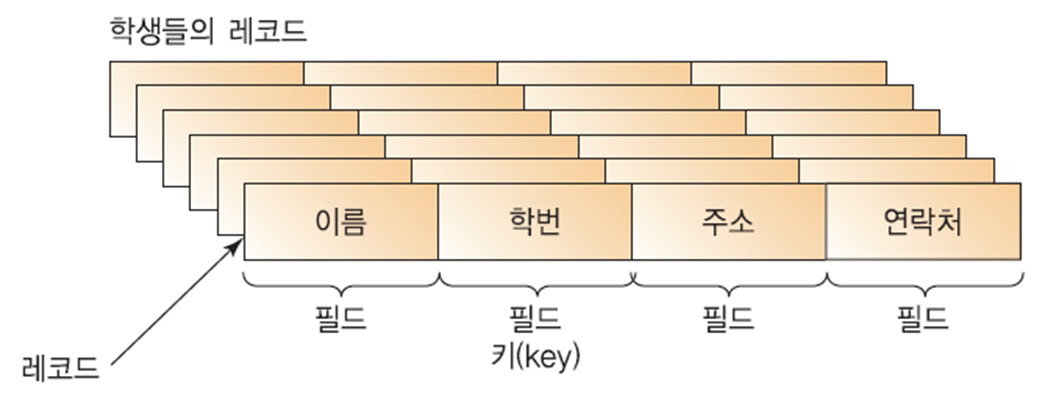
정렬
- 정렬해야할 대상을 레코드(record)라 한다
- 레코드는 필드(field)라는 단위로 다시 나뉜다
- 여러 필드 중에서 레코드와 레코드를 구별시켜주는역할을 하는 필드를 키(key)라고 한다.
결국 정렬은 레코드의 키값의 순서로 재배열하는것
기본정렬알고리즘(단순하지만 비효율적)
- 삽입 정렬
- 선택 정렬
- 버블 정렬 등
복잡하지만 효율적인 방법
- 퀵 정렬
- 힙 정렬
- 합병 정렬
- 기수 정렬 등
정렬 알고리즘의 안정성
- 동일한 키 값을 갖는 레코드들이 정렬후에도 상대적인 위치가 바뀌지 않아야 안정하다
선택 정렬(selection sort)
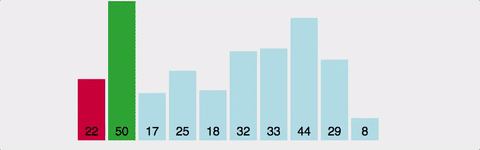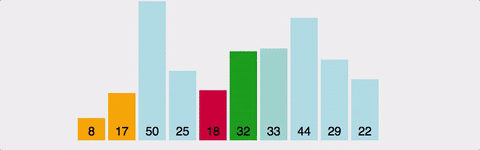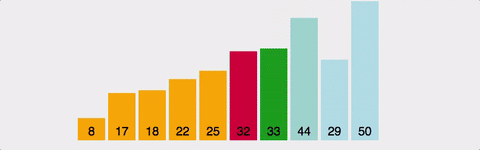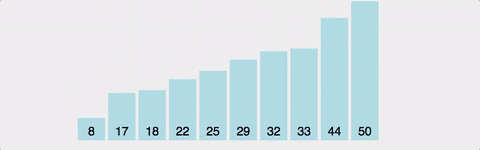
- 정렬안된 리스트에서 작은 키값부터 다른 리스트에 순서대로 정렬하는 방법

제자리 정렬
- 추가로 리스트를 사용하지 않고 리스트 내부에서 정렬을 수행하는 방법
#define SWAP(x, y, t) ( (t)=(x), (x)=(y), (y)=(t) )
void selection_sort(int list[], int n)
