dataframe
2차원 구조, column 마다 다른 데이터 type
row = 레코드 , col = 필드
데이터처리, 통계 등은 column 단위로 이뤄짐
tabular data ( 일반 csv 데이터 구조 처리에 적합)
가로열 index 세로열 column
생성
딕셔너리 이용
{'컬럼명': [ 값, 값,.. ], '컬럼명': [값, 값, .. ] }
pd.DataFrame (딕셔너리)
dic= { 'gender' : [ 1, 2, 1,2], 'bloodtype': ["A", "B", "O", "AB"]}
df1= pd.DataFrame(dic)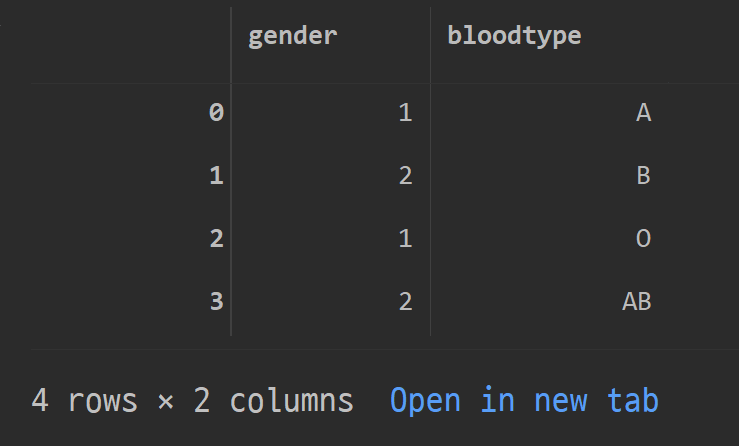
numpy array를 사용 가능
DataFrame ( array, index= row index array, columns = 컬럼명 array)
df = pd.DataFrame(np.random.randn(6, 4), index=np.arange(6), columns=list("ABCD"))
df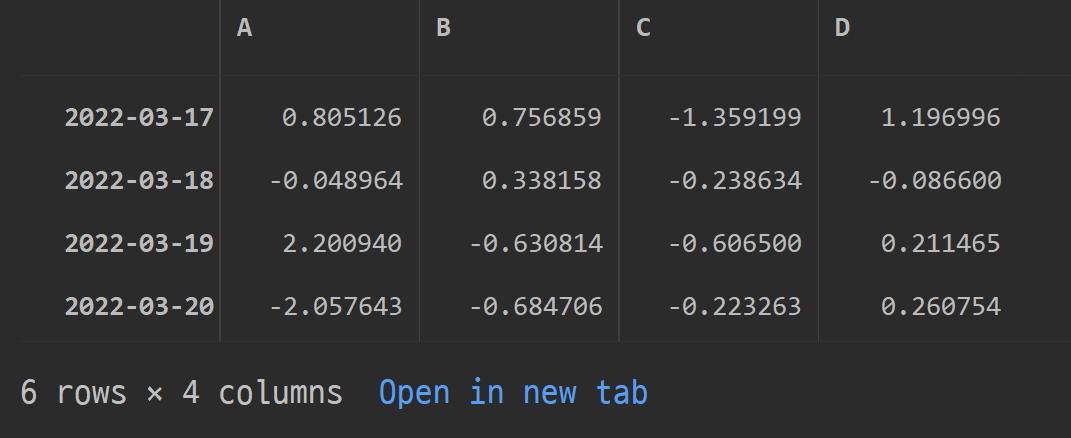
보기
head() , tail() : 최초, 마지막 5개
head (n), tail( n ) : 최초, 마지막 n개
df.head()
=> 마지막꺼 남기고 다
df.tail(2)
=> 밑에서 두개
df.index
df.colums
df.describe()
=> 간단한 통계
df.sort_values(by="B")
=> B기준으로 정렬
df[0:3] # rows => 괄호 한개면 행
df[["age","dept"]] # column => 괄호 두개면 열
count
df1.count()
df1[칼럼].count()
df1[칼럼].value_counts()
=> 각 종류별로 데이터가 몇개 있는지 세어줌size vs count 차이
- NaN값을 제외한 나머지 데이터들의 개수를 세어준다.
