선형회귀
언제 사용해?
- 두 변수 간의 관계가 정비례 or 반비례할 or 선형 관계가 있는 경우
왜 사용해?
- 하나 이상의 입력 기능을 기반으로 숫자 값을 "예측"하려고
사용 예시
-
학생이 공부한 시간을 기반으로 시험에서 학생의 점수를 예측한다고 가정해 보십시오.
-
선형 회귀는 직선을 사용하여 공부한 시간과 시험 점수 사이의 관계를 찾을 수 있다!
-
선이 올라가면 학생들이 더 많이 공부할수록 일반적으로 시험 점수가 올라간다는 의미입니다.
선형 관계란?
- 한 변수가 증가하거나 감소함에 따라 다른 변수도 일정한 비율로 변경하는 관계
선형 관계인지 확인하는법
- pearson 상관계수를 통해 두 변수 간에 유의미한 선형 관계(양수 또는 음수)를 찾으면 선형 회귀가 적합한걸 알 수 있음!
선형 회귀 시각화 방법
- sns.regplot 을 이용하자
- 두 변수의 산점도를 그릴 뿐만 아니라
- 선형 회귀 모델을 데이터에 맞추고 가장 적합한 선을 그려서 변수 간의 선형 관계를 표시
선형 회귀 분석 순서
1. 데이터 수집
- pandas 로 dataFrame 을 만들어
2. 데이터 준비 및 탐색
data_df.shape , data_df.info()2-2 분석하지 않을 변수 제외하기
- 의미가 없는 명목변수 제외하기.
data_df = data_df.drop(['car_name', 'origin'], axis=1, inplace=False)2-3 결측치 처리
- replace('?', NaN)로 교체하거나
- dropna, fillna 로 채워
data_df.horsepower=data_df.horsepower.replace('?', np.NaN)
or
data_df=data_df.dropna()
#후에
data_df.horsepower= data_df.horsepower.astype('int')
3. 모델 training
3-1 X,Y, 훈련용,테스트 데이터 분할하기
- LinearRegression (선형 회귀)를 사용하기
# X,Y 분할
Y = data_df['mpg']
X = data_df.drop(['mpg'], axis=1, inplace=False)
# 훈련용 데이터와 평가용 데이터 분할하기
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=1)train_test_split(X, Y, test_size=0.2, random_state=1) 에서
-
test_size는 데이터 세트의 비율을 지정
test_size=0.2는 데이터 세트의 20%가 평가 데이터에 할당되고 80%가 학습 데이터에 할당됨. -
random_state는 데이터 세트의 무작위 셔플링을 제어
값은 정수이며 고정 값으로 설정하면 코드가 실행될 때마다 동일한 분할이 얻어집니다
if 지정하지 않으면) 임의의 값이 사용되므로 코드가 실행될 때마다 다른 분할이 발생
3-2 선형 회귀 모델 생성 및 훈련
# 모델생성
lr = LinearRegression()
# 훈련
lr.fit(X_train, Y_train)
# 예측
Y_predict = lr.predict(X_test)
4 결과 분석 및 시각화
# 기울기 값
coef = pd.Series(data=np.round(lr.coef_, 2), index=X.columns)
# 참고로 계수가 클수록 독립 변수가 종속 변수에 미치는 영향이 더 크다는 의미입니다.
# mse, rmse 분석
mse = mean_squared_error(Y_test, Y_predict)
rmse = np.sqrt(mse)
print('MSE : {0:.3f}, RMSE : {1:.3f}'.format(mse, rmse))
4-2 선형 회귀 그래프 시각화
fig, axs = plt.subplots(figsize=(16, 16), ncols=3, nrows=2)
sns.regplot(x=feature, y='mpg', data=data_df, ax=axs[row][col], color=plot_color[i])sns subplot을 이용해서 그래프를 그린다.
X_train.shape
- 'X_train'은 일반적으로 교육 데이터의 기능을 포함하는 2D 배열 또는 DataFrame
shape 속성은 (n_samples, n_features)
- n_samples는 데이터세트의 학습 예제(행) 수입니다.
- n_features는 기계 학습 모델에 대한 입력으로 사용되는 기능(열)의 수
lr.fit(X_train, Y_train) 의 기능은?
- 'X_train'은 훈련 데이터의 특징을 포함하는 2D 배열 또는 DataFrame이고
- 'Y_train'은 해당 대상 변수 값을 포함하는 1D 배열 또는 Series입니다.
lr.fit(X_train, Y_train)을 호출하면 모델은 X_train의 기능과 Y_train의 대상 변수 간의 관계를 학습
regression 성능 지표 세가지
- 회귀 모델의 정확도를 평가하는 데 사용되는 일반적인 성능 지표
- 각 메트릭은 모두 예측 값과 실제 값의 차이를 측정하지만 오류의 다른 측면을 강조하는데 차이가 있음.
