개요와 데이터셋
금융 관련 데이터를 이용해 데이터 분석을 연습해보고 싶어서 데이터를 찾아보던 중,
한국신용정보원에서 제공하는 CreDB 개인신용 교육용DB를 발견했다. (링크)
CreDB는 신용정보원에 저장된 신용정보를 표본추출한 뒤,
이를 비식별 조치하여 교육 목적으로 이용자에게 제공하는 서비스이다.
내가 받은 데이터는 light 버전으로, 2000명의 대출,연체,카드개설정보가 담겨 있다.
연령별 대출액의 대표값
먼저 이 데이터로 연령별 대출액의 대표값을 구하겠다.
library(ggplot2)
library(gmodels)
df_id <- read.csv("./data/ID.csv")
df_loan <- read.csv("./data/LN.csv")
df_delay <- read.csv("./data/DLQ.csv")
df_cdopn <- read.csv("./data/CDOPN.csv")먼저 라이브러리와 개인신용 데이터를 import한다.
df_id$age <- as.integer((2018 - df_id$BTH_YR) / 10)
df_loan_new <- df_loan %>% group_by(JOIN_KEY, COM_KEY, SCTR_CD, LN_CD_1, LN_CD_2, LN_YM, LN_AMT) %>%
summarise(YM = max(YM))
df_loan_sum <- df_loan_new %>% group_by(JOIN_KEY) %>% summarise(SUM_AMT = sum(LN_AMT))
df_id_loan_sum <- merge(df_id, df_loan_sum, by="JOIN_KEY", all.y = TRUE)순서대로 설명하자면 다음과 같다.
1. 기준 년도(2018)와 생년 정보의 차이를 통해 나이를 구한 뒤, 이를 10으로 나누어 연령대를 구한다.
- 월마다 대출 정보가 중복되기 때문에, dplyr 라이브러리의 group_by 함수에 YM을 제외한 컬럼을 넣어주고,
summarise 함수로 YM의 최대값으로 함축시켜준다. 그렇게 하면 기존에 58922개였던 데이터가 5382개로 줄어들 것이다.
- 중복이 제거된 데이터를 다시 group_by를 통해 JOIN_KEY(회원코드)로 묶어준다. 또한 summarise 함수를 통해,
SUM_AMT라는 컬럼을 추가해주고, 회원별로 LN_AMT(대출액)의 합이 되는 값을 넣어준다.
- 연령대 데이터가 들어있는 df_id와 회원별 대출액의 합이 들어있는 df_loan_sum을 JOIN_KEY를 매개로 merge시킨다.
이때, 대출을 하지 않은 사람이 존재할 수도 있으므로, all.y=TRUE를 주어 RIGHT JOIN을 시킨다.
df_mean_result <- df_id_loan_sum %>% group_by(age) %>%
summarise(AMT = round(mean(SUM_AMT)), TYPE = "mean")
df_median_result <- df_id_loan_sum %>% group_by(age) %>%
summarise(AMT = round(median(SUM_AMT)), TYPE = "median")
df_result <- rbind(df_mean_result, df_median_result)age(연령대)로 그룹화하여, AMT와 TYPE 컬럼을 생성시킨다.
여기서 두 개의 데이터프레임을 생성하는 이유는, 시각화할 때 각 대표값의 차이를 명확히 보이게 하기 위함이다.
처음에 한 개의 데이터프레임에 모두 넣어서 시각화를 시도해봤으나, 잘 되지 않았다.
따라서, 두 개의 데이터프레임에 평균값과 중위값을 각각 넣은 다음, TYPE 컬럼에 평균값이면 mean, 중위값이면 median을 넣어주었다.
마지막으로 rbind 함수로 이 두 데이터프레임을 병합시켰다.
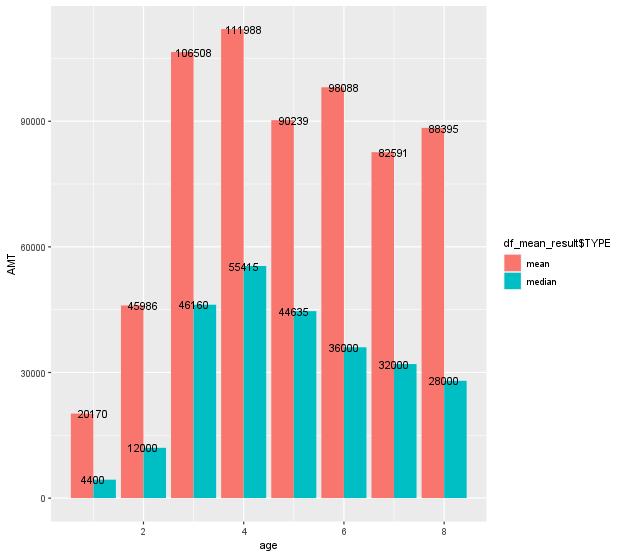
ggplot(df_result, aes(age, AMT, fill=df_result$TYPE)) + geom_bar(stat='identity', position = 'dodge') +
geom_text(aes(y=AMT,label=AMT))마지막으로 ggplot을 통해 막대그래프로 시각화시킨 결과, 다음과 같은 그래프가 나왔다.
