개요
학창 시절, 맛있는 식사에 행복해하고, 맛없는 식사에 불행을 느낄 때가 많았다. 그러면서 언제나 맛있는 식사가 나오길 바란 적도 많았다.
그렇다면, 전국 초중고 중에서 언제나 내가 가장 맛있어할 식사가 나올 학교는 어디일까? 이를 R을 이용해 분석했다.
데이터셋
나이스 교육정보 개방 포털 에서 전국 모든 학교의 기본 정보 및 급식 정보를 조회할 수 있다. 학교 기본 정보는 csv로,
급식 정보는 학교마다 조회해야 되는 번거로움이 있어, 코드 상에서 API 호출을 통해 가져오도록 했다.
코드 설명
library(httr)
library(jsonlite)
library(dplyr)
Sys.setlocale("LC_CTYPE", ".1251")API를 호출해서 JSON 형태의 데이터를 가져와야 하기 때문에 httr과 jsonlite 라이브러리를 로드했다.\
또한 한글 데이터가 있으므로, 로케일 정보를 .949에서 .1251로 바꿔주었다.
school_info <- read.csv("./school_info.csv", encoding = "UTF-8")
school_info$score <- 0기존에 다운로드 받은 학교 기본 정보 csv 파일을 불러와서 dataframe으로 저장해준다. 이때, 인코딩 옵션은 UTF-8로 한다.\
그 다음, 학교마다 급식에 대한 평균 점수를 저장하기 위해, score 컬럼을 추가한다.
list_pattern <- c("국수|스파게티|[가-힣]*면$|소바|모밀|우동|치킨|[가-힣]*버거|머핀|카스테라|케이크|케익|케잌|파스타|핫도그|도넛|토스트|피자|와플|쿠키",
"[가-힣]*(수제비|불고기|가스|까스|스테이크|튀김|구이)$|떡국|[가-힣]*(스프|수프|빵|볶음|볶이)|돼지|닭|쥬스|주스|바나나|딸기|귤|수박|참외|멜론|포도|사과|갈비",
"카레$|커리$|(하이|카레|오므|커리|자장|짜장)라이스|비빔밥|볶음밥|만두|필라프|짬뽕|탕수육|훈제",
"덮밥|토마토$|[가-힣]*(찜|잡채|샐러드|전|탕|찌개|죽|떡|말이)$|샌드위치|방울토마토|우유|주물럭|두부|커틀릿|커틀렛",
"[가-힣]*(밥|김치|깍두기|겉절이)$","[가-힣]*국$|육개장|나물", "[가-힣]*조림$","[가-힣]*(냉채|생채|무침)$")
list_score <- c(3,2,2,1,0,-1,-2,-3)맛있거나 맛없는 음식재료, 또는 요리를 7점 척도로 나열하고, 정확한 검색을 하기 위해 정규식으로 바꿔주었다.
for (sch_code in school_info[, 3]) {
df_dish <- NULL
i <- 1
while (1) {
req_url <- paste0("https://open.neis.go.kr/hub/mealServiceDietInfo?KEY=cee31841befb40f8ab6af2c8a856686d&Type=json&ATPT_OFCDC_SC_CODE=B10&SD_SCHUL_CODE=",
sch_code, "&pSize=1000&MMEAL_SC_CODE=2&pIndex=", i)
response <- RETRY("GET", url = req_url, timeout(30), times = 5)
response <- fromJSON(content(response, as="text"))학교마다 다른 URL을 호출해야 하므로, 학교 기본 정보의 3번째 열에 있는 학교 코드를 for문을 통해 호출한다. \
그리고 각 학교에 저장된 급식의 수가 다르므로, while(1)로 무한반복을 걸었는데,어떻게 탈출하는지는 뒤에 후술하겠다. \
요청할 URL은 위와 같다. 여기서는 서울에 있는 학교의 중식만 호출하겠다. \
학교 코드와 페이지 수를 변수로 지정했고, 반복문이 돌아갈 때마다 두 변수들이 바뀔 것이다. \
마지막으로, 응답 과정에서 timeout error를 방지하기 위해, httr의 RETRY를 통해서 timeout 시간과 반복 횟수를 늘려주었다.
if ("mealServiceDietInfo" %in% names(response)) {
df_response <- as.data.frame(response$mealServiceDietInfo$row[2])
list_dish <- df_response$DDISH_NM
list_dish_split <- strsplit(list_dish, split = "<br/>")
list_dish_only_name <- sapply(list_dish_split, function(x) gsub("[0-9]+.", "", x))
list_dish_final <- lapply(list_dish_only_name, 'length<-', max(lengths(list_dish_only_name)))
if (is.null(df_dish)) {
df_dish <- as.data.frame(list_dish_final)
df_dish <- data.frame(t(df_dish))
rownames(df_dish) <- seq_len(nrow(df_dish))
} else {
temp_dish <- as.data.frame(list_dish_final)
temp_dish <- data.frame(t(temp_dish))
rownames(temp_dish) <- seq_len(nrow(temp_dish))
df_dish <- bind_rows(df_dish, temp_dish)
}
i <- i + 1
} else {
break
}
}다음은 json에서 가져온 데이터를 가공하는 코드이다. 성공한 json request의 경우, mealServiceDietInfo라는 컬럼명이 포함된다. \
만약 데이터가 하나도 없을 경우에는 이 컬럼이 포함되지 않으므로, break를 걸어서 무한루프에서 벗어나게 해준다.\
또한 기본적인 급식 데이터의 경우, 다음과 같이 나온다.
