
1. PRIMARY KEY (기본 키)
- 테이블의 각 레코드를 식별
- 중복되지 않은 고유값을 포함
- NULL 값을 포함할 수 없음.
- 테이블 당 하나의 기본키를 가짐.
- PRIMARY KEY 생성 문법 1
# 하나의 칼럼을 기본키로 설정하는 경우
CREATE TABLE person
(
pid int NOT NULL,
name varchar(16),
age int,
sex char,
PRIMARY KEY (pid)
);
# 여러개의 칼럼을 기본키로 설정하는 경우 - 두 개가 하나의 PRIMARY KEY
CREATE TABLE animal
(
name varchar(16) NOT NULL,
type varchar(16) NOT NULL,
age int,
PRIMARY KEY (name, type)
);- PRIMARY KEY 삭제 문법
# 하나의 칼럼이 기본키로 설정된 경우
ALTER TABLE person
DROP PRIMARY KEY;
# 여러개의 컬럼이 기본키로 설정된 경우 (삭제 방법 동일)
ALTER TABLE animal
DROP PRIMARY KEY;- PRIMARY KEY 생성 문법 2
# 하나의 칼럼을 기본키로 설정하는 경우
ALTER TABLE person
ADD PRIMARY KEY (pid);
# 여러개의 칼럼을 기본키로 설정하는 경우
ALTER TABLE animal
ADD CONSTRAINT PK_animal # 생략 가능
PRIMARY KEY (name, type);2. FOREIGN KEY (외래 키)
- 한 테이블을 다른 테이블과 연결해주는 역할
- 참조되는 테이블의 항목은 그 테이블의 기본키 (혹은 단일값)
- FOREIGN KEY 생성 문법 1
# CREATE TABLE에서 FOREIGN KEY를 지정하는 경우
CREATE TABLE orders
(
oid int not null,
order_no varchar(16),
pid int,
PRIMARY KEY (oid),
CONSTRAINT FK_person
FOREIGN KEY (pid) REFERENCES person(pid)
);
# CREATE TABLE에서 FOREIGN KEY를 지정하는 경우, CONSTRAINT 생략 가능
CREATE TABLE job
(
jid int not null,
name varchar(16),
pid int,
PRIMARY KEY (jid),
FOREIGN KEY (pid) REFERENCES person(pid)
);- CONSTRAINT 확인 문법
- PRIMARY KEY는 고유값이기 때문에 이름이 필요 없음.
- FOREIGN KEY는 여러개 생성 가능, 이름 필요함. (한 테이블이 참조하는 테이블이 여러개 있을 수 있음.)
# 자동 생성된 CONSTRAINT를 확인하는 방법
SHOW CREATE TABLE job;- FOREIGN KEY 삭제 문법
- Reference 관계 삭제, KEY 속성은 남아있음.
ALTER TABLE orders
DROP FOREIGN KEY FK_person;- FOREIGN KEY 생성 문법 2
# Table이 생성된 이후에도 ALTER TABLE을 통해 FOREIGN KEY 지정 가능
ALTER TABLE orders
ADD FOREIGN KEY (pid) REFERENCES person(pid); # CONSTRAINT는 자동 지정- FOREIGN KEY 예제
- police_station과 crime_status 테이블 사이에 관계(Foreign Key)를 설정
AWS RDS(database-1)의 zerobase에서 작업
# AWS RDS(database-1)의 zerobase 접속
-h 엔드포인트 -P 3306 -u admin -p zerobase
# 테이블 이름 확인
show tables;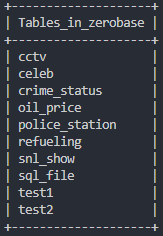
# police_station 정보 확인
desc police_station;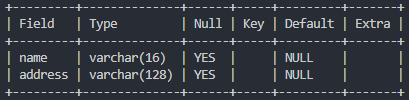
# police_station 내 name 칼럼 데이터를 중복 제외하고 몇개인지 확인
select count(distinct name) from police_station;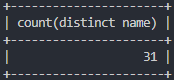
# crime_status 정보 확인
desc crime_status;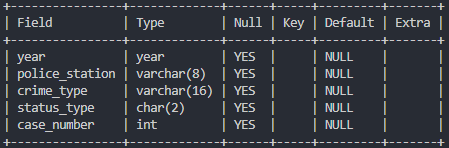
# crime_status 내 police_station 칼럼 데이터를 중복 제외하고 몇개인지 확인
select count(distinct police_station) from crime_status;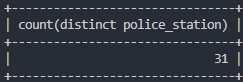
