
ABSTRACT
유튜브는 현존하는 시스템 중 가장 큰 규모와 정교함을 자랑하는 추천시스템을 가지고 있다
본 논문에서는 딥러닝을 활용한 극적인 성능향상에 초첨을 맞춘다
추천 딥러닝 생성 모델에 관해 설명하고 딥 랭킹 모델을 설명한다
대규모 추천시스템을 운영, 유지보수 하며 얻은 인사이트를 알려드림~
1. INTRODUCTION
유튜브는 전세계에서 규모가 가장 큰 동영상 플랫폼, 따라서 유튜브 추천시스템은 10억명 이상의 사용자가 개인화된 콘텐츠를 발견하도록 돕는다(딥러닝이 엄청난 영향을 미침)
유튜브가 영상을 추천하는 것은 3가지 관점에서 매우 어려운 task이다
-
Scale: 기존의 많은 추천 알고리즘은 작은 규모에서는 잘 작동하지만, 유튜브와 같은 방대한 사용자와 비디오 corpus를 가진 시스템에서는 그렇지 않다. 따라서 고도로 전문화된 분산 학습 알고리즘 및 효율적인 serving systems이 필수적이다
-
Freshness: 유튜브는 초당 수 시간 분량의 동영상이 업로드 됨 따라서 추천시스템은 이에 맞게 새로 업로드된 콘텐츠는 물론 사용자가 최근에 취한 행동에도 반응 할 수 있도록 해야한다
-
Noise: Sparsity와 수 많은 외부요인들로 사용자 행동을 예측하기 어려움, 사용자 만족도에 대한 실질적은 데이터를 얻기 힘듬
모델은 오픈소스인 Tenserflow를 사용하고 약 10억 개의 매개변수를 학습하고 수천억 개의 example을 학습함
막대한 양의 행렬 연산과 대조적으로 deep neural networks를 추천 시스템에 사용하는것은 상대적으로 적은 연산이 수행됨
