
Stack
Data Structure
자료 구조는 복수의 자료를 관리하고 저장하는 데 효율적인 형태와 사용법이다. 컴퓨터 메모리에 자료가 어떻게 저장되는지보다 자료를 어떻게 관리하는지를 중점적으로 연구한 것이다.
배열을 만들고 배열의 끝 부분을 가리키는 top이 있으면 Stack이라고 모양을 중심으로 설명하는 것이 아니라, 가장 나중에 넣은 자료가 먼저 나오도록 만드는 것이 Stack이라고 사용 중심적으로 설명해야 한다.
Interface보다 Implementation을 기준으로 말하는 것이다.
Stack
Stack은 물건을 쌓아 올린 형태의 자료 구조이다. 쌓아 있는 종이컵을 생각해 보면 쌓인 컵 전체를 옮기거나 뒤집지 않는 이상 새로운 컵은 가장 위에만 쌓을 수 있고, 꺼낼 때도 위에 있는 컵부터 꺼낼 수 있다. 이처럼 Stack은 후입선출인 (LIFO, Last In First Out) 구조를 가지고 있는 선형 자료 구조이다. Stack의 다음 기능은 아래와 같다.
- push(): 데이터를 추가
- pop(): 데이터 회수
- isEmpty(): 비어 있는지 확인
- isFull(): 가득 차 있는지 확인 (고정된 배열을 사용하는 경우)
- peek(): 제일 위의 데이터 확인
배열을 사용해서 만들 경우 Stack을 구현할 때 고려해야 할 점을 생각해 보자.
- 가장 꼭대기를 표시할 index인 top이 필요
- push(): top의 크기 증가 후 arr[top]에 할당
- pop(): arr[top] 반환 후 top 크기 감소
- isEmpty(): top == -1?
- isFull(): top == maxVal?
- peek(): arr[top] 반환
Stack with JAVA
Stack 클래스를 만들고 멤버 변수로 top과 arr를 선언해 준다. 배열 같은 경우는 변수값이 배열이 어디에서 시작하는가를 지시하고 있기 때문에 배열을 수정하는 데는 아무 영향을 주지 않는다. 따라서 final 키워드를 선언해 준다.
public class Stack {
private int top;
private final int[] arr = new int[16];
}이후 생성자를 통해 top의 값을 추가하고 push 를 구현하면 다음과 같다.
public class Stack {
private int top;
private final int[] arr = new int[16];
public Stack(){
top = -1;
}
// push: 데이터를 스택 제일 위에 넣는 method
public void push(int data) {
top++;
arr[top] = data;
}
}이후 push, isEmpty, isFull, peek까지 구현해 준다.
public class Stack {
private int top;
private final int[] arr = new int[16];
public Stack(){
top = -1;
}
// push: 데이터를 스택 제일 위에 넣는 method
public void push(int data) {
if(arr.length - 1 == top) {
throw new RuntimeException("stack is full");
}
else {
top++;
arr[top] = data;
}
}
// pop: 데이터를 스택 위에서 하나 삭제하는 mtehod
public int pop() {
if (arr.length == 0) {
throw new RuntimeException("stack is empty");
}
else {
return arr[top--];
}
}
// isEmpty: 스택이 비어 있는지를
public boolean isEmpty() {
return (arr.length == 0);
}
// isFull: 스택이 가득 차 있는지를
public boolean isFull() {
return (arr.length == 16);
}
// peek: 가장 위에 있는 데이터 반환
public int peek() {
return arr[top];
}
}이러한 Stack 구조는 함수를 관리할 때도 사용한다. 이를 Call Stack이라고 한다. 프로그램에서 함수를 호출할 때 Stack 구조를 활용해서 함를 쌓아 둔 뒤 가장 위에 있는 함수부터 꺼내서 처리하게 된다.
