Abstract
- Convolution network가 ImageNet 분류문제에서 좋은 성능을 보이는데 왜 CNN이 좋은 성능을 보이는지는 알 수 없었다
- 본 논문에서는 CNN이 분류를 할 때 중간 계층에 무슨 일이 일어나는지 참신한 시각화를 통해 알 수 있게함
- 시각화를 통해 성능이 뛰어난 AlexNet의 아키텍쳐를 표현 할 수 있다
- ImageNet 데이터 뿐만 아니라 다른 데이터에 대해서도 좋은 성능이 나옴을 보여준다
1. Introduction
- 1990년대 얀 르쿤의 CNN(LeNet)이 발표된 이후 CNN은 손글씨나 얼굴인식에서 훌륭한 성능을 보임
- AlexNet(2012)는 ImageNet 2012에서 16.4%의 오류율을 달성하며 2등(26.1%)에 비해 월등한 성적을 거둠
- Convolution Network에 대한 관심은 몇가지 요인이 있다
- 수백만개의 레이블이 달린 큰 데이터에 대한 가용성
- 매우 큰 모델을 사용할 수 있도록 한 GPU의 사용
- Dropout과 같은 모델 규제방안
- 위와 같은 요인에도 불구하고 Convolution Network가 왜 좋은 성능을 보이는지 모델 내부에 대한 통찰력은 부족하다
- 모델이 어떻게 잘 작동하는지 모른다면 더 나은 모델의 개발에 걸림돌이 될 수 있다
- 본 논문에서는 모델을 잘 설명하기 위해 모델의 모든 계층에서 나오는 특징맵(feature map)을 시각화 함, 훈련중 특징맵의 진화를 관찰하고 모델의 문제를 진단할 수 있다
- 시각화는 deconvnet(2011)을 활용, 입력 영상의 일부를 차단하여 영상의 어떤 부분이 classification에 중요한지 검토
2. Approach
- 본 논문에서는 LeNet, AlexNet의 구조를 참고해 활용했다

1. 224x224 이미지에 7x7 컨볼루션 커널(stride=2)을 적용해 96 feature maps 생성(layer 1의 경우)
2. ReLU 함수 통과
3. maxpooling
4. Neural Net input은 6x6x256으로 9216 dimensions
5. softmax 함수로 최종 Classification
- N개의 {x, y} labeled 데이터를 사용했으며 yi 는 해당 인덱스만 true인 discrete variable이다
- loss function은 교차 엔트로피를 사용
- 훈련은 SGD를 사용한 Backprop을 통해 진행
2.1. Visualization with a Deconvnet
- 컨볼루션 넷을 이해하려면 중간 계층의 활동을 해석해야함
- 중간계층을 해석하기 위해 Deconvolution Network(Zeiler et al., 2011)를 활용했다