2. SYSTEM OVERVIEW
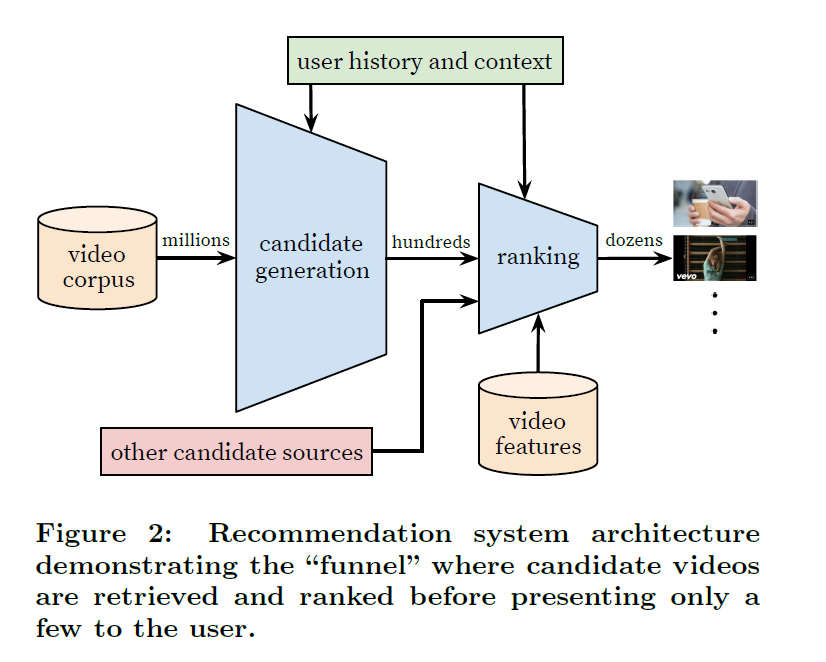
System은 두 개의 신경망으로 구성됨 (candidate generation과 raking)
candidate generation network는 사용자의 유튜브 활동기록을 input으로 받아 대규모 영상 corpus에서 하위 집합의 영상(hundreds)을 검색한다 (이렇게 나온 영상 후보들은 사용자와 관련성이 높음)
협업 필터링을 사용함
사용자 간의 유사성은 동영상 시청id,검색 쿼리, 인구 통계(demographics)와 같은 특징을 활용한다고 한다
ranking network 에서는 사용자에게 각 영상에 점수를 할당하여 제공함
평가 지표는 다양한 metrics(precision, recall, ranking loss 등)을 활용하나 알고리즘의 효율성 평가에는 A/B test를 활용함
실제 실험에서는 클릭 수, 시청 시간 및 사용자 참여를 측정하는 여러 지표를 측정함
3. CANDIDATE GENERATION
후보를 생성하는 동안 막대한 양의 영상은 사용자과 관련된 몇백개의 영상으로 압축된다
3.1 Recommendation as Classification
추천을 다중 분류문제로 봄
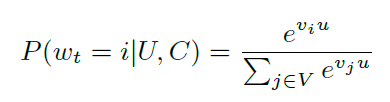
- u: high-dimensional users embedding
- v_j: embedding된 후보 영상
- w_t: time t 에서 특정 영상