Stack Overflow
재귀적 함수 호출로 인해 Call Stack의 최상단이 JVM의 Heap에 도달할 때 발생하는 에러이다. 접시를 쌓다가 천장에 닿은 상태로 Java 말고도 다른 언어에서도 발생한다.
이렇듯 한계점이 있는 Stack은 메모리를 효율적으로 사용하지 못한다는 단점이 있기 때문에 실무에서는 배열의 크기 조절이 자유로운 구조를 사용하는 것이 더욱 효과적일 때도 있다.
괄호 검사
문자열의 문자를 하나씩 조사해서 여는 괄호를 만나게 될 경우 스택에 삽입하고 닫는 괄호를 만나게 될 경우 pop을 실행해서 괄호의 짝이 완벽하게 맞춰져 있는지 검사할 수 있다. 앞 과정을 모두 반복했을 때 스택이 비어 있지 않으면 실패지만 스택이 비어 있는 경우 짝이 맞는 괄호이기 때문이다.
입력으로 (()(())) 문자열을 주면 다음과 같이 작동한다.
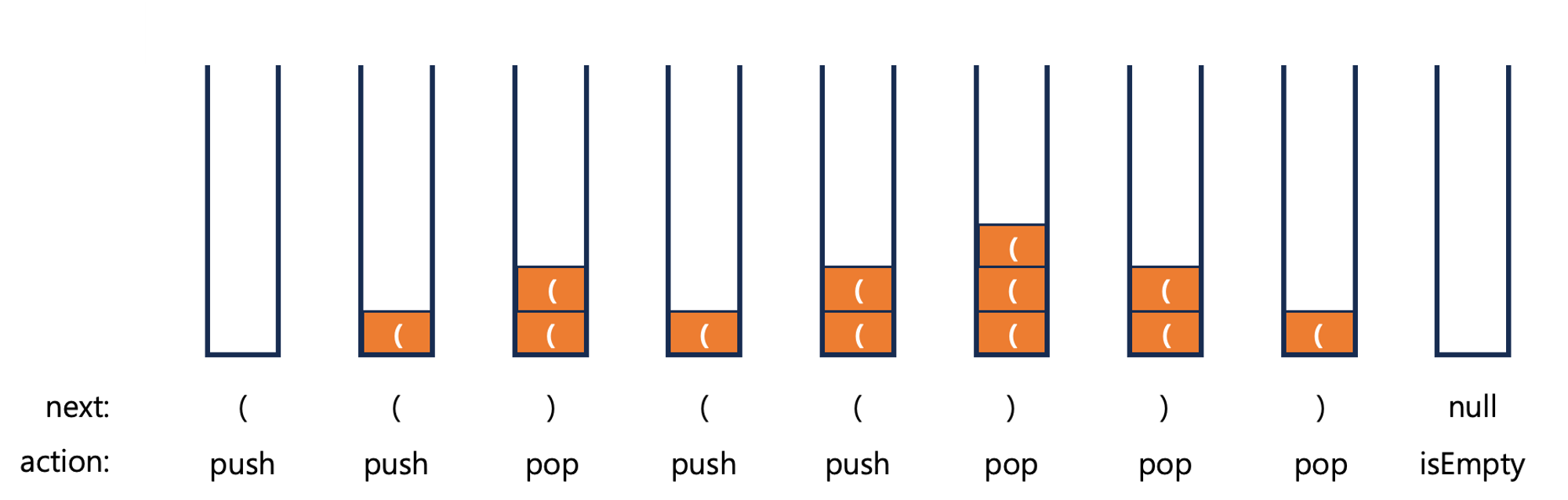
이를 코드로 구현하면 다음과 같다. 앞서 짠 Stack이 아닌 자바에서 제공해 주는 Stack을 이용한다.
