Chapter1 기초통계_기초과정
6) 추정
1. 추정
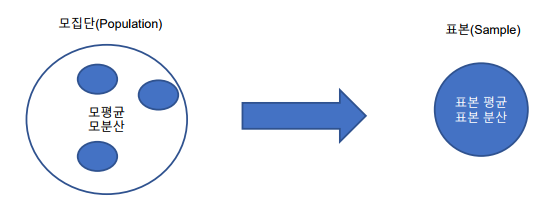
추정(estimation): 모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것
추정량(estimator): 표본 평균으로 모평균을 추정할 때 표본 평균을 모평균에 대한 추정량이라고 함
점추정(point estimation): 모수를 하나의 특정값으로 추정 하는 방법
구간추정(interval estimation): 모수가 포함될 수 있는 구간을 추정하는 방법
점추정의 성질
일치성(Consisttency): 표본의 크기가 모집단의 크기에 근접해야 함, 표본의 크기가 클수록 추정량의 오차가 작아짐
불편성(unbiased estimator): 추정량이 모수와 같아야 함
유효성(efficiency): 추정량의 분산이 최소값이어야 함
평균오차제곰(MSE): 평균오차제곱이 최소값이어야 함
구간추정: 모수가 포함될 수 있는 구간을 추정하는 방법
신뢰구간(confidence level): 추정값이 존재하는 구간에 모수가 포함될 확률
신뢰구간은 신뢰 하한, 신뢰 상한으로 표시
P ( L ( θ ^ ) ≤ θ ≤ U ( θ ^ ) ) = 1 − α P\left( L(\hat{\theta}) \leq \theta \leq U(\hat{\theta}) \right) = 1 - \alpha P ( L ( θ ^ ) ≤ θ ≤ U ( θ ^ ) ) = 1 − α
표본의 크기 결정
2. 모비율 추정
모비율의 점추정: 비율에 대한 추정으로 우리가 원하는 속성(class)에 속하면 1 아니면 0일때, 1의 속성을 갖는 것의 개수를 X라고 하면 X ~ B(n,p)임, 이때 모비율의 점추정량을 표본 비율이라고 함E ( p ^ ) = E ( X n ) = n p n = p , E(\hat{p}) = E\left(\frac{X}{n}\right) = \frac{np}{n} = p, E ( p ^ ) = E ( n X ) = n n p = p ,
V a r ( p ^ ) = V a r ( X n ) = n p ( 1 − p ) n 2 = p ( 1 − p ) n . Var(\hat{p}) = Var\left(\frac{X}{n}\right) = \frac{np(1-p)}{n^2} = \frac{p(1-p)}{n}. V a r ( p ^ ) = V a r ( n X ) = n 2 n p ( 1 − p ) = n p ( 1 − p ) .
모비율의 구간 추정
모비율 구간 추정에서 정규분포의 근사가 가능한 대표본은 보통 np > 5, n(1-p) >5를 동시에 만족 해야 함P ( − z α 2 ≤ Z ≤ z α 2 ) = 1 − α ⟹ P ( − z α 2 ≤ p ^ − p p ( 1 − p ) n ≤ z α 2 ) = P ( − z α 2 ⋅ p ( 1 − p ) n ≤ p ^ − p ≤ z α 2 ⋅ p ( 1 − p ) n ) . P(-z_{\frac{\alpha}{2}} \leq Z \leq z_{\frac{\alpha}{2}}) = 1 - \alpha \implies P\left(-z_{\frac{\alpha}{2}} \leq \frac{\hat{p} - p}{\sqrt{\frac{p(1-p)}{n}}} \leq z_{\frac{\alpha}{2}}\right) = P\left(-z_{\frac{\alpha}{2}} \cdot \sqrt{\frac{p(1-p)}{n}} \leq \hat{p} - p \leq z_{\frac{\alpha}{2}} \cdot \sqrt{\frac{p(1-p)}{n}}\right). P ( − z 2 α ≤ Z ≤ z 2 α ) = 1 − α ⟹ P ⎝ ⎜ ⎛ − z 2 α ≤ n p ( 1 − p ) p ^ − p ≤ z 2 α ⎠ ⎟ ⎞ = P ( − z 2 α ⋅ n p ( 1 − p ) ≤ p ^ − p ≤ z 2 α ⋅ n p ( 1 − p ) ) .
