ZeroR : 최소 이정도보다 나아야 된다. ex) 어느 지역에서는 매일 비가 와서. 내일 비올 확률 85퍼라고 하면 거의 다 맞음
로지스틱 회귀
선형회귀와의 비교
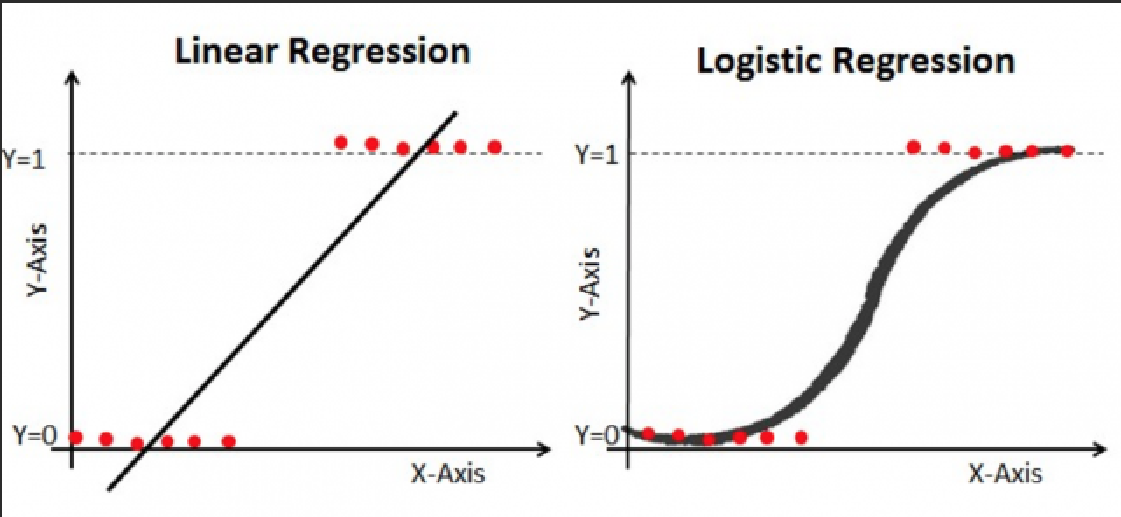
공통점
- 예측 변수(독립 변수)와 결과 변수(종속 변수) 사이의 관계를 모델링
선형회귀
-
결과 변수가 연속적일때 사용.
-
특정 범위 내 모든 값을 가질 수 있음. ex) 온도, 주택가격
-
예측 변수와 결과 변수 사이의 선형 관계를 모델링 해 가장 적합한 선을 찾는것
-
연속 결과 변수와 예측 변수 사이의 선형 관계를 모델링
로지스틱 회귀
-
결과 변수가 이항 또는 범주형일 때 사용 ex) 성공/실패, 존재/부재
-
예측 변수에서 범주 중 하나에 속하는 결과 변수의 확률을 모델링
-
예측 변수가 주어진 이진 결과 변수 모델링
softmax 함수
- 실수 벡터를 확률 분포로 변환하는 데 도움
로지스틱 회귀 순서
1. 데이터 획득
b_cancer = load_breast_cancer()
# sklearn.datasets 에서 얻어옴2. 데이터 탐색
2-1 다루기 쉽게 dataFrame 으로 받기
b_cancer_df= pd.DataFrame(b_cancer.data, columns = b_cancer.feature_names)
# 참고) pd.DataFrame(data, index, columns,dtype,copy)
index = 행
columns = 열
dtype = 전체 데이터 프레임의 데이터 유형 강제
copy = df 를 생성할때 데이터를 복사할지 여부
2-2 target 받기
b_cancer_df['diagnosis']= b_cancer.targettarget 을 사용하는 이유
-
target 값을 포함하지 않으면 분석하고 싶은 값[ex)진단] 에 대한 중요한 정보가 누락되어
의미 있는 인사이트를 도출하거나 데이터 집합을 기반으로 예측 모델을 구축하기가 어려워집니다. -
또 대부분의 dataSet 에 target값이 이미 있음.
이걸 꺼내서 받아주는것
3. 전처리
-
데이터 세트의 기능 또는 변수 범위를 표준화하는 데 사용되는 사전 처리 기술
=> 모든 기능이 유사한 척도를 갖도록 보장. -
cf) scale은 측정값을 동일한 단위로 변환하는 것과 비슷.