public class ParTest {
public boolean solution() throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String input = br.readLine();
Stack<Character> charStack = new Stack<>();
// 문자열 길이만큼 순회
for (int i = 0; i < input.length(); i++) {
char next = input.charAt(i);
// 여는 괄호를 만날 때
if(next == '(') {
charStack.push(next);
}
// 닫는 괄호를 만날 때
else if (next == ')') {
// pop 할 게 없다면 검사 실패
if (charStack.isEmpty()) return false;
// 아니라면 pop
char top = charStack.pop();
if (top != '(') return false;
}
}
if (charStack.isEmpty()) {
return true;
}
return false;
}
public static void main(String[] args) throws IOException {
System.out.println((new ParTest()).solution());
}
}이를 변형해서 중괄호 대괄호까지 있는 경우를 생각하면 다음과 같이 작성할 수 있다.
public class ParTest2 {
public boolean solution() throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String input = br.readLine();
// 검사를 위해 필요한 Stack 정의
Stack<Character> charStack = new Stack<>();
// 문자열 길이만큼 순회
for (int i = 0; i < input.length(); i++) {
char next = input.charAt(i);
// 어차피 괄호는 대 -> 중 -> 소 순서로 열리고 stack에서 꺼내기 때문에 소 -> 중 -> 대 순서로 닫히는지 확인 가능
// 무엇이든 여는 괄호라면 스택에 넣기
if (next == '(' || next == '{' || next == '[') charStack.push(next);
// 닫는 괄호를 만났을 때
else {
// pop 할 게 없으면
if (charStack.isEmpty()) return false;
// 아니라면
char top = charStack.pop();
// 들어온 건 닫는 소괄호 && 열린 건 소괄호가 아닐 때 실패
if(next == ')' && top != '(') return false;
// 들어온 건 닫는 중괄호 && 열린 건 중괄호가 아닐 때 실패
else if (next == '}' && top != '{') return false;
// 들어온 건 닫는 대괄호 && 열린 건 대괄호가 아닐 때 실패
else if (next == ']' && top != '[') return false;
}
}
// 순회 이후 스택이 비었는지 확인
if(charStack.isEmpty()) return true;
// 아니라면 false 반환
return false;
}
public static void main(String[] args) throws IOException {
System.out.println(new ParTest2().solution());
}
}DataBase
Lombok
Spring에서 lombok dependency도 추가해서 새 프로젝트를 생성한다.
Dto가 하나 있을 때, private인 멤버에 접근하기 위해서 Getter/Setter 와 Constructor 그리고 스트링으로 바꿔 주는 toString, 값이 같은지 알려 주는 equals 등을 직접 구현해 줘야 한다.
이 기능을 제공해 주는 Annotation 기반의 Library가 Lombok이다. 아래처럼 @AllArgsConstructor annotation을 사용하면 어떤 파라미터에 대해서든 생성자를 제공해 주기 때문에 다음과 같이 쓸 수 있다. 컴파일하는 단계에서 annotation이 사라지면서 모든 멤버에 대한 생성자를 만들어 준다.
import lombok.AllArgsConstructor;
@AllArgsConstructor
public class StudentDto {
private Long id;
private String name;
private String email;
}@SpringBootApplication
public class LombokApplication {
public static void main(String[] args) {
//SpringApplication.run(LombokApplication.class, args);
StudentDto dto = new StudentDto(1L, "huisu", "huisu@gmail.com");
}
}lomkob의 dependency를 보면 다음과 같이 Compile Only라고 되어 있다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}Lombok은 annotation 표시가 되어 있는 기능만 바이트 코드로 추가해 주기 때문에 컴파일에만 필요하다.
Database
data는 컴퓨터에 저장되어 처리에 효율적인 형태로 변환된 자료 정보이다. 가장 많이 쓰니는 형태는 관계형 데이터베이스이다. 데이터를 관계로 표현한 데이터베이스이고, 역사적으로 가장 많이 활발하게 활용되는 케이스이다.
