웹 기반 기술 이해
프로토콜(네트워크 통신 규약)
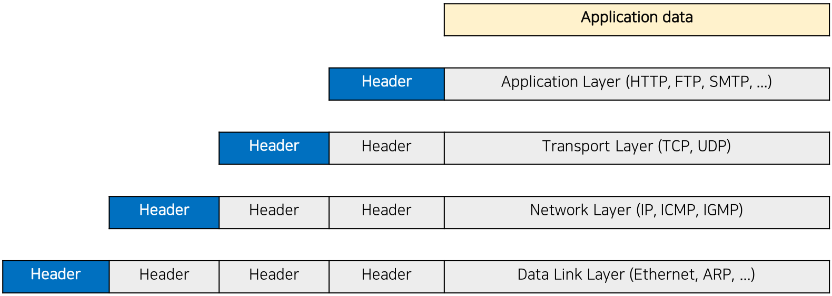
- 인터넷 프로토콜: TCP 및 IP 프로토콜이 핵심(TCP/IP 프로토콜)
- 이더넷: 네트워크 모듈
- IP 프로토콜: 컴퓨터 주소를 찾는 프로토콜
- TCP 프로토콜: 컴퓨터간 신뢰성 있는 데이터 전송을 지원하는 프로토콜
웹 전체 시나리오
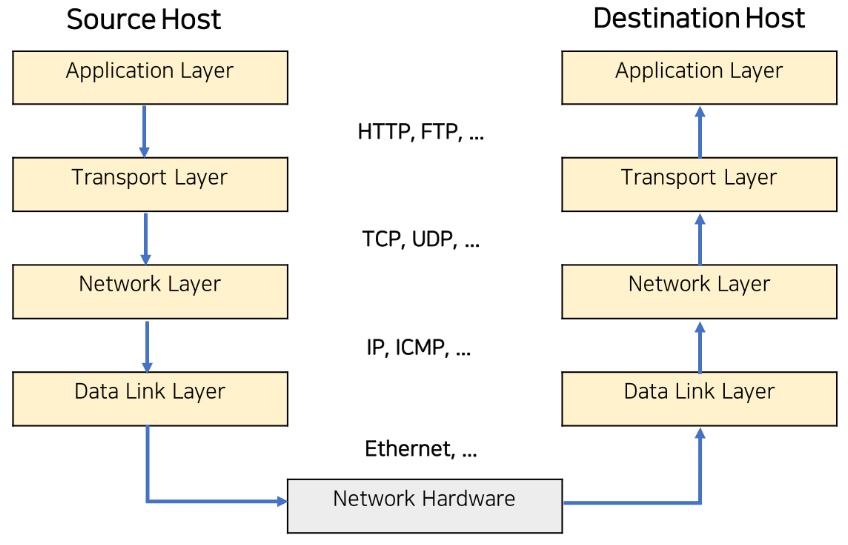
1. 사용자는 브라우저를 사용하여 www.velog.io 같은 url 입력을 통해 웹페이지 요청
2. 사용자의 요청 -> TCP 패킷으로 만들어짐
3. TCP패킷 -> IP 패킷으로 만들어짐 / IP패킷에는 자신의 IP주소와 도착해야될 상대방의 IP주소 정보가 포함 됨
4. IP패킷 -> 이더넷 카드로 보내져서 인터넷으로 전송 됨
5. 이더넷 패킷 -> 도착지의 컴퓨터 이더넷 카드로 전달 됨
6. 도착지의 이더넷 카드 -> IP프로토콜 계층에 해당 데이터 보냄
7. IP프로토콜 계층 -> TCP프로토콜 계층으로 데이터 보냄
8. TCP프로토콜 계층은 누락된 데이터가 없는지 확인하고, 데이터를 재조합한 후 -> Application Layer로 보냄
9. Application Layer에서 해당 데이터가 HTTP프로토콜로 작성돼 있으면 HTTP프로토콜 규칙에 준하여 사용자가 요청한 웹페이지를 웹서버가 제공
10. 웹서버가 제공한 웹페이지는 다시 TCP프로토콜 계층으로 전송되어 TCP패킷 -> IP패킷 -> 이더넷 카드 -> 요청된 컴퓨터 이더넷 카드 -> IP패킷 -> TCP패킷 -> HTTP 패킷의 과정을 거쳐 웹브라우저에 웹페이지가 전달 됨
11. 웹브라우저는 웹페이지 파일에 있는 HTML, CSS, javascript 등을 파싱하여 렌더링 작업을 거쳐 화면에 뿌려줌