영양닭죽(녹두)13.<br/>김말이떡볶이(부식)1.5.6.13.<br/>만두튀김21.5.6.10.12.13.<br/>배추김치9.13.<br/>바나나<br/>급식우유2.이 데이터에서 br이라 써진 문자열을 구분자로 하여 문자열을 리스트로 변환시켜준다.
그 다음, 정규식을 이용해 요리명 뒤의 숫자와 온점을 없애주고, 이를 df_dish에 저장시킨다.
이때, 기존의 df_dish에 데이터가 있을 경우, temp_dish로 저장시켜 bind_rows 함수로 병합시킨다.
if (!is.null(df_dish)) {
rm(list_dish, list_dish_only_name, list_dish_split, list_dish_final)
df_score <- data.frame(list_pattern, list_score)
df_dish <- as.data.frame(lapply(df_dish,function(x) gsub('\\([가-힣a-zA-Z0-9\\-\\/ ]*\\)|[\\*\\.\\/\\+\\-\\&\\@][가-힣]*|\\([가-힣]*|\\-[가-힣]*$', "", x)))
df_dish$score <- 0
for (j in seq_len(nrow(df_dish))) {
list_temp <- sapply(df_score$list_pattern, grepl, df_dish[j,], ignore.case = TRUE)
position <- apply(list_temp, 1, function(a) head(c(which(a), 0), n = 1))
df_dish[j, "score"] <- sum(df_score[position, "list_score"])
}
school_info[school_info[3] == sch_code, "score"] <- mean(df_dish$score)
rm(list_temp, position)
}
print(paste(school_info[school_info$X.U.D45C..U.C900..U.D559..U.AD50..U.CF54..U.B4DC. == sch_code, 4], "complete."))
}저장된 급식 식단의 개수가 0이 아니라면 요리명에 섞인 불순물(특수문자, 하이픈 등)을 다시 걸러준 다음, score 컬럼을 추가한다. \
다시 식단 개수만큼 반복문을 돌려서, df_score에 있는 정규식 패턴에 맞는 요리명을 뽑아와서 list_temp에 저장시킨다.\
그 다음, 각 요리명의 row를 구해서, 패턴에 맞는 점수 값들을 해당 row의 score 컬럼에 저장시킨다. \
마지막으로, 반복이 끝나면 각 점수들의 평균을 구하여 school_info의 score에 저장시키고, \
해당 학교의 점수 산정이 끝났음을 출력한 뒤, 다음 학교로 넘어간다.
결과
school_info 중, 학교명과 평균 점수만 따로 추출해서 본 결과는 다음과 같았다.
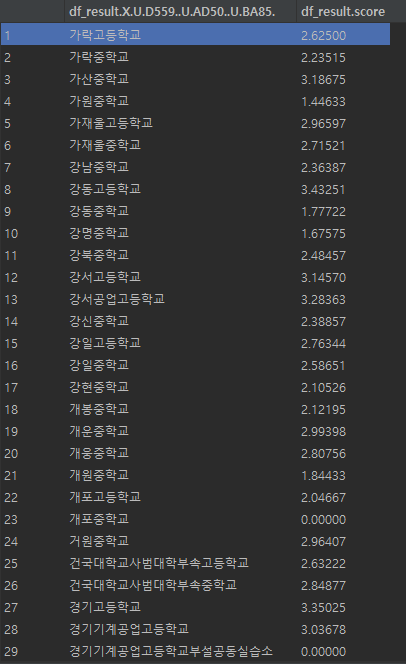
점수가 고르게 분포된 것 같지만, 전처리가 제대로 안된건지, 0점도 간간히 보인다.
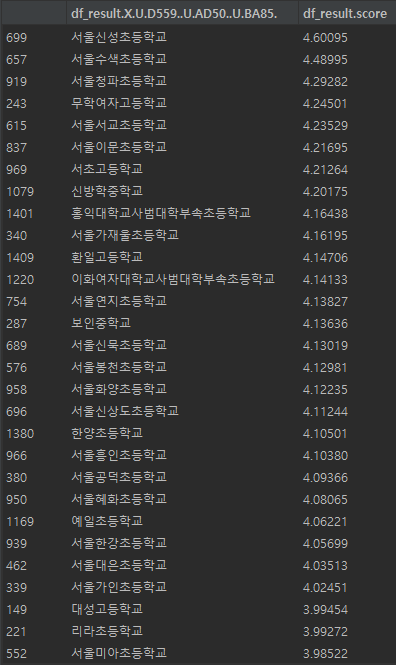
점수를 기준으로 내림차순으로 정렬해보면, 서울 전체 초중고 중에서, 내 기준으로 서울신성초등학교라는 곳의 급식이 가장 맛있다고 나온다. 그렇다면 실제 급식은 어떨까.

음, 꽤 괜찮아 보이는 식단이다.
느낀 점
서울의 모든 학교의 급식에 대한 데이터를 가져오고, 처리하는 데만 한 학교에 약 3초, 총 1시간 정도가 소요되었다. \
이 속도를 개선할 방안을 찾아봐야겠다. 그리고 가장 점수가 낮은 식단을 찾아보니, 생각보다 불순물이 잘 걸러지지 않았다. \
정규식 필터를 좀 더 다듬어야겠다.