- C: context
- U: User
사용자와 사용자에 대한 context가 주어졌을 때 특정 영상에 대한 확률은 위의 식으로 softmax로 구할 수 있음
심층신경망은 사용자의 history와 context로 sofmax classifier을 활용해 영상을 분류함
모델의 훈련에는 영상의 좋아요, 설문조사와 같은 explicit feedback보다는 영상을 끝까지 시청했는가와 같은 implicit feedback을 사용함
Efficient Extreme Multiclass
다량의 클래스의 효율적인 학습을 위해 negative classes를 활용
softmax의 계산에 많은 시간이 소요되기 때문에 negative sampling를 활용하면 100배 빠르게 계산 가능하다고 한다
https://heytech.tistory.com/354 (negative sampling에 관한 설명)
serving time에는 사용자에게 상위 N개의 영상을 보여주어야함
수백만개 아이템의 점수를 매기는것은 수밀리초의 시간이 소요됨(softmax 의 likelihood를 계산하는 것은 오랜 시간이 소요) 그래서 nearest nighbor search를 활용해 그 시간을 줄임
3.2 Model Architecture
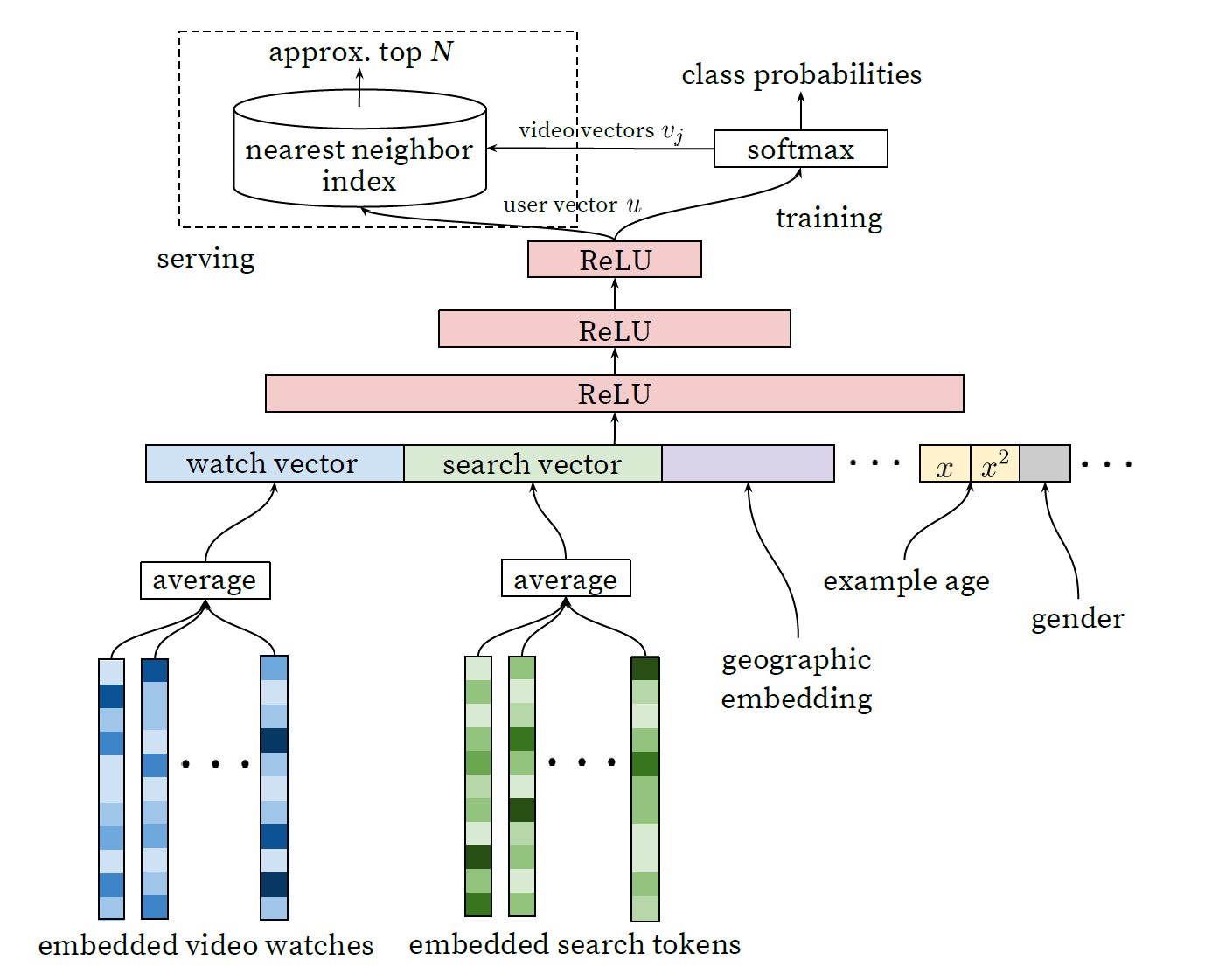
사용자 시청기록에 대한 embedded vector, 검색기록 vector, geographic embedding, example age feature, gender가 input으로 hidden layer에 입력됨(hidden layer은 모두 fully connected)
