데이터 이론 학습
1.통계 (1)

Chapter1 기초통계_기초과정 1) Introduce 통계학(statistics): 산술적 방법을 기초로 하여, 주로 다양한 데이터를 관찰하고 정리, 분석하는 방법을 연구하는 수학의 한 분야 기술통계학(descriptive statistics): 데이터를 수집하고
2.통계 (2)

확률밀도함수(probability density function): 연속형 확률 변수 X에 대해서 함수 f(x)가 아래의 조건을 만족하면 확률밀도함수라고 함모든 ( X )에 대해서 $$f(x) \\geq 0$$$$P(x \\in (-\\infty, \\infty))
3.통계 (3)

추정(estimation): 모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것추정량(estimator): 표본 평균으로 모평균을 추정할 때 표본 평균을 모평균에 대한 추정량이라고 함점추정(point estimation): 모수를 하나의
4.통계 (4)
범주형 자료(categorical data): 관측된 결과를 어떤 속성에 따라 몇 개의 범주로 분류 시켜 도수로 주어진 데이터범주형 자료 분석\-> 범주형 자료에 대한 통계적 추론 방법\-> 범주형 자료 분석은 카이제곱 검정으로 추론t-test와 카이제곱 검정의 차이\
5.통계 (5)
분산분석(analysis of variance): 셋 이상의 모집단의 평균 차이를 검정t-test: 두개의 모집단의 평균 차이를 검정실험계획법(experimental design): 모집단의 특성에 대하여 추론하기 위해 특별한 목적성을 가지고 데이터를 수집하기 위한 실
6.선형대수 (1)
Chatper 1 벡터 1) 벡터의 정의와 표기법 벡터: 물리학 및 공학에서 위치, 속도, 힘 등과 같이 크기와 방향성을 나타냄 공학에서는 벡터 공간이 유클리드 공간인 경우를 다룸 유클리드 벡터, 기하 벡터, 공간 벡터라고 부름 벡터와 대비하여 크기만을 갖는 대상을 스
7.선형대수 (2)

Chapter 3 선형대수학 1) 선형 방정식 소개 선형 방정식:linear equation 비선형 방정식: nonlinear equation 선형 방정식 계(A system of linear equation): 같은 변수들을 포함한 선형 방정식이 1개 또는 그 이
8.선형대수 (3)

\*\*분해(Factorizaiton, Decomposition)하나의 행렬을 두개 혹은 3개 이상의 행렬 곱으로 표현한 식A행렬을 B와 C의 곱으로 표현한 형태를 분해라고 함(A = BC)LU 분해(LU Decomposition)1) A의 역행렬을 이용: 모든 경우를
9.선형대수 (4)