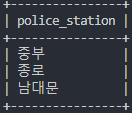
# name 과 police_station 칼럼의 데이터 형태 확인
select distinct name from police_station limit 3;
select distinct police_station from crime_status limit 3;
# 두 칼럼 같게 만들어서 매칭 되는지 확인
select c.police_station, p.name
from crime_status c, police_station p
where p.name like concat ('서울', c.police_station, '경찰서')
group by c.police_station, p.name;>>>
+----------------+------------------+
| police_station | name |
+----------------+------------------+
| 중부 | 서울중부경찰서 |
| 종로 | 서울종로경찰서 |
| 남대문 | 서울남대문경찰서 |
| 서대문 | 서울서대문경찰서 |
| 혜화 | 서울혜화경찰서 |
| 용산 | 서울용산경찰서 |
| 성북 | 서울성북경찰서 |
| 동대문 | 서울동대문경찰서 |
| 마포 | 서울마포경찰서 |
| 영등포 | 서울영등포경찰서 |
| 성동 | 서울성동경찰서 |
| 동작 | 서울동작경찰서 |
| 광진 | 서울광진경찰서 |
| 서부 | 서울서부경찰서 |
| 강북 | 서울강북경찰서 |
| 금천 | 서울금천경찰서 |
| 중랑 | 서울중랑경찰서 |
| 강남 | 서울강남경찰서 |
| 관악 | 서울관악경찰서 |
| 강서 | 서울강서경찰서 |
| 강동 | 서울강동경찰서 |
| 종암 | 서울종암경찰서 |
| 구로 | 서울구로경찰서 |
| 서초 | 서울서초경찰서 |
| 양천 | 서울양천경찰서 |
| 송파 | 서울송파경찰서 |
| 노원 | 서울노원경찰서 |
| 방배 | 서울방배경찰서 |
| 은평 | 서울은평경찰서 |
| 도봉 | 서울도봉경찰서 |
| 수서 | 서울수서경찰서 |
+----------------+------------------+# police_station 내 name 컬럼 primary key로 설정
alter table police_station
add primary key (name);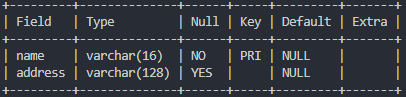
# crime_status 내 reference 컬럼 생성
alter table crime_status
add column reference varchar(16);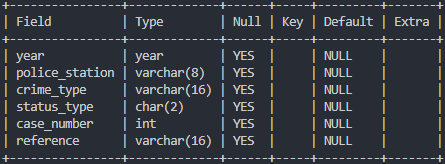
# c.reference 컬럼을 foreign key로 설정 (p.name 컬럼 참조)
alter table crime_status
add foreign key (reference) references police_station(name);# c.reference 데이터를 p.name 처럼 바꿈
update crime_status c, police_station p
set c.reference = p.name
where p.name like concat('서울', c.police_station, '경찰서');select distinct police_station, reference from crime_status;>>>
+----------------+------------------+
| police_station | reference |
+----------------+------------------+
| 중부 | 서울중부경찰서 |
| 종로 | 서울종로경찰서 |
| 남대문 | 서울남대문경찰서 |
| 서대문 | 서울서대문경찰서 |
| 혜화 | 서울혜화경찰서 |
| 용산 | 서울용산경찰서 |
| 성북 | 서울성북경찰서 |
| 동대문 | 서울동대문경찰서 |
| 마포 | 서울마포경찰서 |
| 영등포 | 서울영등포경찰서 |
| 성동 | 서울성동경찰서 |
| 동작 | 서울동작경찰서 |
| 광진 | 서울광진경찰서 |
| 서부 | 서울서부경찰서 |
| 강북 | 서울강북경찰서 |
| 금천 | 서울금천경찰서 |
| 중랑 | 서울중랑경찰서 |
| 강남 | 서울강남경찰서 |
| 관악 | 서울관악경찰서 |
| 강서 | 서울강서경찰서 |
| 강동 | 서울강동경찰서 |
| 종암 | 서울종암경찰서 |
| 구로 | 서울구로경찰서 |
| 서초 | 서울서초경찰서 |
| 양천 | 서울양천경찰서 |
| 송파 | 서울송파경찰서 |