- Deconvolution Network(deconvnet)은 convolution network의 역연산
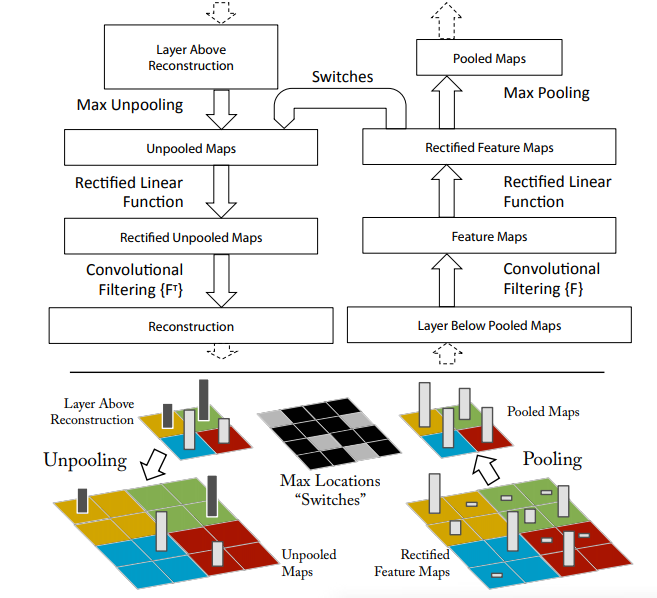
- deconvnet은 convnet의 기능을 거꾸로 재구성한다
- Unpooling: maxpooling 이전의 feature map을 재구성하기 위해 maxpooling으로 사용된 featuremap의 인덱스를 기억해 해당 위치에 픽셀 값을 채워넣는다(그림 하단 참고)
- Rectified: convnet은 ReLU를 사용하기 때문에 항상 feature map에 양수만 갖는다. 특징맵을 재구성 하기 위해 ReLU의 비선형성을 활용한다고 한다
- Filtering: 이전의 Layer으로부터 feature map을 복원하기 위해 학습에 사용했던 convolution filter을 사용함(이때 최대한 근사하게 복원하기 위해 필터의 Transposed를 사용함)
3. Training Details
- ImageNet Classification에 사용한 AlexNet과 유사한 모델을 사용
- AlexNet과 다른점은 3,4,5에서 AlexNet은 Sparse Connection을 사용했지만 Dense Connection으로 대체, Layer 1, 2에서 Filter Size, Stride를 변경함
- ImageNet의 training data sets(1.3 milion images, 1000개의 클래스)를 사용해 훈련하고 이미지를 256x256 으로 resize해 사용
- 128 미니배치와 SGD를 활용해 학습을 수행하고 lr = 0.01로 설정
- fully-connected layer에 Dropout을 사용하고 모든 weights는 초기에 0.01로 세팅하고 bias는 0으로 세팅
- 70 epochs에서 training을 중단하고 GTX580 GPU로 12일간 학습
4. Convnet Visualization
Feature Visualization

- 각 Layer별 얻은 feature map에서 가장 강한 특징 9개와 원본이미지를 보여줌
- feature map의 시각화를 통해 convnet의 동작에 통찰력을 제공할 수 있다
- 예를들어 Layer 5의 1행 2열을 보면 전경의 객체가 아닌 후경의 잔디에 더 활성화가 일어난 것을 확인가능하다
- Layer2는 코너나 에지에 반응
- Layer3은 유사한 질감을 포착하여 더 복잡한 invariance를 가진다
- Layer4는 개의 다리나 새의 다리와 같은 사물의 개체 일부를 시각화