MSE 시리즈는 큰오류나 이상값. MAE는 작은 오류
MSE(Mean Squared Error)
-
예측 값과 실제 값 사이의 제곱 차이의 평균을 계산
-
오류를 제곱함으로써 MSE는 더 큰 오류에 더 많은 가중치를 부여하고 이상값에 민감해짐
-
낮은 MSE는 모델의 예측이 실제 값에 더 가깝다는 것을 의미하므로 더 나은 모델 적합성을 보여줌.
RMSE(Root Mean Squared Error)
- MSE의 제곱근입니다. 제곱근을 취하면 오류 값이 원래 데이터와 동일한 단위로 다시 가져온다.
- RMSE도 이상값에 민감하며 더 큰 오류에 더 많은 가중치를 부여
MAE(Mean Absolute Error)
- 예측 값과 실제 값 간의 절대 차이의 평균을 계산.
- MSE 및 RMSE와 달리 MAE는 오류를 제곱하지 않으므로 모든 오류에 동일한 가중치를 부여한다. => 이상값에 덜 민감.
- 평균 오차를 더 쉽게 해석하지만, 큰 오류를 강조하지 않음.
Ridge Regression => (정규화 있는 선형회귀 버전)
- Linear Regression 과 동일하게 선형 모델이지만
- 모델이 보이지 않는 새로운 데이터를 더 잘 예측하도록 합니다. 모델이 입력 기능에서 학습하는 방식을 약간 변경하여 이를 수행합니다.
언제 사용?
- 모델이 너무 복잡하고 새 데이터에서 제대로 작동하지 않을때
- 데이터 세트에서 가장 중요한 기능을 찾고 싶을때
항상 일반 선형회귀보다 좋은가?
-
다중 공선성, 많은 수의 기능 또는 잡음이 있는 데이터를 처리할 때 일반 선형 회귀보다 훌륭.
-
But, 정규화 기간이 제대로 선택되지 않으면 모델의 성능이 저하됨.
-
- 과적합 문제에 취약하지 않은 경우 단순 선형 회귀가 더 쉽고 좋을 수 있다!
alpha 란?
-
ex) linear_model.Ridge(alpha=.5)
=> 정규화의 강도를 제어하는 매개변수 -
'alpha'가 0으로 설정되면 Ridge 회귀는 일반 최소 제곱 선형 회귀와 동일하게 됩니다(정규화가 적용되지 않음).
-
alpha 값을 높게 설정하면 정규화가 더 많이 적용되고 모델이 과적합에 더 강해집니다.
-
가장 적합한 값을 찾으려면 실험이나 교차 검증과 같은 기술을 사용해야 합니다.
과적합이란?
-
모델이 학습 데이터에서 잘 수행되지만 보이지 않는 새로운 데이터(테스트 시)에 잘 일반화되지 않을 때 발생하는것.
-
ex) 모의고사는 잘보는데, 수능에서 망하는 느낌?ㅎ
정규화란?
- 과적합을 방지하는 데 사용되는 기법.
- ex) 실전 경험을 올려준다!
feature selection(기능선택)
- 머신러닝 모델을 구축하는 데 사용할 데이터 세트의 집합에서 가장 중요한 기능의 하위 집합을 선택하는 프로세스
기능선택의 이점
-
과적합 감소: 베스트 기능만 선택하면 과적합 감소
-
모델 성능 향상: 모델의 복잡성을 줄임
-
복잡성 감소 : 더 적은 기능으로 교육하면 가성비 굳
기능선택의 목표
- 모델의 성능을 개선하고 과적합을 줄이며
- 계산 복잡성을 줄이는 것
fs = SelectKBest(score_func=f_regression, k=k)
-
instance of SelectKBest를 생성하는 것
