파이썬 빅데이터
1.파이썬 Numpy

ndarray : 1가지 type의 값들로 구성, axis = 차원속성ndarray.ndim : 차원수ndarray.shape : 데이터 모양ndarray.size : 전체 값 개수ndarray.dtype : 값의 typendarray.itemsize : 각 값의 크기
2023년 3월 15일
2.파이썬 pandas
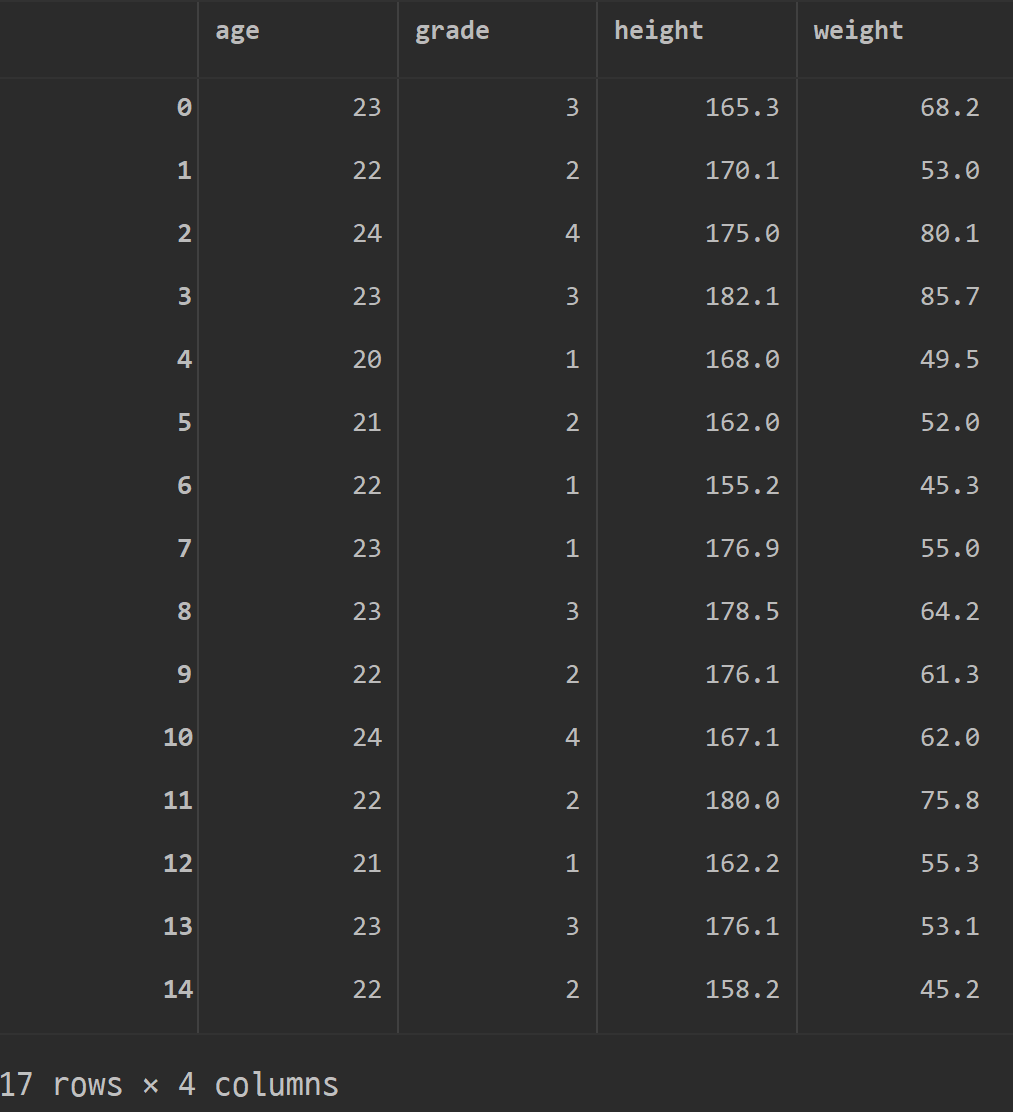
pandasiloc행,열df.iloc\[ 1,2,4, 0, 2]loc행, "열 이름"isin
2023년 3월 15일
3.빅데이터 4주차
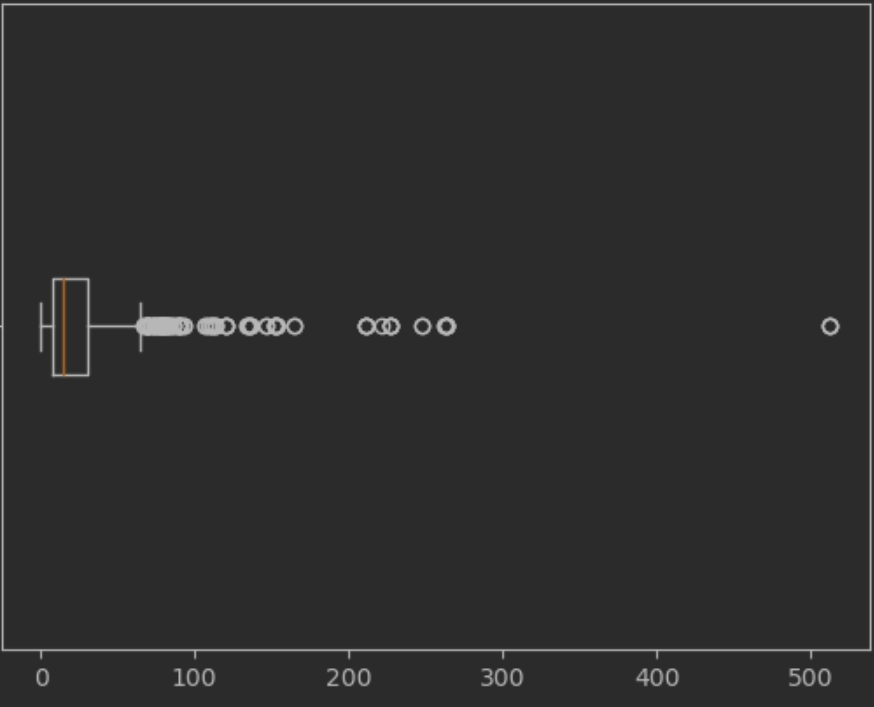
nominal 순서가 의미있는 Numeric 세는게 의미 x = 수치데이터deck 순서 있음출발도시 nfare age 빼고는 nominal.사망자의 숫자가 중요할때는 바 그래프사망자가 훨 많다라는걸 보여줄 때는 파이 그래프sample링 시드를 같은걸 주면 랜덤하지 않게
2023년 3월 29일