예를들면, 박스 길이 측정하는데 길이는 미터로, 넓이는 센치미터로 측정하면 데이터 비교하기 어려운느낌! -
입력 값 범위에 민감한 많은 기계 학습 알고리즘에 유용하게 쓰임.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() # scaler 생성
b_cancer_scaled = scaler.fit_transform(b_cancer.data) # input 값을 scale 한다
print (b_cancer_scaled)standardScaler
- 스케일이 다른 기능이 있는 데이터를 처리할 때 유용한 전처리 단계
- 입력 기능을 조정하고 중앙에 두어 평균 및 단위 분산이 0이 되도록 하여 많은 기계 학습 알고리즘의 성능을 향상
KDEplot
- 확률 밀도 함수를 추정.
=> 간격, 다중모드 및 비정규성과 같은 분포 패턴을 식별하는 데 특히 유용
- 유연성.
=> 광범위한 데이터 분석 작업에 유용 - 분포 비교.
=> 동일한 플롯에 여러 분포를 오버레이하여 여러 그룹 또는 하위 그룹의 분포를 쉽게 비교
4. 모델학습(로지스틱 회귀)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# X, Y 설정하기
Y = b_cancer_df['diagnosis']
X = b_cancer_scaled
4-2 훈련 데이터와 평가 데이터 분할
# 훈련용 데이터와 평가용 데이터 분할하기
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)4-3 로지스틱 회귀 분석
# (1)모델 생성
lr_b_cancer = LogisticRegression()
# (2)모델 훈련
lr_b_cancer.fit(X_train, Y_train)
5. 성능평가
# (3)평가 데이터에 대한 예측 수행 -> 예측 결과 Y_predict 구하기
Y_predict = lr_b_cancer.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score
# 혼돈행렬
print (confusion_matrix(Y_test, Y_predict))혼돈행렬
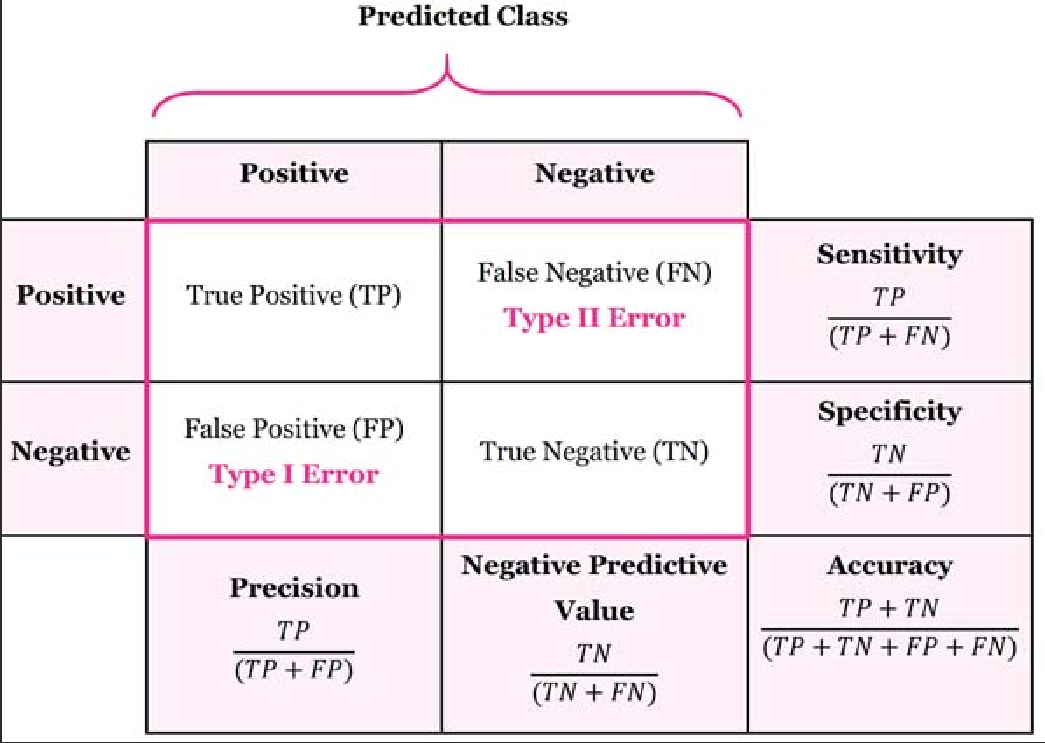
-
예측된 클래스와 실제 클래스를 비교하여 분류 모델의 성능을 평가
-
참 긍정(TP), 참 부정(TN), 거짓 긍정(FP) 및 거짓 부정(FN) 예측의 수를 나타내는 4개의 항목이 있는 행렬
-
진양성(TP): 모델에 의해 양성으로 올바르게 분류
-
True Negatives(TN): 모델에 의해 부정으로 올바르게 분류
-
False Positives(FP): 모델에 의해 양성으로 잘못 분류
-
False Negatives(FN): 모델에서 부정확하게 부정확하게 분류
정밀도(Precision)
-
양성이라고 판정한 것 중 진짜로 맞는 것 ex)진단키트를 돌렸는데 1000명중 100명만 진짜더라
-
긍정적인 인스턴스를 예측할 때 모델이 얼마나 정확한지 측정
-
진양성(TP)과 거짓양성(FP)의 합에 대한 진양성(TP)의 비율
precision = TP / (TP + FP) -
높은 정밀도는 모델이 양성 인스턴스를 예측할 때 매우 정확합니다.
