nominal
-
고유한 순서나 계층 없이 그룹이나 레이블로 분류할 수 있는 데이터
-
TIP) 숫자가 고유한 순서나 순위가 없는 범주나 레이블을 나타내는 경우를 찾아보자
ex)
색상: 빨강, 파랑, 녹색, 노랑
성별: 남성, 여성, 논바이너리
요리의 종류: 이탈리아, 중국, 멕시코, 인도
pd.crosstab ( 변수1, 변수2, normalize=True or False) : normalize = 비율Numeric
-
숫자 값을 나타내는 데이터를 말하며, 순서를 지정하고 산술 연산을 수행할 수 있습니다.
-
세는게 의미 x = 수치데이터. 나이, 체중 등 숫자로 표현 가능한 데이터
-
연속 데이터와 불연속 데이터의 두 가지 하위 범주로 더 나눌 수 있습니다.
연속 데이터 continuous
- 특정 범위 내에서 임의의 숫자를 가질 수 있는 값
- tip) 분수 또는 소수를 포함할 수 있는 연속 척도를 사용하여 측정할 수 있는 것. 무한하게 가능.
ex)
온도: 32.5°C, 21.4°C, -10.3°C
키: 175.3cm, 162.6cm, 190.8cm
시간: 3.2초, 15.8분, 12.6시간
불연속 데이터
- 고유하고 개별적인 숫자만 사용할 수 있는 값
- tip) 정수를 사용하여 셀 수 있는 것으로 생각
ex)
한 반 학생 수: 25, 30, 40
나이: 20, 25, 30
판매 품목 수: 5, 10, 15
titanic['age'].astype(int) 는 왜 에러가 발생할까?
에러: Cannot convert non-finite values (NA or inf) to integer
deck 순서 있음
- titanic['age'] 중에 NaN(Not a Number)이 있기 때문. 일부 누락된 값이 포함되어 있기 때문에 이걸 없애줘야해.
# 중간값으로 NaN 채워주자
titanic['age'] = titanic['age'].fillna(titanic['age'].median())
# 그리고 int로 변환
titanic['age'] = titanic['age'].astype(int)
도수 세기
df.컬럼명.value_counts() or df[‘컬럼명’].value_counts()
titanic.sex.value_counts()
titanic.survived.value_counts(normalize=True)
# 정규화 normalize=True를 하면 백분율로 나온다!출발도시 n
fare age 빼고는 nominal.
사망자의 숫자가 중요할때는 바 그래프
사망자가 훨 많다라는걸 보여줄 때는 파이 그래프
sample링 시드를 같은걸 주면 랜덤하지 않게 추출 ㄱㄴ
표본 추출
단순 추출
-
df.sample(n=추출 개수,frac=추출 비율, replace=중복추출여부, random_state=랜덤시드, ignore_index=새로 인덱스 부여 여부)
-
특정 기준이나 구조 없이 모집단에서 개인을 무작위로 선택하는 것을 포함합니다.
모집단이 동질적이며 모든 개인이 선택될 기회가 동일하다고 가정합니다.
층화 추출
- nominal 필드의 비율 분포 유지하면서
- 연령, 성별 또는 소득과 같은 특정 기준에 따라 모집단을 하위 그룹 또는 계층으로 나누는 것을 포함합니다.
- 각 계층에 대해 더 정확한 추정치
층화 추출 하는이유?
- 더 큰 모집단에서 대표 샘플을 얻기 위해
- 샘플링 오류 감소
- 전체 모집단을 보다 정확하게 표현하기 위해
from sklearn.model_selection import train_test_split
-
train_data, test_data = train_test_split(데이터, test_size=0.1, random_state=1, stratify=필드)
-
stratify 는 층화 샘플링에 사용할 데이터 세트의 열을 지정
데이터 세트를 (훈련 세트, 테스트 세트) 두 하위 집합으로 분할
- 왜?
- 모델은 새로운 데이터로 일반화하는 것이 아니라 훈련 데이터의 특정 패턴과 노이즈를 학습훈련하는것.
따라서 새로운 데이터에서는 제대로 수행되지 않을 수 있기 때문에 훈련 80퍼, 테스트 20퍼로 나누는 관례.