HTTP프로토콜(웹상에서 문서 전송을 위한 프로토콜)
- request(요청) / response(응답)으로 구성
- 웹 브라우저(클라이언트)가 요청하면 웹 서버가 HTML파일이나 다른 자원(이미지, 텍스트, 동영상 등)을 응답으로 전송
- request의 형태에는 대표적으로 GET / POST가 존재
- GET: 데이터 전달을 URL내에서 함
ex) 네이버 검색, 구글 검색 등 - POST: 데이터 전송을 태그를 통해서 함(사용자에게 직접적으로 노출x)
ex) ID, 비밀번호 전달의 경우
- GET: 데이터 전달을 URL내에서 함
- 브라우저는 응답을 렌더링하여 인간이 보기 쉬운 형태로 출력
크롤링(crawling)이해
크롤링(crawling)이란?
- 웹상에 존재하는 내용(정보)를 수집하는 작업
- 프로그래밍으로 자동화 가능
- 크게 세가지 기법 존재
- HTML페이지를 가져와서, HTML/CSS등을 파싱하고 필요한 데이터만 추출하는 기법
- Open API (REST API)를 제공하는 서비스에 Open API를 호출해서 받은 데이터 중 필요한 데이터만 추출하는 기법
- Selenium 등 브라우저를 프로그래밍으로 조작해서 필요한 데이터만 추출하는 기법
BeautifulSoup 라이브러리를 활용한 초간단 예제
- BeautifulSoup은 HTML의 태그를 파싱해서 필요한 데이터만 추출하는 함수를 제공하는 라이브러리
Example1 (제목 추출)
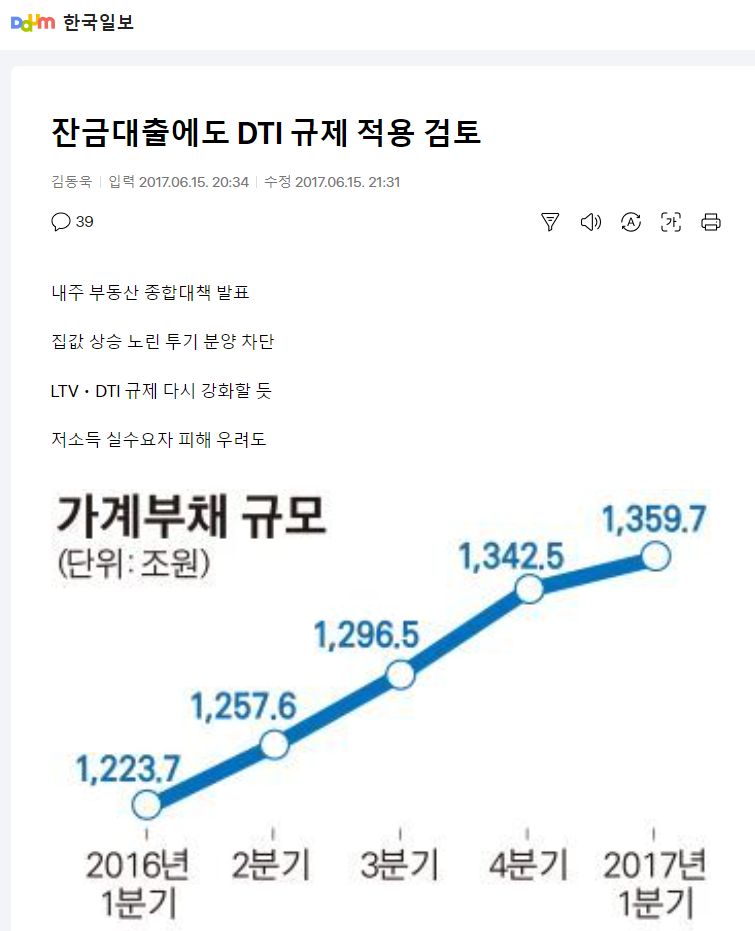
- 다음 뉴스에서 뉴스 제목 추출
import requests
from bs4 import BeautifulSoup
