👉 연휴간 한 일
- 미니 프로젝트(유튜브 특정 한 채널 영상들의 요약 정보 (video_id, 영상 제목, 조회수, 좋아요 수, 댓글 수, 댓글 크롤링)
- 프로젝트 트러블 슈팅
미니 프로젝트 (유튜브 크롤링)
내 파트
유튜브 api를 활용해 지정 영상들의 댓글 크롤링하기 - (이강인 활약상 영상 반응 수집)
- 유튜브 api 생성
- 구글 계정 로그인 후 google api console
(https://console.developers.google.com/)에 접속해 api 키 발급 Library에서 youtube 검색 후 Youtube Data API v3를 enableCredentials에서 사용자 인증 정보 생성 후 api 키 발급
- 라이브러리 설명
google-api-python-client 라이브러리 사용
- 공식문서 👇
google-api-python-client/docs at main · googleapis/google-api-python-client
- 서비스하는 api와 api 버전 목록
- api에서 사용하는 http 통신 방법, 일일 할당량 등
시작하기 | YouTube Data API | Google Developers
- build() : 구글 api 객체 생성 함수. api를 사용하기 위해 필요함
- commentThreads().list() : 영상의 댓글 목록을 GET 방식을 이용해 가져옴
- .insert(POST) 방식도 지원
- .execute() : 실행 함수
- 이렇게 수집된 response는 json형태로 반환됨
- 해당 함수 관련 자료 : https://developers.google.com/youtube/v3/docs/commentThreads/list?hl=ko#http-request
이외에 tqdm , pandas 사용
- 참고자료
- 코드
- google-api-python-client 라이브러리 설치
# 유튜브 라이브러리 설치
# !pip install google-api-python-client- 라이브러리 로드
# 라이브러리 로드
import pandas as pd
from googleapiclient.discovery import build # google api 연결
from tqdm import tqdm # 진행상황 파악
import warnings # 경고창 무시
warnings.filterwarnings('ignore')- 영상 댓글을 가져와 csv파일 만드는 함수 생성
def collect_comments (video_list, result_list, api_key, keyword) :
#tqdm 적용
video_list = tqdm(video_list) # 영상 항목 별로 진행상황 확인
# api 연결
api_obj = build ('youtube', 'v3', developerKey = api_key)
# 각 video의 댓글이 잘 합쳐졌는지 확인하기 위해서 shape 생성
shape_count = list()
for video in video_list: # 리스트에 담긴 첫 번째 영상부터 마지막 영상까지 반복
video_id = video[17:] # 영상 공유하기 기준 url의 video id는 18번째 인덱스부터 끝까지임(모든 영상 동일)
video_list.set_description ("Collecting Comments from youtube....") # tqdm.set_description : 진행상황 확인 중 설명 메세지 달기
response = api_obj.commentThreads().list(part='snippet,replies',
videoId = video_id,
maxResults = 100). execute()
# 각 비디오의 댓글
comments = list() # 댓글을 담을 빈 리스트 생성
while response:
for item in response['items']:
# json 파일에서 불러올 항목 찾기
comment = item['snippet']['topLevelComment']['snippet']
# 댓글 내용, 작성자, 게시일, 좋아요 수 수집
comments.append([comment['textDisplay'], comment['authorDisplayName'], comment['publishedAt'],comment['likeCount']])
# 대댓글 수집 (대댓글 1~3개인 것들은 중간에 댓글이 삭제되거나 하면 값을 가져오지 못하는 오류가 발생해 4개부터 가져옴)
# 댓글 수집과 같은 원리
if item['snippet']['totalReplyCount'] > 3:
for reply_item in item['replies']['comments']:
reply = reply_item['snippet']
comments.append([reply])
comments.append([reply['textDisplay'], reply['authorDisplayName'], reply['publishedAt'], reply['likeCount']])
# page 넘겨가면서 댓글 조회
if 'nextPageToken' in response:
response = api_obj.commentThreads().list(part='snippet,replies', videoId=video_id, pageToken=response['nextPageToken'], maxResults=100).execute()
else:
break
# 데이터 프레임으로 만들어주기
df = pd.DataFrame(comments, columns = ["comment", "author", "datetime", "like_count"])
# na 값 제거
df = df.dropna(axis=0)
# 각 비디오별 자료개수 파악
print(f"{video_id} : {df.shape}")
# 합계할 리스트에 삽입
shape_count.append(df.shape[0])
# 최종 df로 만들기 전에 리스트에 삽입
result_list.append(df)
# 최종 df로 합쳐주기
result_list = pd.concat(result_list,ignore_index=True)
# 파일 생성
result_list.to_csv(f"{keyword}.csv", index=False)
if sum(shape_count) == result_list.shape[0]:
print("합계가 일치합니다.")