{ int i, j, least, temp;
for(i=0; i<n-1; i++) {
least = i;
for(j=i+1; j<n; j++) // 최소값 탐색
if(list[j]<list[least]) least = j;
SWAP(list[i], list[least], temp);
}
}i가 n-1까지인 이유는 마지막 인덱스는 어차피 최대값이니 정렬할 필요가 없다
시간복잡도
- 비교를 n-1 + n-2 + ... +1 만큼 수행((n-1)*n/2), 교환은 3(n-1)만큼 수행하므로
시간복잡도는 O(n^2)
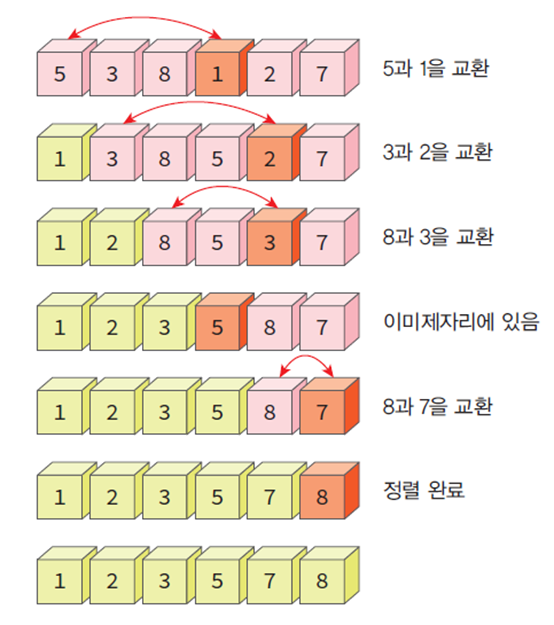
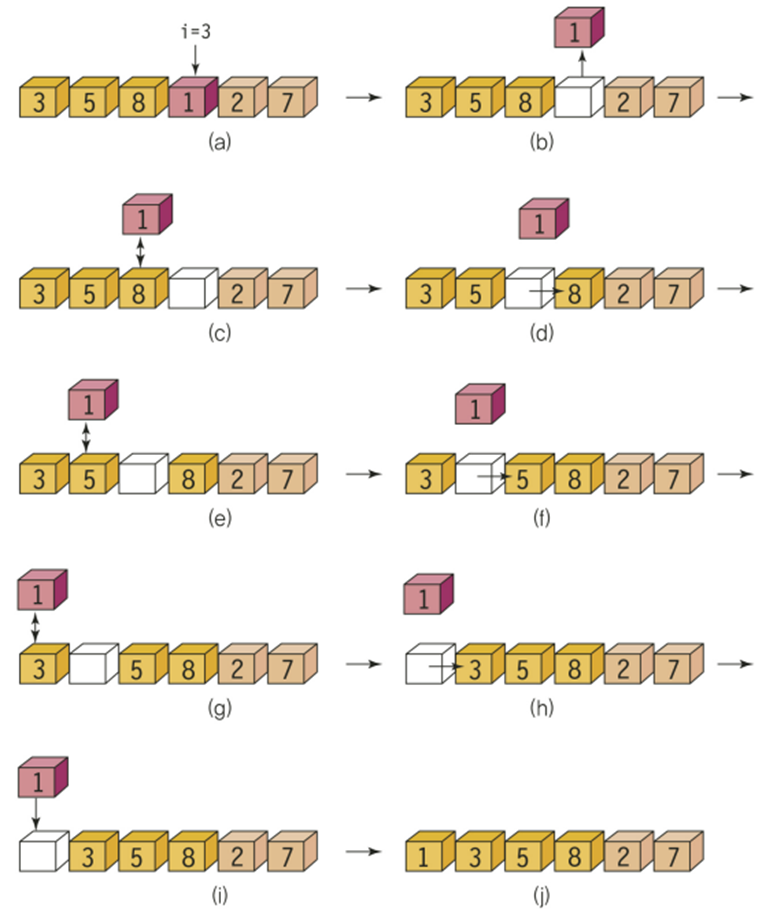
삽입 정렬(insertion sort)
- 정렬되어 있는 부분에 새로운 레코드를 올바른 위치에 삽입한다(제자리 정렬한다)
Code
void insertion_sort(int list[], int n)
{
int i, j, key;
for(i=1; i<n; i++){
key = list[i];
for(j=i-1; j>=0 && list[j]>key; j--)
list[j+1] = list[j]; // 레코드의 오른쪽 이동
list[j+1] = key;
}
}인덱스i=1부터인 이유는 0번째 인덱스는 정렬된것으로 보기 때문
시간복잡도
- 삽입정렬은 어느정도 정렬이 되어 있을 경우 매우 효율적이다.