TIP) 정확함이란?
-
얼마나 많은 것이 참인지 또는 올바른지 나타낸다.
-
ex) 특정이미지에 고양이가 포함되어 있다고 예측했는데 진짜 있으면 예측이 '정확'한것.
-
ex) 의료 진단 작업에서 '정확한' 모델은 매우 확신이 있을때에만 예측을함. => 일부 질병 사례를 놓칠 수 있음.
재현율(Recall) == 민감도(Sensitivity)
-
있는 양성을 찾아낸 비율
-
모델에 의해 올바르게 식별된 긍정적 인스턴스의 비율을 측정합니다.
-
높은 재현율은 대부분의 긍정적 인스턴스를 식별할 수 있음을 의미 => 긍정적 인스턴스를 식별할 때 모델이 매우 완전
-
진양성(TP)과 거짓음성(FN)의 합에 대한 진양성(TP)의 비율
recall = TP / (TP + FN) -
ex) 의료 작업에서 높은 재현율이 훨씬 중요.
일부 거짓 양성을 허용하더라도 모든 참 양성 사례를 식별
TIP) 완전함이란?
- 특정 클래스의 모든 인스턴스를 캡처하거나 식별하는 모델의 기능을 나타낸다.
- 긍정적 인스턴스의 비율을 측정합니다.
ex) 의료 진단 작업에서 '완전한' 모델은 특정 질병의 모든 인스턴스를 식별(if FT가 껴 있더라도)
정확도(Accuracy)
- 양성과 음성 각기 맞는 비율
- 둘다 맞춘거, 대각선의 비율 (TP와 TN)
특이도(Specificity)
- 전체 음성 중에 맞춘 음성 비율
F1
- recall과 presion의 기하 평균
acccuracy = accuracy_score(Y_test, Y_predict) #정확도
precision = precision_score(Y_test, Y_predict) #정밀도
recall = recall_score(Y_test, Y_predict) #재현율
f1 = f1_score(Y_test, Y_predict) #정밀도와 재현율의 조화 평균.
불균형 데이터 세트를 처리할 때 유용. 0~1 값이며, 1이 가장 좋음
roc_auc: ROC-AUC 점수
# 포지티브 클래스와 네거티브 클래스를 구별하는 모델의 능력
0~1 값이며, 1이 완벽. 0.5는 무작위6.PCA
-
차원 축소 기법. 원래 정보를 최대한 보존하면서 기능(차원) 수를 줄임으로써 복잡한 데이터 세트를 단순화하는 데 도움!
-
사실, scale 후 모델학습 전에 해야함.
but, 데이터 유출을 방지하려면 1. 모델 학습 먼저하고 2. scale 3.트레이닝 세트에서 PCA 로 차원 줄인후 테스트 세트 변환. 4. 변환된 트레이닝 세트로 모델 트레이닝. 5. 모델 평가
차원 축소의 이점
- 시각화 용이
- 주 구성요소에만 집중함으로 노이즈 감소
- 계산 비용 감소
from sklearn import decomposition
pca = decomposition.PCA(n_components=8) #PCA 개체 만들기
#n_components는 주성분 수로 n_components=8은 변환된 데이터 셋에 8개의 주성분이 있다!