Chapter 3 선형대수학 10) 특성 방정식 특성방정식(Characterisitic equation) 특성방정식은 det(A- 𝜆I) = 0을 의미함 𝜆가 특성방정식을 만족하면 𝜆는 행렬 A의 eigenvalue임 예시 -> 𝜆(eigenvalue)는 5,
10.분석방법론
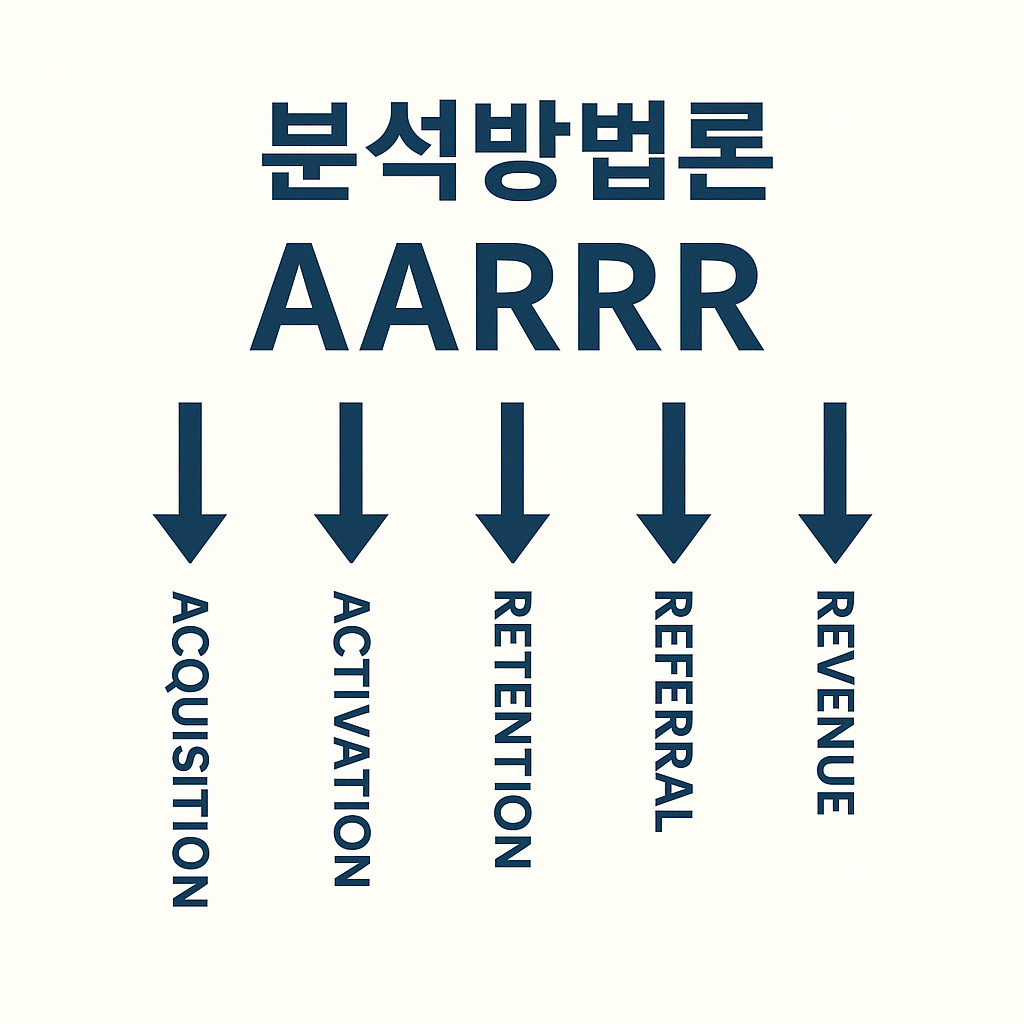
제품 중심의 성장 기업이 추적 해야 하는 5가지 사용자 행동 지표획득, 활성화, 리텐션, 수익, 추천의 약어대부분의 Product Analysis가 해당 프레임웍을 활용하여 지표를 수립하고 고객을 이해하며, 제품 및 서비스를 성장시키기 위해 사용함, 마케팅을 위한 전략
11.머신러닝 (1)
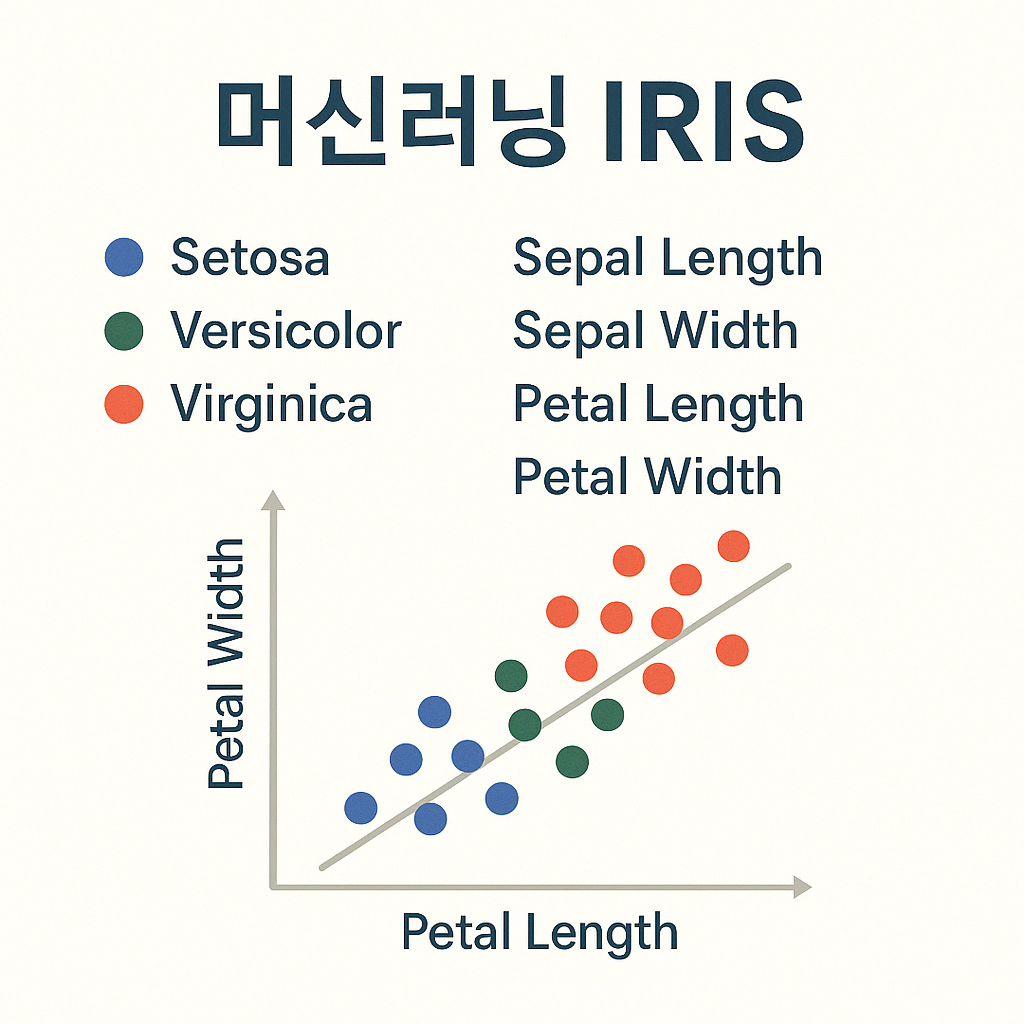
Iris의 품종 분류\-> IRIS는 Versicolor, Virginica, Setosa 3종류로 나눌 수 있음\-> 꽃잎(petal), 꽃받침(sepal)의 길이/너비 정보를 이용해서 이 3종의 품종을 구분엔트로피: 물질의 열적 상태를 나타내는 물리량의 단위
12.머신러닝 (2)
데이터 기반 문제 해결 절차\-> 모델 스스로 데이터를 기반으로 변화에 대응지도학습의 종류\-> 1) 분류 Classification\-> 2) 회귀 Regression비지도학습의 종류\-> 1) 군집\-> 2) 차원 축소머신러닝 모델 만들기 (주택 가격을 예측한다면)
13.머신러닝 (3)

