
Chapter 15 PCA
- 차원축소(dimensionality reduction)와 변수추출(feature extraction) 기법으로 널리 쓰이고 있는 주성분분석(Principal Component Analysis)
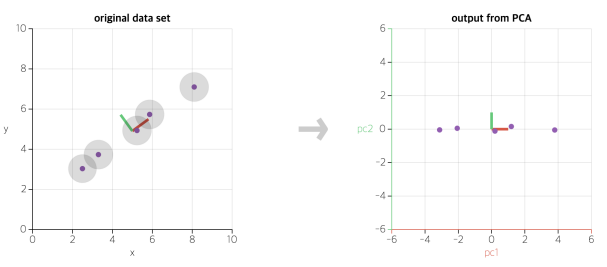
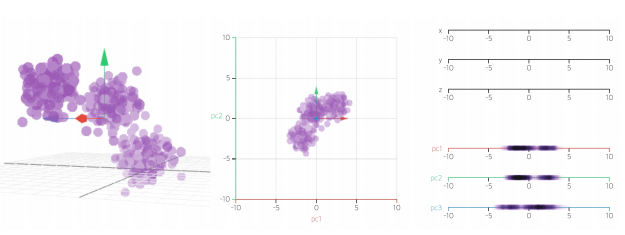
- PCA는 데이터의 분산(variance)을 최대한 보존하면서 서로 직교하는 새 기저(축)를 찾아, 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간으로 변환하는 기법
- 변수추출(Feature Extraction)은 기존 변수를 조합해 새로운 변수를 만드는 기법 (변수선택(Feature Selection)과 구분할 것)
- 데이터를 어떤 벡터에 정사영시켜 차원을 낮출 수 있음
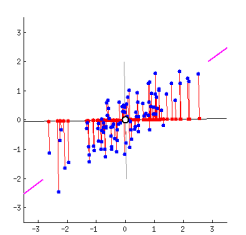

- 데이터를 새로운 축으로 표현하는 것
Chapter 16 PCA eigenface
- olivetti 데이터셋

-> 얼굴 인식용 데이터이지만, 특정 인물의 데이터(10장)만 활용하여 PCA 실습 진행
Chapter 17 Clustering
-
비지도 학습
-> 군집 Clustering : 비슷한 샘플을 모음
-> 이상치 탐지 Outier detection : 정상 데이터가 어떻게 보이는지 학습, 비정상 샘플을 감지
-> 밀도 추정 : 데이터셋의 확률 밀도 함수 Probability Density Function PDF를 추정. 이상치 탐지 등에 사용 -
K-Means
-> 군집화에서 가장 일반적인 알고리즘
-> 군집 중심(centroid)이라는 임의의 지점을 선택해서 해당 중심에 가장 가까운 포인트들을 선택하는 군집화
-> 일반적인 군집화에서 가장 많이 사용되는 기법
-> 거리 기반 알고리즘으로 속성의 개수가 매우 많을 경우 군집화의 정확도가 떨어짐 -
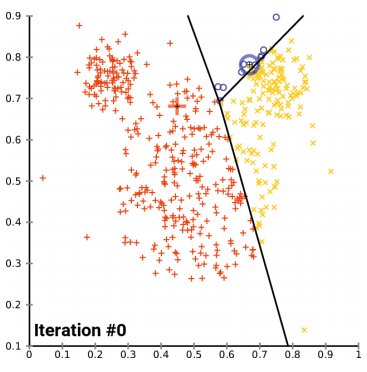
원리
-> 초기 중심점을 설정
-> 각 데이터는 가장 가까운 중심점에 소속 - 중심점에 할당된 평균값으로 중심점 이동
-> 각 데이터는 이동된 중심점 기준으로 가 장 가까운 중심점에 소속
-> 다시 중심점에 할당된 데이터들의 평균 값으로 중심점 이동
-> 데이터들의 중심점 소속 변경이 없으면 종료
-
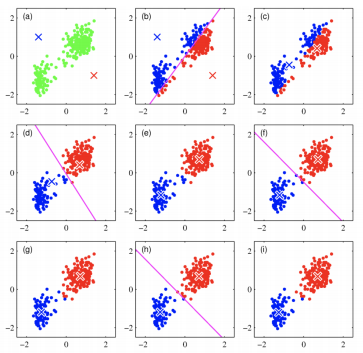
군집 결과의 평가
-> 분류기와 달리 평가 기준(정답)이 없음
-> 군집 결과 평가를 위해 실루엣 분석 활용 -
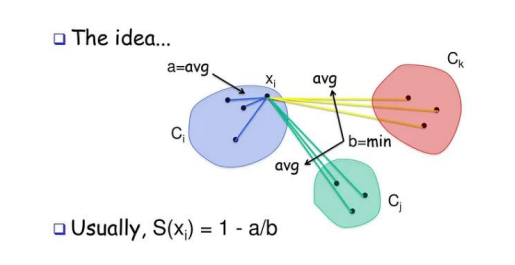
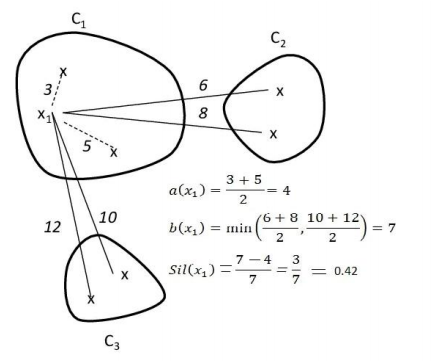
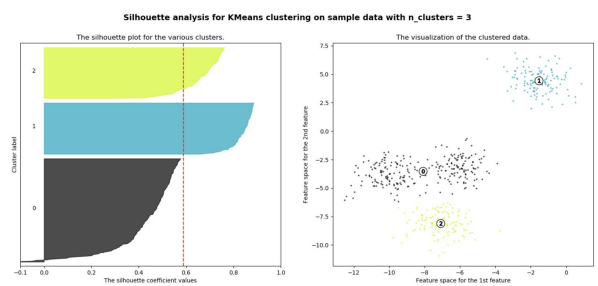
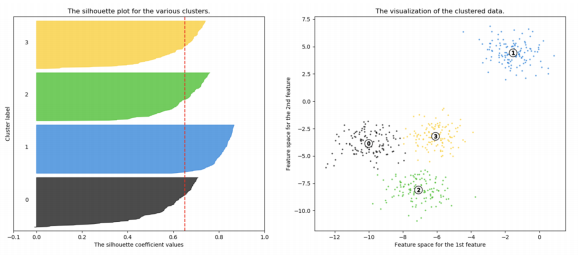
실루엣 분석
-> 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 나타냄
-> 다른 군집과는 거리가 떨어져 있고 동일 군집간의 데이터는 서로 가깝게 잘 뭉쳐 있는지 확인
-> 군집화가 잘 되어 있을 수록 개별 군집은 비슷한 정도의 여유공간을 가지고 있음
-> 실루엣 계수: 개별 데이터가 가지는 군집화 지표
-
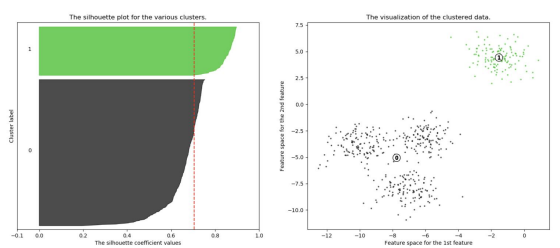
n=2인 경우
-
n=3인 경우
-
n=4인 경우
이 글은 제로베이스 강의 자료 일부를 발췌하여 작성되었습니다
