범주형 자료(categorical data): 관측된 결과를 어떤 속성에 따라 몇 개의 범주로 분류 시켜 도수로 주어진 데이터
범주형 자료 분석
-> 범주형 자료에 대한 통계적 추론 방법
-> 범주형 자료 분석은 카이제곱 검정으로 추론
t-test와 카이제곱 검정의 차이
-> t-test: 연속성 변수의 차이에 대한 검정
-> 카이제곱 검정: 명목형 변수에 대한 검정
적합도 검정(goodness of fit test): 관측된 값들이 추론하는 분포를 따르고 있는지 검정, 한개의 요인을 대상으로 검정
독립성 검정(test of independence): 관측된 값을 두 개의 요인으로 분할하고 각 요인이 다른 요인에 영향을 끼치는지를 검정
동질성 검정(test of homogeneity): 서로 다른 세개 이상의 모집단으로 관측된 값들이 범주내에서 동일한 비율을 나타내는지 검정
2. 독립성 검정
독립성 검정(test of independence): 관측된 값을 두개의 요인으로 분할하고 각 요인이 다른 요인에 영향을 끼치는지를 검정
지지하는 정당과 사는 지역의 관련이 있는지 확인
3. 동질성 검정
서로 다른 모집단에서 관측된 값들이 범주내에서 동일한 비율을 나타내는지 검정
시간의 흐름에 따라 어떤 산업의 거래액이 증가하고 있는지?
어떤 업종의 비중이 떨이지는지?
9) 상관분석 & 회귀분석
1. 상관분석
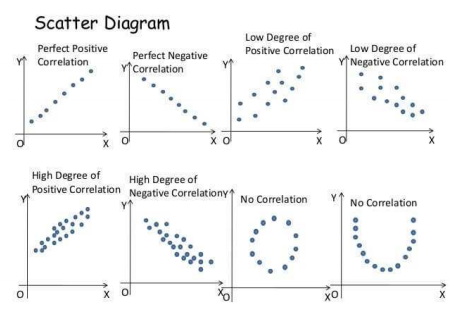
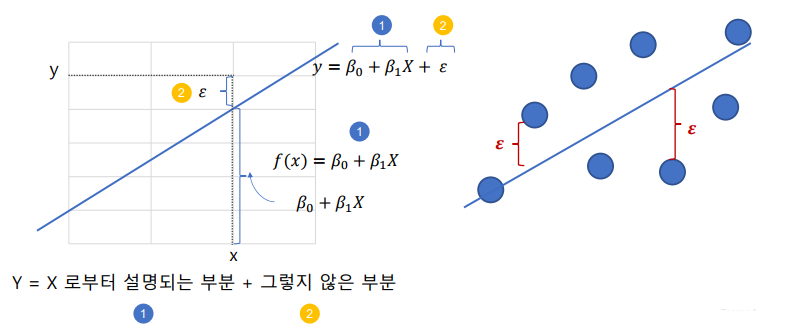
상관관계(correlation coefficient): 두 변수간의 함수 관계가 선형적인 관계가 있는지 파악할 수 있는 측도
ρ=Corr(X,Y)=Var(X)Var(Y)Cov(X,Y)
1) 상관계수 −1≤ρ≤1
2) 상관계수가 1에 가까울 수록 양의 상관관계가 강함
3) 상관계수가 -1에 가까울 수록 음의 상관관계가 강함
4) 상관계수가 0에 가까울 수록 두 변수 간의 상관관계가 존재하지 않음
5) 상관계수가 0이라는 것은 두 변수 간에 선형 관계가 존재하지 않는다는 것
가설검정:
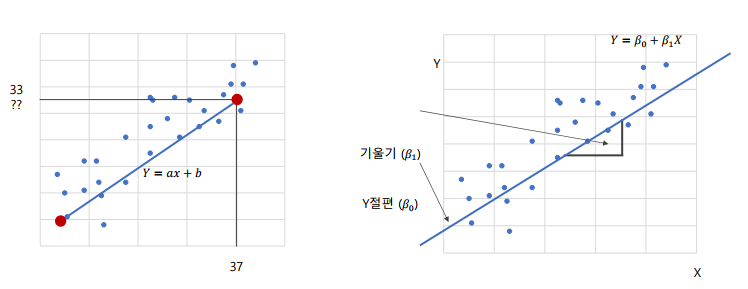
1) 가설 수립 H0:β1=0vsH1:β1=0
2) 검정통계량: t=MSE/Sxxβ1
3) 기각기준: ∣t∣≥t2α(n−2)이면 H0 기각(reject)할 수 있음
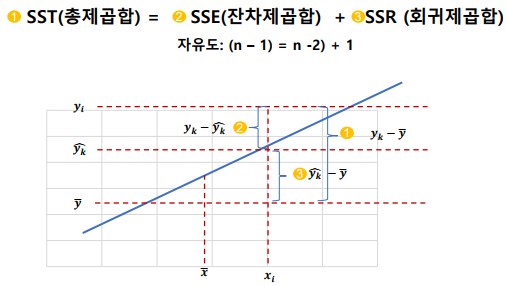
결정 계수(Coefficient of determination: R2): 추정된 회귀식이 얼마나 전체 데이터에 대해서 적합한지를 수치로 제공하는 값
R2=SSTSSR=1−SSTSSE
-> 0과 1사이에 있는 값으로 1에 가까울 수록 추정된 모형이 설명력이 높음