- 인덱스를 교환하는 연산이 없으므로 안정적이다.
비교->n-1 + n+ ...+1 -> n/(n-1)/2
이동->n^2
O(n^2)
버블정렬(bubble sort)

- 인접한 2개의 레코드를 비교하여 순서대로 되어 있지 않으면 교환하는 정렬방법이다
- 레코드의 이동과정이 물속에서 거품이 보글보글 떠오르는것과 유하사여 버블정렬이라 부른다(exchange sort라고도 부른다)

Code
#define SWAP(x, y, t) ( (t)=(x), (x)=(y), (y)=(t) )
void bubble_sort(int list[], int n)
{ int i, j, temp;
for(i=n-1; i>0; i--){
for(j=0; j<i; j++) // 앞뒤의 레코드를 비교한 후 교체
if(list[j]>list[j+1])
SWAP(list[j], list[j+1], temp);
}
}시간복잡도
- 최선, 평균, 최악의 경우에서 모두 일정한 시간복잡도를 보인다
- O(n^2)
셸정렬(Shell sort)
- 셸 정렬은 Donald L.Shel이라는 사람이 제안한 방법으로 삽입정렬이 어느정도 정렬된 배열에서 대단히 빠른 것에 착안한 방법이다.
- 전체 리스트를 일정 간격(gap)의 부분 리스트로 나눈다
- 나뉘어진 각각의 부분 리스트를 삽입정렬 한다
- 간격을 줄인다->각 부분리스트의 크기는 커지고, 부분 리스트의 수는 더 작아진다
- 간격이 1이 될때까지 반복

간격 5 -> 간격 3 -> 간격 1로 부분 리스트 정렬 수행한것임
간격(gab) 이 1이면 삽입정렬과 어차피 같아지지만 셸정렬을 하면 어느정도 정렬이 되므로 경제적
Code
inc_insertion_sort(int list[], int first, int last, int gap)
{
int i, j, key;
for(i=first+gap; i<=last; i=i+gap){
key = list[i];
for(j=i-gap; j>=first && key<list[j];j=j-gap)
list[j+gap]=list[j];
list[j+gap]=key;
}
}
//
void shell_sort( int list[], int n ) // n = size
{
int i, gap;
for (gap=1; gap<=n/9; gap=3*gap+1); //부분리스트의 크기는 9보다 큰 수부터 시작
while (gap>0) {
for(i=0;i<gap;i++) // 부분 리스트의 개수는 gap: n/9 보다 큼
inc_insertion_sort(list, i, n-1, gap);
gap /= 3;
}
}시간복잡도
- 셸 정렬은 삽입정렬에 비해 원거리 자료 이동으로 적은 위치교환으로 경제적이다
최악의 경우 O(n^2)
평균의 경우 O(n^1.5)
합병정렬(Merge Sort)
- 분할 정복(divide and conquer)방법 사용
- 문제의 크기를 분할 후 정렬-> 각각의 문제를 다시결합

- 문제의 크기를 분할 후 정렬-> 각각의 문제를 다시결합
합병 알고리즘

- 합병(merge)의 경우 추가적으로 배열의 할당이 필요하다
- 합병 알고리즘은 두 개의 리스트 요소 중에서 더 작은 요소를 새로운 리스트에 옮긴다-> 옮겨진 리스트의 인덱스는 하나 증가한다->다시 두 리스트의 인덱스 비교를 반복...
