
Chapter1 기초통계_기초과정
1) Introduce
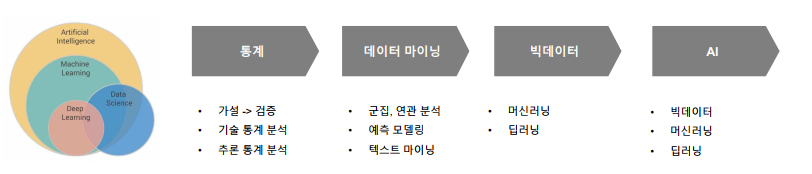
- 통계학(statistics): 산술적 방법을 기초로 하여, 주로 다양한 데이터를 관찰하고 정리, 분석하는 방법을 연구하는 수학의 한 분야
- 기술통계학(descriptive statistics): 데이터를 수집하고 수집된 데이터를 쉽게 이해하고 설명할 수 있도록 정리 요약 설명하는 방법론
- 추론통계학(inferential statistics): 모집단으로 부터 추출한 표본 데이터를 분석하여 모집단의 여러가지 특성을 추측하는 방법론

2) 데이터의 이해
1. 데이터와 그래프
-
변수(Variable): 어떤 정해지지 않은 임의의 값을 표현하기 위해 사용된 '기호', 통계학에서는 조사 목적에 따라 관측된 자료값을 변수라고 함, 해당 변수에 대하여 관측된 값들이 바료 자료(Data)
-
질적 자료: 관측된 데이터가 성별, 주소지, 업종 드오가 같이 몇 개의 범주로 구분하여 표현할 수 있는 데이터를 의미
-
양적 자료: 관측된 데이터가 숫자의 형태로 숫자의 크기가 의미를 가짐, 숫자를 표현할 때 이산형, 연속형 데이터로 구분

-
EDA(Exploaratory Data Analysis): 데이터를 탐색하는 분석방법으로 도표, 그래프, 요약 통계 등을 사용하여 데이터를 체계적으로 분석하는 하나의 방법
-
EDA의 목적
1) 데이터 분석 프로젝트 초기에 가설 수립
2) 데이터 분석 프로젝트 초기에 적절한 모델 및 기법 선정
3) 변수 간 트렌드, 패턴, 관계 등을 찾고 통계적 추론을 기반으로 가정을 평가
4) 분석 데이터에 적절한가 평가, 추가 수집, 이상치 발견 등에 활용 -
데이터 시각화(Data visualization): 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달하는 과정

2. 데이터의 기초 통계량
-
기초 통계량: 통계량은 표본으로 산출한 값으로, 기술 통계량이라고도 표현, 통계량을 통해 데이터가 갖는 특성을 이해할 수 있음
-
중심 경향치: 대표값을 중심경향치라고 함, 대표적으로 평균을 사용하며, 중앙값, 최빈값, 절사 평균 등이 있음
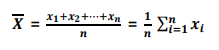
-
중앙값(median): 관측치를 크기 순으로 나열 했을 때, 가운데 위치하는 값, 관측치가 홀수일 경우 중앙, 짝수 일 경우 가운데 두개 값의 산술평균 값, 이상치가 포함된 데이터에서 주로 사용
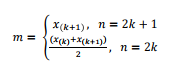
-
최빈값(mode): 관측치 중 가장 많이 관측되는 값으로 명목형 데이터에서 많이 사용
-
산포도: 데이터가 어떻게 흩어져 있는지 확인하기 위해서는 중심경향치와 함께 산포에 대한 측도를 같이 고려해야 함
-
범위(Range): 데이터의 최대값과 최소값의 차이
-
사분위수(quartile): 전체 데이터를 오름차순으로 정렬하여 4등분을 하였을 때, 첫번째를 제1사분위수, 두번째를 제2사분위수, 세번째를 제3사분위수라고 함
-
백분위수(percentile): 전체 데이터를 오름차순으로 정렬하여 주어진 비율에 의해 등분한 값을 말하며, 제p백분위수는 p%에 위치한 자료 값을 말함
-
분산(variance): 데이터의 분포가 얼마나 흩어져 있는지를 알 수 있는 측도
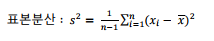
-
표준 편차(standard deviation): 분산의 제곱근

