이번 포스트에서는 선형회귀와 로지스틱 회귀에 대해 알아보려 한다.
지도학습 중 분류와 회귀에 해당하는 내용을 먼저 리마인드하자면,
- 분류: 입력 데이터를 보고 어떤 범주에 속하는지 맞히는 것
- 회귀: 입력 데이터를 보고 연속적인 수치 값을 예측하는 것
이다.
선형 회귀 (Linear Regression)
1. 정의
선형 회귀는 독립 변수 X를 사용해 종속 변수 y(연속값)를 예측하는 회귀 알고리즘이다.
독립 변수와 종속 변수 사이의 관계를 직선(선형 함수) 으로 가정한다.
출력: 실수 전체 범위( −∞ ~ ∞)
예측 대상: 연속값
수식:
y = w x + b
(다변수의 경우: y = wᵀx + b)
- w: 기울기(각 변수의 영향력)
- b: 절편
- ŷ: 예측값
즉,
x가 변할 때 y가 어떻게 변하는지를 하나의 직선으로 가장 잘 설명하는 것이 목표다.
2. 단순 선형 회귀 vs 다중 선형 회귀
-
단순 선형 회귀 (Simple Linear Regression)
독립 변수 1개
예: MinTemp → MaxTemp -
다중 선형 회귀 (Multiple Linear Regression)
독립 변수 여러 개
예: 기온, 습도, 풍속 → 전력 사용량
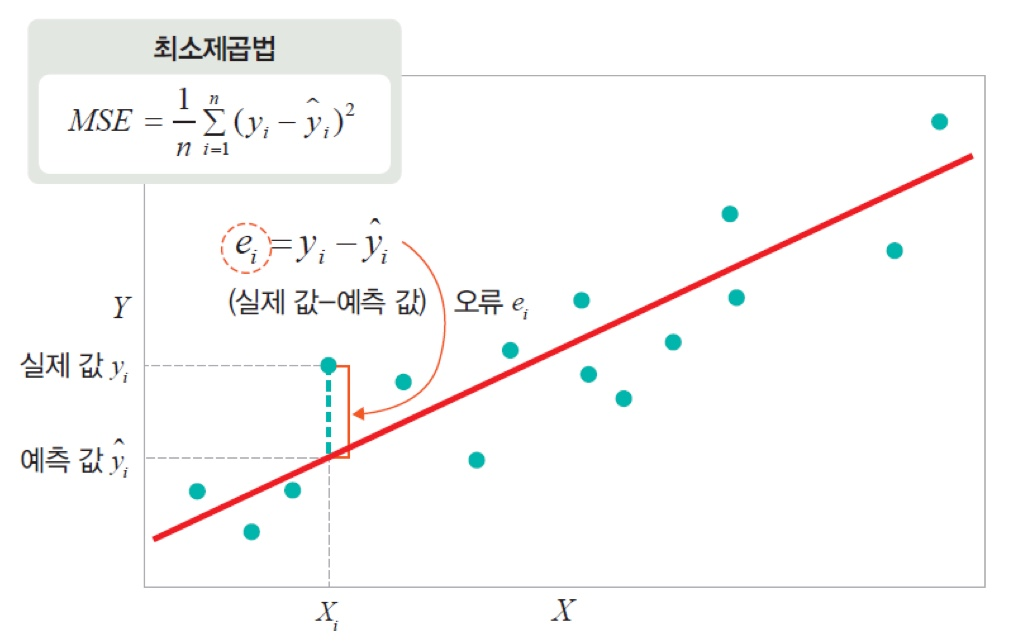
3. 선형 회귀의 손실 함수: 평균제곱오차(MSE)
선형 회귀는 예측값과 실제값의 차이를 최소화한다.
이를 수치화한 것이 평균제곱오차(MSE) 이다.
MSE = (1/n) Σ (yᵢ − ŷᵢ)²
의미:
- 예측이 실제값에서 평균적으로 얼마나 벗어나는지
- 값이 작을수록 좋은 모델
제곱을 사용하는 이유:
1. 오차의 부호 제거 (+/− 상쇄 방지)
2. 큰 오차에 더 큰 패널티
3. 미분 가능 → 학습(최적화)에 유리
4. 경사하강법(Gradient Descent)
4-1. 경사하강법이란?