이 관계형 데이터베이스를 다루기 위한 프로그램을 RDBMS (Relatoinal DataBase Manageent System) 이라고 한다. 서버의 형태로 프로그램과 소통하여 데이터베이스를 조작할 수 있게 해 주는 경우가 많다. RDBMS는 정확한 원천 기술이 아니고 만들어진 제품에 따라 그 사용법이 조금 다를 수 있다.
관계형 데이터베이스는 데이터를 테이블, 행,열 등으로 나눠 구조화해서 체계적으로 관리한다. 자료를 여러 테이블에 나눠서 관리하고 테이블들 간에 관계를 설정한다. 데이터 무결성 유지에 유리하며 SQL문을 사용해서 조작할 수 있다.
Schema: 관계형 데이터베이스가 가진 데이터의 구조를 표현한 것으로 기본적인 데이터베이스 자료의 구조와 표현 방법을 명세하고 있다.Table: 필드와 레코드를 사용해 조작된 데이터 요소들의 집합이다.Column: 속성 또는 칼럼이다.Record: 데이터 하나의 기록을 말한다.Primary Key: 기본키라고 부르며 각 레코드의 고유한 값이다. 따라서 기술적으로 다른 항목과 중복이 불가능하고, 데이터베이스 관리와 테이블 간 관계 설정에 유용하게 사용된다.Fireign Key: 한 테이블의 데이터를 표현할 때 다른 테이블의 데이터가 필요한 경우 해당 테이블의 PK를 다른 테이블에 저장해서 사용하는 경우이다.
SQL
Structured Query Language로 관계형 데이터베이스에서 데이터를 관리하기 위해 사용하는 언어로 쉽게 말해 데이터베이스의 CRUD용 언어이다.
- DDL: Data Definition Language로 데이터의 모습을 정의하기 위한 명령이다.
- DML: Data Manipulation Language로 데이터 조작을 위한 명령이다.
- DCL: Data Control Language 데이터 접근 권한 관련 명령이다.