- 예제 문제 80 퍼 풀고 모의고사로 새로운 문제 실전감 익히는 느낌!과제 2 중간고사 나올수도 2-3줄 만에 풀수있는거
ctgan
-
데이터 확대, 개인 정보 보호 데이터 공유, 테스트 및 검증 목적을 위한 합성 데이터 생성에 널리 사용
기술 통계 보기
quantile(0.99) 99 등의 것은 얼마냐
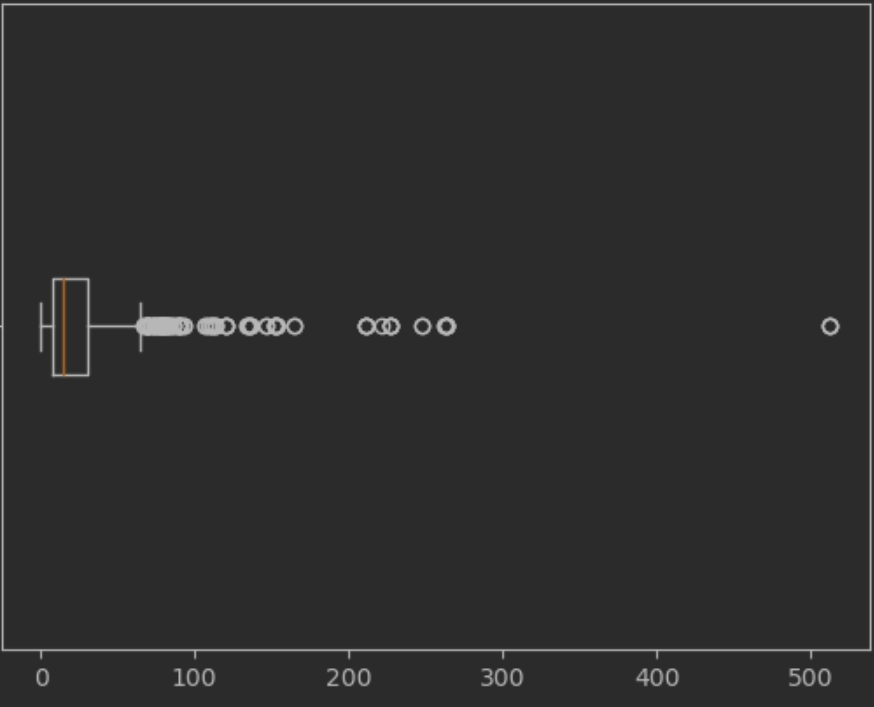
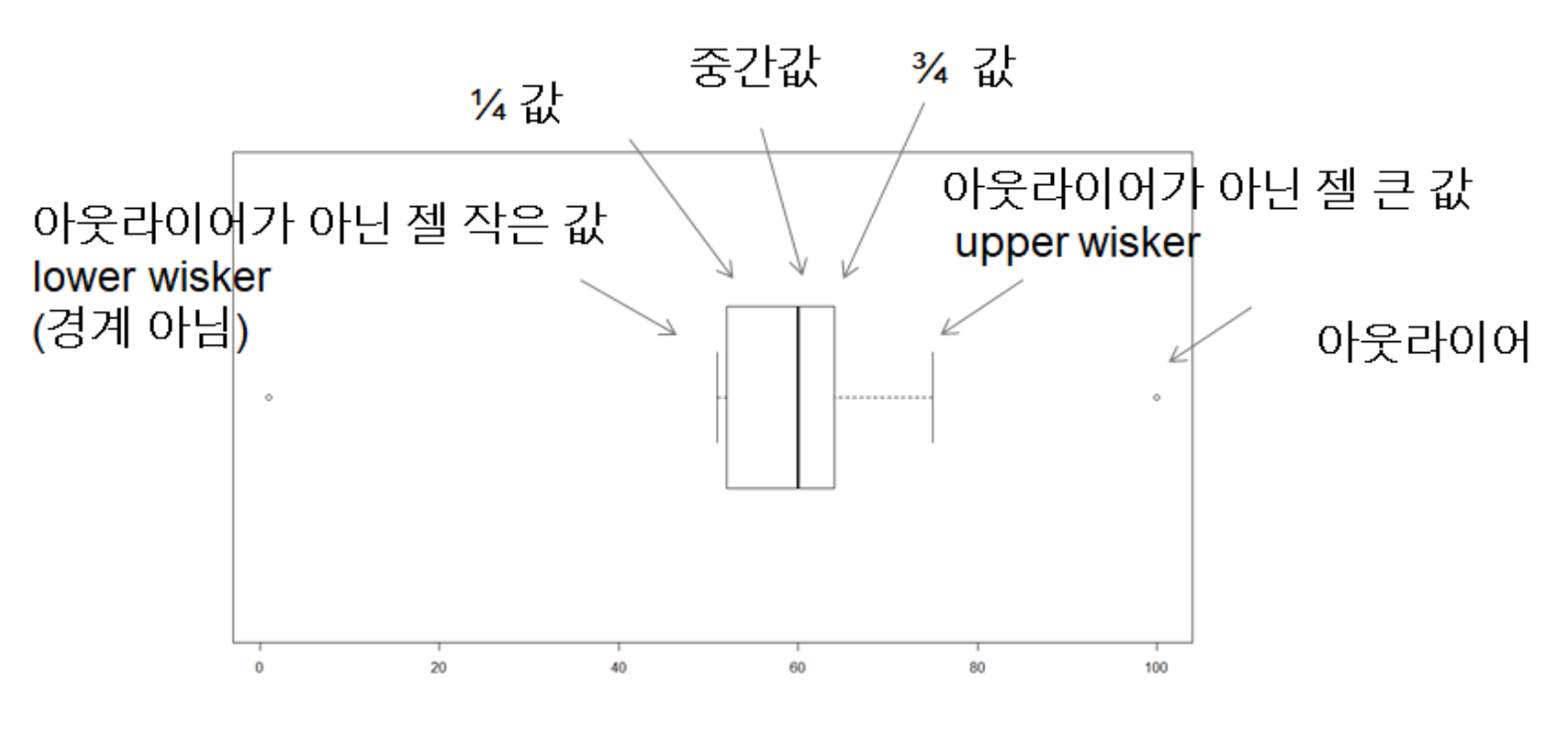
저기 오른쪽 아웃라이어가 아닌 젤 큰 값은
경계선 보다는 작으면서 제일 큰 값을 나타냄
iqr
- iqr 은 사분위수 범위로 데이터의 중간 50%가 속하는 범위를 나타내는 통계적 분산의 척도
- 첫 번째 사분위수(Q1 - 25번째 백분위수)와 세 번째 사분위수(Q3 - 75번째 백분위수) 간의 차이
pd.Categorical
- 사용하는 주요 이점은 일반 배열이나 목록을 사용하는 것에 비해 메모리를 절약하고 성능을 향상시킬 수 있다는 것입니다.