| 노원 | 서울노원경찰서 |
| 방배 | 서울방배경찰서 |
| 은평 | 서울은평경찰서 |
| 도봉 | 서울도봉경찰서 |
| 수서 | 서울수서경찰서 |
+----------------+------------------+# police_station과 주소 매칭하여 나타내기
select c.police_station, p.address
from crime_status c, police_station p
where c.reference = p.name # 매칭
group by c.police_station;>>>
+----------------+-----------------------------------------------------------+
| police_station | address |
+----------------+-----------------------------------------------------------+
| 강남 | 서울특별시 강남구 테헤란로 114길 11 |
| 강동 | 서울특별시 강동구 성내로 33 |
| 강북 | 서울특별시 강북구 오패산로 406 |
| 강서 | 서울특별시 양천구 화곡로 73 |
| 관악 | 서울특별시 관악구 관악로5길 33 |
| 광진 | 서울특별시 광진구 광나루로 447 광진소방서 임시청사 (능동) |
| 구로 | 서울특별시 구로구 가마산로 235 |
| 금천 | 서울특별시 관악구 남부순환로 1435 |
| 남대문 | 서울특별시 중구 한강대로 410 |
| 노원 | 서울특별시 노원구 노원로 283 |
| 도봉 | 서울특별시 도봉구 노해로 403 |
| 동대문 | 서울특별시 동대문구 약령시로 21길 29 |
| 동작 | 서울특별시 동작구 노량진로 148 |
| 마포 | 서울특별시 마포구 마포대로 183 |
| 방배 | 서울특별시 서초구 방배천로 54 |
| 서대문 | 서울특별시 서대문구 통일로 113 |
| 서부 | 서울특별시 은평구 은평로9길 15 |
| 서초 | 서울특별시 서초구 반포대로 179 |
| 성동 | 서울특별시 성동구 왕십리광장로 9 |
| 성북 | 서울특별시 성북구 보문로 170 |
| 송파 | 서울특별시 송파구 중대로 221 |
| 수서 | 서울특별시 강남구 개포로 617 |
| 양천 | 서울특별시 양천구 목동동로 99 |
| 영등포 | 서울특별시 영등포구 국회대로 608 |
| 용산 | 서울특별시 용산구 원효로89길 24 |
| 은평 | 서울특별시 은평구 연서로 365 |
| 종로 | 서울특별시 종로구 율곡로 46 |
| 종암 | 서울특별시 성북구 종암로 135 |
| 중랑 | 서울특별시 중랑구 중랑역로 137 |
| 중부 | 서울특별시 중구 수표로 27 |
| 혜화 | 서울특별시 종로구 창경궁로 112-16 |
+----------------+-----------------------------------------------------------+- FOREIGN KEY 문제
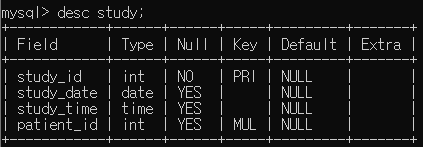
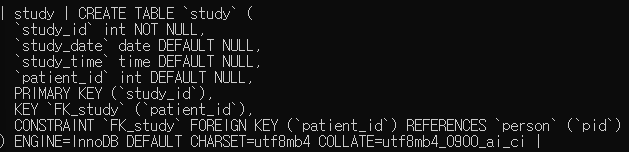
- 다음과 같이 study_id 가 PRIMARY KEY, patient_id 가 person 테이블의 pid 와 연결된 FOREIGN KEY 로 지정된 study 테이블을 생성하세요.

create table study
(
study_id int not null,
study_date date,
study_time time,
patient_id int,
primary key (study_id),
constraint FK_study foreign key (patient_id) references person (pid)
);
2. 생성한 테이블의 PRIMARY KEY 를 삭제하세요.
alter table study
drop primary key;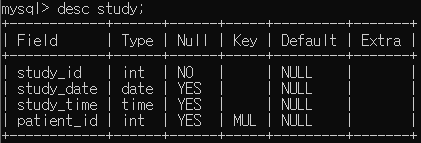
3. 생성한 테이블의 FOREIGN KEY 를 삭제하세요.
alter table study
drop foreign key FK_study;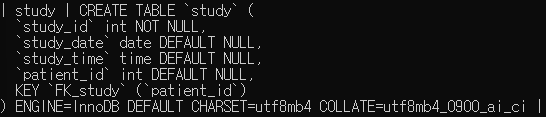
4. study 테이블의 patient_id 를 person 테이블의 pid 와 연결된 FOREIGN KEY 로 등록하세요.
alter table study
add foreign key (patient_id) references person(pid); # 이름 자동 할당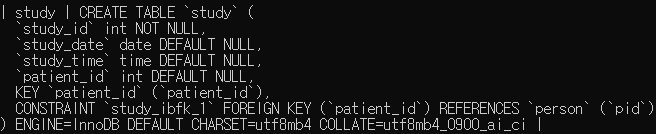
5. study 테이블의 study_id 를 PRIMARY KEY로 등록하세요.
