
Chapter1 기초통계_기초과정
4) 확률분포
2. 연속형 확률분포
- 확률밀도함수(probability density function): 연속형 확률 변수 X에 대해서 함수 f(x)가 아래의 조건을 만족하면 확률밀도함수라고 함
-
모든 ( X )에 대해서
-
-
- 확률 밀도 함수의 성질
- 확률밀도함수의 평균과 분산
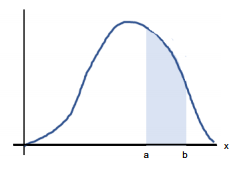
- 누적분포함수(cumulative density function): 확률밀도함수를 적분
- 누적분포함수의 성질
-
-
만약
-
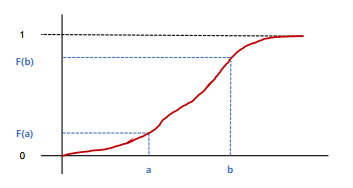
- 균일분포(uniform distribution)

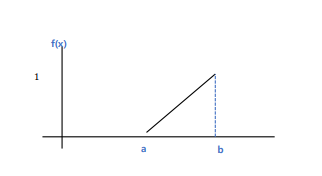
- 정규분포(normal distribution, 가우스 분포)
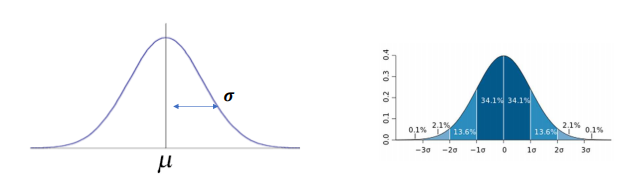
- 정규분포의 평균과 분산
평균:
분산: ,
표준편차:
- 표준 정규 분포(standard normal distribution)
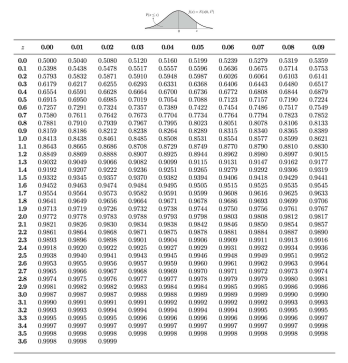
- 정규분포의 성질
-
일 때, 임의의 상수 ( a, b )에 대해서
-
일 때, 표준화된 확률 변수 ( z = \frac{X - \mu}{\sigma} )는
-
, 이고, X와 Y가 독립일 때
- 이항분포의 정규 근사: 일 때, 확률 변수 는 이 sufficiently 크면 근사적으로 정규 분포 를 따른다.
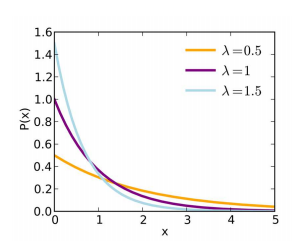
- 지수분포(exponential distribution): 단위 시간당 발생할 확률 인 어떤 사건의 횟수가 포아송 분포를 따른다면, 어떤 사건이 처음 발생할 때까지 걸린 시간 확률 변수 X는 지수 분포임
-지수 분포의 PDF:
-
지수 분포의 CDF:
-
지수분포의 무기억성(Memoryless Property): 어떤 시점부터 소요되는 시간은 과거 시간에 영향을 받지 않음
-
지수분포와 포아송 분포의 관계
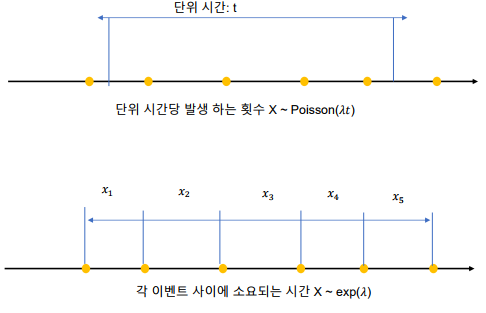
-
확률분포의 관계도