size는 NaN도 포함하여 모든 데이터의 갯수를 세어준다
csv 파일 읽기
df=pd.read_csv("studentlist.csv", encoding="cp949")
dfiloc[행,열]
df.iloc[1:5, 0:3]
df.iloc[ [1,2,4], [0, 2]]
=> 원하는 행,열의 숫자index로 표시loc: label에 의한 참조
df.loc[0:3, ["age","grade"]]
df[ df["bloodtype"]=="B"]
=> 값에 의한 참조. 정확한 row를 맞춰야해isin () : 포함조건
df.loc [df["bloodtype"].isin( ["B", "A"] ), ["name", "age"] ]
concat
df2= df[["age", "grade"]]
df3= df[["height", "weight"]]
df4=pd.concat([df2, df3], axis=1)
df4
=> axis=1 열 기준으로 df2 df3 합치기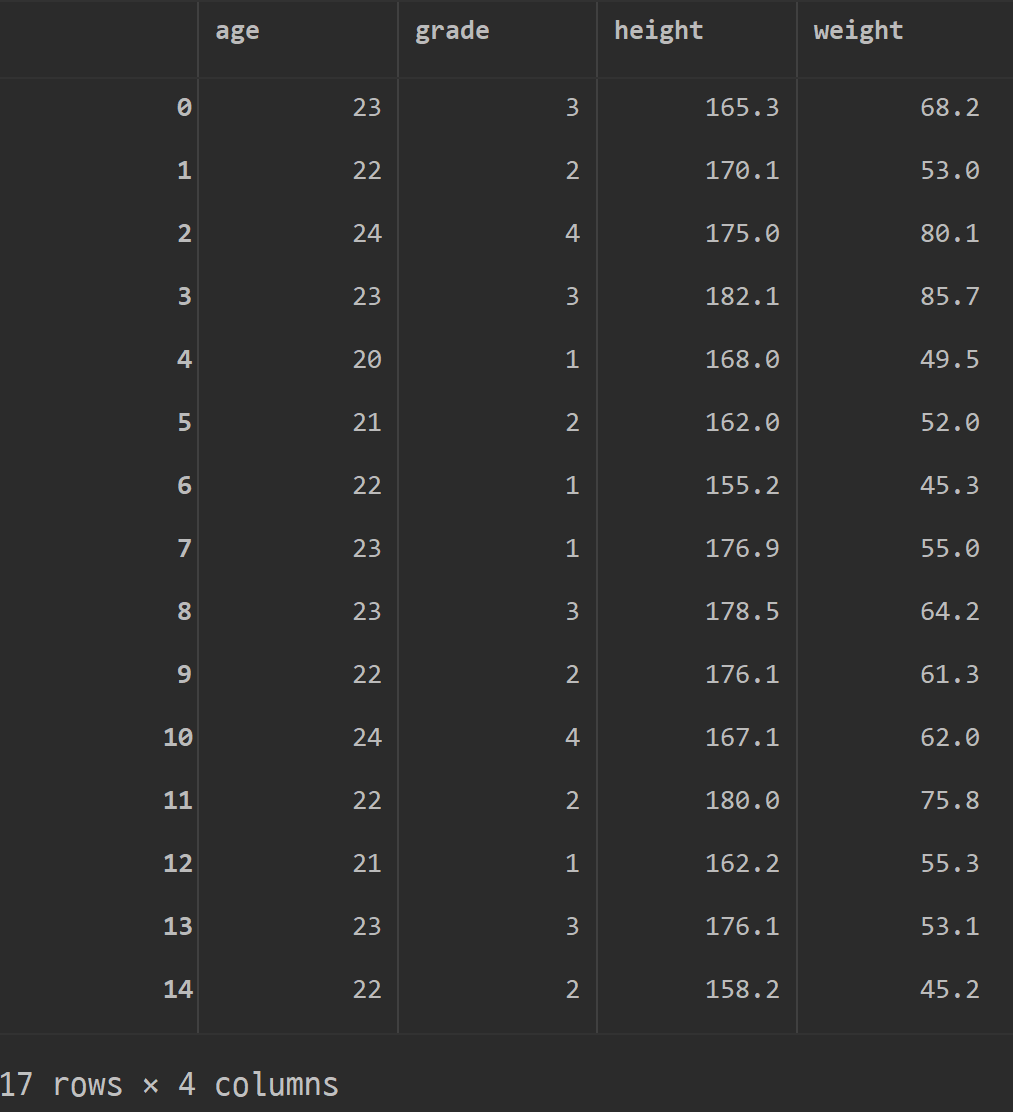