alter table study
add primary key (study_id);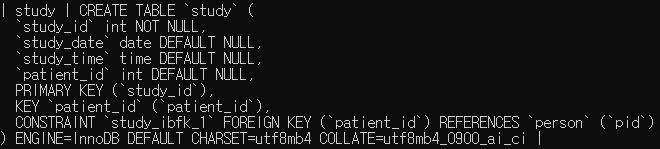
3. Aggregate Functions (집계함수)
- 정의 : 여러 칼럼 혹은 테이블 전체 칼럼으로부터 하나의 결과값을 반환하는 함수
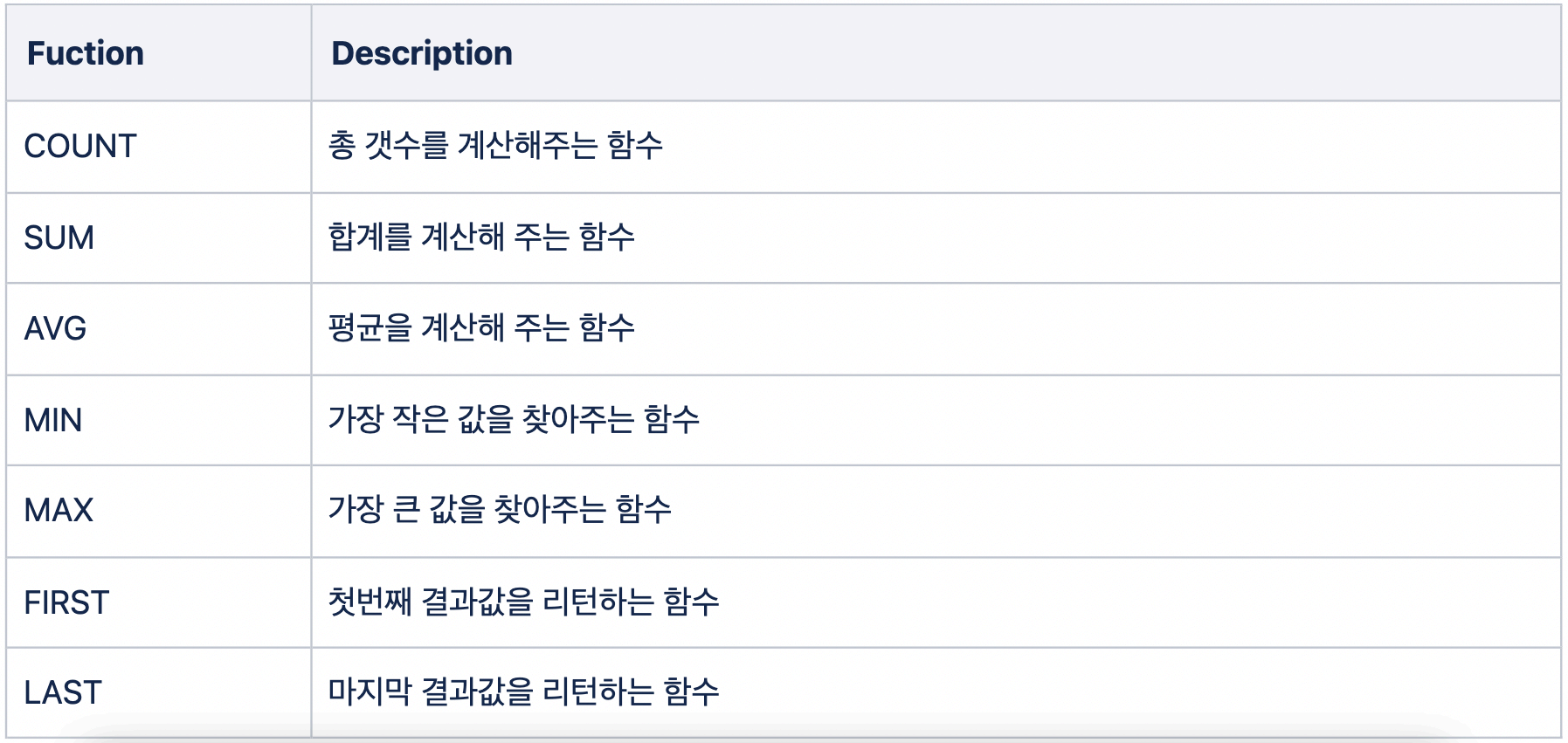
- 실습 환경
- COUNT : 총 갯수를 계산해주는 함수
# police_station 테이블의 데이터 개수
select count(*) from police_station;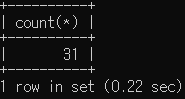
# crime_status 테이블에서 경찰서는 총 몇군데인지 확인 (중복 제거)
select count(distinct police_station) from crime_status;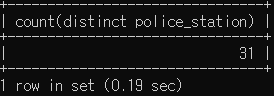
# crime_type은 총 몇가지인지 확인 (중복 제거)
select count(distinct crime_type) from crime_status;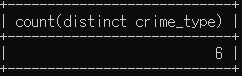
# crime_status 에서 status_type은 무엇인지 확인 (중복 제거)
select distinct status_type from crime_status;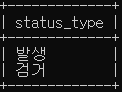
- SUM : 숫자 칼럼의 합계를 계산해주는 함수
# 범죄 총 발생 건수
select sum(case_number)
from crime_status
where status_type='발생';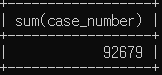
# 살인 총 발생 건수
select sum(case_number)
from crime_status
where status_type='발생' and crime_type like '살인';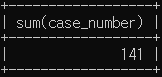
# 중부 경찰서에서 검거된 총 범죄 건수
select sum(case_number)
from crime_status
where status_type='검거' and police_station='중부';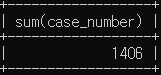
# 종로경찰서와 남대문경찰서의 강도 발생 건수의 합
select sum(case_number)
from crime_status
where (police_station like '종로' or police_station like '남대문')
and crime_type='강도';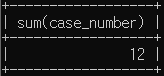
- AVG : 숫자 칼럼의 평균을 계산해주는 함수
# 평균 폭력 검거 건수
select avg(case_number)
from crime_status
where crime_type like '폭력' and status_type='검거';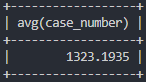
# 중부경찰서 범죄 평균 발생 건수
select avg(case_number)
from crime_status
where police_station like '중부' and status_type like '발생';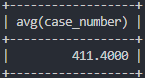
# 구로경찰서와 도봉경찰서의 평균 살인 검거 건수
select avg(case_number)
from crime_status
where (police_station like '구로' or police_station like '도봉')
and crime_type like '살인' and status_type like '검거';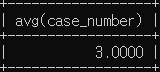
- MIN : 숫자 칼럼 중 가장 작은 값을 찾아주는 함수
# 강도 발생 건수가 가장 적은 경우 몇 건
select min(case_number)
from crime_status
where crime_type like '강도' and status_type='발생';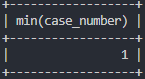
# 중부경찰서에서 가장 낮은 검거 건수
select min(case_number)
from crime_status
where police_station like '중부' and status_type like '검거';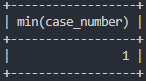