학습은 cross-entropy loss를 minimized with gradient descent
serving시에는 nearest neighbor search
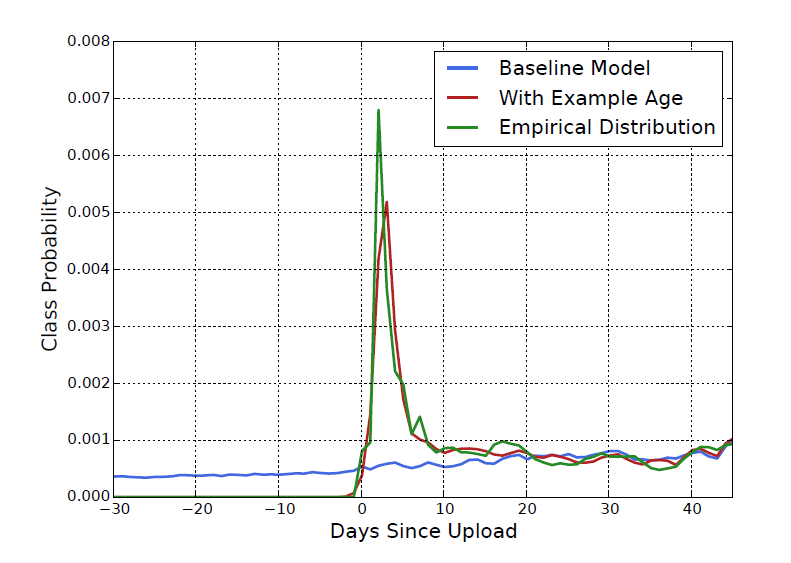
사용자들은 최신의 영상을 추천받기 원하는데 example age feature을 추가함으로써 그것을 만족하고 성능을 올릴 수 있었다
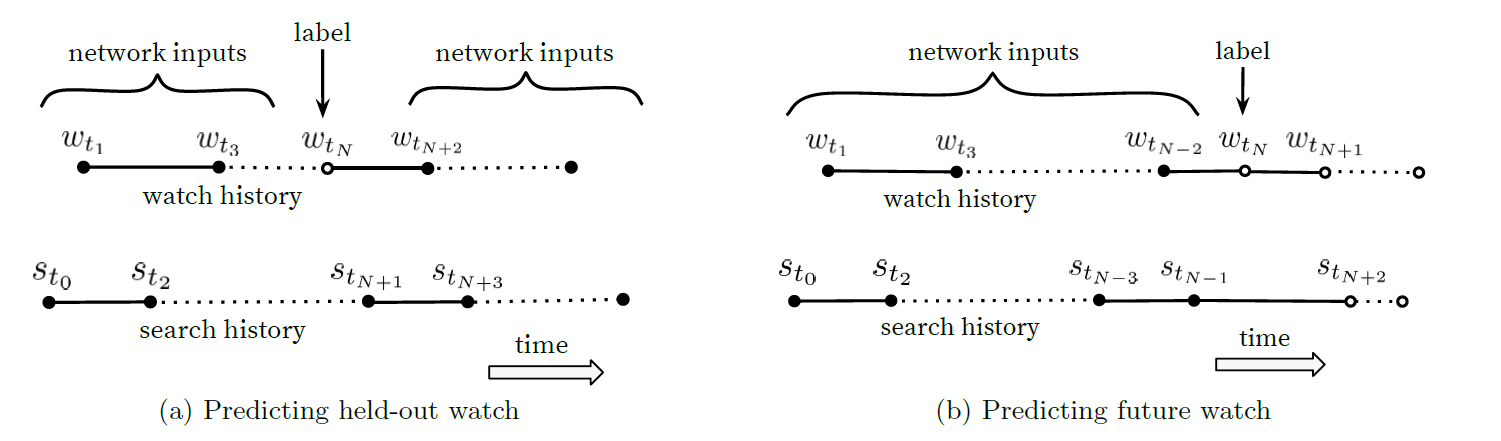
3.4 Label and Context Selection
사용자가 유튜브의 추천외의 수단으로 영상을 찾는다면 유튜브팀은 그것을 빠르게 알고 다른 사용자에게 전파시킬것이다
또 다른 insight는 사용자마다 고정된 크기의 training example을 할당하여 highly active users가 집단에 끼치는 영향력을 줄인다
사용자가 영상을 시청함에 있어 비대칭성이 있다(한 종류의 영상만 보지 않음)
추천결과를 예측함에 따라 random을 대상으로 추천하는 것 보다 시간성을 고려해서 추천하는것이 더 효과적(마치 시리즈물을 보는 것 처럼)
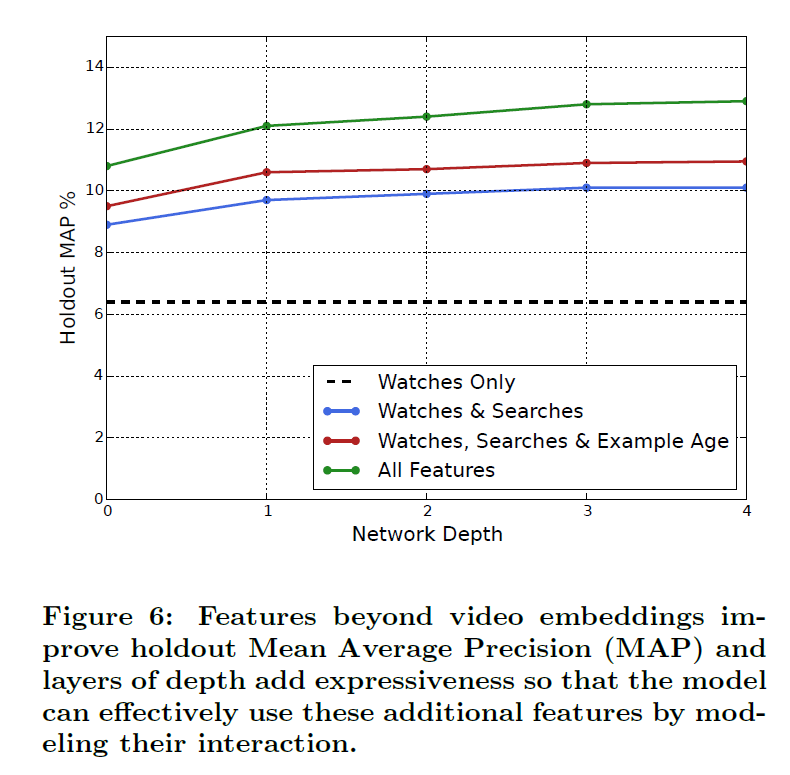
다양한 features 와 depth가 깊어짐에 따라 성능은 향상
4. RANKING
ranking을 하려고 사용자와 영상간의 관계에 대한 feature를 사용함 그 이유는 수백만개 후보 영상들을 ranking하는것보다 몇백개의 비디오를 점수 매기는게 더 낫기 때문