# 1.requests 라이브러리를 활용하여 HTML 페이지 요청
## res 객체에 HTML 데이터 저장
res = requests.get('https://v.daum.net/v/20170615203441266')
## res.content로 데이터 추출 가능
print(res.content)
# 2.BeautifulSoup 활용하여 HTML 페이지 파싱
soup = BeautifulSoup(res.content, 'html.parser')
# 3.필요한 데이터 검색
title = soup.find('title')
# 4.필요한 데이터 추출
print(title.get_text())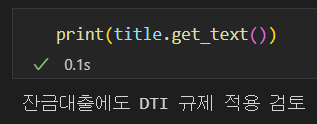
Example2(find, find_all)
- find()와 find_all() 메서드 사용법 이해하기
- find(): 가장 먼저 검색되는 태그 반환
- find_all(): 전체 태그 반환
from bs4 import BeautifulSoup
html = """
<html>
<body>
<h1 id='title'>[1]크롤링이란?</h1>;
<p class='cssstyle'>웹페이지에서 필요한 데이터를 추출하는 것</p>
<p id='body' align='center'>파이썬을 중심으로 다양한 웹크롤링 기술 발달</p>
</body>
</html>
"""
soup = BeautifulSoup(html, "html.parser")
# 태그로 검색 방법
title_data = soup.find('h1')
print(title_data)
print(title_data.string)
print(title_data.get_text())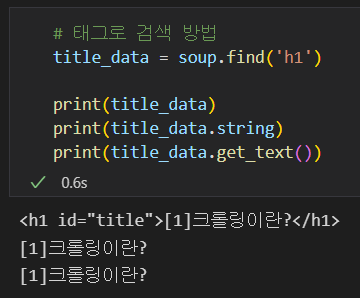
# 가장 먼저 검색되는 태그를 반환
p_data = soup.find('p')