경사하강법은 손실 함수(MSE)가 최소가 되도록 가중치 w, b를 반복적으로 업데이트하는 최적화 알고리즘이다.
4-2. 왜 경사하강법이 필요한가?
선형 회귀의 목표는 아주 명확하다.
예측값과 실제값의 차이가 가장 작아지도록
가중치(θ)를 찾는 것
선형 회귀 모델은 다음과 같이 표현된다.
ŷ = θ₀ + θ₁x₁ + θ₂x₂ + … + θₙxₙ
(벡터 형태: ŷ = θᵀx)
그렇다면 “가장 잘 맞는다”는 것을 어떻게 수치로 표현할까?
-> Cost function(손실 함수) 가 필요하다.
4-3. Cost Function: MSE / SSE
선형 회귀에서 가장 대표적인 cost function은 다음 두 가지다.
- SSE (Sum of Squared Error)
- MSE (Mean Squared Error)
수식으로 쓰면:
의미:
- 현재 가중치 θ를 사용했을 때
- 예측이 전체적으로 얼마나 틀렸는지를 나타내는 함수
-> 학습이란, 이 cost function 값을 최소로 만드는 θ를 찾는 과정이다.
4-4. 경사하강법의 핵심 아이디어 (직관)
Cost function을 3차원으로 그려보면,
θ 공간 위에 그릇 모양(convex) 곡면이 만들어진다.
- 현재 θ는 그릇 어딘가에 있음
- 가장 낮은 지점이 cost 최소값
- 기울기(gradient)는 가장 가파르게 증가하는 방향
따라서 우리는 기울기 방향이 아닌 기울기의 반대 방향으로 이동
이 아이디어가 바로 경사하강법이다.
4-5. 경사하강법의 수식적 형태
경사하강법의 기본 업데이트 식은 다음과 같다.
- J(θ): cost function (MSE or SSE)
- ∇J(θ): cost function의 gradient
- η (learning rate): 한 번에 이동하는 크기
의미를 풀면:
“현재 위치에서 cost를 가장 빠르게 줄이는 방향으로
learning rate만큼 가중치를 업데이트한다”
4-6. Batch Gradient Descent (배치 경사하강법)
정의
- 전체 학습 데이터(all samples) 를 사용해
- 한 번의 gradient를 계산하고
- 한 번 가중치를 업데이트
수식 예시 (SSE 기준):
특징
- 장점
- gradient가 정확함
- 안정적인 수렴
- 단점
- 데이터가 많으면 계산 비용 큼
- 한 번 업데이트에 시간이 오래 걸림
-> Batch learning에 해당
4-7. Stochastic Gradient Descent (SGD)
정의
- 샘플 1개를 뽑아서
- 즉시 gradient 계산
- 즉시 가중치 업데이트
수식 개념:
특징
- 장점
- 매우 빠른 업데이트
- 메모리 사용 적음
- local minima에 빠질 확률 감소
- 단점
- 경로가 불안정
- cost가 진동하면서 감소
-> Online learning에 해당
4-8. Mini-batch Gradient Descent (미니배치)
정의
- 전체 데이터를 작은 batch로 나눔
- batch 단위로 gradient 계산
- 가중치 업데이트
특징
- Batch GD와 SGD의 절충안
- 실제 딥러닝에서 가장 많이 사용
- GPU 병렬 처리에 유리
-> “gradient descent”라고 하면 대부분 mini-batch gradient descent를 의미
4-9. Batch / Mini-batch / Stochastic 비교 정리
| 방식 | 사용 데이터 | 안정성 | 속도 |
|---|---|---|---|
| Batch GD | 전체 데이터 | 매우 안정적 | 느림 |
| SGD | 1개 샘플 | 불안정 | 매우 빠름 |
| Mini-batch GD | 일부 샘플 | 균형 | 빠름 |
4-10. Learning Rate (η): 가장 중요한 하이퍼파라미터
Learning rate는
“한 번에 얼마나 크게 이동할지” 를 결정한다.