⟹ P ( p ^ − z α 2 ⋅ p ( 1 − p ) n ≤ p ≤ p ^ + z α 2 ⋅ p ( 1 − p ) n ) = 1 − α . \implies P\left(\hat{p} - z_{\frac{\alpha}{2}} \cdot \sqrt{\frac{p(1-p)}{n}} \leq p \leq \hat{p} + z_{\frac{\alpha}{2}} \cdot \sqrt{\frac{p(1-p)}{n}}\right) = 1 - \alpha. ⟹ P ( p ^ − z 2 α ⋅ n p ( 1 − p ) ≤ p ≤ p ^ + z 2 α ⋅ n p ( 1 − p ) ) = 1 − α .
모평균 차이의 추정(점추정)E ( X ‾ 1 − X ‾ 2 ) = E ( X ‾ 1 ) − E ( X ‾ 2 ) = μ 1 − μ 2 E(\overline{X}_1 - \overline{X}_2) = E(\overline{X}_1) - E(\overline{X}_2) = \mu_1 - \mu_2 E ( X 1 − X 2 ) = E ( X 1 ) − E ( X 2 ) = μ 1 − μ 2
V a r ( X ‾ 1 − X ‾ 2 ) = V a r ( X ‾ 1 ) − V a r ( X ‾ 2 ) = σ 1 2 n 1 + σ 2 2 n 2 Var(\overline{X}_1 - \overline{X}_2) = Var(\overline{X}_1) - Var(\overline{X}_2) = \frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2} V a r ( X 1 − X 2 ) = V a r ( X 1 ) − V a r ( X 2 ) = n 1 σ 1 2 + n 2 σ 2 2
모평균 차이의 추정(구간추정: 대표본)Z = ( X ‾ 1 − X ‾ 2 ) − ( μ 1 − μ 2 ) σ 1 2 / n 1 + σ 2 2 / n 2 ∼ N ( 0 , 1 ) ⇒ 1 − α = P ( − z α 2 < Z < z α 2 ) = P ( − z α 2 < ( X ‾ 1 − X ‾ 2 ) − ( μ 1 − μ 2 ) σ 1 2 / n 1 + σ 2 2 / n 2 < z α 2 ) Z = \frac{(\overline{X}_1-\overline{X}_2)-(\mu_1-\mu_2)}{\sqrt{\sigma_1^2/n_1+\sigma_2^2/n_2}} \sim N(0,1) \Rightarrow 1 - \alpha = P(-z_{\frac{\alpha}{2}} < Z < z_{\frac{\alpha}{2}}) = P\left(-z_{\frac{\alpha}{2}} < \frac{(\overline{X}_1-\overline{X}_2)-(\mu_1-\mu_2)}{\sqrt{\sigma_1^2/n_1+\sigma_2^2/n_2}} < z_{\frac{\alpha}{2}}\right) Z = σ 1 2 / n 1 + σ 2 2 / n 2 ( X 1 − X 2 ) − ( μ 1 − μ 2 ) ∼ N ( 0 , 1 ) ⇒ 1 − α = P ( − z 2 α < Z < z 2 α ) = P ( − z 2 α < σ 1 2 / n 1 + σ 2 2 / n 2 ( X 1 − X 2 ) − ( μ 1 − μ 2 ) < z 2 α )
P ( ( X ‾ 1 − X ‾ 2 ) − z α 2 ⋅ σ 1 2 / n 1 + σ 2 2 / n 2 < μ 1 − μ 2 < ( X ‾ 1 − X ‾ 2 ) + z α 2 ⋅ σ 1 2 / n 1 + σ 2 2 / n 2 ) P((\overline{X}_1 - \overline{X}_2) - z_{\frac{\alpha}{2}} \cdot \sqrt{\sigma_1^2/n_1 + \sigma_2^2/n_2} < \mu_1 - \mu_2 < (\overline{X}_1 - \overline{X}_2) + z_{\frac{\alpha}{2}} \cdot \sqrt{\sigma_1^2/n_1 + \sigma_2^2/n_2}) P ( ( X 1 − X 2 ) − z 2 α ⋅ σ 1 2 / n 1 + σ 2 2 / n 2 < μ 1 − μ 2 < ( X 1 − X 2 ) + z 2 α ⋅ σ 1 2 / n 1 + σ 2 2 / n 2 )