print(p_data)
print(p_data.string)
print(p_data.get_text())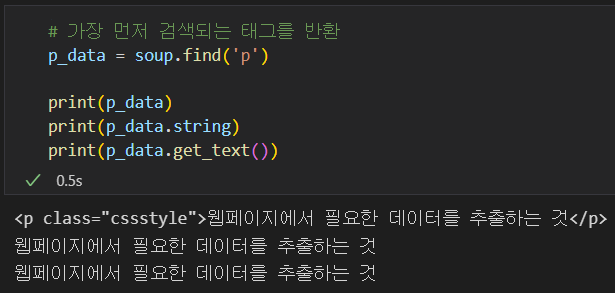
# 태그에 있는 id로 검색
title_data = soup.find(id='title')
print(title_data)
print(title_data.string)
print(title_data.get_text())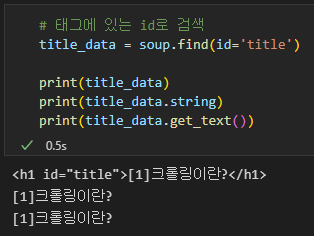
# HTML 태그와 CSS class를 활용해 필요한 데이터 추출 방법
p_data = soup.find('p', class_='cssstyle') # 'class_='은 생략 가능
print(p_data)
print(p_data.string)
print(p_data.get_text())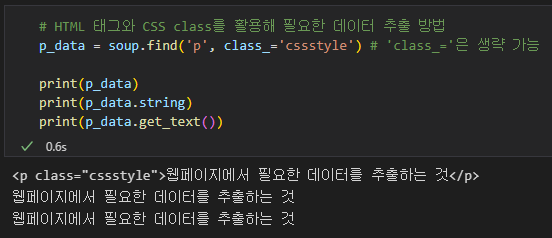
# HTML 태그와 태그에 있는 속성:속성값을 활용해 필요한 데이터 추출 방법
p_data = soup.find('p', attrs={'align':'center'})
print(p_data)
print(p_data.string)
print(p_data.get_text())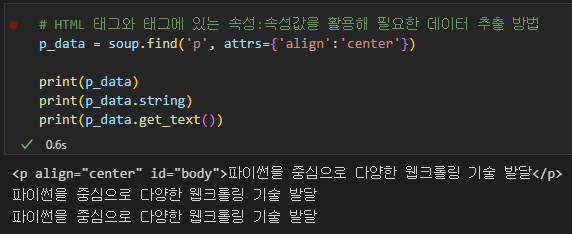
# find_all() 관련된 모든 데이터를 리스트 형태로 추출하는 함수
p_data = soup.find_all('p')
print(p_data)
print(p_data[0].get_text())
print(p_data[1].get_text())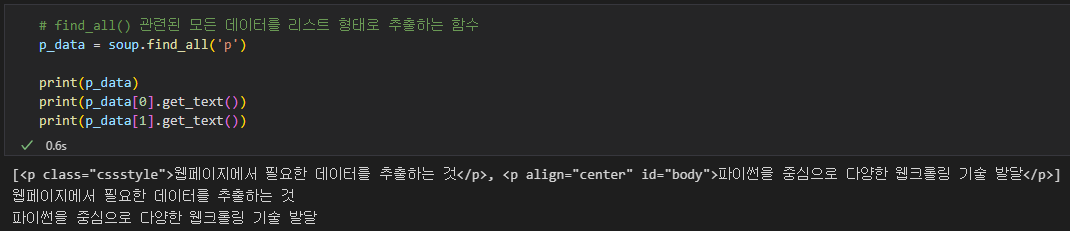
Example3(String)