너무 작은 경우
- 수렴은 하지만 매우 느림
- 학습 시간 증가
너무 큰 경우
- 최소값을 지나쳐서 발산
- 학습 실패 가능
4-11. Learning Rate 조절 방식
(1) Constant learning rate
η = 0.1, 0.01, 0.001 …
- 가장 단순
- 직접 튜닝 필요
(2) Step decay
- 일정 epoch마다 learning rate 감소
- 예: 20 epoch마다 η / 10
(3) Time-based decay
ηₜ = η₀ / (1 + k·t)
- 시간이 지날수록 점점 감소
(4) Exponential decay
ηₜ = η₀ · e^(−k·t)
- 초반에는 빠르게
- 후반에는 안정적으로 수렴
4-12. Epoch의 의미
- Epoch = 학습 데이터 전체를 한 번 사용한 횟수
- Batch GD: 1 epoch = 1 update
- SGD: 1 epoch = N번 update
- Mini-batch: 1 epoch = (N / batch size)번 update
4-13. 핵심 요약
- Cost function(MSE/SSE)
→ “얼마나 틀렸는가”를 수치화 - Gradient descent
→ cost를 줄이기 위한 최적화 방법 - Batch / SGD / Mini-batch
→ gradient 계산에 사용하는 데이터 범위 차이 - Learning rate
→ 학습의 성패를 좌우하는 핵심 하이퍼파라미터
결론적으로,
선형 회귀의 학습이란 MSE로 오차를 정의하고,
경사하강법으로 그 오차를 줄여가는 과정이다.
5. 선형 회귀 실습 예제 (날씨 데이터)
라이브러리 호출
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics 데이터 불러오기
dataset = pd.read_csv('../chap3/data/weather.csv')데이터 분포 시각화
dataset.plot(x='MinTemp', y='MaxTemp', style='o')
plt.title('MinTemp vs MaxTemp')
plt.xlabel('MinTemp')
plt.ylabel('MaxTemp')
plt.show()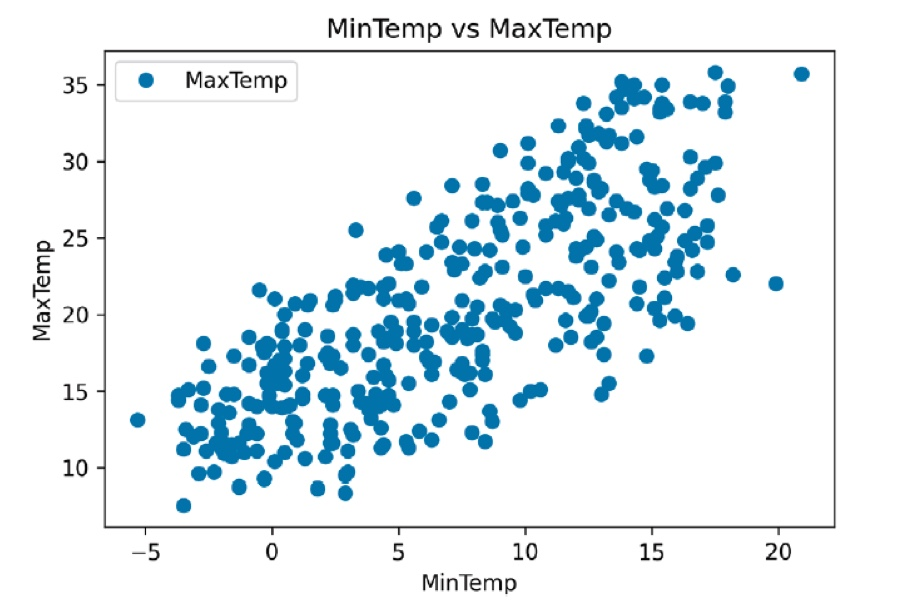
→ MinTemp와 MaxTemp 사이에 대략적인 선형 관계 확인
# 독립변수/ 종속변수 설정
X = dataset['MinTemp'].values.reshape(-1, 1)
y = dataset['MaxTemp'].values.reshape(-1, 1)
# 학습 / 검증 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2
)
# 모델 생성 및 학습
regressor = LinearRegression()
regressor.fit(X_train, y_train)