-
분산: 크기가 N인 모집단의 평균을 라고 할 때 모평균과 모분산은 다음과 같음
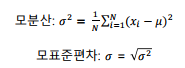
-
변동계수(CV:Coefficient of Variation): 평균이 다른 두개 이상의 그룹의 표준편차를 비교할 때 사용
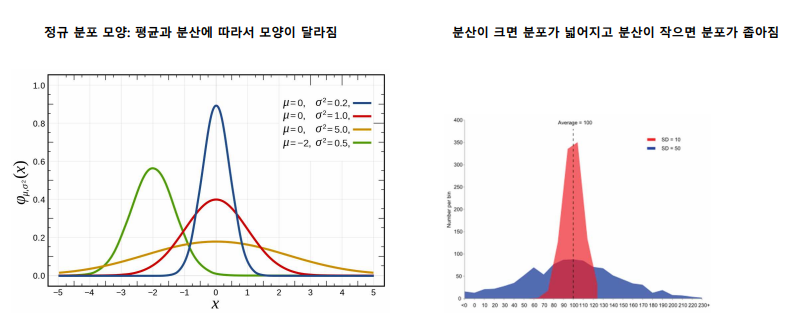
-
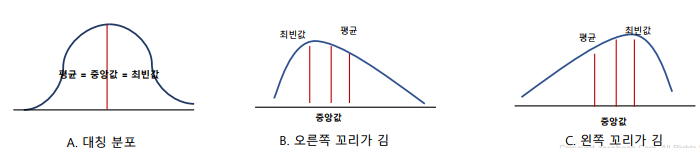
왜도(skew): 자료의 분포가 얼마나 비대칭적인지 표현하는 지표
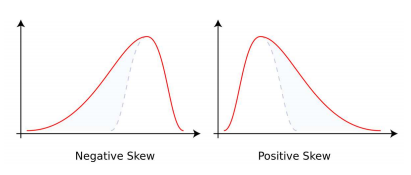
-
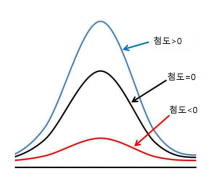
첨도(kurtosis): 활귤분포의 꼬리가 두꺼운 정도를 나타내는 척도
3) 확률이론
1. 확률
-
확률(probability): 모든 경우의 수에 대한 특정 사건이 발생하는 비율
-
확률의 고전적 정의: 어떤 사건의 발생 확률은 그것이 일어날 수 있는 경우의 수 대 가능한 모든 경우의 수의 비
-
표본 공간(Sample space): 어떤 실험에서 나올 수 있는 모든 가능한 결과들의 집합
-
사건 A가 일어날 확률을 P(A)라고 하고 표본공간(S)가 유한집합일때 표본 공간의 모든 원소들이 일어날 확률이 같으면