- MAX : 숫자 칼럼 중 가장 큰 값을 찾아주는 함수
# 살인이 가장 많이 검거된 건 수
select max(case_number)
from crime_status
where crime_type like '살인' and status_type like '검거';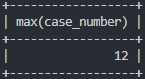
# 강남경찰서에서 가장 많이 발생한 범죄 건 수
select max(case_number)
from crime_status
where police_station like '강남' and status_type like '발생';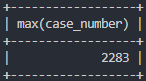
- GROUP BY : 그룹화하여 데이터를 조회
# crime_status에서 경찰서별로 그룹화하여 경찰서 이름을 조회
SELECT police_station
FROM crime_status
GROUP BY police_station
ORDER BY police_station
LIMIT 5;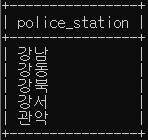
# 경찰서 종류를 검색 - DISTINCT 를 사용하는 경우 (ORDER BY 를 사용할 수 없음)
SELECT DISTINCT police_station
FROM crime_status
LIMIT 5;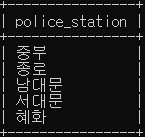
# 경찰서 별로 총 발생 범죄 건수를 검색
SELECT police_station, sum(case_number) 발생건수
FROM crime_status
WHERE status_type LIKE '발생'
GROUP BY police_station
ORDER BY 발생건수 DESC
LIMIT 5;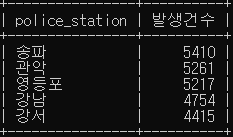
# 경찰서 별로 평균 범죄 검거 건수를 검색
SELECT police_station, avg(case_number) 평균검거건수
FROM crime_status
WHERE status_type LIKE '검거'
GROUP BY police_station
ORDER BY 평균검거건수 DESC
LIMIT 5;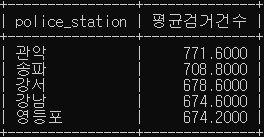
# 경찰서 별 평균 범죄 발생건수와 평균 범죄 검거 건수를 검색
SELECT police_station, status_type, avg(case_number)
FROM crime_status
GROUP BY police_station, status_type
LIMIT 6;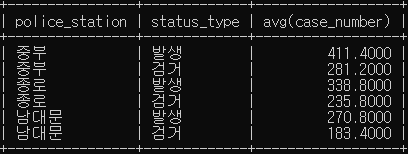
# 경찰서 별로 절도 범죄 평균 발생 건수를 가장 많은 건수 순으로 10개 검색하고 확인하세요.
SELECT police_station, avg(case_number)
FROM crime_status
WHERE crime_type like '절도' AND status_type like '발생'
GROUP BY police_station
ORDER BY avg(case_number) DESC
LIMIT 10;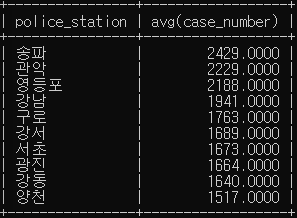
# 경찰서 별로 가장 많이 검거한 범죄 건수를 가장 적은 건수 순으로 5개 검색하세요.
SELECT police_station, max(case_number)
FROM crime_status
WHERE status_type like '검거'
GROUP BY police_station
ORDER BY max(case_number) ASC
LIMIT 5;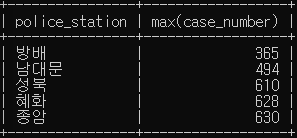
- HAVING : 조건에 집계함수가 포함되는 경우 WHERE 대신 HAVING 사용
# 경찰서 별로 발생한 범죄 건수의 합이 4000 건보다 보다 큰 경우를 검색
SELECT police_station, sum(case_number) count
FROM crime_status
WHERE status_type LIKE '발생'
GROUP BY police_station
HAVING count > 4000;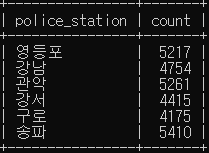
# 경찰서 별로 발생한 폭력과 절도의 범죄 건수 평균이 2000 이상인 경우를 검색
SELECT police_station, avg(case_number)
FROM crime_status
WHERE (crime_type LIKE '폭력' OR crime_type like '절도')
AND status_type LIKE '발생'