# 예측 수행
y_pred = regressor.predict(X_test)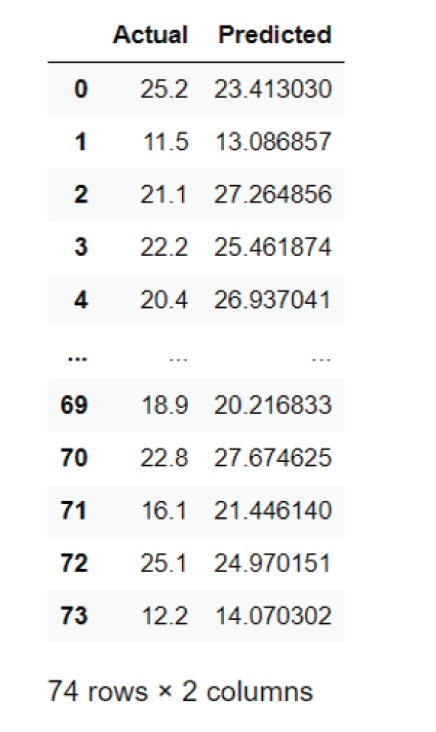
# 결과 비교
# Actual 값과 Predicted 값을 나란히 비교하여 예측 성능을 확인한다.
# 회귀선 시각화
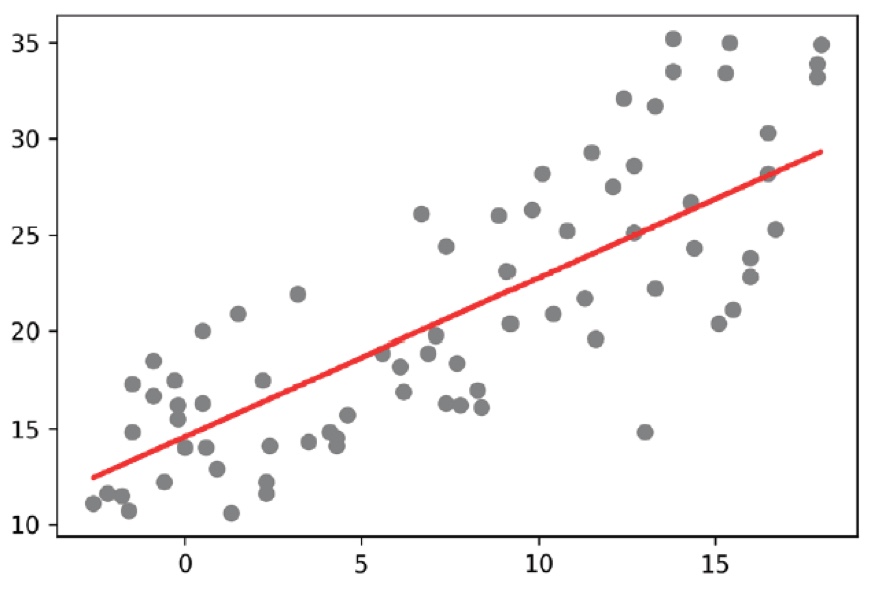
plt.scatter(X_test, y_test, color='gray')
plt.plot(X_test, y_pred, color='red', linewidth=2)
plt.show()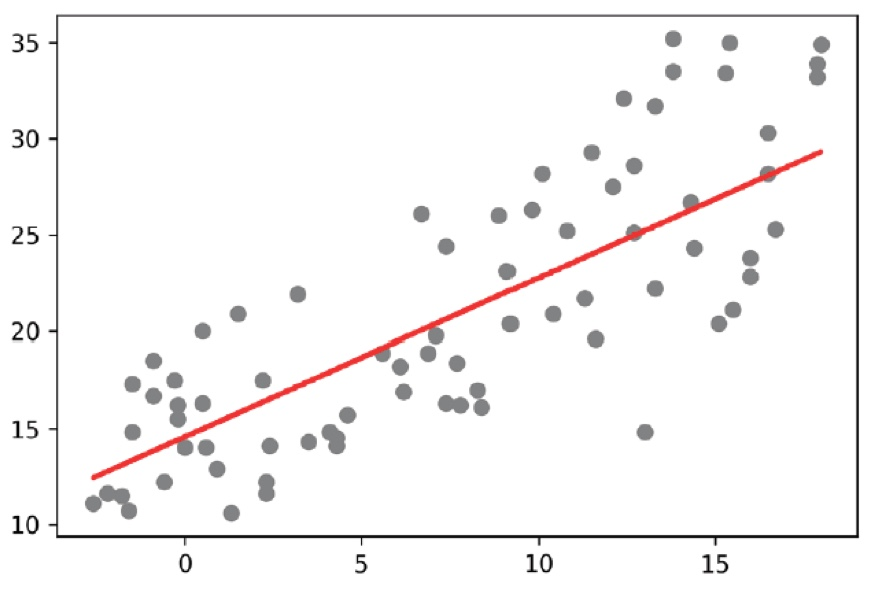
6. 모델 평가: MSE와 RMSE
평균제곱오차(MSE)와 루트 평균제곱오차(RMSE)를 사용해 모델을 평가한다.
print('평균제곱법(MSE):', metrics.mean_squared_error(y_test, y_pred))
print('루트 평균제곱법(RMSE):',
np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
RMSE는 원래 y와 같은 단위를 가지므로 해석이 직관적이다.
