
데이터 셀렉션 및 필터링
- 판다스는 iloc[ ], loc[ ] 연산자를 통해 넘파이와 비슷하게 데이터를 추출할 수 있다
- 판다스의 DataFrame'[ ]'안에 들어갈 수 있는 것은 칼럼명 문자, 또는 인덱스로 변환 가능한 표현식만 가능하다
import pandas as pd
titanic_df = pd.read_csv('titanic_train.csv')
print('단일 칼럼 데이터 추출:\n', titanic_df['Pclass'].head(3))
print('\n 여러 칼럼의 데이터 추출:\n', titanic_df[['Survived', 'Pclass']].head(3))
print('[] 안에 숫자 index는 KeyError 오류 발생:\n', titanic_df[0])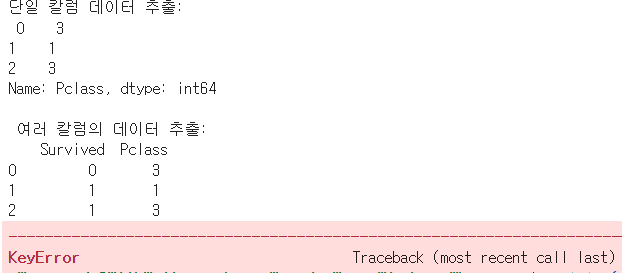
[ ]내에 숫자인 0이 칼럼명이 아니기 때문에 오류를 발생한다
그러나 인덱스 형태로 변환 가능한 표현식은 [ ]내에 입력할 수 있다
titanic_df[0:2] 와 같은 슬라이싱을 이용하면 원하는 결과를 반환한다

불린 인덱싱 표현도 가능하다
titanic_df[titanic_df['Pclass'] ==3].head(3)

iloc[ ] 연산자
- iloc[ ]는 위치 기반 인덱싱 방식으로 동작한다
- iloc[ ]는 위치 기반 인덱싱만 허용하기 때문에 행과 열의 좌표 위치에 해당하는 값으로 정수값 또는 정수형 슬라이싱, 팬시 리스트 값을 입력해줘야 한다
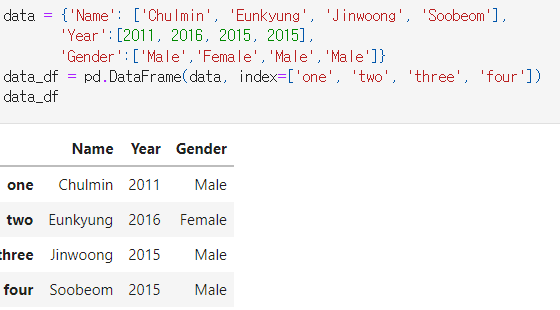
위와 같은 DataFrame에서 data_df.iloc[0, 0]은 위치 기반으로
Chulmin을 반환한다
- iloc[ ] 연산자 내에 위치 정숫값 및 위치 정수 슬라이싱을 이용해 다양하게 데이터를 추출 할 수 있다
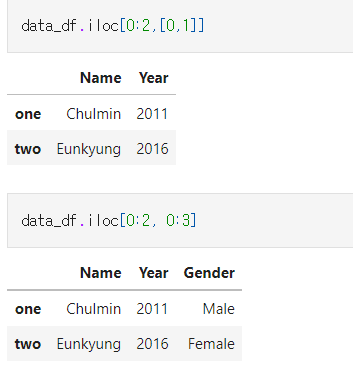
- iloc[ ]은 열 위치에 -1을 입력하여 마지막 열 데이터를 가져오는데 유용하다
머신러닝 학습 데이터의 맨 마지막 칼럼이 타깃 값인 경우가 많은데 이 경우iloc[:, -1]을 하게 되면 맨 마지막 칼럼(타깃 값)을 가져오고,
iloc[:, :-1]을 하면 처음부터 마지막 칼럼을 제외한 칼럼의 값을 가져온다 - iloc[ ]은 불린 인덱싱은 제공하지 않는다
loc[ ] 연산자
- loc[ ]은 명칭(label) 기반으로 데이터를 추출한다
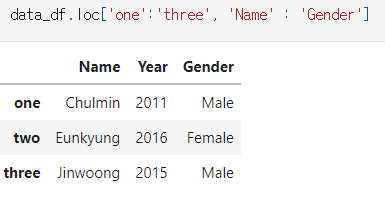
data_df.loc['one', 'Name'] -> Chulmin을 반환함
- loc[ ]에 슬라이싱 기호 : 를 적용할 때 유의할 점은 종료값까지 포함한다
예를들어 0:3은 3까지 인덱스 를 포함한다
불린 인덱싱
- 불린 인덱싱은 매우 편리한 데이터 필터링 방식
- iloc, loc와 같이 명확히 인덱싱을 지정하는 방식보다 불린 인덱싱에 의존해 데이터를 가져오는 경우가 많다
- [], loc[]은 지원하지만, iloc[]은 지원되지 않는다
titanic_df = pd.read_csv('titanic_train.csv')
titanic_boolean = titanic_df[titanic_df['Age'] > 60]
print(type(titanic_boolean))
titanic_boolean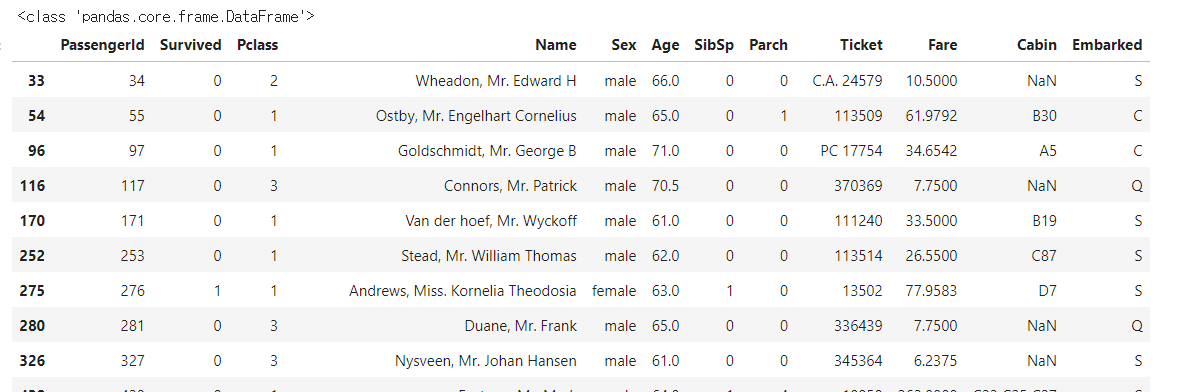
titanic_df[titanic_df['Age'] > 60] 는 DataFrame의 'Age'칼럼 값이 60보다 큰 데이터를 모두 반환한다