- 이는 범주형 변수가 정수 배열로 저장되기 때문입니다.
titanic['embark_town'] = pd.Categorical(titanic.embark_town, categories=["Southampton", "Cherbourg"])신뢰구간 구하기
30 개 이하의 샘플 : st.t.interval(alpha=신뢰구간, df=샘플 갯수-1, loc=평균, scale=평균오차)
# t 분포 기반. 표본 크기가 작거나 모집단 표준 편차를 알 수 없는 경우에 적합
30 개 이상 : st.norm.interval(alpha=0.95, loc=np.mean(data), scale=st.sem(data))
import scipy.stats as st
import numpy as np
sample1=titanic.sample (n=30)
sample2=titanic.sample (frac=0.6)
print ("sample1:", np.mean(sample1.fare), st.t.interval(alpha=0.95, df=len(sample1)-1, loc=np.mean(sample1.fare), scale=st.sem(sample1.fare)))
print ("sample2:", np.mean(sample2.fare), st.norm.interval(alpha=0.95, loc=np.mean(sample2.fare), scale=st.sem(sample2.fare)))
print ("population:", np.mean(titanic.fare))평균 비교
-
2개의 평균이 있을 때, 샘플에서는 평균이 차이가 나는데 실제 모집단에서도 차이가 날지 분석
-
가설 검정
- 가설 : 실제 모집단에서는 차이가 없다
- 검정 : 가설이 맞는지 판단하는 절차
-
예
- 키 크는 약이 효과가 있는지.. 약을 먹인 몇 명의 결과를 놓고 판단하고자 함
- 원래 중학교 2학년 인구의 키 평균 = 164
- 1학년부터 약먹은 2학년(샘플) 평균 = 167
- 영가설 : 원래 키에서 변동이 없다 (샘플에서만 평균이 높게 나왔을 뿐)
- 검정 : 샘플로 추정할 수 있는 모집단의 신뢰구간 (전체 중학생에게 약을 먹였을 때, 그 평균은 95%의 확률로 이 구간내에 있을 것이다) 안에 원래 평균(164) 이 있다면, 영가설이 맞다 (변동이 없다=효과가 없다)
- 만약 검정 결과 원래 평균이 신뢰 구간 밖이라면, 영가설 기각 (변동이 있다)
- 평균값이 => 통계적으로 유의미한 차이가 있다.
st.ttest_1samp(데이터, 비교평균)
- pvalue < 0.05 이면 영가설 기각 (아니면 영가설이 맞음)st.ttest_1samp (sample2.fare, 20) # 샘플 집단의 배 삯 평균은 20 #모집단의 샘플2 평균이 20일 확률!도수비교
- nominal 데이터의 값 별 분포가 차이가 있는가? (샘플에서 그렇게 나왔는데 전체도 그렇다고 추정할 수 있나?)
- 특정 혈액형이 더 많은가?
- 가설 : 혈액형 분포는 같다 = 고르게 분포한다 (영가설)
- 검정 : chisquare ( 데이터 )
- 실제 분포가 균등한데, 샘플이 이렇게 나올 확률을 얻음
- if pvalue < 0.05 전체도 다르다고 추정할 수 있음
- 카테코리 별로 => 통계적으로 유의미한 차이가 있다.
카이스퀘어 사용
1. 카이스퀘어 pvalue
from scipy.stats import chisquare
chisquare ([10, 12, 13, 5])
# 결과값 pvalue=0.283이 나옴. 원래는 균등 분포인데, 샘플에서만 우연히 이렇게 차이나왔을 가능성 28%
# 샘플이 커지면
chisquare ([100, 120, 130, 50 ] )
# 결과값 pvalue=2.826e^-8 나옴. 원래는 균등 분포인데, 이렇게 큰 샘플에서 우연히 이렇게 차이가 많이 나게 나올 가능성 0.000002 % => 통계적으로 유의미한 차이를 보인다.
# 사용예시 그냥 돌리면됨.
num_class=sample2["class"].value_counts()
print (chisquare (num_class))
# 샘플의 개수가 커야 의미가 항상 있음.
- 0,05 보다 작으면 차이가 유의미한 수준