예를 들어 RMSE ≈ 4.12라면, 평균적으로 약 4도 정도의 오차로 예측하고 있다는 의미다.
로지스틱 회귀(Logistic Regression)
1. 정의
선형 회귀의 한계:
- 출력값이 −∞ ~ ∞ 범위
- 분류 문제에 직접 적용하기 부적합
로지스틱 회귀(Logistic Regression)는 분석 대상이 두 집단(또는 그 이상)의 범주로 나뉘는 경우, 각 관측치가 어느 집단에 속할 확률을 추정하고 이를 바탕으로 분류를 수행하기 위해 사용되는 통계적 기법이다.
즉,
- 출력값은 연속적인 수치가 아니라
- 특정 클래스에 속할 확률이며
- 이를 기준으로 최종 클래스를 결정한다.
이 점에서 로지스틱 회귀는 이름과 달리 분류(Classification) 문제를 다룬다.
2. 일반적인 회귀 분석과 로지스틱 회귀의 차이
| 구분 | 일반적인 회귀 분석 | 로지스틱 회귀 분석 |
|---|---|---|
| 종속 변수 | 연속형 변수 | 이산형 변수 (0/1) |
| 목적 | 값 예측 | 범주 분류 |
| 모형 추정 | 최소제곱법 | 최대우도법 |
| 모형 검정 | t-test, F-test | χ²-test |
핵심 차이는 종속 변수의 형태와 모형을 학습하는 기준(손실 함수) 에 있다.
3. 우도(Likelihood)와 최대우도법(MLE)
3-1. 우도(Likelihood)란?
우도(likelihood)는 주어진 결과(Y)가 나타났을 때, 그 결과를 가장 잘 설명하는 가설(모델 파라미터)이 얼마나 그럴듯한지를 나타내는 척도이다.
중요한 관점 전환:
- 확률: θ가 주어졌을 때 Y가 나올 확률
- 우도: Y가 주어졌을 때 θ가 얼마나 그럴듯한가
3-2. 최대우도법의 개념
최대우도법은 다음과 같이 정의된다.
즉,
입력 X와 결과 Y가 주어졌을 때
Y가 실제로 관측될 확률을 최대화하는 θ를 찾는 것
관측치들이 서로 독립이라고 가정하면,
전체 우도는 각 샘플 우도의 곱으로 표현된다.
곱셈은 계산이 불안정하므로 로그를 취한다.
-> 이 식이 로지스틱 회귀의 학습 목표이다.
4. 로지스틱 회귀의 확률 모델
로지스틱 회귀는 선형 결합을 그대로 사용하되,
출력을 시그모이드 함수(sigmoid) 로 변환한다.
시그모이드 함수:
확률 모델:
- 출력은 0~1 사이
- 이를 기준으로 클래스를 분류
- 문제 유형은 분류지만,
내부 구조가 회귀식이므로 이름에 “회귀”가 붙는다
5. 로지스틱 회귀의 학습 절차
로지스틱 회귀 분석은 다음 두 단계로 진행된다.
1단계: 확률 추정
- 각 관측치에 대해
- 집단 1에 속할 확률 P(Y=1 | X)을 계산
2단계: 분류 기준(cut-off) 설정
- 일반적으로 기준값은 0.5
예시:
- P(Y=1) ≥ 0.5 → 집단 1
- P(Y=1) < 0.5 → 집단 0
이 기준은 문제에 따라 조정 가능하다.
6. 로지스틱 회귀 실습 예제: Digits 데이터셋 분류
이번 예제에서는 사이킷런(sklearn)에서 제공하는 digits 숫자 데이터셋을 사용하여
로지스틱 회귀 모델을 학습하고, 예측 및 성능 평가까지 진행한다.
라이브러리 호출 및 데이터 준비
digits 데이터셋은 0~9까지의 숫자를 손글씨 이미지로 표현한 데이터셋이다.