모평균 차이의 추정(구간추정: 소표본, 모분산을 모르는 경우)
합동 분산 추정량(pooled variance estimator)s p 2 = ( n 1 − 1 ) s 1 2 + ( n 2 − 1 ) s 2 2 n 1 + n 2 − 2 s_p^2 = \frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1 + n_2 - 2} s p 2 = n 1 + n 2 − 2 ( n 1 − 1 ) s 1 2 + ( n 2 − 1 ) s 2 2
T = ( X ‾ 1 − X ‾ 2 ) − ( μ 1 − μ 2 ) s p 1 / n 1 + 1 / n 2 ∼ t ( n 1 + n 2 − 2 ) T = \frac{(\overline{X}_1 - \overline{X}_2) - (\mu_1 - \mu_2)}{s_p\sqrt{1/n_1 + 1/n_2}} \sim t(n_1 + n_2 - 2) T = s p 1 / n 1 + 1 / n 2 ( X 1 − X 2 ) − ( μ 1 − μ 2 ) ∼ t ( n 1 + n 2 − 2 ) 1 − α = P ( − t α / 2 ( n 1 + n 2 − 2 ) < T < t α / 2 ( n 1 + n 2 − 2 ) ) 1 - \alpha = P(-t_{\alpha/2}(n_1 + n_2 - 2) < T < t_{\alpha/2}(n_1 + n_2 - 2)) 1 − α = P ( − t α / 2 ( n 1 + n 2 − 2 ) < T < t α / 2 ( n 1 + n 2 − 2 ) ) = P ( − t α / 2 ( n 1 + n 2 − 2 ) < ( X ‾ 1 − X ‾ 2 ) − ( μ 1 − μ 2 ) s p 1 / n 1 + 1 / n 2 < t α / 2 ( n 1 + n 2 − 2 ) ) = P\left(-t_{\alpha/2}(n_1 + n_2 - 2) < \frac{(\overline{X}_1 - \overline{X}_2) - (\mu_1 - \mu_2)}{s_p\sqrt{1/n_1 + 1/n_2}} < t_{\alpha/2}(n_1 + n_2 - 2)\right) = P ( − t α / 2 ( n 1 + n 2 − 2 ) < s p 1 / n 1 + 1 / n 2 ( X 1 − X 2 ) − ( μ 1 − μ 2 ) < t α / 2 ( n 1 + n 2 − 2 ) ) = P ( ( X ‾ 1 − X ‾ 2 ) − t α / 2 ( n 1 + n 2 − 2 ) ⋅ s p 1 / n 1 + 1 / n 2 < μ 1 − μ 2 < ( X ‾ 1 − X ‾ 2 ) + t α / 2 ( n 1 + n 2 − 2 ) ⋅ s p 1 / n 1 + 1 / n 2 ) = P((\overline{X}_1 - \overline{X}_2) - t_{\alpha/2}(n_1 + n_2 - 2) \cdot s_p\sqrt{1/n_1 + 1/n_2} < \mu_1 - \mu_2 < (\overline{X}_1 - \overline{X}_2) + t_{\alpha/2}(n_1 + n_2 - 2) \cdot s_p\sqrt{1/n_1 + 1/n_2}) = P ( ( X 1 − X 2 ) − t α / 2 ( n 1 + n 2 − 2 ) ⋅ s p 1 / n 1 + 1 / n 2 < μ 1 − μ 2 < ( X 1 − X 2 ) + t α / 2 ( n 1 + n 2 − 2 ) ⋅ s p 1 / n 1 + 1 / n 2 )
모비율 차이의 추정(점추정)E ( p ^ 1 − p ^ 2 ) = E ( p ^ 1 ) − E ( p ^ 2 ) = p 1 − p 2 E(\hat{p}_1 - \hat{p}_2) = E(\hat{p}_1) - E(\hat{p}_2) = p_1 - p_2 E ( p ^ 1 − p ^ 2 ) = E ( p ^ 1 ) − E ( p ^ 2 ) = p 1 − p 2
