
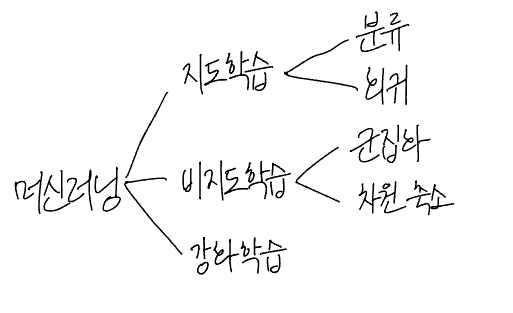
이번 게시글에서는 비지도학습 중 차원축소에 해당하는 PCA에 대해 알아보고자 한다.
비지도학습이란 지도학습과 달리 정답이 없는 상태에서 학습 알고리즘이 스스로 입력데이터에서 패턴을 발견하는 학습방법이다.
PCA의 필요성 (차원의 저주)
현실 속의 데이터는 고차원의 데이터가 많다.
테이블 형태의 데이터가 있을 때, 열의 개수가 아주 많으면 고차원의 데이터라고 한다. 또한 텍스트 데이터는 단어 수만큼의 차원(수만~수십만)을 가지게 되고, 이미지의 경우 픽셀 수(ex: 28×28=784)만큼의 차원, 로그 데이터는 사용자 행동 feature가 수백~수천으로, 이들은 모두 고차원의 데이터이다.
이런 경우 모델 학습에 필요한 데이터의 양이 차원에 지수적으로 증가하는 "차원의 저주"에 걸리게 된다.
차원의 저주란
- 데이터가 희소(sparse)해짐
차원이 커질수록 “공간”이 기하급수적으로 커져서, 같은 데이터 개수로는 공간을 촘촘히 채울 수 없음
-> 이웃(neighbor) 개념이 약해지고, 거리 기반 방법(KNN 등)도 불안정해짐.- 필요한 데이터량이 폭발함
같은 품질의 일반화 성능을 얻으려면 샘플 수가 차원에 따라 급격히 늘어남.
-> 학습이 느려지고 과적합도 쉬워짐.
따라서 우리는 고차원의 데이터를 저차원의 데이터로 축소해야한다.
PCA란 무엇인가
“고차원 데이터를 더 적은 차원으로 표현하되, 중요한 정보를 빼놓지 않고 담는다.”
PCA는 Principle Component Analysis의 약자로, 주성분 분석이라는 뜻을 담고있다.
즉 고차원의 데이터를 저차원의 데이터로 축소시키는 알고리즘이며, 다음 두가지 본질이 중요하다.
1) 정보를 최대한 유지하면서 줄인다
차원축소는 단순히 feature 개수를 줄이는 작업이 아니라, 중요한 정보만 남기고 불필요한 성분을 제거하는 데 있다. 즉 데이터의 여러 가지 특징 중에서 가장 '주요(Principal)'한 '성분(Component)'을 찾아내겠다는 뜻이며, 이러한 본질 때문에 "주성분 분석"이라는 이름이 붙은걸로 이해할 수 있다.
- 서로 강하게 상관된 feature(중복 정보) 제거
- 노이즈 성분 제거
- 데이터의 중요한 구조 보존
- 패턴
- 군집 구조
- 데이터가 퍼져 있는 주요 방향성
-> 데이터의 본질적 구조를 보존하는 것이 목적이다.
2) 표현을 더 쉽고 빠르게 만든다
차원이 줄어들면 계산과 학습이 훨씬 효율적이다.
- 계산량 감소 (시간 / 메모리 절약)
- 모델 파라미터 수 감소 → 과적합 완화
- 2D / 3D 시각화를 통한 구조 이해 가능
-> 따라서 차원축소는 전처리 단계에서도 자주 사용된다.
수학적 표현
PCA를 제대로 이해하기 위해서는, 기저, 선형변환, 정사영 등 선형대수의 핵심 개념을 먼저 이해해야 한다.
