
🦁🦁
👉 오늘 한 일
- 피처 엔지니어링 이어서
- 랜덤 포레스트
- 의사결정나무(회귀)
feature engineering
하이퍼파라미터 튜닝은 원래 가장 마지막 단계에 함
결측치가 많은데 0으로 처리하면 제대로된 분석이 불가능
수치형 변수를 범주형으로 인코딩할 수 있음
label이 없는 데이터들은 사람이 직접 label을 수작업으로 넣기도 함
- 자동화가 되어 있는 부분도 있고 labeling을 전문적으로 하는 업체도 있음
데이터셋 샘플링
split_count = int(df.shape[0] * 0.8)
train = df[:split_count]
test = df[split_count:]
X_train = train[feature_names]
y_train = train[label_name]
X_test = test[feature_names]
y_test = test[label_name]트리를 더 선명하게 그리고 싶다면 graphviz 라이브러리 이용
model.score()의 값과 accuracy_score() 값의 결과는 같이 나오는데 y_predict를 따로 만드는 이유
-> 다른데 쓸데가 있어서
이상치 제거
Insulin_nan : raw data에서 0을 nan로 바꾼 컬럼
Insulin_fill : Insulin_nan에서 nan값을 평균으로 채운 값
어디서 이상치를 제거해야 하는가? -> Insulin_fill은 전처리가 한 번 된 값이므로 Insulin_nan에서 하는게 조금 더 정확함
decision tree의 samples, value
- samples : 분지해서 나눠진 raw의 개수
- value : 분지된 노드 안에서 label을 예측한 값([T, F])
decision tree의 단점
- 계층적 접근 방식이기 때문에 중간에 에러가 발생하면 다음 단계로 에러가 계속 전파됨
- 결과 또는 성능의 변동 폭이 큼
-> 과적합 가능성이 높음. 일반화하기 어려움
단점에도 불구하고 사용하는 이유 : 빠르고 단순해서 데이터 피처의 중요도 파악에 용이하고 직관적임
random forest
랜덤 포레스트
- 가장 큰 특징은 랜덤성(randomness)에 의해 트리들이 서로 조금씩 다른 특성을 갖는다는 것
- 각 트리들의 예측(prediction)들이 비상관화(decorrelation) 되게하며, 결과적으로 일반화(generalization) 성능을 향상시킴
- 랜덤화(randomization)는 포레스트가 노이즈가 포함된 데이터에 대해서도 강인하게 만들어 줌
- 대표적인 배깅 알고리즘
배깅(bagging)
- bootstrap aggregating의 약자로 bootstrap을 통해 조금씩 다른 훈련 데이터에 대해 생성된 기초 분류기(tree)들을 결합시키는 방법
- bootstrap : 주어진 훈련 데이터에서 중복을 허용해서 표본을 원 데이터와 같은 크기의 데이터셋을 만드는 과정
- random bootstraping 시 중복을 허용해 같은 샘플이 다른 tree에도 포함될 수 있음
장점
- 월등히 높은 정확성
- 간편하고 빠른 학습 및 테스트 알고리즘
- 변수소거 없이 수천 개의 입력 변수들을 다루는 것이 가능
- 임의화를 통한 좋은 일반화 성능
- 다중 클래스 알고리즘 특성
RandomForestClassifier() : 랜덤 포레스트
- n_estimator : 생성할 tree의 개수
- n_jobs : 사용할 cpu의 코어 수
- -1을 arg로 넘기면 모든 코어 사용 -> 속도 개선됨
- 코어의 수를 지정하지 않고 -1을 사용하는 이유? : 사용중인 코어를 모를 경우를 대비하기 위해(내 컴퓨터에서만 동작하는게 아니라 다른 사람 컴퓨터에서도 구동되기 때문)
- 랜덤 포레스트는
plot.tree로 시각화할 수 없음.treeinterpreter라이브러리 사용해 시각화(집계한 결과의 feature importance를 시각화해줌)
🤔sklearn 기본 데이터에서 보스턴 집값 데이터가 제외된 이유?