Chapter 5 와인 데이터 분류 레드와인/화이트와인 두 종류의 데이터셋 존재 두개의 데이터를 합칠때 각각을 구분할 수 있는 부분이 필요함 Boxplot을 통해 와인 데이터 항목들을 그렸을 때, 컬럼들의 최대, 최소 범위가 각각 다르고 평균과 분산이 각각 다름 특성
14.머신러닝 (4)
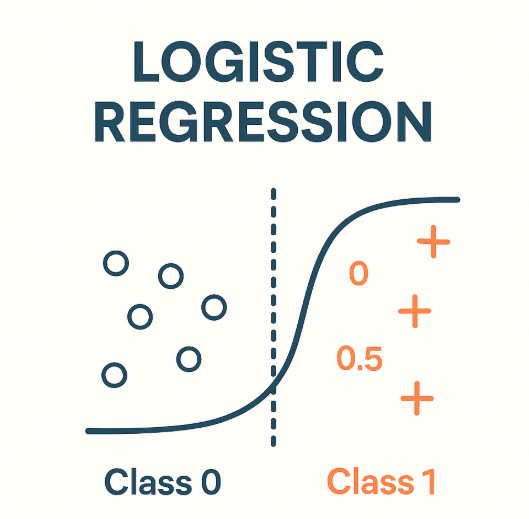
Chapter 7 모델 평가 1) 분류 모델 평가의 개념 대부분 다양한 모델, 파라미터를 두고 상대적으로 비교 회귀 모델은 실제 값과의 에러치를 가지고 계산함 분류 모델의 평가 항목 이진 분류 모델의 평가 
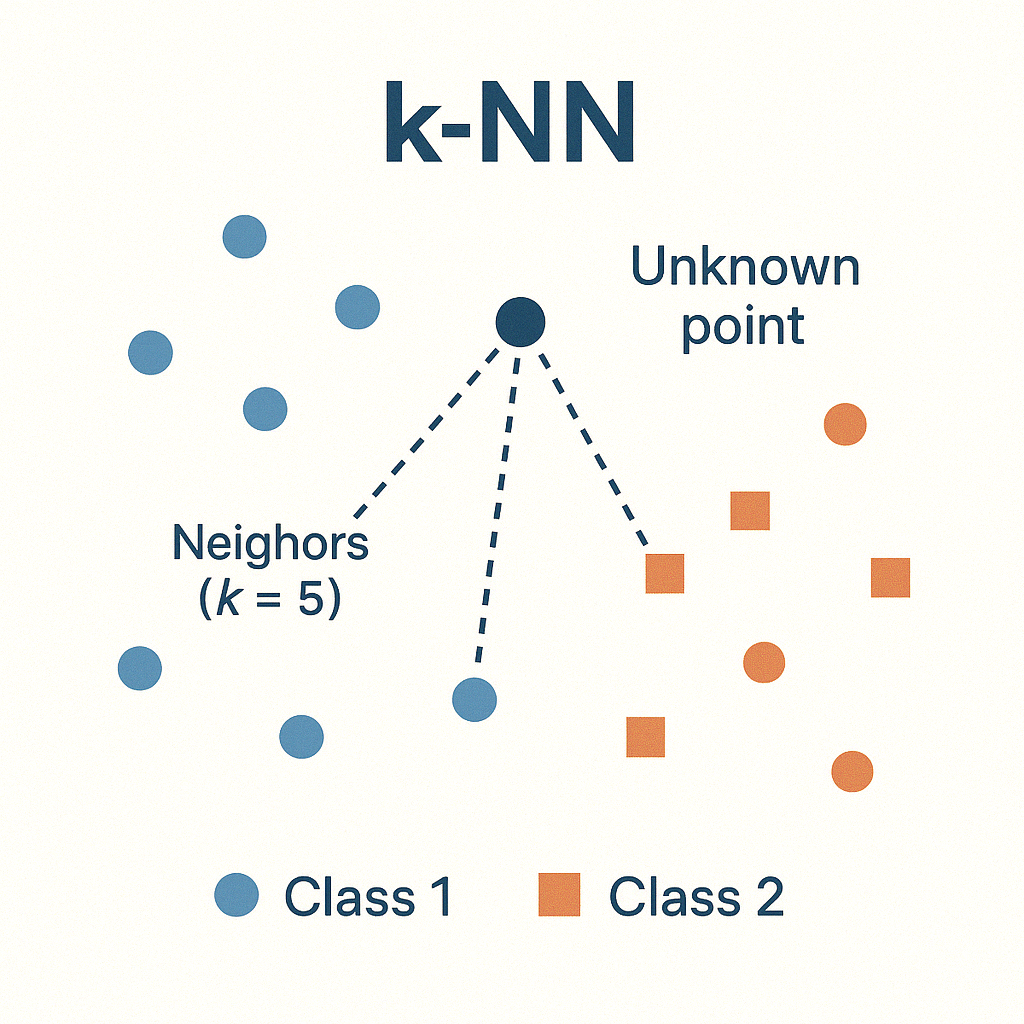
과적합: 모델이 학습 데이터에만 과도하게 최적화되어 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상holdoutk-fold cross validationstratified k-fold cross validation검증 validation이 끝난 후 test용 데
16.머신러닝 (6)
여러개의 분류기를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측 값을 얻는 것voting (여러 모델 사용)bagging (동일한 모델 사용, 데이터셋이 다름)\-> 데이터 중복
17.머신러닝 (7)

