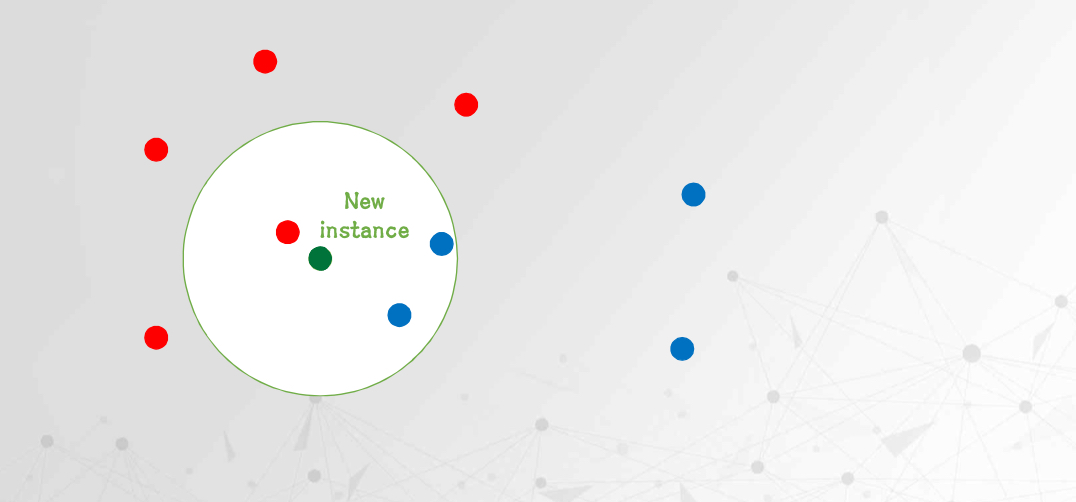
지도학습, 분류와 회귀
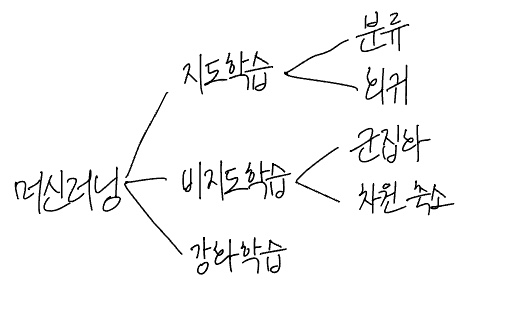
머신러닝은 크게 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning) 으로 나뉜다.
이 중 지도학습은 정답(레이블)이 있는 데이터를 기반으로 모델을 학습시키는 방법이다.
지도학습은 예측하려는 값의 형태에 따라 크게 분류(Classification) 와 회귀(Regression) 로 나눌 수 있다.
분류 vs 회귀
먼저 분류는
“이게 뭐야?” 를 맞히는 문제라고 생각하면 된다.
예를 들면 다음과 같다.
- 학생인가 / 회사원인가
- 스팸 메일인가 / 정상 메일인가
- 고양이인가 / 강아지인가
즉, 정해진 범주 중 하나를 선택하는 문제로,
데이터에 이름표(label)를 붙이는 작업이라고 이해하면 된다.
반면 회귀는
“얼마야?” 를 맞히는 문제다.
- 이 집의 가격은 얼마인가
- 내일 기온은 몇 도일까
처럼 연속적인 숫자 값을 예측하는 것이 목적이다.
정리하면 다음과 같다.
- 분류: 입력 데이터를 보고 어떤 범주에 속하는지 맞히는 것
- 회귀: 입력 데이터를 보고 연속적인 수치 값을 예측하는 것
분류 알고리즘의 예
대표적인 분류 알고리즘으로는 다음과 같은 것들이 있다.
- KNN (K-Nearest Neighbor)
- Decision Tree
- Logistic Regression
이번 게시글에서는 이 중 KNN에 대해 다뤄보려고 한다.
KNN의 개념
KNN은 K-Nearest Neighbor,
즉 K-최근접 이웃의 약자다.
새로운 데이터가 들어오면,
기존 학습 데이터들과의 거리(distance) 를 계산한 뒤
가장 가까운 K개의 이웃을 참고해 예측을 수행한다.