: "B"라는 피처가 존재.(흑인 수가 얼마나 되는지 나타내는 피처) 윤리적인 이유로 삭제
틀린 값만 찾아보기
test["accuracy"] = y_test == y_predict
test[test["accuracy"] == False]Decision tree(회귀)
예측모델 성능 평가
hold-out validation : train dataset에서 validation dataset으로 나눔(전체 dataset에서 train, validation, test로 나눔). 훈련셋을 이용해서 모델을 훈련시키고, 검증셋으로 모델의 최적 파라미터들을 찾아가고, 그 다음에 테스트셋을 이용해서 모델의 성능을 평가함.
- train, test 두 가지로 나누는 것도 hold-out validation 방법의 하나임
- 장점 : 빠르게 평가가 가능함
k-fold validation : train 데이터셋을 k개의 서브셋으로 분리. 이후에 하나의 서브셋만 테스트에 사용하고 나머지 k-1개의 서브셋은 훈련에 사용. 이를 k번 반복해 측정한 성능지표를 평균냄으로 최종적으로 모델의 성능을 평가함.
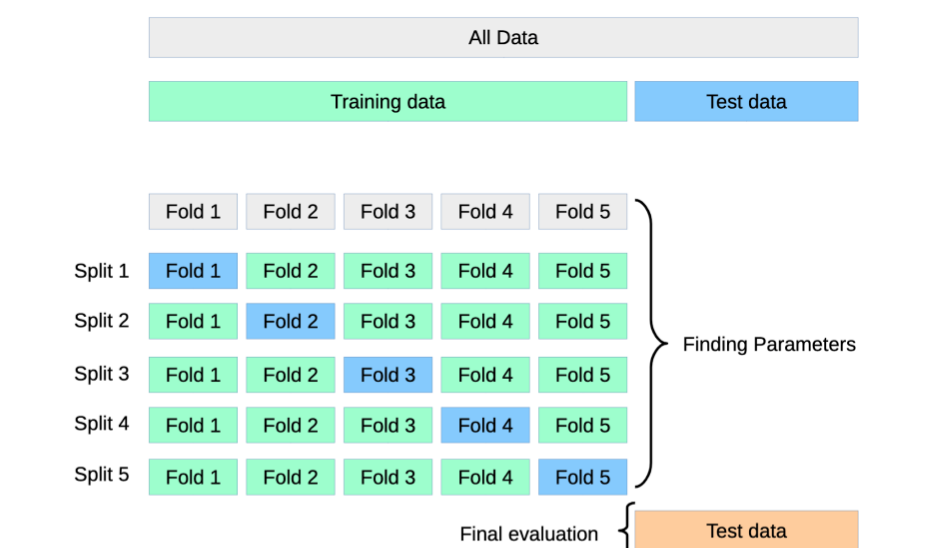
- 4개의 fold(초록색)로 학습을 하고 1개의 fold(파란색)로 검증 후 각 split의 성능을 평균내서 평가함
- 폴드 번호가 같으면 같은 데이터셋임
- 여러 fold로 쪼갤수록 신뢰도가 올라감
- 시계열 데이터의 교차 검증 과정은 조금 다름
- 고정된 train set과 test set으로 평가와 모델 튜닝하다보면 과적합되어 다른 모델에 일반화하기 어렵기 때문에 사용함
cross_val_predict() : 교차검증을 위한 함수. 교차 검증의 예측 결과를 반환해줌
cross_val_score함수로 바로 점수를 출력할 수도 있음- cv : fold의 개수
- verbose : 실행 로그를 출력함
- verbose=1 보다 verbose=2가 로그를 더 자세하게 출력함
r2_score()로 평가할 수 있음- r2_score = 1이 가장 좋음(예측값이 실제값과 모두 같음)
seaborn의 regplot, jointplot, residplot으로 예측값과 실제값을 비교해볼 수 있음
JD
99CON : 주니어 개발자의 이력서 쓰기 - 이동욱
https://speakerdeck.com/weirdx/99con-junieo-gaebaljayi-iryeogseo-sseugi-idongug
이력서 예시
https://jojoldu.github.io/
프로젝트는 최신순으로 정렬
파일은 PDF로. 절대 압축 NOPE
보편적인 이력서 양식
-
본인 프로필
-
본인 소개(5~7줄로)
-
기술 스택
- 신입일 경우 기술 스택은 상세하게 적을 것(어떤 툴로 무엇을 해봤고 무엇을 할 줄 아는지)
-
오픈소스 / 프로젝트 / 경력(순서는 무관)
-
교육(학교, 부트캠프), 발표, 집필, 기타등등..(선택사항)