차원축소(dimensionality reduction)와 변수추출(feature extraction) 기법으로 널리 쓰이고 있는 주성분분석(Principal Component Analysis)PCA는 데이터의 분산(variance)을 최대한 보존하면서 서로
18.Tensorflow (1)
민스키의 기호주의연결주의입력이 2개인 퍼셉트론퍼셉트론의 한계 XOR\-> 해결방법은 곡선\-> 다층 퍼셉트론이 필요 편향을 고려한 표현활성화 함수 h활성화함수는 비선형이 주로 사용\-> 함수의 합성에서 선형함수를 사용하면 합성의 의미가 없음시그모이드ReLU신경망은 행렬
19.Tensorflow (2)
머신러닝을 위한 오픈소스 플랫폼: 딥러닝 프레임워크구글이 주도적으로 개발하여 구글 코랩에는 기본적으로 장착 됨Tensor: 벡터나 행렬Graph: 텐서가 흐르는 경로Tensor Flow: 텐서가 Graph를 통해 흐름신경망에서 아이디어를 얻어서 시작된 Neural Ne
20.Tensorflow (3)
Chapter 6 마스크 착용 여부 예측 마스크 착용 여부 예측 Chapter 7 CNN 모델 학습을 통한 개와 고양이 분류 개와 고양이 분류 Chapter 8 VGG [VGG](https://drive.
21.Tensorflow (4)
Pytorch CNNpytorch transfer learning이 글은 제로베이스 강의 자료 일부를 발췌하여 작성되었습니다
22.SQL (1)