-
확률의 성질

1) 확률의 덧셈법칙:
2) A와 B가 배반 사건이면,
3) A의 여사건이 ( A^c ) 이면,
-
! (Factorial): n개를 일렬로 늘어 놓은 경우의 수를 n!로 표현하며,
-
순열(Permutation): 순서를 고려하여 n개 중 r개를 뽑아서 배열하는 경우의 수
-
조합(Combination): 순서를 고려하지 않고 n개 중 r개를 뽑아서 배열하는 경우의 수
-
조건부 확률(conditional probability): 어떤 사건 A가 발생한 상황에서 또 하나의 사건 B가 발생할 확률
-
확률의 곱셈법칙
-> 사건 A와 B가 독립일 경우,
-
베이즈 정리(Bayes' Theorem): 표본 공간 S에서 서로 배반인 사건에 의하여 분할 되어 있을 때 임의의 사건 A에 대하여 다음이 성립
2. 확률 변수
-
확률 변수(random variable): 표본공간에서 각 사건에 실수를 대응시키는 함수
-
확률 변수의 값은 하나의 사건에 대하여 하나의 값을 가지며, 실험의 결과에 의하여 변함
-
일반적으로 확률 변수는 대문자로 표현하며, 확률변수의 특정값을 소문자로 표혐
-
이산 확률 변수(discrete random variable): 셀 수 있는 값들로 구성되거나 일정 범위로 나타나는 경우
-
연속 확률 변수(continuous random variable): 연속형 또는 무한대와 같이 셀 수 없는 경우
-
확률 변수의 평균: 기대값
-
확률 변수의 분산
-
기대값의 성질: a,b가 상수이고, X, Y를 임의의 확률 변수라고 할 때
(a)
(b)
(c)
(d)
(e) -
분산의 성질: a,b가 상수이고, X, Y를 임의의 확률 변수라고 할 때
(a)
(b)
(c)
(d)
(e)
(f) -
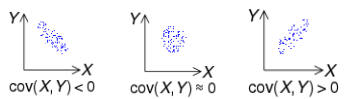
공분산: 2개의 확률변수의 선형 관계를 나타내는 값
4) 확률 분포
1. 이산형 확률 분포
-
확률 분포(probability distribution): 확률 변수 X가 취할 수 있는 모든 값과 그 값을 나타날 확률을 표현한 함수
-
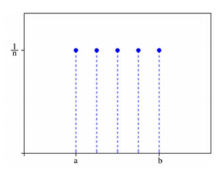
이산형 균등 분포(discrete uniform distribution): 확률 변수 X가 유한개이고, 모든 확률 변수에 대하여 균일한 확률을 갖는 분포
-
기대값:
-
분산:
-
-
베르누이 시행(Bernoulli trial): 각 시행의 결과과 성공, 실패 두가지 결과만 존재하는 시행
-
베르누이 분포(Bernoulli distribution): 성공이 '1', 실패가 '0'의 값을 갖을 때 확률 변수의 분포
-
기대값(평균):
-
분산:
-
이항분포(Binomial distribution): 연속적인 베르누이 시행을 거쳐 나타나는 확률 분포
-
서로 독립인 베르누이 시행을 n번 반복해서 실행 했을 때, 성공한 횟수 X의 확률 분포
-
이항분포의 기대값은 np, 분산은 np(1-np)
-
포아송 분포(Poisson distribution): 어느 희귀한 사건이 어떤 일정한 시간대에 특정한 사건이 발생할 확률 분포
-
포아송 분포의 조건
1) 어떤 단위구간 동안 이를 더 짧은 작은 단위의 구간으로 나눌 수 있고, 이러한 더 짧은 단위 구간 중에 어떤 사건이 발생할 확률은 전체 척도 중에서 항상 일정
2) 두 개 이상의 사건이 동시에 발생할 확률은 0에 가까움
3) 어떤 단위구간의 사건의 발생은 다른 단위구간의 발생으로부터 독립적임
4) 특정 구간에서의 사건 발생확률은 그 구간의 크기에 비례함
5) 포아송 분포 확률 변수의 기댓값과 분산은 모두 임
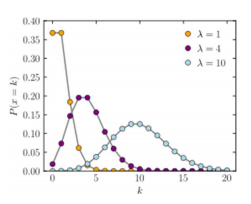
-
이항 분포의 포아송 근사: 확률 변수 X가 X ~ B(n,p)이고, n이 충분히 크고, p가 아주 작을 때, X의 분포는 평균이 인 포아송 분포로 근사 시킬 수 있음
-
기하분포(geometric distribution): 어떤 실험에서 처음 성공이 발생하기까지 시도한 횟수 X의 분포, 이때 각 시도는 베르누이 시행을 따름
- 음이항분포(negative binomial distribution): 어떤 실험에서 성공확률이 p일때, r번의 실패가 나올 때까지 발생한 성공 횟수 X의 확률 분포
이 글은 제로베이스 강의 자료 일부를 발췌하여 작성되었습니다