5) 모집단과 표본 분포
1. 모집단과 표본
-
모집단(Population), 표본(Sample)
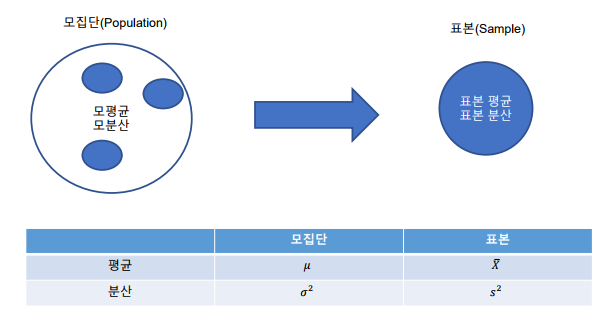
-
표본추출(Sampling): 모집단으로부터 표본을 추출 하는 것을 Sampling이라고 하며, 표본으로부터 그 특성을 찾아내고 모집단의 특성을 추론하고자 함
-
복원추출(Sampling with replacement): 모집단에서 데이터를 추출 할 때 하나를 추출하고 다시 넣고 추출하는 방법으로 동일한 표본이 추출 될 수 있음
-
비복원추출(Samplign without replacement): 모집단에서 데이터를 추출 할 때 하나를 추출하고 다시 넣지 않고 추출하는 방법
-
Random Sampling: 모딥단에서 데이터를 추출할 때 주의할 점은 편향되지 않아야 함, 각 개체가 모두 동일한 확률로 추출하는 방법
-
불균형 데이터(Imbalanced Data)의 문제: 데이터가 불균형 데이터 일 경우 문제가 생김
-
Sampling 기법: 관심 대상의 비율이 낮은 경우
-> Over Sampling: 적은 class의 수를 많은 class의 비율만큼 증가, 과도적합 문제 발생 가능
-> Under Sampling: 많은 class의 수를 적은 class의 비율만큼 감소, 데이터 편향 문제나, 모형의 성능이 떨어질 수 있음

2. 표본분포
- 통계량(Statistic): 표본에 기초하여 계산되는 수치 함수
-
표본분포(Sampling distribution): 통계량들이 이루는 분포
-
표본 평균(Sample mean)
-
표본 평균의 기대값
-
표본 평균의 분산
-
중심극한 정리(central limit theorem)
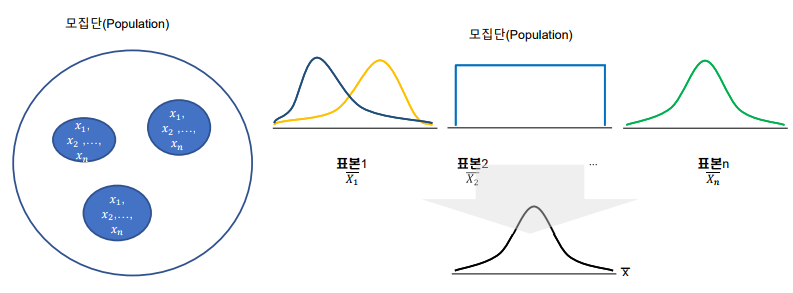
-
카이제곱 분포(Chi-square distribution): 확률 변수 이 표준 정규 분포를 따른다면, 확률 변수 는 자유도 인 카이제곱 분포를 따름
-> 카이제곱 분포는 범주형 자료 분석에서 활용 -
확률 변수 , 즉 가 자유도 인 카이제곱 분포를 따를 때:
확률 밀도 함수 (PDF):
기대값과 분산:
-
자유도: 표본수-제약조건의 수 또는 표본수-추정해야 하는 모수의 수를 의미, 일반적으로 n-1을 사용
-
T분포(T-distribution): 을 따르고, 일 때,
-
만약 확률 변수 가 정규분포를 따르고 모표준편차 를 안다면,
- 만약 모표준편차 를 모른다면, 를 대신해서 표본표준편차 를 이용하여 확률변수 를 정의함
-
F분포(F distribution): 이면,
-
두 개의 독립적인 모집단()으로부터 각각 표본을 추출했을 때
,
F 분포는 아래와 같음:
-> 서로 독립인 두 정규모집단의 분산 또는 표준편차들의 비율에 대한 통계적 추론, 분산분석 등에 활용
이 글은 제로베이스 강의 자료 일부를 발췌하여 작성되었습니다