- Layer5는 사물이나 개체의 전체적인 모습을 포함하는 high Level feature 시각화
Feature Evolution during Training

<각 layer 마다 좌에서 우로 epoch[1, 2, 5, 10, 20, 30, 40, 64]로 학습진행 상황 시각화>
- 훈련 중에 특징이 어떻게 진화하는지를 시각화
- 모델의 하위 layers는 몇 epoch안에 수렴하나, 상위의 layers는 40-50 epoch가 지나야만 수렴하는 것을 알 수 있다 따라서 충분한 epoch이 모델 훈련에 필요함
Feature Invariance
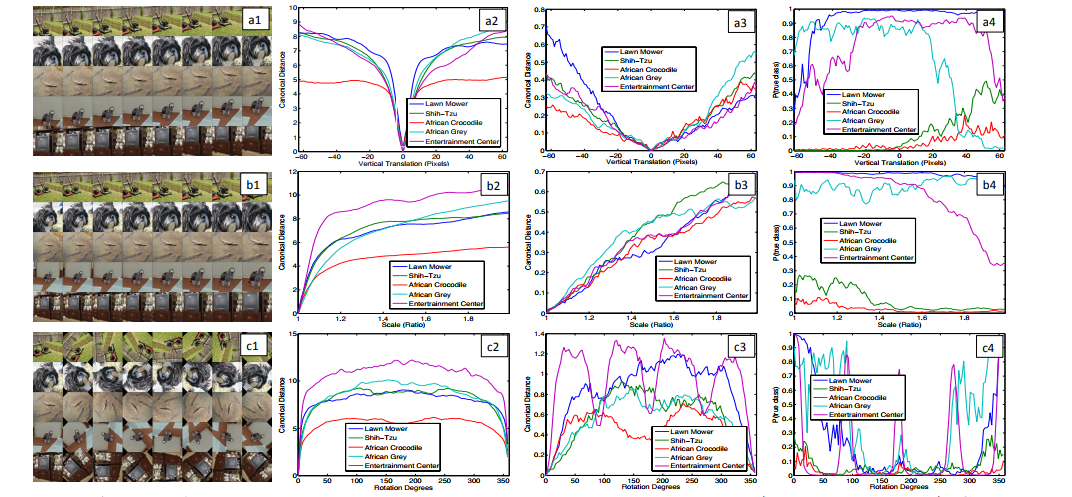
- 이미지를 이동(a), 크기변환(b), 회전(c)를 조정해 변화를 관찰
- 첫 번째 층에서는 작은 변형이 큰 영향을 미치지만 이후 그 영향이 미미해진다
- 이동과 크기변환에 대해서는 Classification에 불변한 특징이 있지만 회전에 경우 Classification에 영향이 있을 수 있다
4.1 Architecture Selection
-
훈련된 모델의 시각화를 통해 Convolution 작동 방식을 알 수 있을뿐만 아니라, 좋은 아키텍처를 선택하는데 도움이 될 수 있다

<(b)와 (d)는 AlexNet의 첫번째, 두번째 layer 시각화, (c)와 (e)는 논문에서 사용한 아카텍쳐의 첫번째, 두번째 layer 시각화> -
위의 figuer에서 (b)경우 극도로 높고 낮은 주파수 성분이 포함된 것을 알 수 있고 (d)는 높은 stride(=4)를 AlexNet에서 사용했기 때문에 에일리어싱이 관찰됨
-
이런 문제점을 줄이기 위해 논문에서 사용한 아키텍쳐는 컨볼루션 커널의 사이즈를 11x11 -> 7x7로, stride를 4 -> 2로 변경
-
더 좋은 정보를 전달 할 수 있었고 Classification 성능도 늘어났다고 함
4.2 Occlusion Sensitivity
-
모델이 이미지를 classification하는데 객체의 위치정보를 활용하는지 혹은 주변 context를 활용하는지 실험
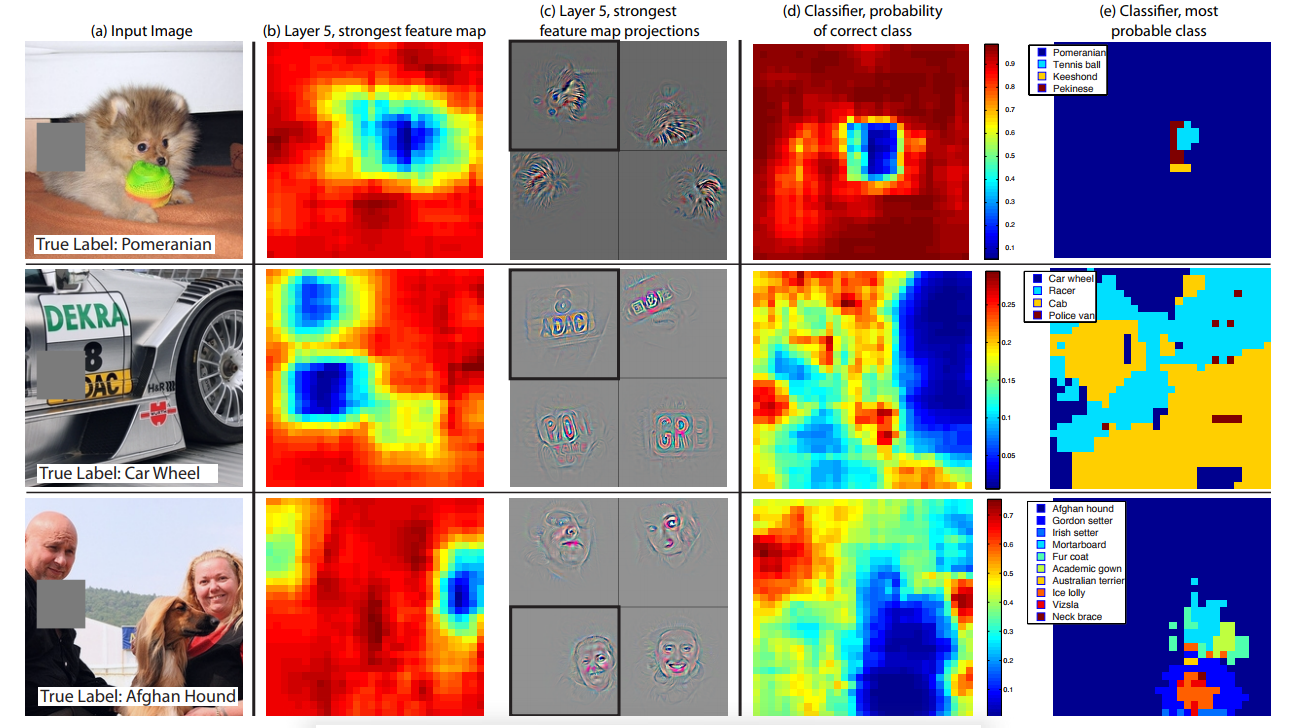
-
이걸을 확인하기 위해 input image에 회색 상자로 일부를 가리고 실험
-
모델이 객체를 지역화하는것을 확인 할 수 있다
-
객체가 가려질때 정확한 클래스의 확률이 감소한다
-
첫번째 행 (e)를 보면 개의 얼굴이 가려졌을때 테니스볼로 최종 분류 할 수 있음을 볼 수 있다
4.3 Corresp ondence Analysis
-
딥러닝 모델이 서로다른 이미지에서 객체의 일부분의 대응관계에 대한 명확한 매커니즘은 없다(매칭)
-