merge
기본꼴
merge(df_left, df_right, how='inner', on=None)
df3= pd.merge(df, dff, left_on='name', right_on='realname')
=> df dff 를 합치는데, how는 기본으로 inner, left on의 키는 name
groupby
df.groupby(["sex","bloodtype"]).mean()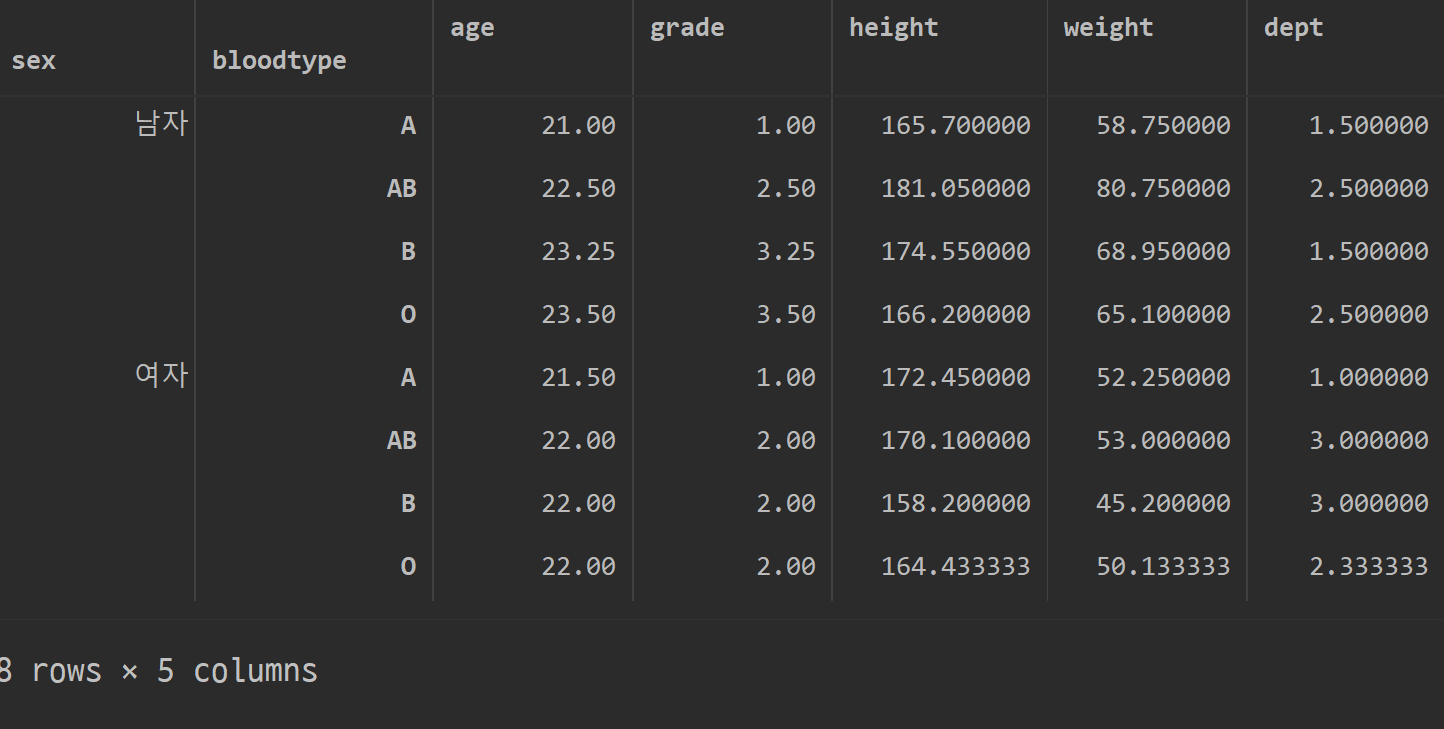
pd.concat vs merge
concat
- pd.concat은 데이터를 쌓거나 추가. 지정된 축을 따라 Pandas 개체를 연결
merge
- pd.merge는 공통 키를 기반으로 데이터를 병합
matplotlib
input data 형식
numpy array 이어야 함
pandas column도 가능
- plt.plot([x축 데이터], [y축 데이터]) 형식
plot type