- 둘 중 하나의 리스트가 먼저 끝나면 나머지 리스트의 요소들을 새로운 리스트로 복사한다
Code
void merge(int list[], int left, int mid, int right)
{
int i, j, k, l;
i=left; j=mid+1; k=left;
// 분할 정렬된 list의 합병
while(i<=mid && j<=right){
if(list[i]<=list[j]) sorted[k++] = list[i++];
else sorted[k++] = list[j++];
}
if(i>mid) // 남아 있는 레코드의 일괄 복사
for(l=j; l<=right; l++)
sorted[k++] = list[l];
else // 남아 있는 레코드의 일괄 복사
for(l=i; l<=mid; l++)
sorted[k++] = list[l];
// 배열 sorted[]의 리스트를 배열 list[]로 복사
for(l=left; l<=right; l++)
list[l] = sorted[l];
}합병정렬 순환 알고리즘
void merge_sort(int list[], int left, int right)
{
int mid;
if(left<right)
{
mid = (left+right)/2; // 리스트의 균등 분할
merge_sort(list, left, mid); // 부분리스트 정렬
merge_sort(list, mid+1, right);//부분리스트 정렬
merge(list, left, mid, right); // 합병
}
}시간복잡도
- 안정적이며 최적, 평균, 최악의 경우 큰 차이 없이 일정한 복잡도를 보인다
- 크기가 n인ㄴ 리스트를 균등 분배하므로 logn, n개의 레코드를 비교하므로 n
- 이동의 문제는 레코드의 포인터만 바꾸면 되므로 무시할만 하다
- O(nlogn)
퀵 정렬
- 평균적으로 가장 빠른 정렬 방법이다
- 분할 정복법을 사용한다
- 리스트를 2개의 부분 리스트로 비균등분할(리스트의 크기가 다를수 있음)하고
각각의 부분 리스트를 다시 퀵정렬한다 - 피벗(pivot)을 기준으로 작으면 왼쪽 크면 오른쪽배열에 저장한다