candidate generation과 유사한 신경망을 활용해 각 영상에 대한 점수를 측정(logistic regression 활용)
스코어가 측정된 영상들을 sorted해서 사용자에게 보여주게된다
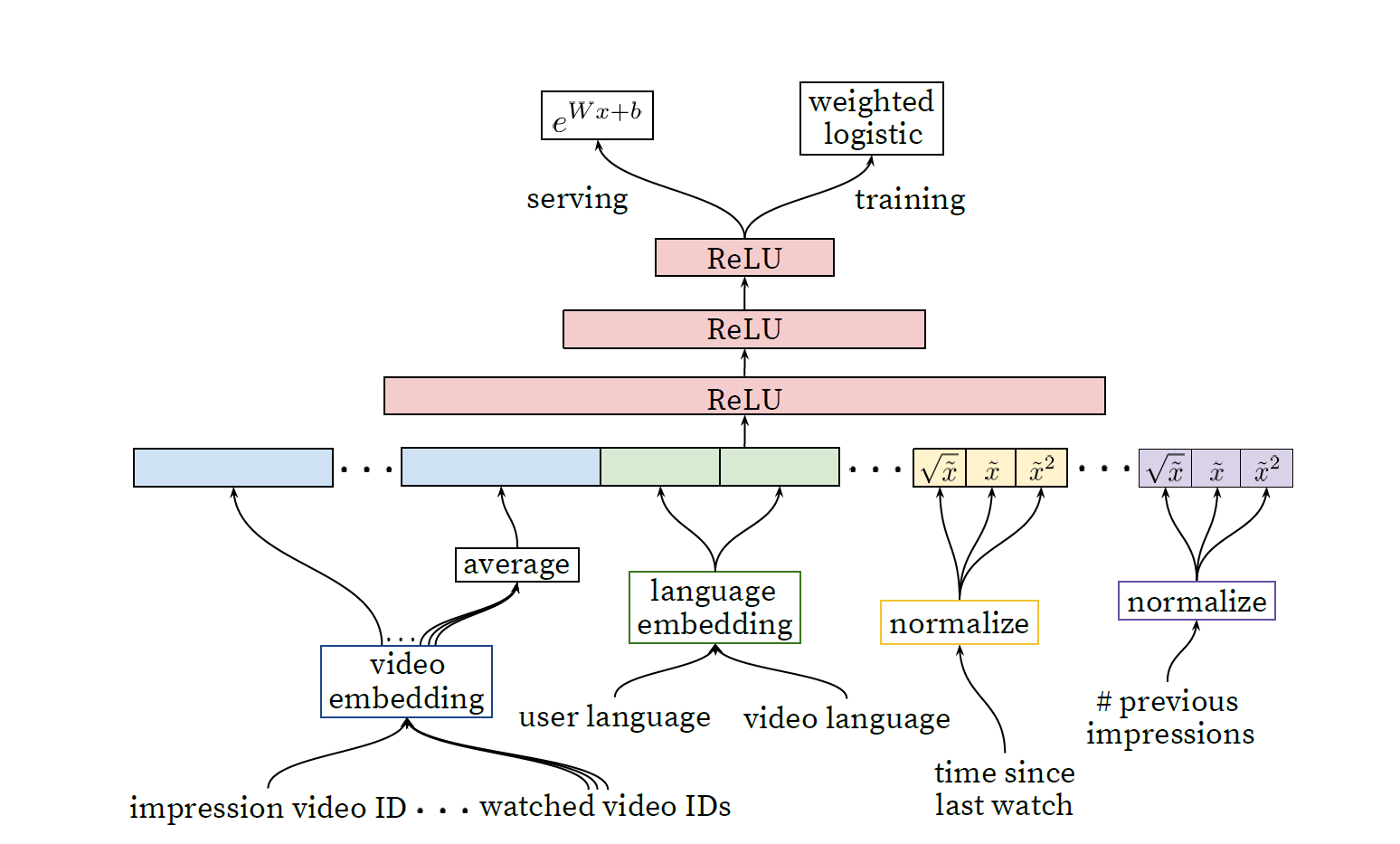
4.1 Feature Representation
사용한 categorical feature는 너무 방대하다고 한다(사용자 로그인에 관한 이진 값이나 수백만개의 값을 가질 수 있는 최근 검색 기록)
수백개의 features를 신경망에 입력을 하기 위해 수작업을 꽤나 한 것으로 보임
주요한 challenge는 사용자 행동 데이터와 영상간의 관계를 맺도록 하는것
이를 수행하기위해 사용자가 어떤 채널에서 영상을 얼마나 많이 보는가, 영상을 얼마나 오래 시청하는가 와 같은 특징이 사용자와 영상간의 관계를 강력하게 표현 할 수 있게한다
Embedding Categorical Features
- candidatae generation 신경망과 비슷하게 sparse한 features를 dense하게 만들어줌
- Top-N 영상 및 검색어를 embedding하고 나머지는 0으로 둔다
- 영상 id, 사용자가 마지막으로 본 영상 id, 이 추천에 사용된 seed 영상 모두 사용한다
Continuous Features
- 신경망은 input의 scaling에 민감함
- continous feature들을 scailing을 통해 분포를 바꿔주었다 (0~1 사이로)