분류 문제에서는
가까운 K개의 데이터가 속한 클래스를 기준으로 다수결(Majority Vote) 을 통해
새로운 데이터의 클래스를 결정한다.
K 값에 따른 분류 예시
아래 그림에서 초록색 점이 새롭게 분류할 데이터라고 가정해보자.
K = 1 인 경우

가장 가까운 1개의 데이터만 참고한다.
이 경우, 가장 가까운 이웃이 속한 클래스가 곧 예측 결과가 된다.
K = 3 인 경우
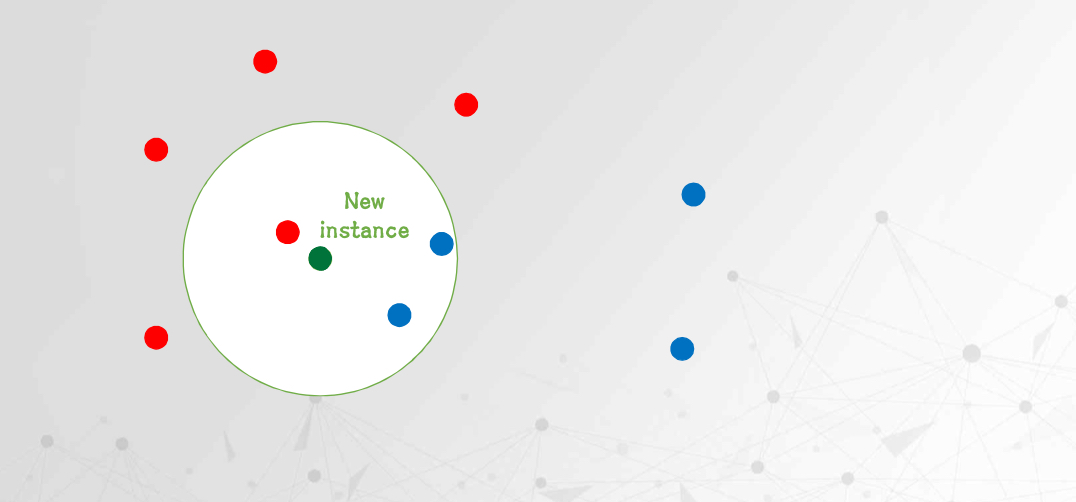
가장 가까운 3개의 데이터를 기준으로 판단한다.
이 중 2개가 파란색 클래스, 1개가 빨간색 클래스이므로
새로운 데이터는 파란색 클래스로 분류된다.
KNN의 하이퍼파라미터
KNN에서 중요한 하이퍼파라미터는 크게 두 가지다.
-
K : 몇 개의 이웃을 참고해 예측을 수행할 것인가
-
Distance Measure : 데이터 사이의 거리를 어떻게 측정할 것인가
즉,
“몇 명의 이웃에게 물어볼지”
“가까움의 기준을 무엇으로 할지”
를 정하는 과정이라고 볼 수 있다.
K 값이 너무 작거나 클 때의 문제
-
K가 너무 작은 경우
- 데이터의 지역적 특성을 지나치게 반영
- 노이즈에 민감
- 과적합(overfitting) 발생 가능
-
K가 너무 큰 경우
- 멀리 있는 데이터까지 과도하게 고려
- 지역적인 특성을 놓침
- 과소적합(underfitting) 발생 가능
따라서 K 값은
과적합과 과소적합 사이에서 균형을 이루는 방향으로 선택해야 한다.