4.빅데이터 5주차
coef 저기 수식에서 앞에 있는 계수임.상관계수와 달라.
2023년 4월 5일
5.빅데이터 6주차 - 머신러닝(선형 회귀)
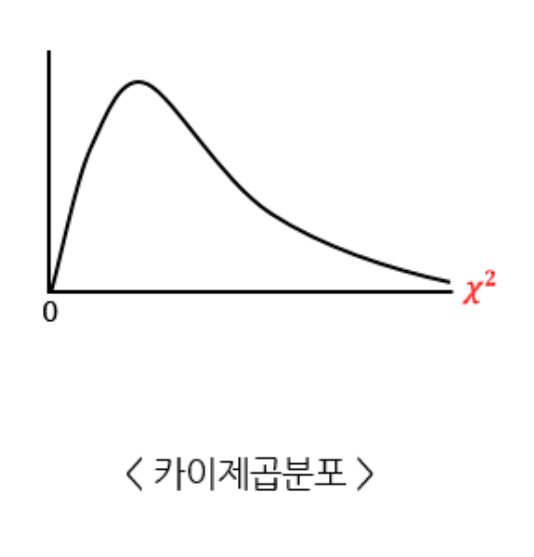
샘플 사이즈가 작을때 쓰기 유리해. => 정규분포를 가성비 있게 만드는법.카이가 표준정규분포라고 할 때카이 스퀘어 값의 크고 작음을 알려주는분산의 분포'X_train'은 일반적으로 교육 데이터의 기능을 포함하는 2D 배열 또는 DataFramen_samples는 데이터
2023년 4월 10일
6.빅데이터 7주차 - 로지스틱 회귀
예측 변수(독립 변수)와 결과 변수(종속 변수) 사이의 관계를 모델링결과 변수가 연속적일때 사용.특정 범위 내 모든 값을 가질 수 있음. ex) 온도, 주택가격예측 변수와 결과 변수 사이의 선형 관계를 모델링 해 가장 적합한 선을 찾는것연속 결과 변수와 예측 변수 사이
2023년 4월 17일
7.빅데이터 9주차 - clustering
K-means clustering
2023년 5월 3일