Chapter 2 Database 사용해보기 Database 정의 Database: 여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합체 DBMS(Database Management System): 사용자와 데이터베이스 사이에서 사용자의 요구에
23.SQL (2)

Table: 데이터베이스 안에서 실제 데이터가 저장되는 형태, 행과 열로 구성된 뎅이터 모음Table 생성 문법id(int)와 name(varchar(16)) 칼럼을 가지는 mytable 이라는 이름의 테이블 생성Table 목록 확인 문법Table 정보 확인 문법Ta
24.SQL (3)

Chapter 7 Logical Operations 논리 연산자 AND 조건을 모두 만족하는 경우 TRUE OR 하나의 조건이라도 만족하면 TRUE NOT 조건을 만족하지 않는 경우 TRUE BETWEEN 조건값이 범위 사이에 있으면 TRUE IN 목록 안에
25.SQL (4)

두개 이상의 테이블을 결합하는 것두 개의 테이블에서 공통된 요소들을 통해 결합하는 조인방식두개의 테이블에서 공통영역을 포함해 왼쪽 테이블의 다른 데이터를 포함하는 조인방식두개의 테이블에서 공통영역을 포함해 오른쪽 테이블의 다른 데이터를 포함하는 조인방식두개의 테이블에서
26.SQL (5)

Chapter 14 Primary key, Foreign key Primary Key(기본키) 테이블의 각 레코드를 식별 중복되지 않은 고유값을 포함 NULL 값을 포함할 수 없음 테이블 당 하나의 기본키를 가짐 Primary key 삭제 문법 Foreign Key
27.기초통계

Chapter 1 기초통계와 데이터 분석 기초 데이터의 종류 Numerical(수치형) -> 수치 값으로 표현되는 데이터로 연속적 또는 이산적일 수 있음 -> 예시) 연속적: 키, 몸무게, 온도 등, 이산적: 판매된 제품의 개수, 사람 수 등 -> 분석방법: 중앙값,