pca.fit(b_cancer_scaled) # PCA개체를 데이터 세트에 맞추기
b_cancer_pca = pca.transform(b_cancer_scaled) #차원 축소
6-1 PCA 후 모델학습 과정 빠르게
# 1. X, Y 설정하기
Y = b_cancer_df['diagnosis']
X = b_cancer_pca #pca 후 데이터
# 2. 훈련용 데이터와 평가용 데이터 분할하기
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)
# 3. 로지스틱 회귀 분석 : (1)모델 생성
lr_b_cancer = LogisticRegression()
# 4. 로지스틱 회귀 분석 : (2)모델 훈련
lr_b_cancer.fit(X_train, Y_train)
# 5. 로지스틱 회귀 분석 : (3)평가 데이터에 대한 예측 수행 -> 예측 결과 Y_predict 구하기
Y_predict = lr_b_cancer.predict(X_test)
SVC
- 다양한 유형의 데이터를 분류하거나 분리하는 방법을 학습하는데 도움을 줌
ex) 한 장의 종이에 많은 점이 있고 파란색 점과 빨간색 점을 구분하는 선을 긋고 싶다고 상상해 보십시오. SVC()는 컴퓨터가 최적의 선(또는 곡선)을 찾도록 도와줌
이점
- 기능 많을때 작동 굳
- 실제로 맞지 않는 이상값에 잘 안속음
- 새로운 데이터 줘도 예측을 잘함
단점
- 속도 느리며, 각 예측에 대한 확률 제공 X
순서
모델 훈련 -> scale 조정 -> svc 모델 훈련 -> 예측 및 평가
# 1. 데이터 셋 로드
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 2. 데이터 세트를 교육 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. 데이터 스케일 조정
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 4. SVM 모델 훈련
model = SVC()
model.fit(X_train, y_train)
# 5. 예측
y_pred = model.predict(X_test)
# 6. 모델 평가
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
결정트리
- 데이터 포인트가 어떤 범주에 속하는지 파악하기 위해 스무고개하는것.
사용 장점
- 시각화 및 해석이 쉬움
- numeric nominal 둘다 처리 가능 => 전처리 안해도됨
- 누락된 값 처리가능
- 비 선형관계
순서
1. 데이터 읽어와서 df로 저장
feature_name_df = pd.read_csv('data2/features.txt', sep='\s+', header=None, names=['index', 'feature_name'], engine='python')```
from sklearn.metrics import confusion_matrix
print (confusion_matrix(Y_test, Y_predict))
행렬 대각선 외에 것들은 삐져나온값
찾아주는 라이브러리가 있다 gridSearchCV
후보군을 주면 max_depth 차원이 깊어짐.
깊게 트리를 만드는걸 허용 X 면 옆으로 뚱뚱한 트리 나와
# oneHot 인코딩
숫자지만 그 숫자에 의미가 없으면 이것도 인코딩해줘야해 ex) 지역번호 서울 02,경기 031 => 숫자가 커진다고 의미가 있는게 아니니까
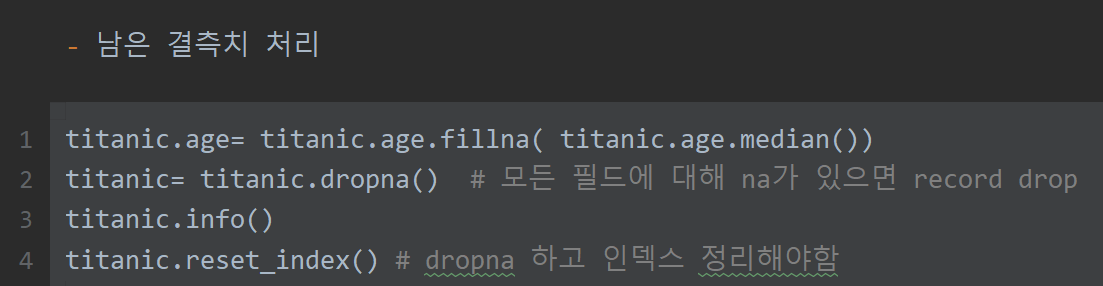
#na를 드롭을 했는데 인덱스가 남아있어. 새로만든 df는 이게 안빠져있는데 그래서 합쳐지면 문제가돼. => reset index를 drop 하고 필히 해줘야함 