- 신경망의 성능을 좋게 하기 위해 x^2, x^(2/1) 과 같은 작업을 해주기도 함
4.2 Modeling Expected Watch Time
사용자의 watch time을 예측하기 위해 weighted logistic regression을 사용함
사용자가 좋아요 한 영상은 그 영상의 길이 만큼 가중치를 주고 좋아요 하지 않은 영상은 그냥 unit weight을 받음
4.3 Experiments with Hidden Layers
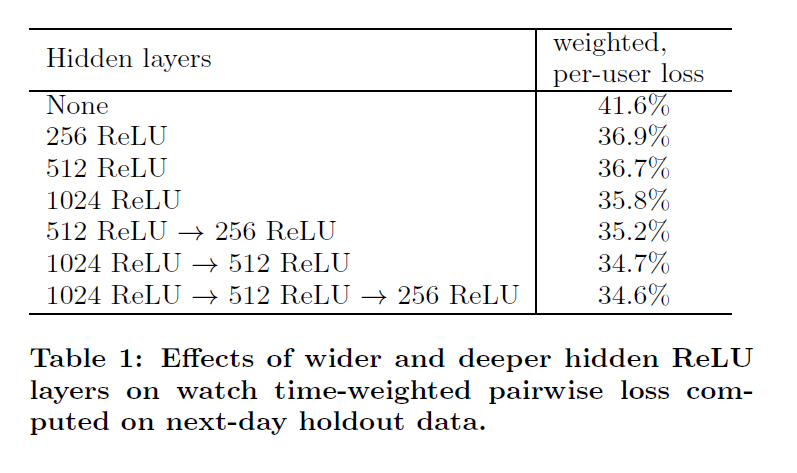
- weighted per-user loss는 사용자가 한 페이지에서 클릭한 영상과 클릭하지 않은 영상을 통해 구해진다.
- 클릭하지 않은 영상이 클릭한 영상보다 더 높은 score을 받게 되면 모델은 mispredict한것 그래서 그 비율을 통해 weighted per-user loss를 구한다
- 은닉층의 폭이나 깊이가 깊을 수록 성능은 좋다, 그러나 컴퓨팅 파워가 많이 들어가기 때문에 serving하는데 시간이 많이 걸려 trade-off가 발생
CONCLUSIONS
- 딥러닝을 활용한 추천시스템 모델은 당사가 이전에 사용하던 matrix factorization 보다 더 효과적이다
- 영상의 age를 사용한것은 효과적이었음
- 딥러닝 기반의 랭킹은 이전의 트리기반 watch time prediction보다 더 뛰어남
- weighted logistic regression으로 클릭된 영상에 가중치를 더 주는 방식이 click-through rate 보다 더 휼륭함
.jpg)