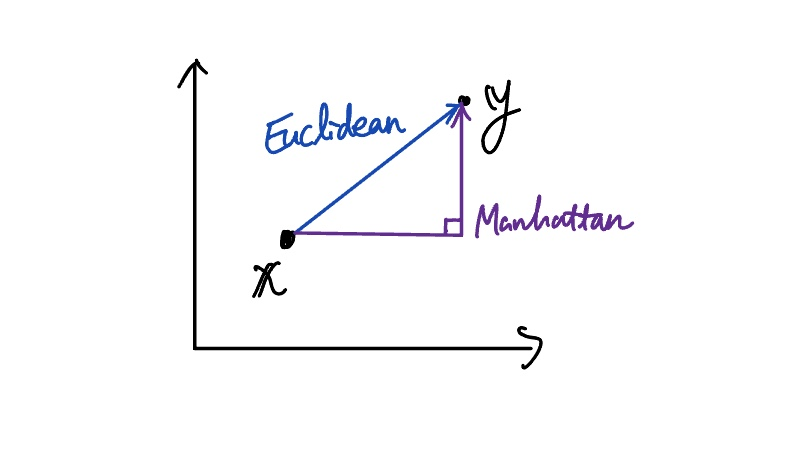
KNN의 거리 측정 방식과 정규화의 필요성
대표적으로 사용되는 거리 측정 방식에는
Euclidean distance, Manhattan distance, Mahalanobis distance 가 있다.
1. Euclidean Distance (유클리디안 거리)
유클리디안 거리는
두 점 사이의 직선 거리를 의미한다.
우리가 좌표평면에서 점 두 개를 찍고
자로 재는 가장 익숙한 거리라고 생각하면 된다.
유클리디안 거리는
모든 feature가 비슷한 범위와 단위를 가진다는 전제가 깔려 있다.
따라서 스케일 차이가 큰 경우, 특정 feature가 거리 계산을 지배하게 된다.
2. Manhattan Distance (맨해튼 거리)
맨해튼 거리는
각 좌표축 방향으로 이동한 거리의 절댓값 합으로 정의된다.
이름처럼 맨해튼의 격자형 도로를 따라
가로·세로로만 이동한다고 생각하면 이해하기 쉽다.
맨해튼 거리는
feature 간 독립성이 강한 경우나
희소한 데이터(sparse data)에서 자주 사용된다.
3. Mahalanobis Distance (마할라노비스 거리)
마할라노비스 거리는
단순히 값의 차이만 보는 것이 아니라
데이터의 분산과 공분산 구조를 함께 고려한 거리다.
즉,
“이 방향의 차이는 흔한가, 드문가?”
를 반영한 거리 측정 방식이다.
KNN에서는 자주 쓰이지는 않지만,
데이터 분포를 고려한 통계적 거리 개념으로 알아두면 좋다.
왜 KNN에서는 정규화가 필요한가?
KNN은 거리 기반 알고리즘이기 때문에,
feature들의 스케일 차이가 그대로 거리 계산에 반영된다.
예를 들어,
- 키: 150 ~ 190
- 연봉: 3,000 ~ 20,000
이 두 feature를 정규화 없이 사용하면
연봉 차이가 거리 계산을 거의 전부 지배하게 된다.
이 경우,
- 키 정보는 사실상 무시되고
- “연봉이 비슷한 데이터”만 이웃으로 선택된다
즉,
의도하지 않은 feature 하나가 거리 기준을 왜곡하게 된다.
정규화의 역할
정규화(normalization 또는 scaling)는
서로 다른 범위를 가진 feature들을
비슷한 스케일로 맞춰주는 과정이다.
정규화를 수행하면,
- 모든 feature가 거리 계산에 공평하게 기여
- 이웃 선택 기준이 더 의미 있는 유사도로 바뀜
- K 값 변화에 따른 성능도 더 안정적
그래서 KNN에서는
정규화는 선택이 아니라 전제 조건
이라고 볼 수 있다.
KNN 알고리즘의 장단점
지금까지 KNN의 개념, 거리 측정 방식, 정규화의 필요성까지 살펴봤다.
마지막으로 KNN 알고리즘의 장점과 단점을 정리해보자.
장점
-
노이즈의 영향을 상대적으로 덜 받는다
단일 데이터 하나에 의존하지 않고,
여러 이웃(K개)을 기준으로 판단하기 때문에
일부 노이즈가 결과에 미치는 영향이 완화된다. -
데이터의 분산을 고려하면 노이즈에 더 강해진다
거리 기반으로 이웃을 선택하기 때문에
데이터 분포를 잘 반영할수록 안정적인 분류가 가능하다. -
학습 데이터의 수가 많을수록 효과적이다
데이터가 충분히 많다면
새로운 데이터 주변에 유사한 이웃이 존재할 확률이 높아져
예측 성능이 향상될 수 있다.