SQL은 SELECT, INSERT 등의 키워드로 시작하며 독립적으로 실행할 수 있는 완전한 코드 조각을 Statement라고 하고, Statement를 이루는 작은 단위를 Clause라고 한다.
SQL DDL
intelliJ에서 DB 사용할 수 있도록 준비를 완료해 준다. 이후 sql 문으로 테이블을 만들고 데이터를 넣어 준다.
이후 전체 선택 후 시행하면 데이터가 무사히 삽입된다.
cmd + A → cmd + Enter
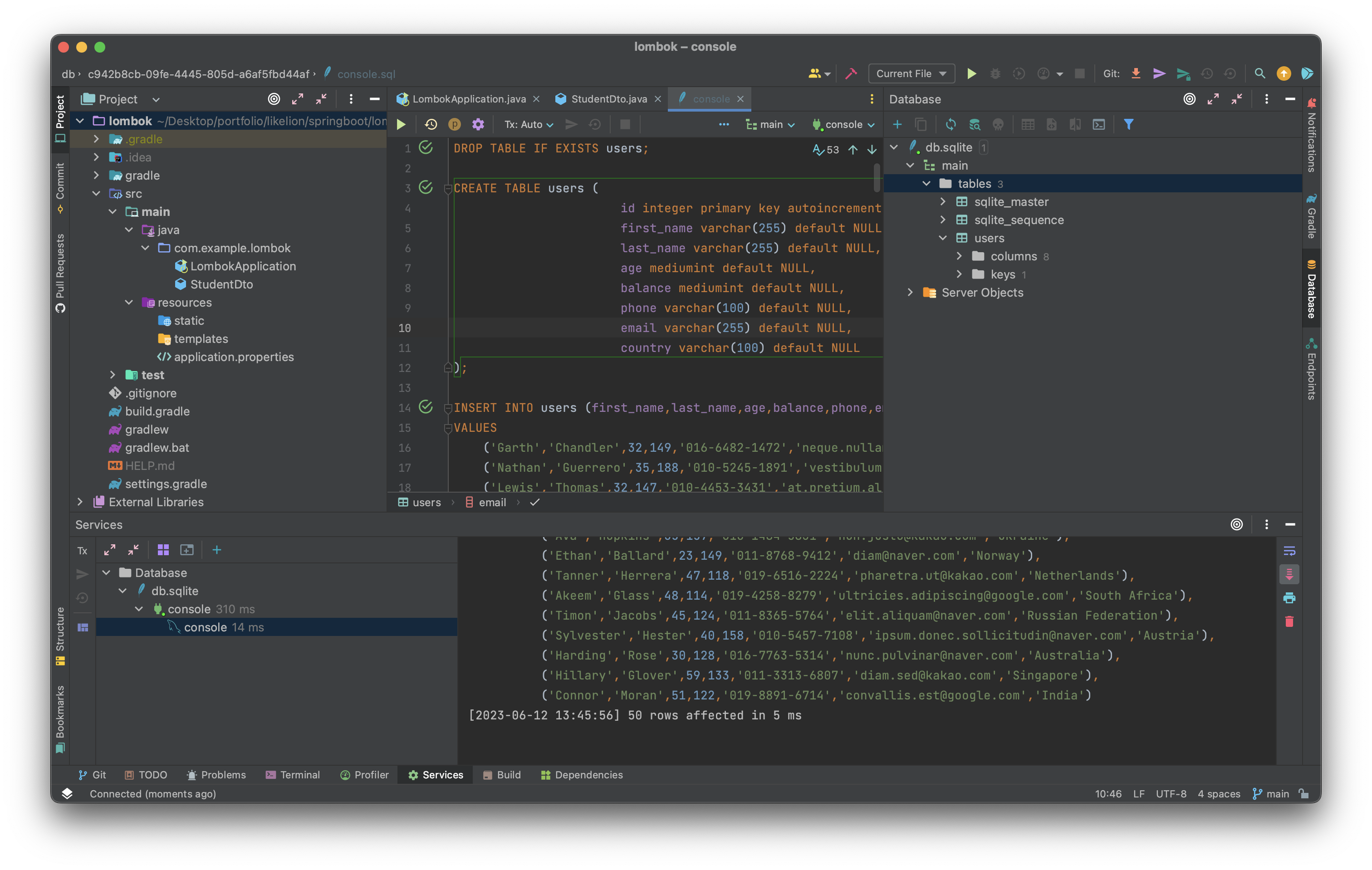
이후 1_ddl.sql 파일을 새로 생성한 뒤 프로젝트에서는 SQLite를 쓰겠다는 의미로 SQL dialect를 설정해 준다.

위에서 만든 Student Dto를 구현하기 위한 테이블을 만드는 SQL 구문은 다음과 같다.
create table students (
id integer,
name varchar(32),
email text
);CREATE TABLE
컬럼의 타입은 매우 상세하게 들어가면 제품마다 다르다. VARCHAR, NVARCHAR, TEXT의 구분 등이 그렇다. SQLite 기준으로는 다섯 개로 표현이 가능하다.
- NULL: 정보가 없는 데이터
- INTEGER: 정수형 데이터
- REAL: 실수형 데이터
- TEXT: 문자형 데이터
- BLOB: Binary Large Object
데이터 무결성과 Table Constraints
데이터가 생성되고 조회되괴 수정되고 삭제될 때 우리의 데이터가 항상 정확하고 일관성 있게 데이터 무결성을 지킬 수 있도록 설계하는 것도 중요하다. 회원 정보에서 아이디가 비어 있으면 안 되고, 계좌 정보에서는 계좌 번호가 비어 있으면 안 되고, 배달 정보에서는 배달 주소가 없으면 안 된다. 따라서 무결성을 유지하기 위해 테이블 컬럼에 들어올 수 있는 데이터를 제한시키거나 제약하는 것을 Constraints라고 한다.
- NOT NULL
- UNIQUE
- PRIMARY KEY
- AUTOINCREMENT
