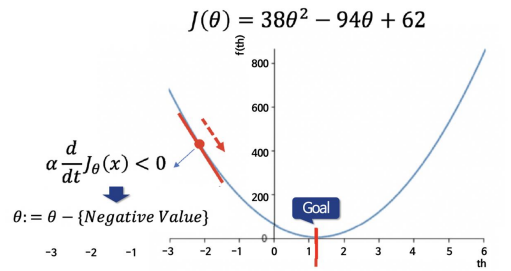
-
Learning Rate
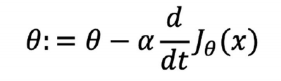
-> 학습률이 작을 때
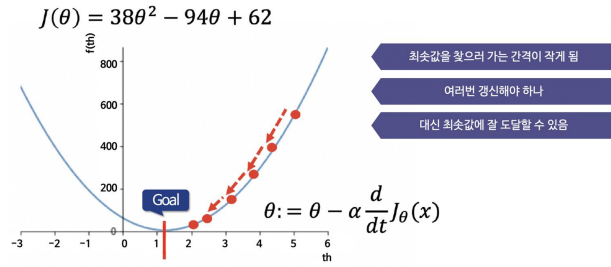
-> 학습률이 클 때
이 글은 제로베이스 강의 자료 일부를 발췌하여 작성되었습니다