퀵 정렬 알고리즘
void quick_sort(int list[], int left, int right)
{
if(left<right){
int q=partition(list, left, right);
quick_sort(list, left, q-1);
quick_sort(list, q+1, right);
}
}int q는 partition함수에 의해 받는 피폿의 인덱스 값이다
분할(partiton)
피벗(pivot): 가장 왼쪽 숫자라고 가정
두개의 변수 low와 high를 사용한다.
low는 피벗보다 작으면 통과, 크거나 같으면 정지
high는 피벗보다 크면 통과, 작거나 같으면 정지
정지된 위치의 숫자를 교환
low와 high가 교차하면 종료
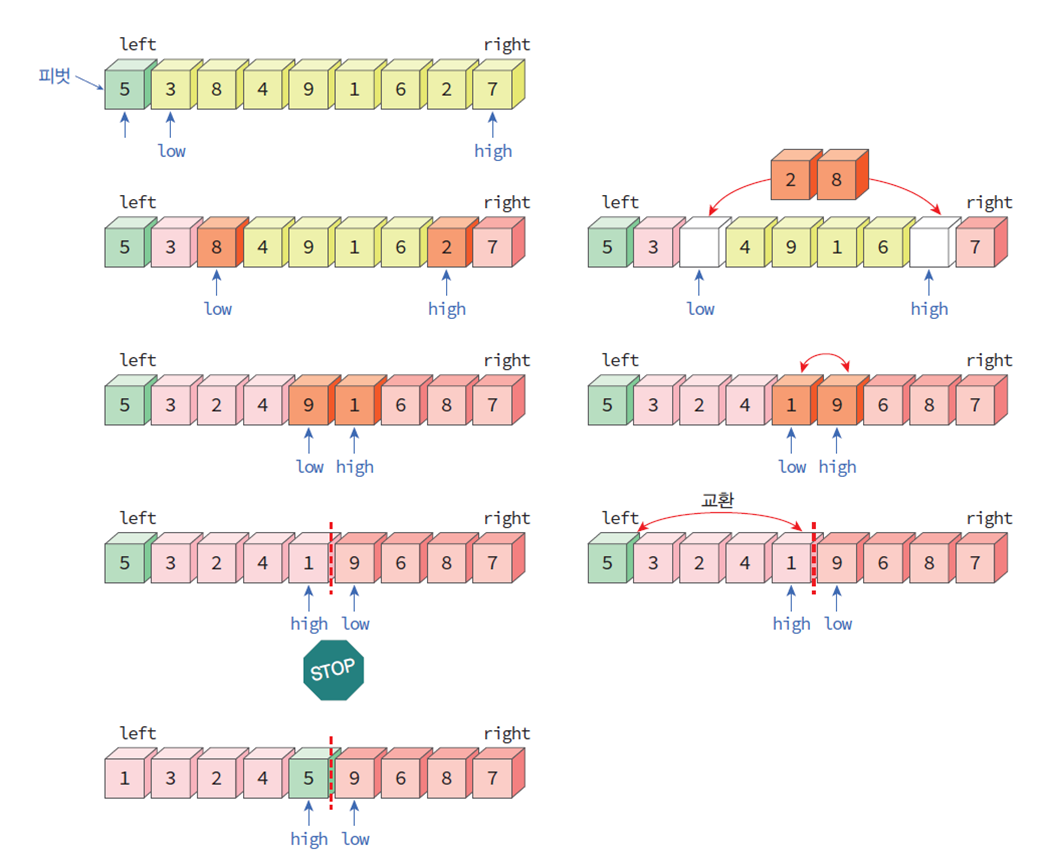
partition code
int partition(int list[], int left, int right)
{
int pivot, temp;
int low,high;
low = left;
high = right+1;
pivot = list[left];
do {
do
low++;
while(low<=right && list[low]<pivot);
do
high--;
while(high>=left && list[high]>pivot);
if(low<high) SWAP(list[low], list[high], temp);
} while(low<high);
SWAP(list[left], list[high], temp);
return high;
}
시간복잡도: O(nlogn)
그러나 최악의 경우(극도로 불균등한 리스트의 경우) O(n^2)->중앙값을 피벗으로 선택하면 불균등 분할 완화 가능하다
정렬 알고리즘 시간 복잡도 비교
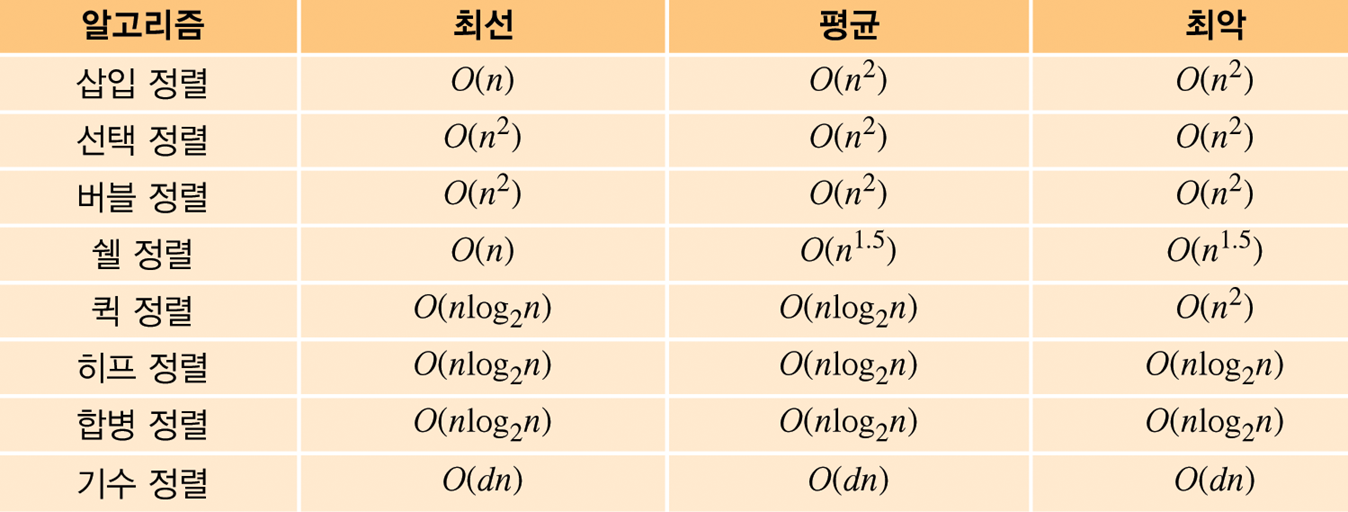
Reference (https://jbhs7014.tistory.com/180)
C언어로 쉽게 풀어 쓴 자료구조, 천인국, 공용해, 하상호_2019
상명대학교 홍철의 교수님 강의자료
.jpg)