V a r ( p ^ 1 − p ^ 2 ) = V a r ( p ^ 1 ) + V a r ( p ^ 2 ) = p 1 ( 1 − p 1 ) n 1 + p 2 ( 1 − p 2 ) n 2 Var(\hat{p}_1 - \hat{p}_2) = Var(\hat{p}_1) + Var(\hat{p}_2) = \frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2} V a r ( p ^ 1 − p ^ 2 ) = V a r ( p ^ 1 ) + V a r ( p ^ 2 ) = n 1 p 1 ( 1 − p 1 ) + n 2 p 2 ( 1 − p 2 )
모비율 차이의 추정(구간추정)( p ^ 1 − p ^ 2 ) − ( p 1 − p 2 ) p 1 ( 1 − p 1 ) n 1 + p 2 ( 1 − p 2 ) n 2 ∼ Z ( 0 , 1 ) ⟹ 1 − α = P ( − z α 2 < Z < z α 2 ) = P ( − z α 2 < ( p ^ 1 − p ^ 2 ) − ( p 1 − p 2 ) p 1 ( 1 − p 1 ) n 1 + p 2 ( 1 − p 2 ) n 2 < z α 2 ) \frac{(\hat{p}_1 - \hat{p}_2) - (p_1 - p_2)}{\sqrt{\frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2}}} \sim Z(0,1) \implies 1 - \alpha = P\left(-z_{\frac{\alpha}{2}} < Z < z_{\frac{\alpha}{2}}\right) = P\left(-z_{\frac{\alpha}{2}} < \frac{(\hat{p}_1 - \hat{p}_2) - (p_1 - p_2)}{\sqrt{\frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2}}} < z_{\frac{\alpha}{2}}\right) n 1 p 1 ( 1 − p 1 ) + n 2 p 2 ( 1 − p 2 ) ( p ^ 1 − p ^ 2 ) − ( p 1 − p 2 ) ∼ Z ( 0 , 1 ) ⟹ 1 − α = P ( − z 2 α < Z < z 2 α ) = P ⎝ ⎜ ⎛ − z 2 α < n 1 p 1 ( 1 − p 1 ) + n 2 p 2 ( 1 − p 2 ) ( p ^ 1 − p ^ 2 ) − ( p 1 − p 2 ) < z 2 α ⎠ ⎟ ⎞
= P ( ( p ^ 1 − p ^ 2 ) − z α 2 ⋅ p 1 ( 1 − p 1 ) n 1 + p 2 ( 1 − p 2 ) n 2 < p 1 − p 2 < ( p ^ 1 − p ^ 2 ) + z α 2 ⋅ p 1 ( 1 − p 1 ) n 1 + p 2 ( 1 − p 2 ) n 2 ) = P\left((\hat{p}_1 - \hat{p}_2) - z_{\frac{\alpha}{2}} \cdot \sqrt{\frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2}} < p_1 - p_2 < (\hat{p}_1 - \hat{p}_2) + z_{\frac{\alpha}{2}} \cdot \sqrt{\frac{p_1(1-p_1)}{n_1} + \frac{p_2(1-p_2)}{n_2}}\right) = P ⎝ ⎜ ⎛ ( p ^ 1 − p ^ 2 ) − z 2 α ⋅ n 1 p 1 ( 1 − p 1 ) + n 2 p 2 ( 1 − p 2 ) < p 1 − p 2 < ( p ^ 1 − p ^ 2 ) + z 2 α ⋅ n 1 p 1 ( 1 − p 1 ) + n 2 p 2 ( 1 − p 2 ) ⎠ ⎟ ⎞ Chapter2 기초통계_심화과정
7) 가설 검정
1. 가설검정과 유의수준 정의
가설 검정 = 가설(Hypothesis) + 검정(Testing)
가설(Hypothesis): 주어진 사실 또는 조사하려고 하는 사실에 대한 주장 또는 추축