- string 검색 예제
- 태그가 아닌 문자열 자체로 검색
- 문자열, 정규표현식 등등으로 검색 가능
- 문자열 검색의 경우 한 태그내의 문자열과 exact matching인 것만 추출
- 이것이 의도한 경우가 아니라면 정규표현식 사용
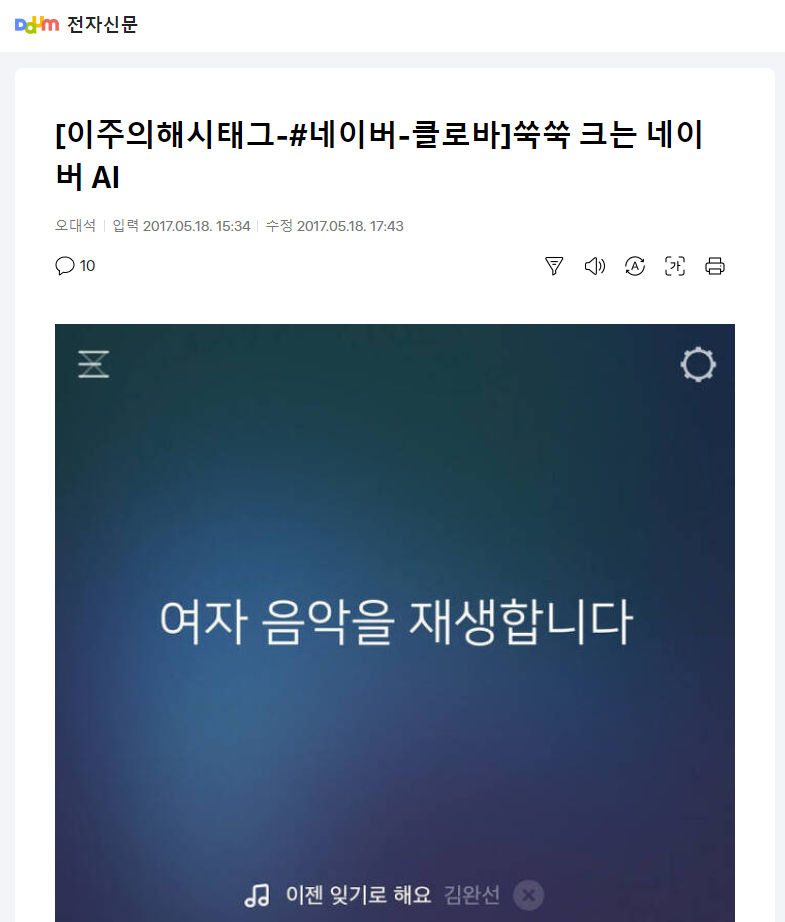
import re
res = requests.get('https://v.daum.net/v/20170518153405933')
soup = BeautifulSoup(res.content, 'html.parser')
print(soup.find_all(string='오대석'))
print(soup.find_all(string=['[이주의해시태그-#네이버-클로바]쑥쑥 크는 네이버 AI', '오대석']))
print(soup.find_all(string='AI'))
print(soup.find_all(string=re.compile('AI'))[0])
#print(soup.find_all(string=re.compile('AI')))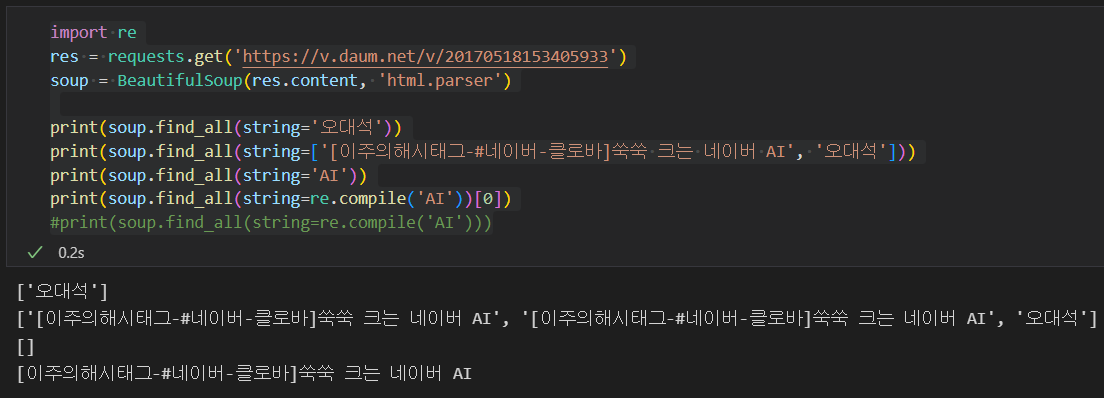
Open API(Rest API)를 활용한 크롤링
Open API(Rest API)란?
- API: Application Programming Interface의 약자로 특정 프로그램을 만들기 위해 제공되는 모듈(함수 등)을 의미
- Open API: 누구나 사용할 수 있도록 공개된 API(주로 Rest API 기술 많이 사용)
- Rest API: Representational State Transfer API의 약자로 HTTP프로토콜을 통해 서버 제공 기능을 사용할 수 있는 함수를 의미
- 일반적으로 XML, JSON의 형태로 응답을 전달
JSON이란?
