Chapter 13 앙상블 기법
-
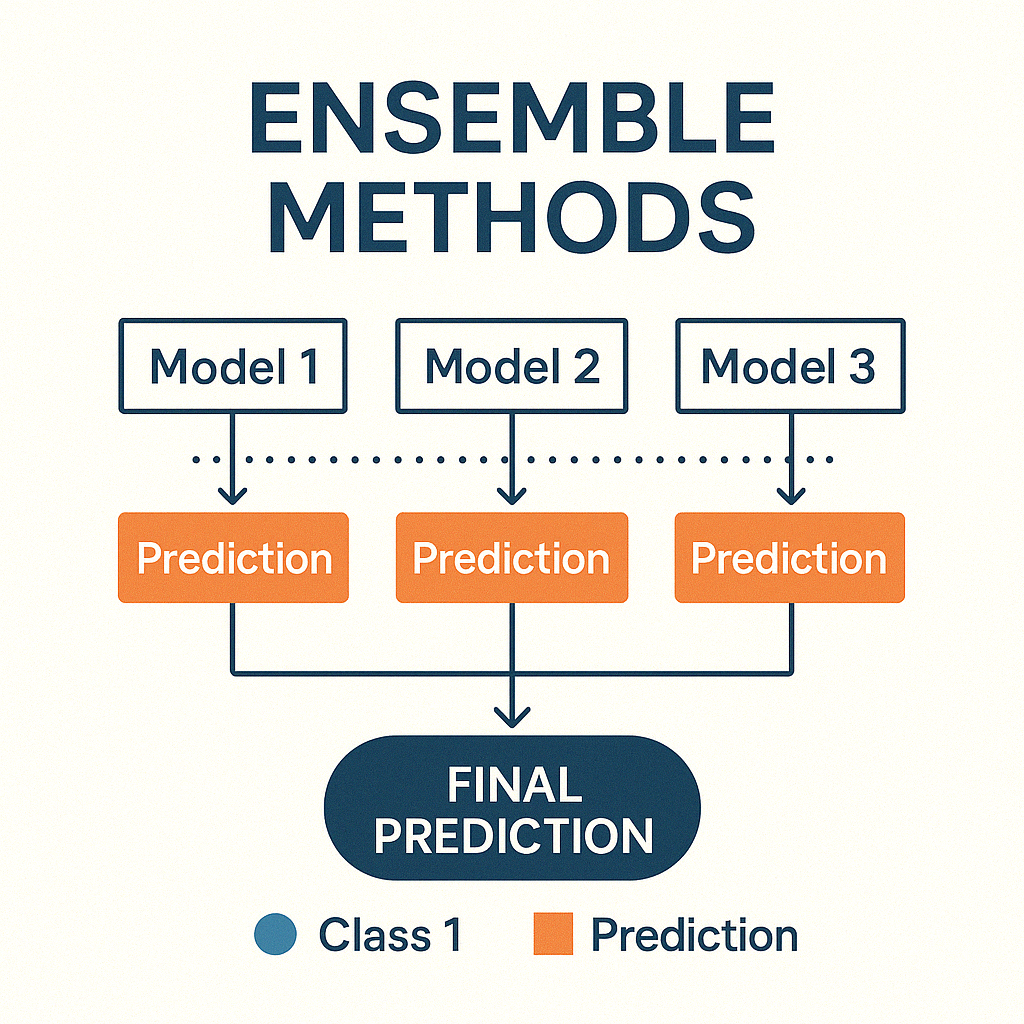
여러개의 분류기를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법
-
다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측 값을 얻는 것
-
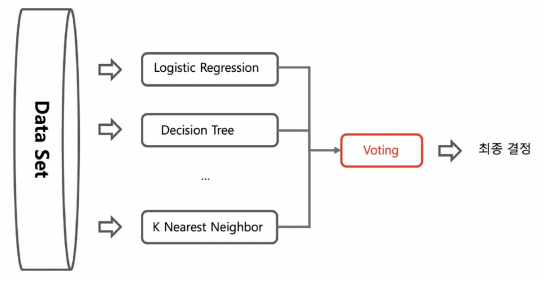
voting (여러 모델 사용)
-
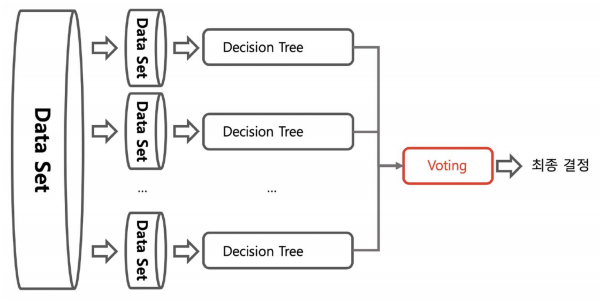
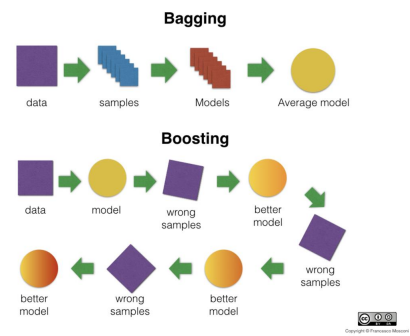
bagging (동일한 모델 사용, 데이터셋이 다름)
-> 데이터 중복을 허용해서 샘플링하고 그 각각의 데이터에 같은 알고리즘을 적용해서 결과를 투표로 결정
-> 각각의 분류기에 데이터를 각각 샘플링해서 추출하는 방법을 부트스트래핑 분할 방식이라고 함
-
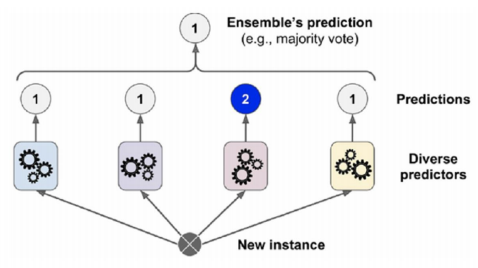
최종 결정에서 소프트보팅: 다수결의 원칙과 비슷
-
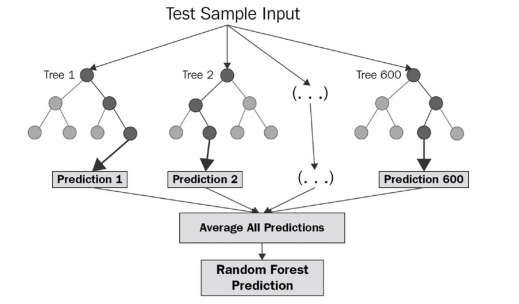
랜덤포레스트
-> 같은 알고리즘으로 구현하는 배깅의 대표적인 방법
-> 앙상블 방법 중에서 비교적 속도가 빠르며 다양한 영역에서 높은 성능을 보여줌
-> 결정 나무를 기본으로 함
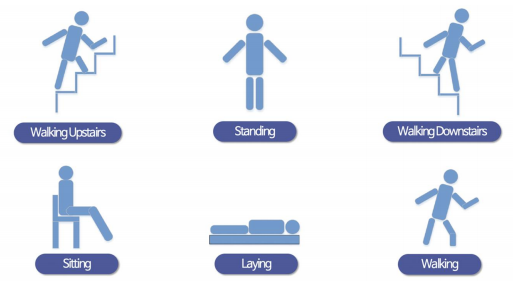
HAR(Human Activity Recognition)
-
IMU 센서를 활용해서 사람의 행동을 인식하는 실험
-
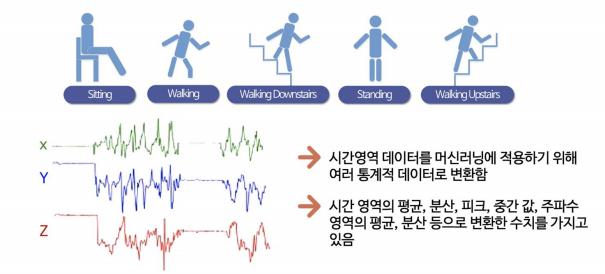
데이터 특성
-> 가속도계로부터의 3축 가속도 및 추정 된 신체 가속도