-
k는 선택할 상위 기능('k')의 수를 지정
교차 검증 (cross validation) = 성능평가
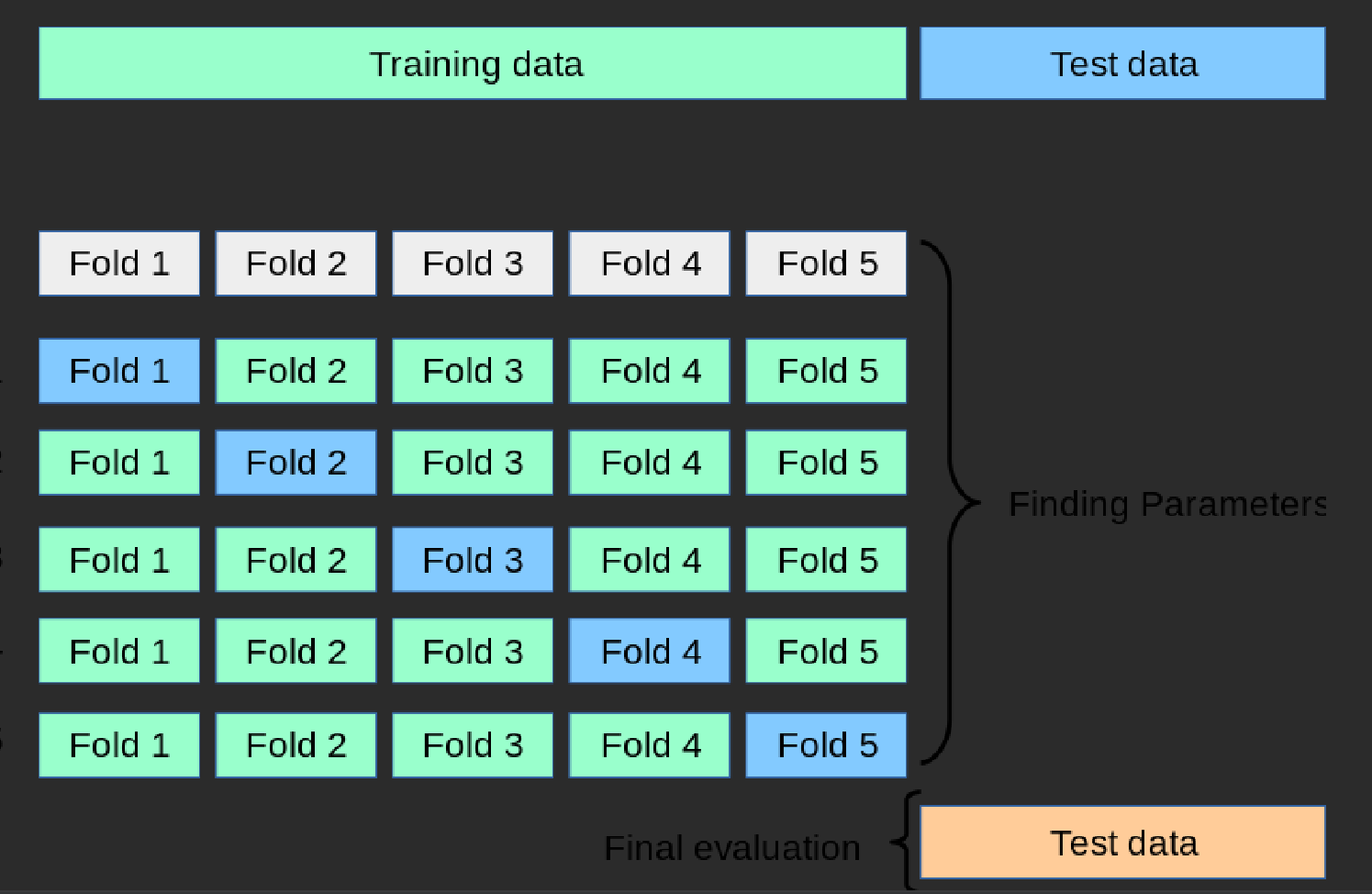
- 모델의 성능을 평가하고 과적합을 방지하는 기술
how to ?
-
데이터 셋을 '폴드' 라고 하는 여러 하위집합으로 분할하기
-
- 모델은 여러번 훈련되고 평가되며, 매번 다른 폴드를 테스트로, 나머지 폴드를 train 세트로 사용.
언제 사용?
-
본 적 없는 데이터 모델
-
성능을 비교해 최상의 모델을 선택할 때
순서
1. 폴드 수 선택(cv)
2. 데이터 세트 분할
- 데이터 세트를 k개의 동일한 크기 부분 또는 "폴드"로 나눕니다.
from sklearn.model_selection import KFold
kf = KFold(n_splits=k, shuffle=True, random_state=42)
3. k번 모델 훈련 및 검증
- 각 접기에 대해 test 세트로 사용하고 나머지(k-1) 접기를 train 세트로 사용합니다.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
lr = LinearRegression()
mse_scores = []
for train_index, val_index in kf.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]
lr.fit(X_train, y_train)
y_pred = lr.predict(X_val)
mse = mean_squared_error(y_val, y_pred)
mse_scores.append(mse)
4. 성능 메트릭 계산
- 각 반복에 대해 검증 세트의 모델에 대한 성능 메트릭(예: 정확도 또는 평균 제곱 오차)을 계산
mse_scores # List of mean squared error values for each fold
5. 평균 성능
- 모든 k 반복을 완료한 후 모든 k 검증 세트에 대한 평균 성능 지표를 계산
avg_mse = sum(mse_scores) / k
print("Average Mean Squared Error:", avg_mse)
구문 분석
data_df = data_df.drop(['car_name', 'origin'], axis=1, inplace=False)
-
inplace=True 는 원본 DataFrame이 수정됩니다. 새로운 DataFrame이 생성되지 않습니다.
-
inplace=False 는 원래 DataFrame은 변경되지 않은 상태로 유지됩니다.
-
즉, 'car_name' 및 'origin' 열이 제거된 새 DataFrame이 생성되고 원래 DataFrame 'data_df'는 변경되지 않고 유지됩니다.
fig, axs = plt.subplots(figsize=(16, 16), ncols=3, nrows=2)
-
figsize: 전체 그림의 너비와 높이를 인치 단위로 설정합니다. 이 경우 너비와 높이가 모두 16인치임을 의미하는 (16, 16)으로 설정됩니다.
-
ncols: 서브플롯 그리드의 열 수
-
nrows: 서브플롯 그리드의 행 수