- JavaScript Object Notation의 약자로 서버와 클라이언트 또는 컴퓨터와 프로그램 사이에 데이터를 주고 받을 때 사용하는 데이터 포멧
- 키와 값을 괄호와 세미콜론과 같이 간단한 기호로 구성하여 표현할 수 있으며 언어나 운영체제에 구애받지 않아 많이 사용 됨
- 특히 웹/앱 환경에서 Rest API를 사용하여 서버와 클라이언트 간에 데이터를 주고 받을 때 많이 사용
- JSON 포멧 예시:
{"id":"01", "Language":"Java", "Edition":"Third", "Author":"Herbert Schildt"}
네이버 검색 Open API를 이용한 크롤링 예시
- 네이버와 같은 주요 포털 사이트에서도 Open API를 제공
(네이버 Developers - https://developers.naver.com/main/) - 네이버 Developers 사이트 가입
- Application -> 애플리케이션 등록(API 이용신청)에서 검색 API 사용 신청
- Application -> 내 애플리케이션에서 Client ID와 Client Secret 확인
requests 라이브러리 활용
- requests 라이브러리를 사용해서 Open API(Rest API)를 통해 데이터를 바로 가져올 수 있음
import requests
client_key = '클라이언트 키'
client_secret = '클라이언트 비밀번호'
naver_url = 'https://openapi.naver.com/v1/search/news.json?query=스마트폰'
header_params = {"X-Naver-Client-Id":client_key, "X-Naver-Client-Secret":client_secret}
response = requests.get(naver_url, headers=header_params)
#print(response.json())
#print(response.text)
if(response.status_code == 200):
data = response.json()
print(data['items'][0]['title'])
print(data['items'][0]['description'])
else:
print("Error Code:"+response.status_code)
Exercise
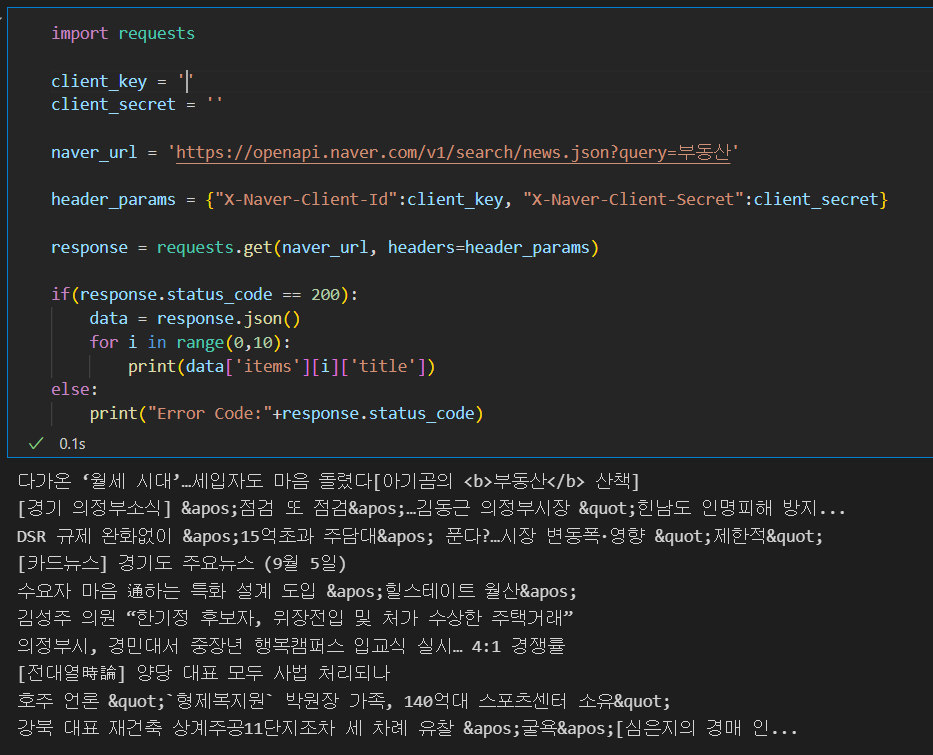
- 네이버 검색 Open API를 사용해서 부동산 키워드로 검색 결과 중 상위 10개의 타이틀 출력
Reference

graph data scientist