단점
-
K 값이라는 하이퍼파라미터를 직접 설정해야 한다
K가 너무 작으면 과적합,
너무 크면 과소적합 문제가 발생할 수 있어
적절한 K 값을 찾는 과정이 필요하다. -
데이터 특성에 맞는 거리 척도 선택이 어렵다
Euclidean, Manhattan, Mahalanobis 등
어떤 거리 척도를 쓰느냐에 따라 결과가 크게 달라질 수 있다. -
예측 시 계산 비용이 크다
새로운 관측치가 들어올 때마다
학습 데이터 전체와의 거리를 계산해야 하므로
데이터가 많아질수록 예측 속도가 느려진다.
정리
KNN은 구조가 단순하고 직관적인 알고리즘이지만,
거리 정의와 정규화, K 값 선택에 따라 성능 차이가 크게 발생한다.
따라서 KNN은
- 데이터 규모가 너무 크지 않고
- feature 스케일이 잘 정리되어 있으며
- 지역적인 유사성이 중요한 문제
에서 특히 효과적으로 사용할 수 있는 분류 알고리즘이다.
KNN 실습 예제
이번에는 Iris 데이터셋을 활용한 KNN 분류 코드 예제를 통해,
데이터를 어떻게 전처리하고,
교차 검증으로 최적의 K 값을 선택하며,
학습 데이터와 테스트 데이터의 비율(test_size)이 모델 성능에 어떤 영향을 미치는지를 살펴본다.
특히 이 예제에서는
- test_size를 여러 값으로 바꿔가며
- 매번 교차 검증을 통해 최적의 K를 찾고
- 그 결과 정확도(Accuracy)가 어떻게 변하는지를 시각적으로 확인한다.
0. 라이브러리 불러오기
# 라이브러리 불러오기
import numpy as np # numpy: 수치 계산(배열, argmax 등)
import pandas as pd # pandas: 표 형태(DataFrame)로 데이터 보기 편하게
import matplotlib.pyplot as plt # matplotlib: 그래프 시각화
import seaborn as sns # seaborn: 통계 시각화(이 코드에서는 사실상 사용되지 않음)
from mpl_toolkits.mplot3d import Axes3D # 3D 그래프 그릴 때 사용(이 코드에서는 사용되지 않음)
from sklearn import datasets # scikit-learn 예제 데이터셋(iris 등) 불러오기
from sklearn.model_selection import train_test_split, cross_val_score
# train_test_split: 학습/테스트 데이터 분할
# cross_val_score: 교차 검증을 통한 모델 성능 평가
from sklearn.neighbors import KNeighborsClassifier # KNN 분류 모델
from sklearn.preprocessing import StandardScaler
# StandardScaler: 각 feature를 평균 0, 표준편차 1로 만들어 스케일을 맞춤참고
seaborn,Axes3D는 지금 코드에서는 실제로 쓰이지 않는다.
(나중에 히트맵/3D 시각화 추가할 거면 의미 있음)
1. Iris 데이터셋 로드 및 전처리
# 1. Iris 데이터셋 로드 및 전처리
iris = datasets.load_iris() # iris 데이터셋 로드
X = iris.data # 입력 데이터(feature) (shape: 150 x 4)
y = iris.target # 정답(label) (0, 1, 2)
feature_names = iris.feature_names # feature 이름 리스트X: 꽃받침/꽃잎의 길이·너비 등 4개의 특성(feature)y: 품종 클래스(0=setosa, 1=versicolor, 2=virginica)
2. DataFrame으로 변환 (확인용)
이 부분은 모델 학습에 필수는 아니고,
데이터를 사람이 보기 쉽게 확인하기 위한 과정이다.
# 데이터를 다루기 쉬운 pandas DataFrame 형태로 변환
iris_df = pd.DataFrame(data=X, columns=iris.feature_names)
# 'species'라는 새로운 컬럼을 추가하여,
# 숫자 형태의 정답(y)을 실제 품종 이름으로 변환해 저장
iris_df['species'] = iris.target_names[y]iris_df는 (feature 4개 + species 1개)로 구성된다.- 예를 들어 y가 0이면 species는 'setosa'로 바뀐다.