GROUP BY police_station
HAVING avg(case_number) >= 2000;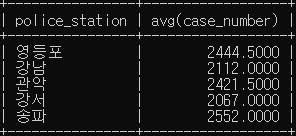
# 경찰서 별로 가장 적게 검거한 건수 중 4건보다 큰 경우를 건수가 큰 순으로 정렬하여 검색하세요.
SELECT police_station, min(case_number)
FROM crime_status
WHERE status_type LIKE '검거'
GROUP BY police_station
HAVING min(case_number) > 4
ORDER BY min(case_number) DESC;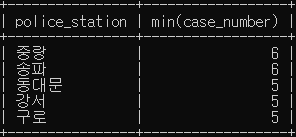
# '대문' 으로 끝나는 이름의 경찰서 별 범죄발생 건수의 평균이 500건 이상인 경우를 검색하세요.
SELECT police_station, avg(case_number)
FROM crime_status
WHERE status_type LIKE '발생' AND police_station LIKE '%대문'
GROUP BY police_station
HAVING avg(case_number) >= 500;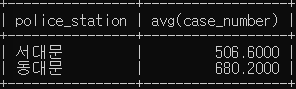
3. Scalar Functions
- 정의 : 입력 값을 기준으로 단일 값을 반환하는 함수

- 실습 환경 만들기
# sandwich.csv to AWS RDS database
import mysql.connector
import pandas as pd
#
conn = mysql.connector.connect(
host = "엔드포인트",
port = 3306,
user = "admin",
password = "비밀번호",
database = "zerobase"
)
#
df = pd.read_csv('sandwich.csv', encoding='utf-8')
df.tail()
df.info()
#
sql = 'create table sandwich (ranking int, cafe varchar(32), menu varchar(32), price float, address varchar(32))'
cursor = conn.cursor(buffered=True)
cursor.execute(sql)
#
cursor.execute('desc sandwich')
result = cursor.fetchall()
for row in result:
print(row)
#
sql = 'insert into sandwich values (%s, %s, %s, %s, %s)'
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()
#
conn.close()- UCASE 문법 : 영문을 대문자로 반환하는 함수
# 다음 문장을 모두 대문자로 조회
SELECT UCASE('This Is ucase Test.');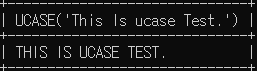
# $15가 넘는 메뉴를 대문자로 조회
SELECT UCASE(menu) FROM sandwich WHERE price > 15;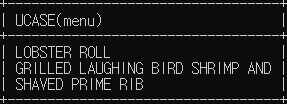
- LCASE 문법 : 영문을 소문자로 반환하는 함수
# 다음 문장을 모두 소문자로 조회
SELECT LCASE('This Is lcase Test.');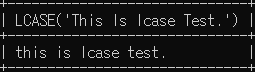
# $5가 안되는 메뉴를 소문자로 조회
SELECT LCASE(menu) FROM sandwich WHERE price < 5;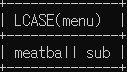
- MID 문법 : 문자열 부분을 반환하는 함수
# 1번 위치에서 4글자를 조회
SELECT MID('This Is lcase Test.', 1, 4);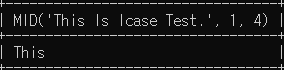
# -4번 위치(뒤에서 4번째 위치)에서 4글자를 조회
SELECT MID('This Is lcase Test.', -4, 4);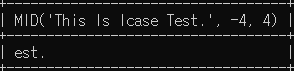
# 11위 카페이름 중 두번째 단어만 조회 - 6번 위치에서 4글자
SELECT MID(cafe, 6, 4) FROM sandwich WHERE ranking = 11;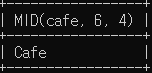
- LENGTH 문법 : 문자열의 길이를 반환하는 함수
# 다음 문장의 길이를 조회
SELECT LENGTH('This is len test');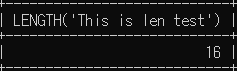
# 문자가 없는 경우 길이도 0
SELECT LENGTH('');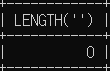
# 공백의 경우에도 문자이므로 길이가 1
SELECT LENGTH(' ');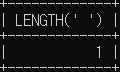
# NULL 의 경우 길이가 없으므로 NULL
SELECT LENGTH(NULL);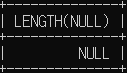
# sandwich 테이블에서 Top 3의 주소 길이를 검색
SELECT LENGTH(address), address FROM sandwich WHERE ranking <= 3;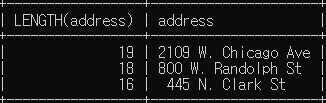
- Round 문법 : 지정한 자리에서 숫자를 반올림하는 함수
# 반올림할 위치를 지정하지 않을 경우, 소수점 자리 (0) 에서 반올림
SELECT ROUND(315.625);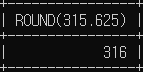
# 소수점 첫번째 위치는 0
SELECT ROUND(315.625, 0);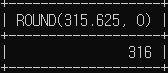
# 두번째 소수점 위치는 1
SELECT ROUND(315.625, 1);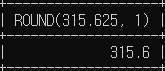
# 십단위 위치는 -2
SELECT ROUND(315.625, -2);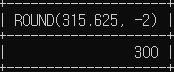
# sandwich 테이블에서 소수점 자리는 반올림해서 1달러 단위까지만 표시 (최하위 3개만 표시)
SELECT ranking, price, ROUND(price)
FROM sandwich
ORDER BY ranking DESC
LIMIT 3;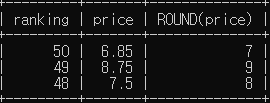
- NOW 문법 : 현재 날짜 및 시간을 반환하는 함수
SELECT NOW();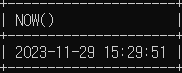
- FORMAT 문법 : 숫자를 천단위 콤마가 있는 형식으로 반환하는 함수
- 반환된 값이 string 이기 때문에 ROUND와 다름.