return result_list
else:
print(f"sum : {sum(shape_count)} / {result_list.shape[0]} 합계가 일치하지 않습니다.")
return result_list- 함수 적용
url_list = ["https://youtu.be/mktb4KDO4Jo", "https://youtu.be/v9n3z9UEPXs"] # 영상 공유하기 기준 url
api_key = 'api key'
comments_list = [] # 댓글을 저장할 리스트 생성
keyword = "이강인"
collect_comments(url_list, comments_list, api_key, keyword)수집한 파일 전처리 및 분석(Shorts // 일반 영상 데이터 비교)
- 폰트 설정
import platform
import matplotlib as mpl
# 레티나 디스플레이로 폰트가 선명하게 표시되도록 함
from IPython.display import set_matplotlib_formats
# 한글 폰트 설정
def get_font_family():
"""
시스템 환경에 따른 기본 폰트명을 반환하는 함수
"""
system_name = platform.system()
if system_name == "Darwin" :
font_family = "AppleGothic"
elif system_name == "Windows":
font_family = "Malgun Gothic"
else:
mpl.font_manager._rebuild()
findfont = mpl.font_manager.fontManager.findfont
mpl.font_manager.findfont = findfont
mpl.backends.backend_agg.findfont = findfont
font_family = "NanumBarunGothic"
return font_family# 한글폰트를 설정
plt.rc("font", family=get_font_family())
plt.rc("axes", unicode_minus=False)
set_matplotlib_formats("retina")- 파일 불러와서 하나의 데이터프레임으로 병합
# 파일 불러오기
data_list = ['Youtube_scrap_조코딩_2022-10-03_v0','Youtube_scrap_생활코딩_2022-10-03_v0','Youtube_scrap_동빈나_2022-10-03_v0','Youtube_scrap_노마드코더_2022-10-03_v0']
data = []
for i in data_list:
data.append(pd.read_csv(f'./{i}.csv', dtype={"itemcode":"object"}, parse_dates=["date"])) ## csv 불러올 때 date 칼럼 datetime형식으로 불러오도록 수정했습니다!
df = pd.concat(data).reset_index(drop=True).sort_values(by=["view","likecnt","comment"], ignore_index=True, ascending = False)
video_id = df['video_id'][0]
video_name = df['title'][0]
df.shape- 데이터 요약정보 확인
df.info()- 전처리
# 날짜별 분석을 위해 파생변수 생성
df["year"] = df["date"].dt.year
df["month"] = df["date"].dt.month
df["dayofweek"] = df["date"].dt.dayofweek # 요일# 쇼츠 / 일반 분할
df_shorts = df[df["title"].str.contains("Shorts")]
df_normal = df[~df["title"].str.contains("Shorts")]
print(df_normal.shape)
print(df_shorts.shape)# 과학적 표기법 해제
pd.set_option('display.float_format', '{:.1f}'.format)
df_normal.describe()
df_shorts.describe()- 시각화
# 채널 별 일반 영상 수
sns.countplot(data = df_normal, x="channel_name")# 채널 별 쇼츠 영상 수
sns.countplot(data = df_shorts, x="channel_name")fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_size_inches(18,10)
sns.pointplot(data=df_normal, x="year", y="view", hue="channel_name", ax=axes[0][0], ci=None)
sns.pointplot(data=df_normal, x="month", y="view", hue="channel_name", ax=axes[0][1], ci = None)
sns.pointplot(data=df_shorts, x="year", y="view", hue="channel_name", ax=axes[1][0], ci = None)
sns.pointplot(data=df_shorts, x="month", y="view", hue="channel_name", ax=axes[1][1], ci = None)
axes[0][0].set(title = '연도별 조회수(일반)')
axes[0][1].set(title = '월별 조회수(일반)')
axes[1][0].set(title = '연도별 조회수(쇼츠)')
axes[1][1].set(title = '월별 조회수(쇼츠)')프로젝트 트러블 슈팅
노션 페이지 정리
https://www.notion.so/Structure-v-59edbf155b4f4aaabe74723f8a779ff9
video comment 불러오는 부분해결
- 이 부분의 코드가 위치한 부분