3. 데이터 표준화 (StandardScaler)
KNN은 거리 기반이라 feature 스케일이 거리 계산에 직접 영향을 준다.
그래서 표준화를 먼저 한다.
# 데이터 표준화 (스케일 조정)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)fit_transform(X)는fit: 평균/표준편차 계산transform: 그 기준으로 변환
을 한 번에 수행한다.
※ 엄밀히 말하면, 데이터 누수 방지를 위해
scaler는 train 데이터로만 fit하고 test에는 transform만 적용하는 게 정석이다.
(이 코드는 실습/비교용으로 전체에 한 번 적용한 형태)
4. test_size를 바꿔가며 정확도 비교 준비
test_sizes = [0.1, 0.2, 0.3, 0.4, 0.5] # 테스트 데이터 비율 후보들
accuracy_results = [] # 각 test_size에서의 최종 정확도를 저장- test_size가 커질수록
- 테스트 데이터는 많아지지만
- 학습 데이터는 줄어든다
→ 성능이 어떻게 변하는지 보는 것이 목적이다.
5. test_size별 반복 학습 + 최적 K 탐색(CV)
이 루프가 코드의 핵심이다.
for size in test_sizes:
# (1) 현재 test_size 비율로 train/test 분할
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=size, random_state=42
)
# (2) K 후보(1~20) 중에서 최적 K를 교차 검증으로 찾기
k_values = list(range(1, 21)) # k값 후보 리스트
cv_scores = [] # 각 k의 교차 검증 평균 정확도를 저장할 리스트
for k in k_values:
knn_cv = KNeighborsClassifier(n_neighbors=k)
# 5-fold 교차 검증:
# train 데이터를 5개로 나눠 번갈아 검증하며 평균 정확도를 계산
scores = cross_val_score(
knn_cv, X_train, y_train,
cv=5, scoring='accuracy'
)
cv_scores.append(scores.mean())
# (3) 평균 정확도가 가장 높은 k를 best_k로 선택
best_k = k_values[np.argmax(cv_scores)]
# (4) best_k로 최종 모델 학습
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)
# (5) 테스트 데이터로 최종 정확도 평가
accuracy = knn.score(X_test, y_test)
accuracy_results.append(accuracy)
# (6) 결과 출력
print(f"test_size = {size}, best_k = {best_k}, Accuracy = {accuracy:.4f}")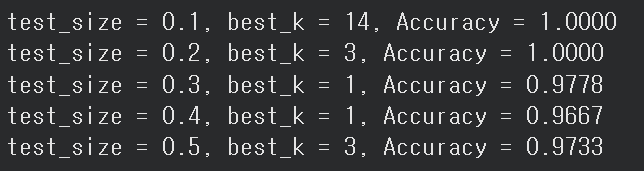
-
test_size가 0.1, 0.2인 경우
학습 데이터의 비율이 충분히 높아(90%, 80%)
KNN이 안정적인 이웃 구성을 할 수 있었고,
그 결과 테스트 정확도가 100%로 나타났다. -
test_size가 증가함에 따라
학습 데이터의 양이 줄어들고,
이에 따라 최적의 K 값이 점점 작아지는 경향을 보였다.
이는 학습 데이터가 적을수록
넓은 범위의 이웃을 포함하는 큰 K가 오히려
분류 성능을 저하시킬 수 있기 때문이다. -
test_size가 0.3 이상인 구간에서는
versicolor와 virginica처럼 분포가 겹치는 클래스에서
오분류가 발생하며 정확도가 소폭 하락했다.
이 결과는 KNN이
학습 데이터의 양과 이웃(K) 구성에 매우 민감한 알고리즘임을 보여준다.
여기서 중요한 포인트
왜 교차 검증을 쓰나?
- test 데이터는 “최종 평가”를 위해 남겨둬야 한다.
- K를 고르는 과정에서 test를 써버리면
test 성능이 과대평가될 수 있다(데이터 누수/과적합).
그래서 K 선택은 train 내부에서 교차 검증(CV) 으로 진행한다.
test_size가 바뀌면 best_k도 바뀔 수 있다
- train 데이터가 줄어들면
- 작은 K는 노이즈에 민감해질 수 있고
- 큰 K는 과소적합이 될 수 있다
- 따라서 최적 K는 상황(데이터 양)에 따라 달라질 수 있다.