PCA는 본질적으로 데이터가 놓인 좌표계를 어떻게 바꿀 것인가에 대한 문제이기 때문이다.
1) 데이터는 벡터이고, 벡터는 좌표다
머신러닝에서 하나의 데이터 샘플은 보통 벡터로 표현된다.
여기서 중요한 사실은, 이 벡터의 값이 절대적인 의미를 갖는 것이 아니라,
어떤 기저에서 표현된 좌표인가에 따라 해석이 달라진다는 점이다.
2) 기저(Basis): 좌표계를 정의하는 축들
공간의 기저란 다음 조건을 만족하는 벡터들의 집합이다.
- 서로 선형독립(linearly independent)
- 공간 전체를 span함
선형독립(linearly independent)이란- “축이 겹치지 않는다”
예를 들어 2차원 공간에서
- (1, 0)
- (2, 0)
이 두 벡터를 생각해보면, 방향이 완전히 같다. 두 번째 벡터는 첫 번째 벡터를 늘린 것일 뿐이다.
이런 경우는 새로운 방향을 전혀 추가하지 못한다. 축을 두 개 둔 것처럼 보이지만 사실상 하나뿐이다.
반면
- (1, 0)
- (0, 1)
이 두 벡터는 서로 완전히 다른 방향이다. 하나로 다른 하나를 만들 수 없고, 각자 맡은 방향이 다르다.
이때 비로소 각 축이 서로 다른 정보를 담당하게 된다.
그래서 선형독립이란, 각 기저 벡터가 고유한 방향을 하나씩 책임지는 상태라고 이해하면 된다.
공간을 span한다는 것의 의미- “빈 곳이 없다”
즉 이 축들만 이용해서 공간 안의 모든 점에 갈 수 있다.
2차원 공간에서 (1, 0) 하나만 있으면,
- x축 위로는 이동 가능
- 위아래(y방향)로는 절대 이동 불가
-> 즉, 공간의 일부만 커버한 상태다.
반면
- (1, 0)
- (0, 1)
이 두 축이 있으면,
- 좌우 + 상하
- 어느 점이든 도달 가능
-> 이때 “공간 전체를 span한다”고 말한다.
즉 span이란 좌표계에 빈 방향이 하나도 없는 상태 라고 생각하면 된다.
3) 기저변환: 벡터는 그대로, 좌표계만 바꾼다
이제 새로운 기저를 생각해보자.
여기서 각 는 의 기저 벡터이다.
만약 이 기저가 직교정규라면,
벡터 를 이 새로운 기저 에서의 좌표로 표현하면
가 된다.
중요한 해석은 다음과 같다.
기저변환은 벡터를 바꾸는 것이 아니라,
같은 벡터를 다른 좌표계에서 표현하는 것이다.
4) 선형변환 관점에서 본 PCA
선형변환은 일반적으로 다음과 같이 정의된다.
여기서 행렬 는 공간을 늘리거나, 회전시키거나, 투영하는 역할을 한다.
PCA에서 사용하는 변환은 다음과 같다.
- : 원래 데이터
- : 선형변환 행렬
- : 새로운 좌표(PCA 좌표)
즉 PCA는 선형변환을 통해 데이터를 다른 좌표계로 재표현하는 과정이다.
5) 정사영(Orthogonal Projection)
PCA에서 가장 중요한 연산은 정사영(Projection)이다.
상위 개의 기저 벡터를 모아
라고 하면, 벡터 를 이 부분공간으로 정사영한 결과는
이다.
- : 저차원 좌표로 변환 (인코딩)
- : 원공간으로 복원 (디코딩)
이때 는 차원 부분공간으로의 직교정사영 행렬이다.