<code><a href="/youtube/v3/docs/commentThreads/list#videoId">videoId</a></code>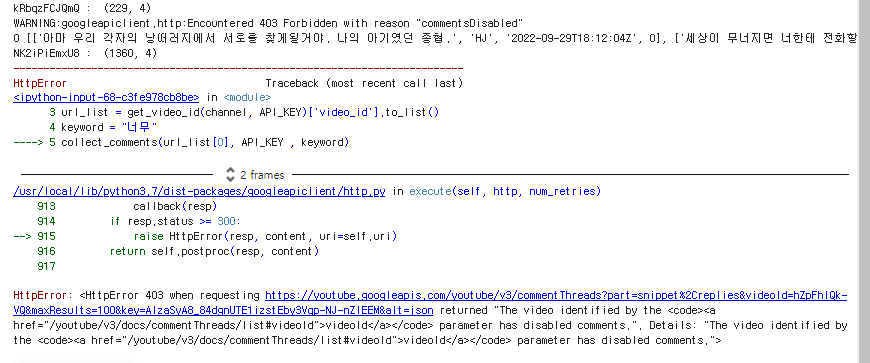
- “commentDisabled” <http 403 ERROR>
HttpError: <HttpError 403 when requesting https://youtube.googleapis.com/youtube/v3/commentThreads?part=snippet%2Creplies&videoId=hZpFhlQk-VQ&maxResults=100&key=AIzaSyA8_84dgnUTE1izstEby3Vqp-NJ-nZlEEM&alt=json returned "The video identified by the
<code><a href="/youtube/v3/docs/commentThreads/list#videoId">videoId</a></code>
parameter has disabled comments.". Details: "The video identified by the <code><a href="/youtube/v3/docs/commentThreads/list#videoId">videoId</a></code> parameter has disabled comments.">error 나는 비디오 id : hZpFhlQk-VQ
build() 함수 status return값을 찾아서 불러올 수 있는 비디오만 긁어오는 것도 좋을듯
통계분석이 가능할지 ??해결
전체 조회수 총합이나, date와 view의 관계, view와 likecnt의 관계등을 따지는게 낫지 않을까
영상 좋아요수 viewer count , comment 로 한번 시각화
댓글은 워드클라우드 해결!
Token 수집 제한 이슈
comments = []
video_id = 'wDfqXR_5yyQ'
comment_list_response = youtube.commentThreads().list( videoId = video_id, order = 'relevance', part = 'snippet,replies', maxResults = 100
).execute()
cnt = 0
while comment_list_response: for item in comment_list_response['items']: comment = item['snippet']['topLevelComment']['snippet'] comments.append([comment['textDisplay'], comment['authorDisplayName'], comment['publishedAt'], comment['likeCount']]) if item['snippet']['totalReplyCount'] > 0: for reply_item in item['replies']['comments']: reply = reply_item['snippet'] comments.append([reply['textDisplay'], reply['authorDisplayName'], reply['publishedAt'], reply['likeCount']]) if 'nextPageToken' in comment_list_response: comment_list_response = youtube.commentThreads().list( videoId = video_id, order = 'relevance', part = 'snippet,replies', pageToken = comment_list_response['nextPageToken'], maxResults = 100 ).execute() cnt += 1 else: print(cnt) break
comment_df = pd.DataFrame(comments, columns = ["comment", "author", "datetime", "like_count"])
>>> 21. *2022년 10월 2일 오전 2:00*
유튜브 댓글 수집하면서 문제가 생겼네요. api를 이용하면 `nextPageToken`를 이용하여 다음 페이지로 넘어가는데, 해당 토큰이 20번밖에 작동을하지 않네요.
한번 수집 시 100개의 결과가 최댓값이니 총 2000개의 댓글만을 수집하는 한계가 있습니다.
2. *2022년 10월 2일 오전 2:01*
구글링을 해보니 10년전쯤에는 토큰이 10개가 한계였던거 같네요.
[https://issuetracker.google.com/issues/35171641?pli=1](https://issuetracker.google.com/issues/35171641?pli=1)

-
데이터 쪼가리 저장 꼭 하기csv 파일로 반환하는 함수 꼭 꼭 꼭 !!!! 로직을 video 목록 다 추출한 csv파일을 만들어놓고 try~except 해서 에러 나면 미리 세이브해둔 파일 쓰고 에러안나면 킵고잉하게 함수를 짜면 될것같음 -
Colab 한글 폰트 이슈
!apt-get install fonts-nanum* -qq # 나눔 한글 폰트 설치
font = '/usr/share/fonts/truetype/nanum/NanumGothicEco.ttf' # 나눔고딕 호출Colab은 별도로 한글 폰트를 설치해서 불러와야 한다…
드라이브에 한글 폰트 업로드 하는 뻘짓을 하지 말자전반적인 프로젝트 프로세스 정리
[미니프로젝트] 데이터 수집
https://velog.io/@moonstar/%EB%AF%B8%EB%8B%88%ED%94%84%EB%A1%9C%EC%A0%9D%ED%8A%B8-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%88%98%EC%A7%91
노션 보고서
https://www.notion.so/likelion-aischool/0a98439030e94fbda9762811eb01dec2

자라나라 새싹새싹🌱