평균값과 중위값의 차이가 꽤나 크다는 점을 볼 수 있다.
연체액과 연체 기간 상관분석
rm("df_id_loan_sum", "df_loan_new", "df_loan_sum", "df_mean_result", "df_median_result", "df_result")먼저 위 대표값들을 구하는 과정에서 만든 데이터프레임들을 제거한다.
df_delay_new <- df_delay %>% group_by(JOIN_KEY, COM_KEY, SCTR_CD,DLQ_TYPE, DLQ_CD_1, DLQ_CD_2, DLQ_YM,DLQ_AMT) %>%
summarise(DLQ_COUNT = n())
df_delay_new$DLQ_AMT <- ifelse(df_delay_new$DLQ_AMT < 500000, df_delay_new$DLQ_AMT, NA)
ggplot(df_delay_new, aes(x=DLQ_COUNT, y=DLQ_AMT)) + geom_point()
cor.test(df_delay_new$DLQ_COUNT, df_delay_new$DLQ_AMT)group_by와 summarise 함수를 통해 DLQ_COUNT 컬럼(개별 연체 기간)을 포함한 데이터프레임을 생성한다.
그 다음, DLQ_AMT(개별 연체액)과 DLQ_COUNT 컬럼을 산점도로 표시하면 다음과 같다.
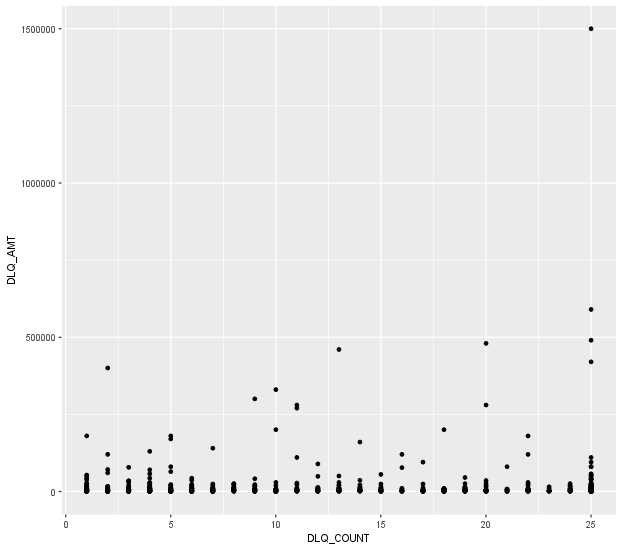
이때, 개별 연체액이 1500000인 데이터 때문에 실제와는 다른 결과가 발생할 수 있다.
따라서, 두 번째 줄에서 보이듯이 이상치를 제거해줬다.
이를 산점도로 다시 표시하면 다음과 같고,
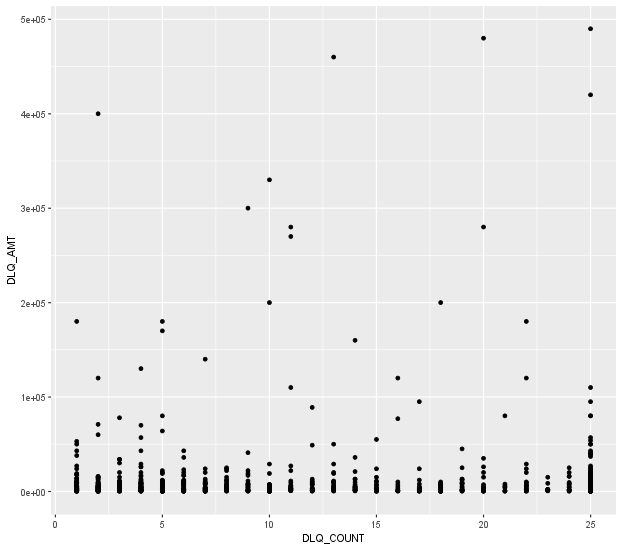
cor.test 함수로 상관분석을 실행하면 다음과 같은 결과가 나온다.
data: df_delay_new$DLQ_COUNT and df_delay_new$DLQ_AMT
t = 1.162, df = 880, p-value = 0.2455
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.02694022 0.10488202
sample estimates:
cor
0.0391412 t검정 값은 1.162가 나오고, p-value(유의확률)의 값은 0.2455로, 95%의 신뢰수준에서 개별 연체액과 개별 연체 횟수 간 상관관계는 낮다고 볼 수 있다.