6. test_size vs accuracy 시각화
마지막으로 test_size 변화에 따른 성능을 선 그래프로 그린다.
plt.figure(figsize=(10, 6))
plt.plot(test_sizes, accuracy_results, marker='o', linestyle='--')
plt.title('Test Size vs. Model Accuracy')
plt.xlabel('Test Size Ratio')
plt.ylabel('Accuracy')
plt.xticks(test_sizes)
plt.grid(True)
plt.show()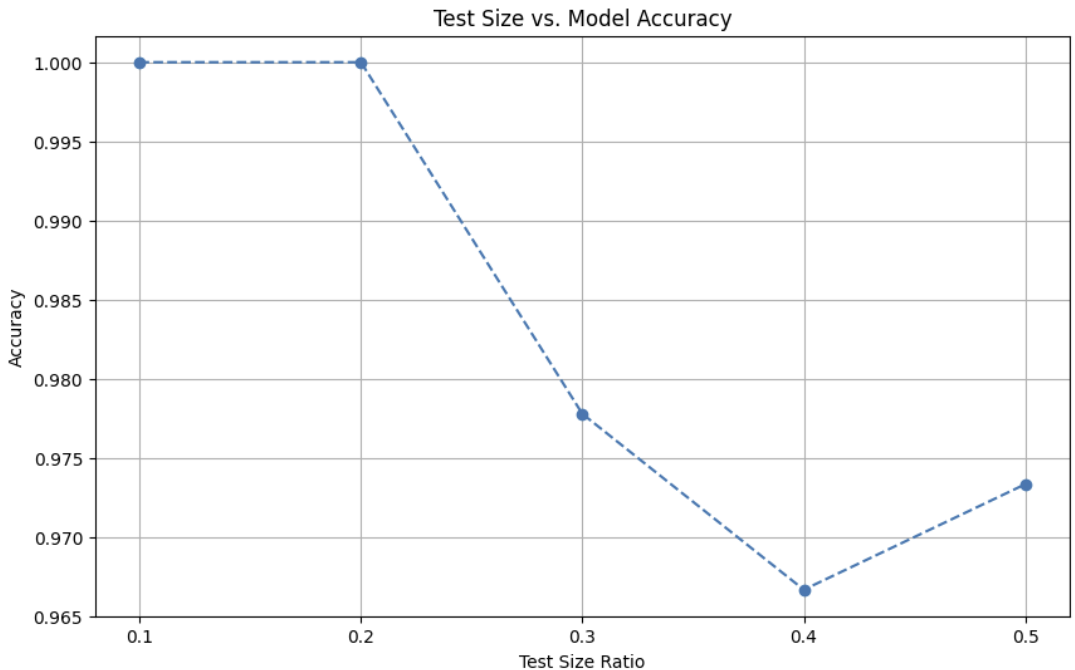
그래프는 test_size 비율에 따라
KNN 분류기의 테스트 정확도가 어떻게 변하는지를 시각적으로 보여준다.
-
전반적으로 test_size가 증가할수록
정확도가 감소하는 경향을 확인할 수 있다.
이는 테스트 데이터가 많아질수록
학습 데이터가 줄어들어 KNN의 이웃 기반 판단이
불안정해지기 때문이다. -
test_size = 0.1, 0.2 구간에서는
충분한 학습 데이터 덕분에
매우 높은 정확도를 유지한다. -
test_size = 0.4에서 정확도가 가장 낮게 나타나는데,
이 구간에서는 최적 K 값이 매우 작아져(K=1)
단일 이웃에 의존하는 분류가 이루어졌고,
그로 인해 노이즈와 경계 데이터에 취약해진 결과로 해석할 수 있다. -
test_size = 0.5에서는
최적 K 값이 다시 증가하면서
정확도가 소폭 회복되는 모습을 보인다.
이 그래프는
데이터 분할 비율 선택이 KNN 성능에 직접적인 영향을 미치며,
적절한 test_size와 K 값을 함께 고려해야 함을 보여준다.