6) Reconstruction Error
상위 K개의 주성분을 모아
라고 하면,
1) 차원축소 (인코딩)
2) 복원 (디코딩)
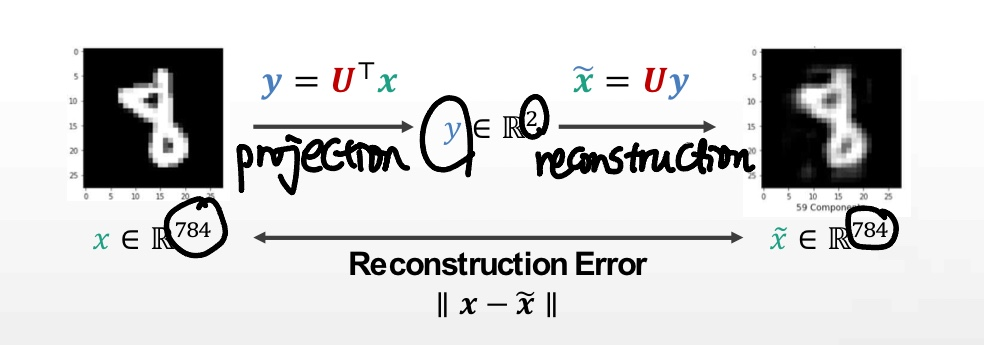
여기서 중요한 점은,
- 는 원래 와 완전히 같지 않다
- 일부 정보는 버려진다
이때의 차이를 reconstruction error라고 하며, 차원축소 시 이 reconstruction error를 최소화해야 한다.
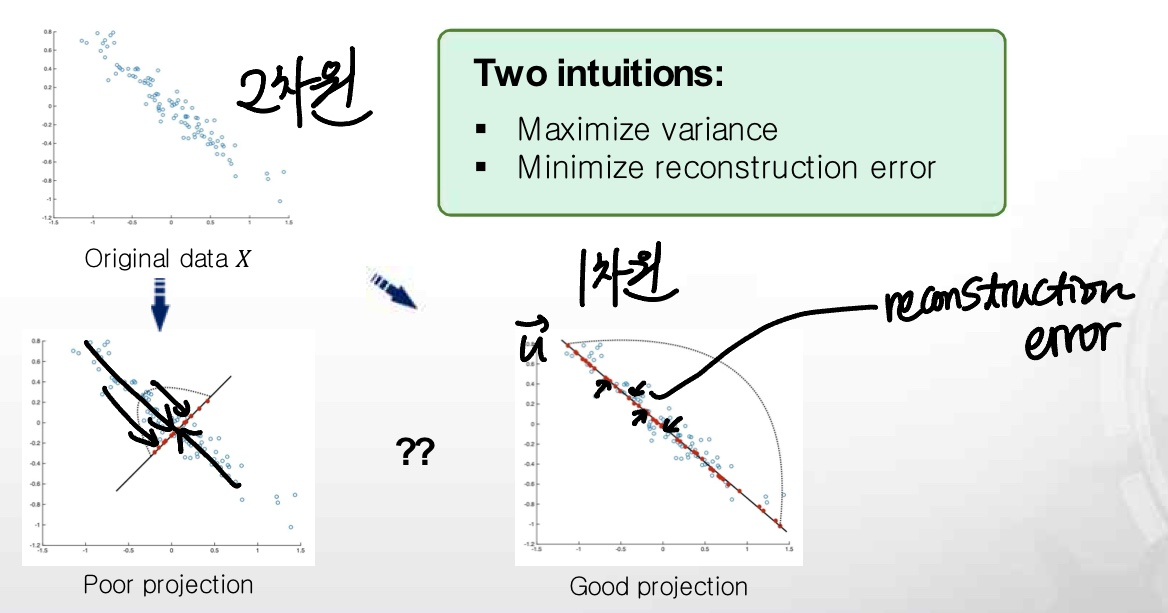
7) “좋은 정사영”이란 무엇인가?
여기서 핵심 질문이 나온다.
어떤 부분공간으로 정사영해야 reconstruction error가 가장 작아질까?
PCA의 대답은 아래와 같다.