“ro” 빨간 점
“b-” solid blue line default
“r–” 빨강 --- 선
“bs” 파랑 네모
“g^” 초록 세모
여러 chart
- figure : 그림 전체 (여러 axes를 포함)
plt.figure(figsize=(7, 3))
#전체 가로세로 크기
##7by 3 크기- axes : 그 내부의 좌표축
- subplot ( ) : 하나의 axes를 만듦
plt.subplot(231)
# 2 x 3 구성의 1번- bar (), scatter (), plot () 각기 다른 모양 plot ()의 파라메터로도 표현 가능
plt.bar(names, values) 
2가지 이상의 정보를 2차원에 표시
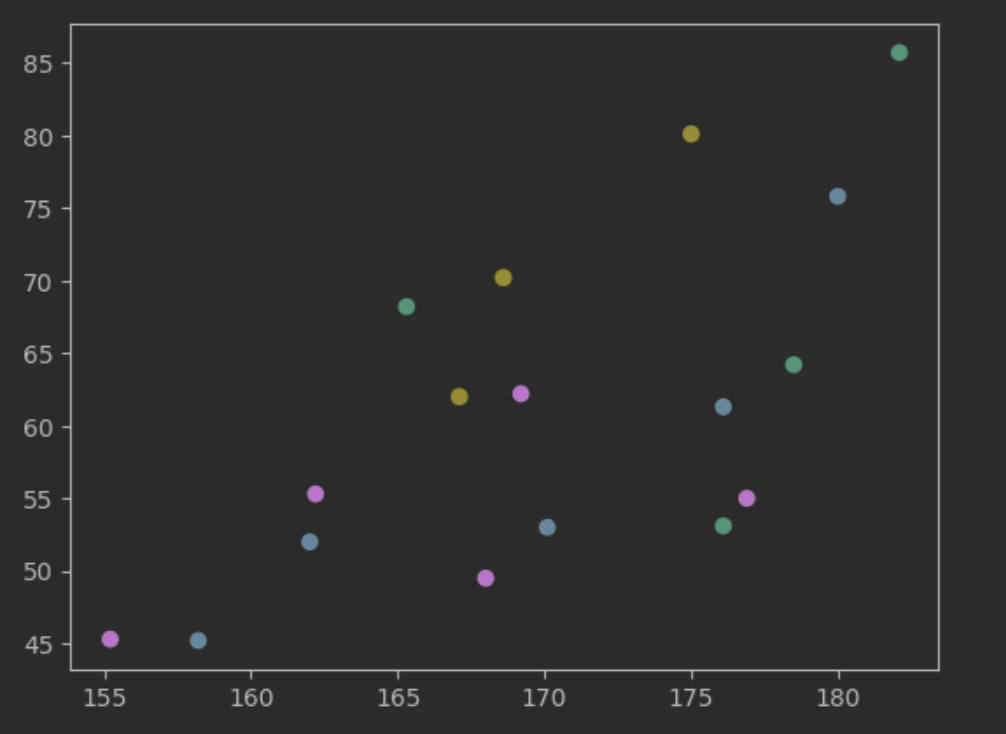
- scatter ( x, y, c=유형별 컬러, s=사이즈, data= label을 가진 원본 데이터)
plt.scatter ( "height", "weight", c="grade" ,data=df)