각 이미지는 8×8 크기의 흑백 이미지이며, 이를 펼쳐서 64차원 벡터로 저장한다.
%matplotlib inline
from sklearn.datasets import load_digits
digits = load_digits() # 사이킷런에서 제공하는 숫자 데이터셋 로드
print("Image Data Shape:", digits.data.shape)
print("Label Data Shape:", digits.target.shape)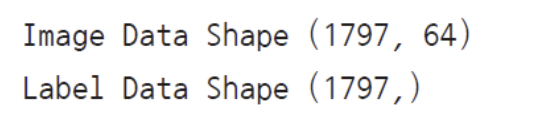
digits 데이터셋 시각화
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 4))
for index, (image, label) in enumerate(zip(digits.data[:5], digits.target[:5])):
plt.subplot(1, 5, index + 1)
plt.imshow(np.reshape(image, (8, 8)), cmap=plt.cm.gray)
plt.title('Training: %i\n' % label, fontsize=20)
plt.show()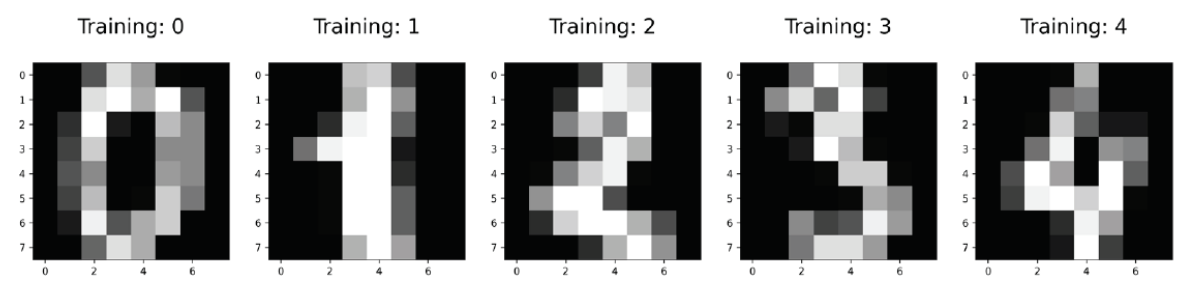
학습/검증 데이터셋 분리 후 훈련
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
digits.data,
digits.target,
test_size=0.25,
random_state=0
)
from sklearn.linear_model import LogisticRegression
logisticRegr = LogisticRegression()
logisticRegr.fit(X_train, y_train)모델 예측
logisticRegr.predict(X_test[0].reshape(1, -1))
logisticRegr.predict(X_test[0:10])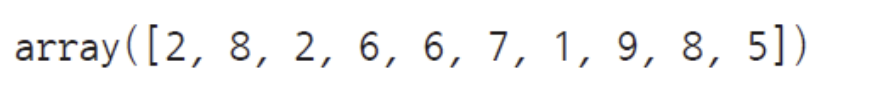
-> 10개의 이미지 데이터를 사용한 로지스틱회귀 모델에 대한 예측결과 출력
predictions = logisticRegr.predict(X_test)
score = logisticRegr.score(X_test, y_test)
print(score)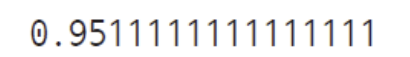
-> 전체 데이터를 사용한 로지스틱회귀 모델에 대한 예측결과 출력 (성능 95%)
선형회귀 vs 로지스틱회귀 핵심 요약
선형 회귀 (Linear Regression)
- 문제 유형: 회귀 (Regression)
- 예측 대상: 연속적인 값
- 출력 범위: −∞ ~ ∞
- 모델 형태: y = θᵀx
- 손실 함수: MSE (평균제곱오차)
- 학습 방식: 최소제곱법(MSE)
- 특징: 값 자체를 예측, 해석이 직관적
로지스틱 회귀 (Logistic Regression)
- 문제 유형: 분류 (Classification)
- 예측 대상: 클래스에 속할 확률
- 출력 범위: 0 ~ 1
- 모델 형태: P(y=1|x) = σ(θᵀx)
- 손실 함수: Cross Entropy (Log Loss)
- 학습 방식: 최대우도법(MLE)
- 특징: 확률 기반 분류, 시그모이드 함수 사용
즉
선형 회귀는 값을 예측
로지스틱 회귀는 확률을 예측해 분류