Y(저차원의 데이터들)의 분산을 최대화하면 된다.
reconstruction error를 최소화하는 것은 Y의 분산을 최대화하는 것과 같기 때문이다.
그 이유를 알아보자.
PCA를 수행하기 전, 원래 고차원 데이터들의 평균을 원점으로 이동시키면, 아래와 같이 좌표상에 고차원의 원본 데이터와 원점, 그리고 주성분 u로 정사영한 저차원의 데이터가 있다고 생각할 수 있다.
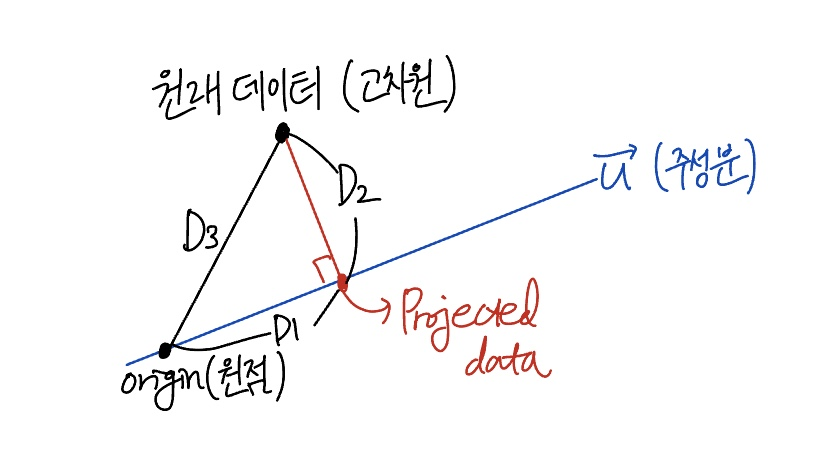
- (Variance of the data): 원점(평균)에서 원래 데이터 포인트까지의 거리이며, 이 값은 데이터가 고정되어 있으므로 변하지 않는 상수이다.
-> 원본 데이터들의 평균이 원점이므로, 원본 데이터와 원점 사이의 거리인 는 분산의 정의와 일치하게 된다. - (Variance of the embedding): 우리가 설정한 주성분 축 위로 데이터가 정사영된 거리이다.
- (Reconstruction Error): 원래 데이터에서 축까지의 수직 거리이며, 축으로 압축하면서 잃어버린 오차를 의미한다.
이때 피타고라스 정리에 의해 다음의 식이 성립한다.
는 상수이므로 reconstruction error()를 최소화하는 것은 Y의 분산()을 최대화하는 것과 같다.
따라서 PCA에서는
Y의 variance를 최대화하는 것과
reconstruction error를 최소화하는 것이 완전히 같은 문제가 된다.
8) 한 줄 요약
PCA는 데이터의 분산을 가장 잘 설명하는 기저로 정사영하여, 버려지는 정보(reconstruction error)를 최소화(=저차원 데이터의 분산을 최대화)하는 주성분 U를 찾는 차원축소 방법이다.
끝으로, 이번 내용을 정리하면서 선형대수학 강좌에서 배웠던 기저, 선형변환, 정사영 등의 개념이 차원 축소의 핵심 원리로 그대로 활용된다는 점이 매우 인상 깊었다.
선형대수학 강좌를 수강할 당시에는 각 개념이 다소 추상적으로 느껴졌고, 계산 위주로 학습했던 기억이 있는데 PCA를 통해 다시 바라보니 선형대수에서 배운 개념들은 단순한 수학적 도구가 아니라 데이터를 어떤 좌표계로 바라볼 것인가, 어떤 방향의 정보를 남기고 무엇을 버릴 것인가라는 질문에 대한 답이었다는 것을 알게 되었다.
이 경험을 통해 선형대수는 더 이상 독립된 이론 과목이 아니라,
머신러닝과 데이터 분석을 이해하기 위한 가장 기본적인 언어라는 생각이 들었다.