-> 자이로스코프의 3축 각속도
-> 시간 및 주파수 영역 변수가 포함 된 561기능 벡터
-> 활동 라벨
-> 실험을 수행한 대상의 식별자 -
데이터 클래스
Chapter 14 Credit Card Fraud Detection
-
앙상블 기법
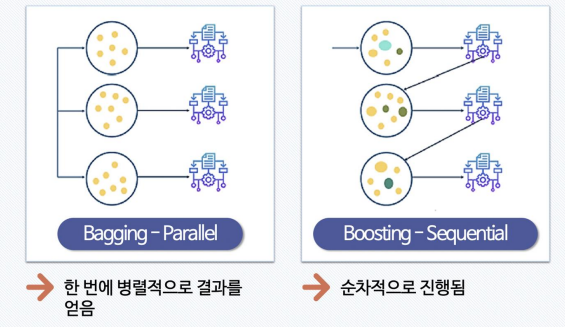
-> 앙상블은 전통적으로 Voting, Bagging, Boosting, 스태깅 등으로 나눔
-> 보팅과 배깅은 여러개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
-> 보팅과 배깅의 차이점은 보팅은 각각 다른 분류기, 배깅은 같은 분류기를 사용
-> 대표적인 배깅 방식이 랜덤 포레스트 -
Boosting
-> 여러개의 분류기가 순차적으로 학습을 하면서, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해 다음 분류기가 가중치를 인가해서 학습을 이어 진행하는 방식
-> 예측 성능이 뛰어나서 앙상블 학습을 주도함
-
부스팅 기법
-> GBM: AdaBoost 기법과 비슷하지만, 가중치 업데이트 시 경사하강법 사용
-> XGBoost: GBM에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택되어 빠른 속도와 효율을 가짐
-> LightGBM: XGBoost 보다 빠른 속도를 가짐 -
Bagging과 Boosting의 차이
-
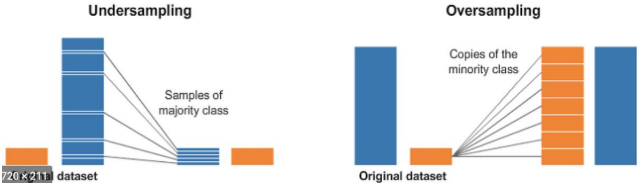
데이터의 불균형이 심할 때 두 클래스의 분포를 강제로 맞추기 위해 Undersampling이나 Oversampling 사용 가능
이 글은 제로베이스 강의 자료 일부를 발췌하여 작성되었습니다