그러나 딥러닝이 암시적으로 이것을 수행하는것으로 보인다
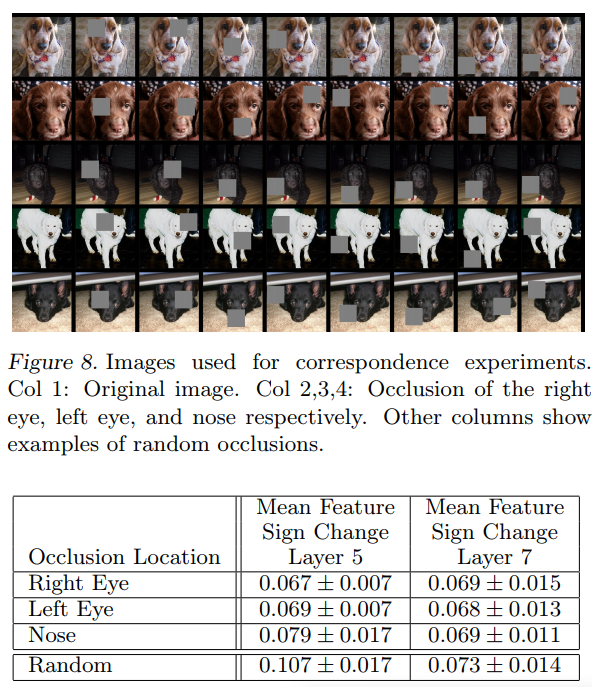
-
col1: 원본 이미지
-
col2, 3, 4 : 각각 오른쪽 눈, 왼쪽 눈, 코를 가린 이미지
-
나머지 columns: 랜덤하게 가린 이미지
-
5개의 사진간의 평균 일치도를 계산 하였는데 Layer5 경우 눈과 코를 가린것의 점수가 낮았으나 Layer7(상위 layer)의 경우 그 점수가 비슷해짐 -> 상위 레이어가 서로 다른 개의 품종을 구별했기 때문
5. Experiment
5.1. ImageNet 2012
- ImageNet 2012 데이터 셋을 그대로 활용해 AlexNet과 본 논문에서 사용한 모델(7 × 7 filters in layer 1 and stride 2 convolutions in layers 1
& 2)의 비교 - AlexNet과 비교해 1.7%의 성능향상으로 14.8%의 오류율
5.2. Feature Generation
-
모델을 visualization한 덕분에 ImageNet에서 최상의 성능을 거둘 수 있었다
-
Caltech-101, Caltech-256, PASCAL 2012 데이터 셋에 대해서도 실험
-
1-7 layers를 그대로 두고 layer 최상단에 softmax classifier 를 추가해 실험
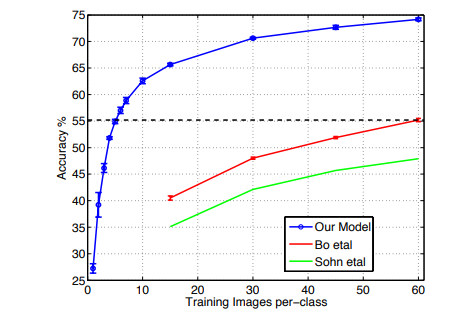
-
논문에 사용된 모델이 Caltech, PASCAL 데이터 세트에서도 좋은 성능을 보이고 클래스당 6개의 이미지만 사용해도 다른 모델들을 능가한다
5.3 Feature Analysis
- ImageNet 사전 훈련된 모델의 각 layer의 기능을 서로 비교함
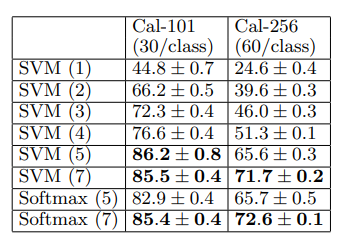
- 각 계층에 SVM 혹은 Softmax를 사용해 분류 성능을 평가함
- 상위 layer로 갈수록 더 특징을 뽑아내고 성능이 좋아진다
- layer가 더 깊어질수록 더 강력한 feature를 학습한다
6. Discussion
- CNN 모델내의 활동을 새로운 방법으로 시각화함
- 시각화를 통해 상위 layer로 갈수록 구성성, 불변성 및 클래스 구별과 같은 직관적으로 바람직한 특성을 보여줌
- 시각화를 통해 더 모델이 더 좋은 결과를 얻도록 디버그할 수 있다
- occlusion experiments를 통해 이미지의 local structure에 민감함을 확인
- 모델이 잘 동작하려면 최소한의 깊이를 가져야함
- ImageNet 데이터셋으로 훈련시킨 모델이 Caltech, PASCAL 데이터셋에도 일반화된 성능을 보인다
.jpg)