# 소수점을 표시하지 않을 경우 0
SELECT FORMAT(12345.6789, 0);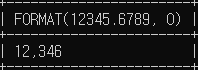
# 소수점 두자리까지 표시할 경우 2
SELECT FORMAT(12345.6789, 2);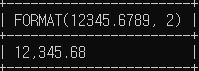
# 소수점 열자리까지 표시
SELECT FORMAT(12345.6789, 0);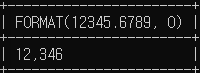
# oil_price 테이블에서 가격이 백원단위에서 반올림 했을 때 2000원 이상인 경우 천원단위에 콤마를 넣어서 조회
SELECT 상호, FORMAT(가격, 0)
FROM oil_price
WHERE ROUND(가격, -3) >= 2000;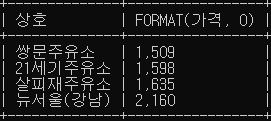
- Scalar Function 문제
# sandwich 테이블에서 가계이름은 대문자, 메뉴이름은 소문자로 조회하세요
SELECT UCASE(cafe), LCASE(menu) FROM sandwich;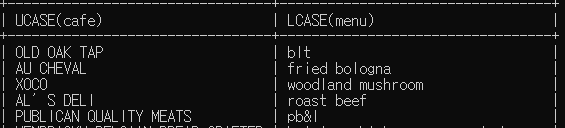
# sandwich 테이블에서 10위 메뉴의 마지막 단어를 조회하세요.
select ranking, cafe, mid(menu, -3, 3) from sandwich where ranking=10;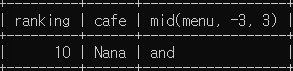
# sandwich 테이블에서 메뉴 이름의 평균 길이를 조회하세요.
select avg(length(menu)) from sandwich;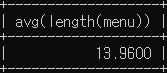
# oil_price 테이블에서 가격을 십원단위에서 반올림해서 조회하세요.
select round(가격, -2) from oil_price;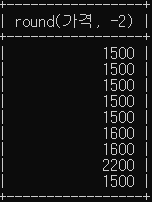
# oil_price 테이블에서 가격이 십원단위에서 반올림 했을 때 2000원 이상인 경우,
천단위에 콤마를 넣어서 조회하세요.
select format(가격, 0), 가격
from oil_price
where round(가격, -2) >= 2000;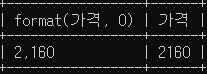
4. SQL Subquery
- 정의 : 하나의 SQL 문 안에 포함되어 있는 또 다른 SQL 문을 말한다.메인쿼리가 서브쿼리를 포함하는 종속적인 관계이다.
- 서브쿼리는 메인쿼리의 칼럼 사용 가능
- 메인쿼리는 서브쿼리의 칼럼 사용 불가
- Subquery 사용시 주의
- Subquery는 괄호로 묶어서 사용
- 단일 행 혹은 복수 행 비교 연산자와 함께 사용 가능
- Subquery에서는 order by를 사용 불가
- Subquery 종류
- 스카라 서브쿼리 (Scalar Subquery) - SELECT 절에 사용
- 인라인 뷰 (Inline View) - FROM 절에 사용
- 중첩 서브쿼리 (Nested Subquery) - WHERE 절에 사용
- Scalar Subquery : SELECT 절에서 사용하는 서브쿼리. 결과는 하나의 Column이어야 한다.
# 서울은평경찰서의 강도 검거 건수와 서울시 경찰서 전체의 평균 강도 검거 건수를 조회
SELECT case_number,
(SELECT avg(case_number)
FROM crime_status
WHERE crime_type LIKE '강도' AND status_type LIKE '검거') avg # 하나의 컬럼
FROM crime_status
WHERE police_station Like '은평' AND crime_type LIKE '강도' AND status_type Like '검거';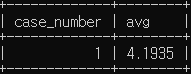
- Inline View : FROM 절에 사용하는 서브쿼리. 메인쿼리에서는 인라인 뷰에서 조회한 Column 만 사용가능하다
# 경찰서별로 가장 많이 발생한 범죄 건수와 범죄 유형을 조회
SELECT c.police_station, c.crime_type, c.case_number
FROM crime_status c,
(SELECT police_station, max(case_number) count
FROM crime_status
WHERE status_type LIKE '발생'
GROUP BY police_station) m # 테이블 형태
WHERE c.police_station = m.police_station # join 두가지 조건
AND c.case_number = m.count; 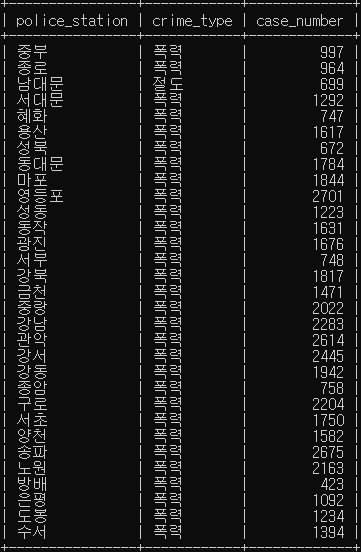
- Nested Subquery : WHERE 절에서 사용하는 서브쿼리.