통계학에서는 특히 모수를 추정 할 때 모수가 어떠하다는 증명을 하고 싶은 추축이나 주장을 가설이라고 함 할 때 모수가 어떠하다는 증명을 하고 싶은 추축이나 주장을 가설이라고 함
귀무가설(Null hypothesis: H 0 H_0 H 0
대립가설(Alternative hypothesis: H 1 H_1 H 1
제1종 오류: 귀무가설이 참이지만, 귀무가설을 기각하는 오류
제2종 오류: 귀무가설을 기각해야 하지만, 귀무가설을 채택하는 오류
검정통계량: 귀무가설이 참이라는 가정하에 얻은 통계량
P-value: 귀무가설이 참일 확률로 0~1 사이의 표준화된 지표
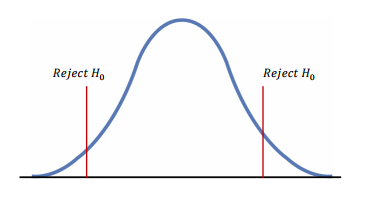
기각역(reject region): 귀무가설을 기각시키는 검정통계량의 관측값의 영역
가설 검정의 절차
양측검정(two-side test): 대립가설의 내용이 같지 않다 또는 차이가 있다 등의 양쪽 방향의 주장
단측검정(one-side test): 한쪽만 검증하는 방식으로 대립가설의 내용이 크다 또는 작다 처럼 한쪽 방향의 주장
2. 단일 표본에 대한 가설검정
가설:H 0 : μ = μ 0 H_0: \mu = \mu_0 H 0 : μ = μ 0 H 1 : μ ≠ μ 0 H_1: \mu \neq \mu_0 H 1 : μ = μ 0 H 0 : μ = μ 0 H_0: \mu = \mu_0 H 0 : μ = μ 0 H 1 : μ > μ 0 H_1: \mu > \mu_0 H 1 : μ > μ 0 H 0 : μ = μ 0 H_0: \mu = \mu_0 H 0 : μ = μ 0 H 1 : μ < μ 0 H_1: \mu < \mu_0 H 1 : μ < μ 0
유의수준:α = 0.05 \alpha = 0.05 α = 0 . 0 5 z = x ‾ − μ σ / n ∼ N ( 0 , 1 ) z = \frac{\overline{x} - \mu}{\sigma/\sqrt{n}} \sim N(0,1) z = σ / n x − μ ∼ N ( 0 , 1 )
검정통계량 관측값:z 0 = x ‾ − μ 0 σ / n z_0 = \frac{\overline{x} - \mu_0}{\sigma/\sqrt{n}} z 0 = σ / n x − μ 0
a) ∣ z 0 ∣ ≥ z α / 2 |z_0| \geq z_{\alpha/2} ∣ z 0 ∣ ≥ z α / 2 H 0 H_0 H 0 z 0 ≥ z α z_0 \geq z_{\alpha} z 0 ≥ z α H 0 H_0 H 0 z 0 ≤ − z α z_0 \leq -z_{\alpha} z 0 ≤ − z α H 0 H_0 H 0
모평균 가설검정 - 모분산을 모르는 경우(소표본)
가설:H 0 : μ = μ 0 H_0: \mu = \mu_0 H 0 : μ = μ 0 H 1 : μ ≠ μ 0 H_1: \mu \neq \mu_0 H 1 : μ = μ 0 H 0 : μ = μ 0 H_0: \mu = \mu_0 H 0 : μ = μ 0 H 1 : μ > μ 0 H_1: \mu > \mu_0 H 1 : μ > μ 0 H 0 : μ = μ 0 H_0: \mu = \mu_0 H 0 : μ = μ 0 H 1 : μ < μ 0 H_1: \mu < \mu_0 H 1 : μ < μ 0
유의수준:α = 0.05 \alpha = 0.05 α = 0 . 0 5 T = X ‾ − μ σ / n ∼ t ( n − 1 ) T = \frac{\overline{X} - \mu}{\sigma/\sqrt{n}} \sim t(n-1) T = σ / n X − μ ∼ t ( n − 1 )
검정통계량 관측값:t 0 = X ‾ − μ 0 σ / n t_0 = \frac{\overline{X} - \mu_0}{\sigma/\sqrt{n}} t 0 = σ / n X − μ 0
a) ∣ t 0 ∣ ≥ t α / 2 ( n − 1 ) |t_0| \geq t_{\alpha/2}(n-1) ∣ t 0 ∣ ≥ t α / 2 ( n − 1 ) H 0 H_0 H 0 t 0 ≥ t α ( n − 1 ) t_0 \geq t_{\alpha}(n-1) t 0 ≥ t α ( n − 1 ) H 0 H_0 H 0 t 0 ≤ − t α ( n − 1 ) t_0 \leq -t_{\alpha}(n-1) t 0 ≤ − t α ( n − 1 ) H 0 H_0 H 0