위와 같이 복합 조건 연산자로 데이터를 추출 가능하다
cond1 = titanic_df['Age'] > 60
cond2 = titanic_df['Pclass'] == 1
cond3 = titanic_df['Sex'] == 'female'
titanic_df[cond1 & cond2 & cond3]
변수를 할당하고 변수를 결합해서 불린 인덱싱을 수행 할 수 있다
정렬
- DataFrame과 Series를 정렬하기 위해서 sort_values( ) 메소드를 이용한다
- sort_values( )의 주요 파라미터는 by, ascending, inplace이다
- by로 특정 칼럼을 입력하면 해당 칼럼으로 정렬을 수행한다
- ascending=True로 설정하면 오름차순으로 정렬, False로 설정하면 내림차순으로 정렬한다
디폴트는 True 이다 - inplace=False로 설정하면 호출한 DataFrame은 그대로 유지하고 정렬된 DataFrame을 반환한다 True로 설정하면 호출한 DataFrame의 정렬 결과를 그대로 적용한다
디폴트는 False 이다
titanic_sorted = titanic_df.sort_values(by=['Name'])
titanic_sorted.head(3)위의 코드는 Name칼럼을 오름차순 정렬해 반환한다

- 여러 개의 칼럼으로 정렬하려면 by에 리스트 형식으로 정렬하려는 칼럼을 만든다
titanic_sorted = titanic_df.sort_values(by=['Pclass', 'Name'], ascending=False)
titanic_sorted.head(3)
Aggregation 함수
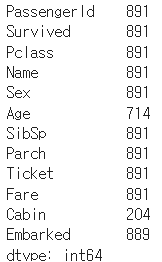
- DataFrame에서 min(), max(), sum(), count()와 같은 aggregation 함수를 적용할 수 있다
titanic_df.count()
count( )함수는 Null값을 반영하지 않은 결과를 반환한다
특정 칼럼에 aggregation함수를 적용 할 수 있다
titanic_df[['Age', 'Fare']].mean()