그렇다면 개인별 총 연체액과 총 연체 기간 간 상관관계는 어떨까. 코드는 다음과 같다.
df_delay_final <- df_delay_new %>% group_by(JOIN_KEY) %>% summarise(DLQ_CNT = sum(DLQ_COUNT), DLQ_AMT = sum(DLQ_AMT))
df_delay_final <- subset(df_delay_final,DLQ_CNT < 100 & DLQ_AMT < 500000)
ggplot(df_delay_final, aes(x=DLQ_CNT, y=DLQ_AMT)) + geom_point()
cor.test(df_delay_final$DLQ_CNT, df_delay_final$DLQ_AMT)이번에는 개별 연체액의 총합인 DLQ_CNT 컬럼과 개별 연체 기간의 총합인 DLQ_AMT를 포함한 데이터프레임을 생성했다.
이를 산점도로 표시하면 다음과 같다.
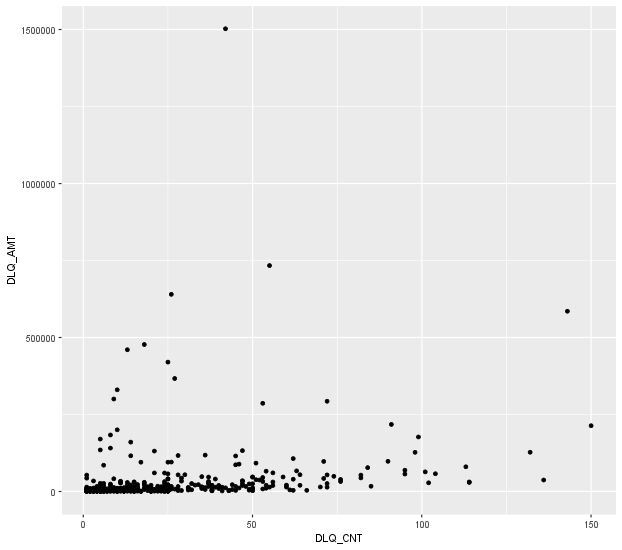
여기서도 이상치가 발생하므로, 두 번째 줄처럼 범위를 지정해서 이를 제거해준 뒤, 산점도로 나타내면 다음과 같고,
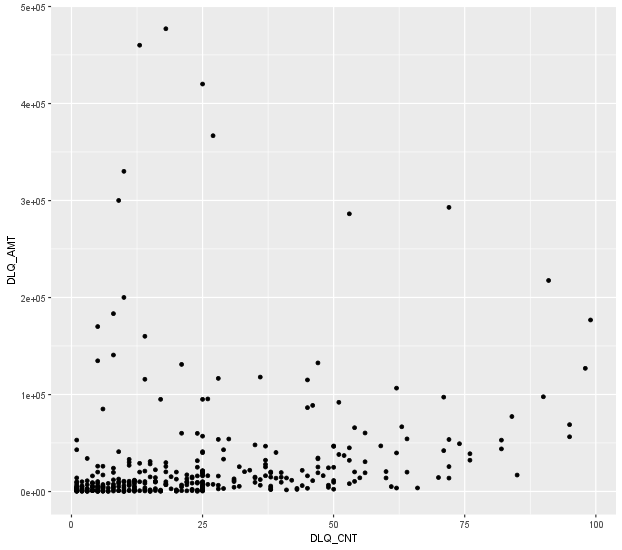
cor.test 함수로 상관분석을 실행하면 다음과 같은 결과가 나온다.
data: df_delay_final$DLQ_CNT and df_delay_final$DLQ_AMT
t = 4.2706, df = 385, p-value = 2.459e-05
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.1154312 0.3058730
sample estimates:
cor
0.2126708 t-검정 값은 4.2706이고, p-value 값은 2.459e-05으로, 이는 95% 신뢰수준에서 유의수준인 0.05보다 낮다고 볼 수 있다.
따라서 총 연체액과 총 연체 기간 간 상관관계는 있다고 볼 수가 있다.
느낀 점
사실 처음에는 개인신용 데이터를 기반으로 신용점수를 계산해보는 코드를 작성하려 했으나, 생각만큼 잘 되지는 않았다.
만약 데이터에 신용점수까지 포함되어 있었다면 회귀분석을 통해 구할 수 있었을까...