3. 두개의 표본에 대한 가설 검정
가설:H 0 : μ 1 = μ 2 H_0: \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 ≠ μ 2 H_1: \mu_1 \neq \mu_2 H 1 : μ 1 = μ 2 H 0 : μ 1 = μ 2 H_0: \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 > μ 2 H_1: \mu_1 > \mu_2 H 1 : μ 1 > μ 2 H 0 : μ 1 = μ 2 H_0: \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 < μ 2 H_1: \mu_1 < \mu_2 H 1 : μ 1 < μ 2
유의수준:α = 0.05 \alpha = 0.05 α = 0 . 0 5 Z = ( X ‾ 1 − X ‾ 2 ) − ( μ 1 − μ 2 ) σ 1 2 n 1 + σ 2 2 n 2 ∼ N ( 0 , 1 ) Z = \frac{(\overline{X}_1 - \overline{X}_2) - (\mu_1 - \mu_2)}{\sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}}} \sim N(0,1) Z = n 1 σ 1 2 + n 2 σ 2 2 ( X 1 − X 2 ) − ( μ 1 − μ 2 ) ∼ N ( 0 , 1 )
검정통계량 관측값:Z 0 = ( X ‾ 1 − X ‾ 2 ) σ 1 2 n 1 + σ 2 2 n 2 Z_0 = \frac{(\overline{X}_1 - \overline{X}_2)}{\sqrt{\frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}}} Z 0 = n 1 σ 1 2 + n 2 σ 2 2 ( X 1 − X 2 )
a) ∣ Z 0 ∣ ≥ Z α / 2 |Z_0| \geq Z_{\alpha/2} ∣ Z 0 ∣ ≥ Z α / 2 H 0 H_0 H 0 Z 0 ≥ Z α Z_0 \geq Z_{\alpha} Z 0 ≥ Z α H 0 H_0 H 0 Z 0 ≤ − Z α Z_0 \leq -Z_{\alpha} Z 0 ≤ − Z α H 0 H_0 H 0
가설:H 0 : μ 1 = μ 2 H_0: \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 ≠ μ 2 H_1: \mu_1 \neq \mu_2 H 1 : μ 1 = μ 2 H 0 : μ 1 = μ 2 H_0: \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 > μ 2 H_1: \mu_1 > \mu_2 H 1 : μ 1 > μ 2 H 0 : μ 1 = μ 2 H_0: \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 < μ 2 H_1: \mu_1 < \mu_2 H 1 : μ 1 < μ 2
유의수준:α = 0.05 \alpha = 0.05 α = 0 . 0 5 S p 2 = ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2 n 1 + n 2 − 2 S_p^2 = \frac{(n_1-1)S_1^2 + (n_2-1)S_2^2}{n_1 + n_2 - 2} S p 2 = n 1 + n 2 − 2 ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2 T = ( X ‾ 1 − X ‾ 2 ) − ( μ 1 − μ 2 ) S p 1 n 1 + 1 n 2 ∼ t ( n 1 + n 2 − 2 ) T = \frac{(\overline{X}_1 - \overline{X}_2) - (\mu_1 - \mu_2)}{S_p\sqrt{\frac{1}{n_1} + \frac{1}{n_2}}} \sim t(n_1 + n_2 - 2) T = S p n 1 1 + n 2 1 ( X 1 − X 2 ) − ( μ 1 − μ 2 ) ∼ t ( n 1 + n 2 − 2 )