groupby( )
- DataFrame의 groupby()는 입력 파라미터에 by 칼럼에 칼럼을 입력하면 대상 칼럼으로 groupby 된다
groupby(by='Pclass')를 호출하면 Pclass 칼럼 기준으로 Groupby 된 DataFrame Groupby 객체를 반환한다
titanic_groupby = titanic_df.groupby('Pclass').count()
titanic_groupby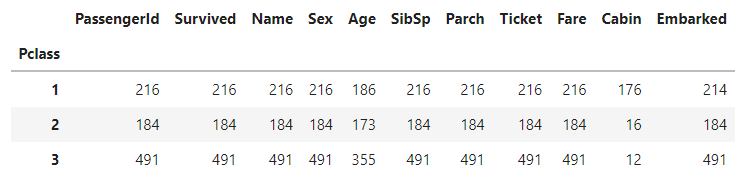
- DataFrame groupby( )에 서로 다른 aggregation함수를 적용할 경우
DataFrameGroupby객체에 agg( ) 함수 내에 인자로 입력해서 사용한다
titanic_df.groupby('Pclass')['Age'].agg([max, min])
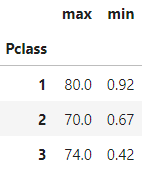
- agg( ) 내에 입력값으로 딕셔너리 형태로 aggregation이 적용될 칼럼들과 aggregation 함수를 입력하여 사용할 수 있다
agg_format={'Age':'max', 'SibSp':'sum', 'Fare':'mean'}
titanic_df.groupby('Pclass').agg(agg_format)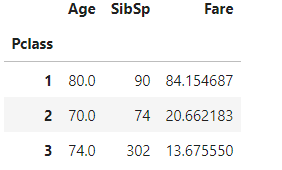
결손 데이터 처리
-
머신러닝 알고리즘은 NaN값을 처리하지 않으므로 이 값을 다른 값으로 대체해야한다
-
NaN 값은 평균, 총합 등의 함수 연산 시 제외가 된다
-
NaN 여부를 확인하는 API는 isna( ) 이며, NaN 값을 다른 값으로 대체하는 API는 fillna( ) 이다
isna( )
titanic_df.isna().head(3)

isna( )를 수행하면 모든 칼럼의 값이 NaN인지 True나 False로 알려준다
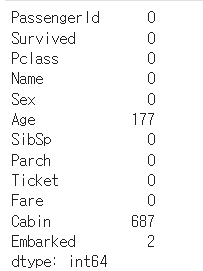
- 결손 데이터 개수는 isna( ) 결과에 sum( )을 결합해 구할 수 있다
titanic_df.isna().sum()
fillna( )로 결손 데이터 처리
- fillna( )를 이용해 결손 데이터를 편리하게 다른 값으로 대체 할 수 있다
titanic_df['Cabin'] = titanic_df['Cabin'].fillna('C000')
titanic_df.head(3)
Cain칼럼의 NaN값을 C000으로 대체 한 것이다
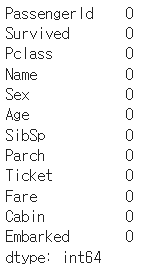
titanic_df['Age'] = titanic_df['Age'].fillna(titanic_df['Age'].mean())
titanic_df['Embarked'] = titanic_df['Embarked'].fillna('S')
titanic_df.isna().sum()Age칼럼의 NaN 값을 평균 나이로, Embarked 칼럼의 NaN값을 S로 대체 한 것이다
apply함수로 lambda식 결합
- apply에 lambda 식을 적용해 데이터를 가공 할 수 있다
titanic_df['Name_len'] = titanic_df['Name'].apply(lambda x : len(x))
titanic_df[['Name', 'Name_len']].head(3)- lambda 식에서 if else 절을 이용해 가공 가능하다
titanic_df['Child_Adult'] = titanic_df['Age'].apply(lambda x : 'Child' if x <= 15 else 'Adult')
titanic_df[['Age', 'Child_Adult']].head(8)-
주의 할 점은 lambda식의 if절의 경우 if 식보다 반환값을 먼저 작성해 주어야 한다
-
lambda식은 if, else if, else와 같이 else if 는 제공하지 않는다 따라서 else 절을 ( )로 내포하여 ( ) 내에서 다시 if else를 적용해야 한다
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : 'Child' if x<=15 else ('Adult' if x<= 60 else 'Elderly'))
titanic_df['Age_cat'].value_counts()- else if 가 많이 나와야 하는 경우 별도의 함수를 만드는게 더 나을 수 있다
# 나이에 따라 세분화된 분류를 수행하는 함수 생성
def get_category(age):
cat = ''
if age <= 5:
cat = 'Baby'
elif age <= 12:
cat = 'Child'
elif age <= 18:
cat = 'Teenager'
elif age <=25:
cat = 'Student'
elif age <=35:
cat = 'Young Adult'
elif age <60:
cat = 'Adult'
else : cat = 'Elderly'
return cat
titanic_df['Age_cat'] = titanic_df['Age'].apply(lambda x : get_category(x))
titanic_df[['Age', 'Age_cat']].head()Reference 권철민, 파이썬 머신러닝 완벽 가이드, 위키북스2020
.jpg)