- Single Row : 하나의 열을 검색하는 서브쿼리
- 서브쿼리가 비교연산자( =, >, >=, <, <=, <>, !=)와 사용되는 경우
- 서브쿼리의 검색 결과는 한 개 행의 결과값을 가져야 한다. (두개 이상인 경우 에러)
SELECT name
FROM celeb
WHERE name = (SELECT host
FROM snl_show
WHERE id = 1); # 한 개의 행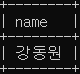
- Multiple Row : 하나 이상의 행을 검색하는 서브쿼리
- IN : 서브쿼리 결과 중에 포함 될때
# SNL에 출연한 영화배우를 조회 SELECT host FROM snl_show WHERE host IN (Select name FROM celeb WHERE job_title LIKE '%영화배우%'); # 하나 이상의 행
- EXISTS : 서브쿼리 결과에 값이 있으면 반환
# 범죄 검거 혹은 발생 건수가 2000건 보다 큰 경찰서 조회 SELECT name FROM police_station p WHERE EXISTS (SELECT police_station FROM crime_status c WHERE p.name = c.reference AND case_number > 2000);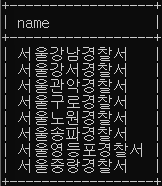
- ANY : 서브쿼리 결과 중에 최소한 하나라도 만족하면 (비교 연산자 사용)
# SNL 에 출연한 적이 있는 연예인 이름 조회 SELECT name FROM celeb WHERE name = ANY (SELECT host FROM snl_show);
- ALL : 서브쿼리 결과를 모두 만족하면 (비교 연산자 사용)
SELECT name FROM celeb WHERE name = ALL (SELECT host FROM snl_show WHERE id = 1);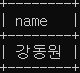
- IN : 서브쿼리 결과 중에 포함 될때
- Multiple Column : 하나 이상의 열을 검색하는 서브쿼리
- 서브쿼리 내에 메인쿼리 컬럼이 같이 사용되는 경우
# 강동원과 성별, 소속사가 같은 연예인의 이름, 성별, 소속사를 조회
SELECT name, sex, agency
FROM celeb
WHERE (sex, agency) IN (SELECT sex, agency
FROM celeb
WHERE name = '강동원');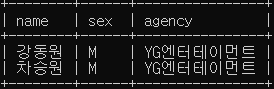
- SQL Subquery 문제
- oil_price 테이블에서 셀프주유의 평균가격과 SK에너지의 가장 비싼 가격을
Scalar Subquery 를 사용하여 조회
- oil_price 테이블에서 셀프주유의 평균가격과 SK에너지의 가장 비싼 가격을
select * from oil_price limit 1;
select avg(가격) from oil_price where 셀프='Y';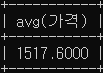
select max(가격) from oil_price where 상표='SK에너지';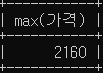
SELECT max(가격), (SELECT avg(가격) From oil_price WHERE 셀프='Y')
FROM oil_price
WHERE 상표='SK에너지';
- oil_price 테이블에서 상표별로 가장 비싼 가격과 상호를 Inline View 를 사용하여 조회하세요.
select 상표, max(가격)
from oil_price
group by 상표;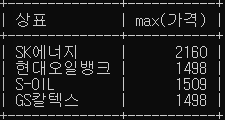
select o.상호, o.상표, s.max_price
from oil_price o,
(select 상표, max(가격) max_price from oil_price group by 상표) s
where o.상표 = s.상표 and o.가격 = s.max_price;
- 평균가격 보다 높은 주유소 상호와 가격을 Nested Subquery 를 사용하여 조회하세요.
select avg(가격) from oil_price;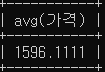
select 상호, 가격
from oil_price
where 가격 > (select avg(가격) from oil_price);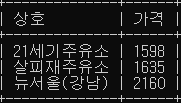
- 3번에서 조회한 주유소에서 주유한 연예인의 이름과 주유소, 주유일을
Nested Subquery 를 사용하여 조회하세요. (refueling 테이블)
- 3번에서 조회한 주유소에서 주유한 연예인의 이름과 주유소, 주유일을
select * from refueling limit 1;
select 이름, 주유소, 주유일
from refueling
where 주유소 in (select 상호 from oil_price where 가격 > (select avg(가격) from oil_price));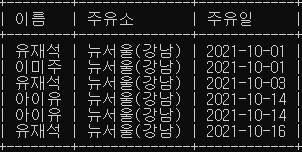
- refueling 테이블과 oil_price 테이블에서 10만원 이상 주유한 연예인 이름, 상호, 상표, 주유 금액, 가격을 Inline View 를 사용하여 조회하세요.
select 이름, 주유소, 금액 from refueling where 금액 >= 100000;
select r.이름, o.상호, o.상표, r.금액, o.가격
from oil_price o, (select 이름, 주유소, 금액 from refueling where 금액 >= 100000) r
where o.상호 = r.주유소;