-> 0이라는 건 추정된 모형이 설명력이 전혀 없다고 할 수 있음
수정 결정 계수(Adjust R2)
-> R2은 유의하지 않은 변수가 추가되어도 항상 증가됨
-> Adjust R2은 특정 계수를 곱해 줌으로서 R2가 항상 증가하지 않도록 함
-> 보통 모형 간의 성능을 비교할 때 사용함
Radj2=1−[n−(p+1)n−1]SSTSSE
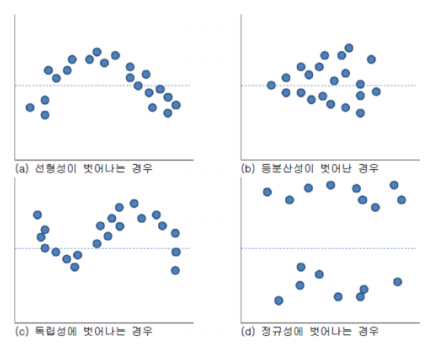
잔차 분석
a) 선형성을 벗어나는 경우
-> 종속변수와 독립변수가 선형 관계가 아님
b) 등분산성이 벗어난 경우
-> 일반적인 회귀모형 사용 불가능
-> 등분산성 가정 위배
c) 독립성이 벗어나는 경우
-> 시계열 데이터 또는 관측 순서에 영향을 받는 데이터에서는 독립성을 담보할 수 없음 (Durbin-Watson test 실행)
d) 정규성을 벗어나는 경우
-> Normal Q-Q plot으로도 확인
-> 잔차가 -2 ~ +2 사이에 분포해야 함
-> 벗어나는 자료가 많으면 독립성 가정 위배
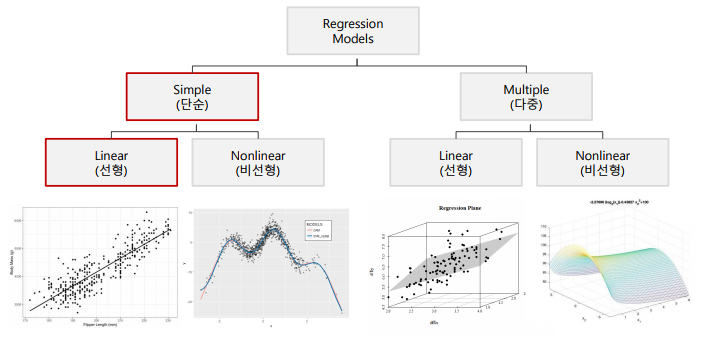
3. 다중 회귀분석
다중 회귀분석(multiple regression analysis): 2개 이상의 독립변수로 종속 변수를 예측하는 회귀 모형을 만드는 방법
로지스틱 회귀분석(Logisitic regression analysis): 반응 변수가 범주형인 경우 사용하는 모형
다항 회귀분석(polynomial regression): 독립 변수가 k개이고 반응 변수와 독립변수가 1차 함수 이상인 회귀 분석
변수선택법
전진선택법(forward selection): 독립변수를 1개부터 시작하여 가장 유의한 변수들부터 하나씩 추가하면서 모형의 유의성을 판단하는 방법
후진제거법(backward selection): 모든 독립변수를 넣고 모형을 생성한 후, 하나씩 제거하면서 판단하는 방법
단계 선택법(stepwise selection): 전진선택법, 후진제거법 두가지 방법을 모두 사용하여 변수를 넣고 빼면서 판단하는 방법
더미 변수(dummy variable): 값이 0 또는 1로 이루어진 변수
-> 범주형 변수를 사용하기 위해서 더미변수가 필요
다중공선성(Multicollinearity)
-> 상관관계가 높은 독립변수들이 동시에 사용될 때 문제가 발생
-> 결정계수 값은 높아 회귀식의 설명력은 높지만 독립변수의 P-value가 커서 개별 인자들이 유의하지 않은 경우 의심할 수 있음
-> 일반적으로 분상팽창요인(VIF)이 10 이상이면 다중 공선성이 존재함
-> VIF=1−Rk21, k번째 독립변수를 종속변수로 나머지를 독립변수로 하는 회귀모형의 결정 계수
해결방안
1) 다중공선성이 존재하지만 유의한 변수인 경우 목적에 따라 사용할 수 있음
2) 변수 제거
3) 주성분분석으로 변수를 재조합