검정통계량 관측값:T 0 = ( X ‾ 1 − X ‾ 2 ) S p 1 n 1 + 1 n 2 T_0 = \frac{(\overline{X}_1 - \overline{X}_2)}{S_p\sqrt{\frac{1}{n_1} + \frac{1}{n_2}}} T 0 = S p n 1 1 + n 2 1 ( X 1 − X 2 )
a) ∣ T 0 ∣ ≥ t α / 2 ( n 1 + n 2 − 2 ) |T_0| \geq t_{\alpha/2}(n_1 + n_2 - 2) ∣ T 0 ∣ ≥ t α / 2 ( n 1 + n 2 − 2 ) H 0 H_0 H 0 T 0 ≥ t α ( n 1 + n 2 − 2 ) T_0 \geq t_{\alpha}(n_1 + n_2 - 2) T 0 ≥ t α ( n 1 + n 2 − 2 ) H 0 H_0 H 0 T 0 ≤ − t α ( n 1 + n 2 − 2 ) T_0 \leq -t_{\alpha}(n_1 + n_2 - 2) T 0 ≤ − t α ( n 1 + n 2 − 2 ) H 0 H_0 H 0
대응 비교: 쌍으로 조사된 자료 ( X 1 , Y 1 ) , ( X 2 , Y 2 ) , . . . , ( X l , Y l ) (X_1, Y_1), (X_2, Y_2), ..., (X_l, Y_l) ( X 1 , Y 1 ) , ( X 2 , Y 2 ) , . . . , ( X l , Y l ) X i X_i X i μ X \mu_X μ X Y i Y_i Y i μ Y \mu_Y μ Y D i = X i − Y i D_i = X_i - Y_i D i = X i − Y i
가설:H 0 : μ X = μ Y H_0: \mu_X = \mu_Y H 0 : μ X = μ Y H 1 : μ X ≠ μ Y H_1: \mu_X \neq \mu_Y H 1 : μ X = μ Y H 0 : μ X = μ Y H_0: \mu_X = \mu_Y H 0 : μ X = μ Y H 1 : μ X > μ Y H_1: \mu_X > \mu_Y H 1 : μ X > μ Y H 0 : μ X = μ Y H_0: \mu_X = \mu_Y H 0 : μ X = μ Y H 1 : μ X < μ Y H_1: \mu_X < \mu_Y H 1 : μ X < μ Y
a) H 0 : μ D = 0 H_0: \mu_D = 0 H 0 : μ D = 0 H 1 : μ D ≠ 0 H_1: \mu_D \neq 0 H 1 : μ D = 0 H 0 : μ D = 0 H_0: \mu_D = 0 H 0 : μ D = 0 H 1 : μ D > 0 H_1: \mu_D > 0 H 1 : μ D > 0 H 0 : μ D = 0 H_0: \mu_D = 0 H 0 : μ D = 0 H 1 : μ D < 0 H_1: \mu_D < 0 H 1 : μ D < 0
유의수준:α = 0.05 \alpha = 0.05 α = 0 . 0 5 T = D ‾ − μ D S D / n ∼ t ( n − 1 ) T = \frac{\overline{D} - \mu_D}{S_D / \sqrt{n}} \sim t(n-1) T = S D / n D − μ D ∼ t ( n − 1 )
검정통계량 관측값:T 0 = D ‾ − μ D S D / n T_0 = \frac{\overline{D} - \mu_D}{S_D / \sqrt{n}} T 0 = S D / n D − μ D
a) ∣ t 0 ∣ ≥ t α / 2 |t_0| \geq t_{\alpha/2} ∣ t 0 ∣ ≥ t α / 2 H 0 H_0 H 0 t 0 ≥ t α t_0 \geq t_{\alpha} t 0 ≥ t α H 0 H_0 H 0 t 0 ≤ − t α t_0 \leq -t_{\alpha} t 0 ≤ − t α H 0 H_0 H 0
이 글은 제로베이스 강의 자료 일부를 발췌하여 작성되었습니다